Week 14: Delta Lake on Azure Databricks 🚀
 Mehul Kansal
Mehul Kansal
Hey there! 👋
In this week's blog, we’ll delve into the specific challenges associated with traditional Data Lakes and demonstrate how Delta Lake, an open-source storage layer, effectively addresses these issues, with hands-on examples using Azure Databricks. Let's begin!
Data Lake challenges
As we know, a Data Lake is a storage repository that holds vast amounts of raw data in its native format. But it has some limitations to it.
A major challenge that arises with Data Lake is that it does not provide any ACID guarantees (Atomicity, Consistency, Isolation, Durability).
Some of the scenarios in which ACID guarantees are not achievable in case of Data Lake are:
Job failing while appending the data: Data atomicity and consistency get affected in this scenario.
Job failing while overwriting the data: Data atomicity, consistency and durability get affected in this case.
Simultaneous reads and writes: Data isolation gets affected in this case.
Appending data with a different schema: Data consistency gets affected here.
Delta Lake
Delta Lake is an open source storage layer that acts like a utility installed on the Spark cluster. It overcomes all the challenges faced in case of a Data Lake.
In delta lake, transaction log files get generated after all the part files get created and the entire job gets executed completely.
Due to the transaction files, ACID properties are guaranteed in delta lake.
Delta Lake Practical
- Suppose we have the following two files in our storage account in Azure.
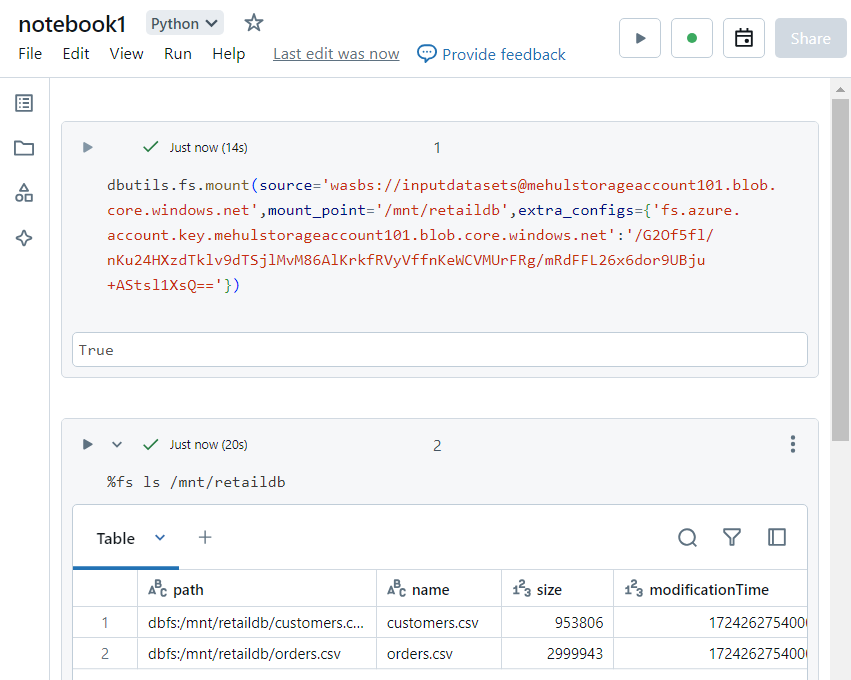
- We mount the storage account in our Databricks workspace, using the access key. Then, we can access the two files in the file system.
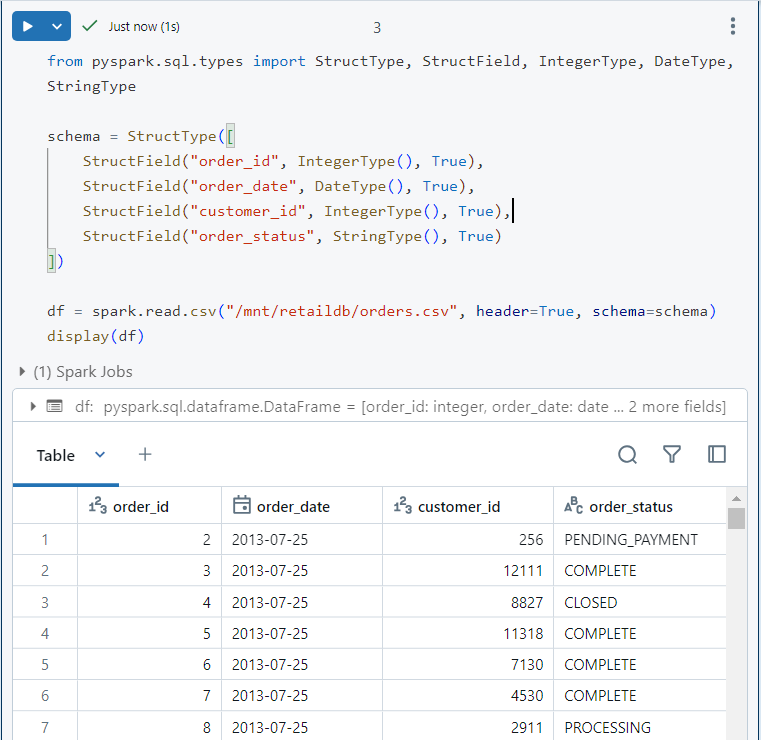
- We create a dataframe out of the 'orders.csv' file using the following syntax.
- We write the data into our storage account in both parquet and delta format.
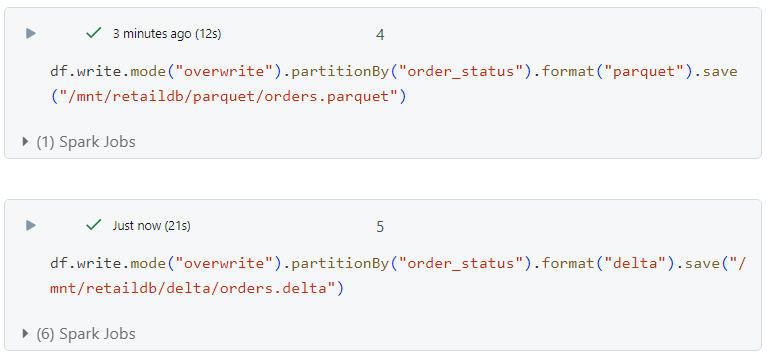
- In case of parquet, data gets stored within folders equivalent to different 'order_status'.
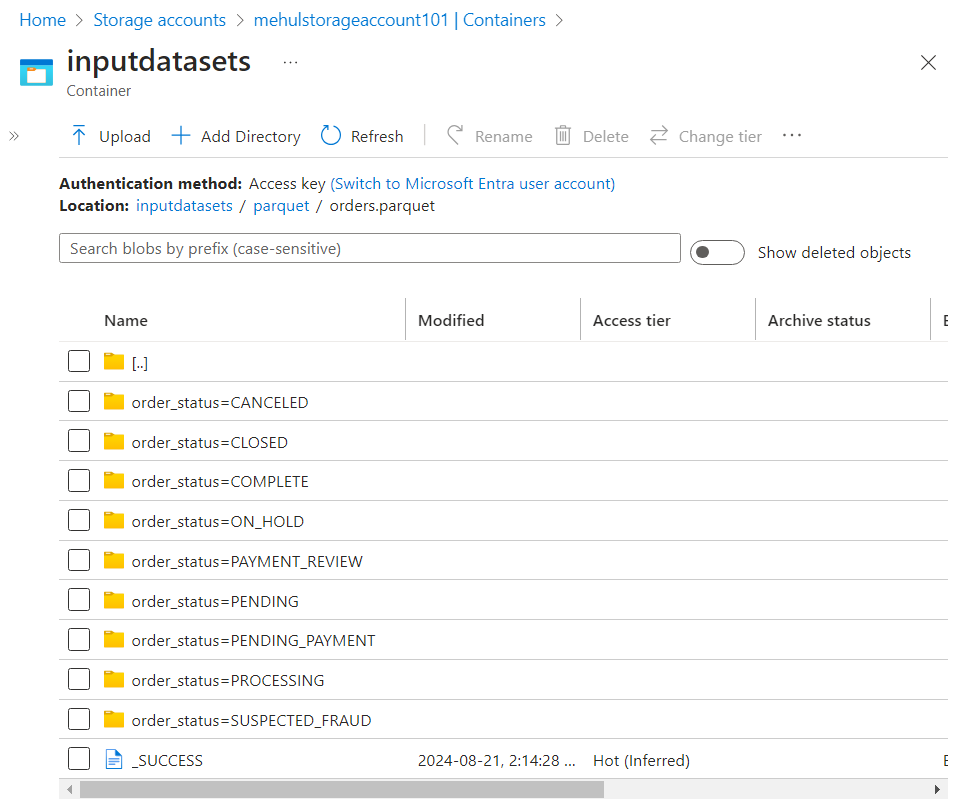
- In case of delta format, the folder structure is same as in parquet, but an extra '_delta_log' folder gets created, which stores the transaction logs.
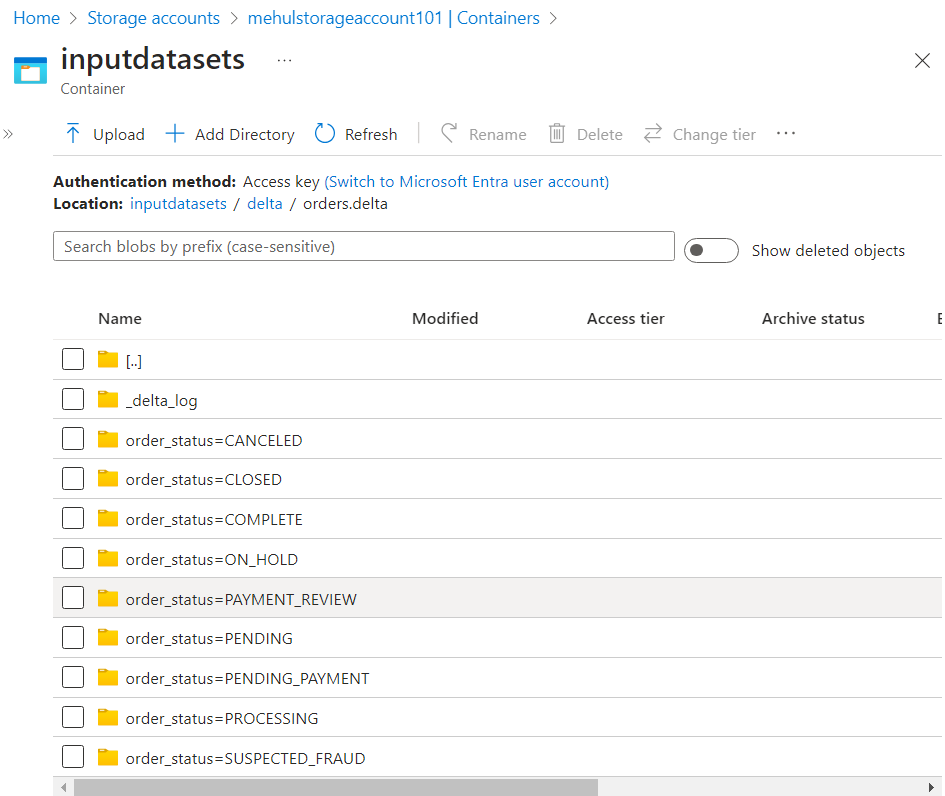
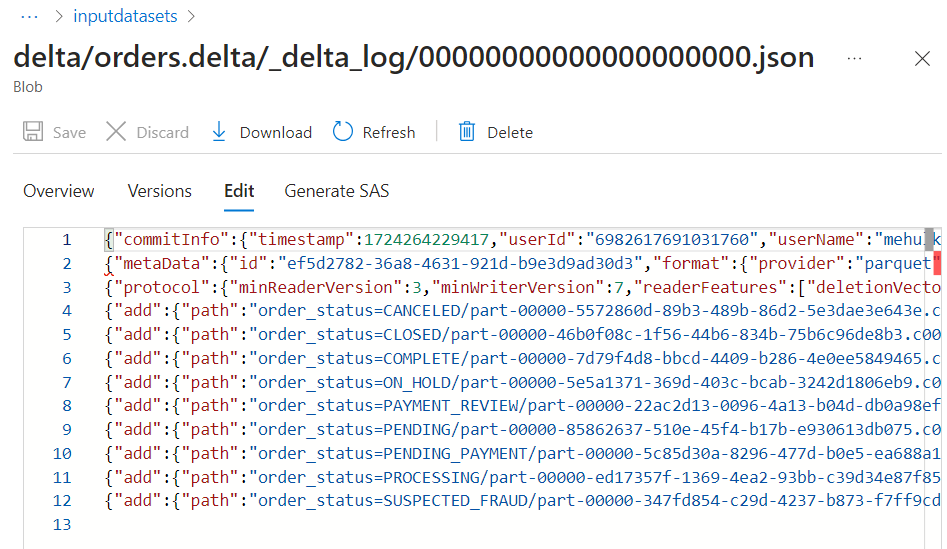
- The log file contains the history of transactions thus enabling ACID guarantees.
Creating tables on the data stored in Delta lake
- We create the database using the following usual command.
%sql
create database if not exists retaildb
- We create a table in parquet format using the following syntax.
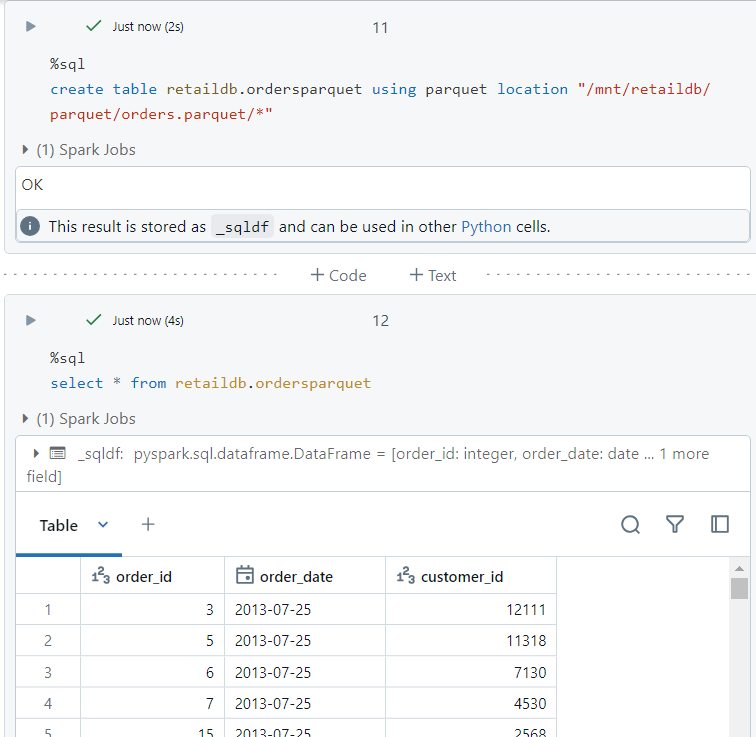
- For creating a table in delta format, we use the following syntax.
- We can perform the normal SQL commands on the parquet table.
- Similarly, we can perform the normal SQL commands on the delta table.
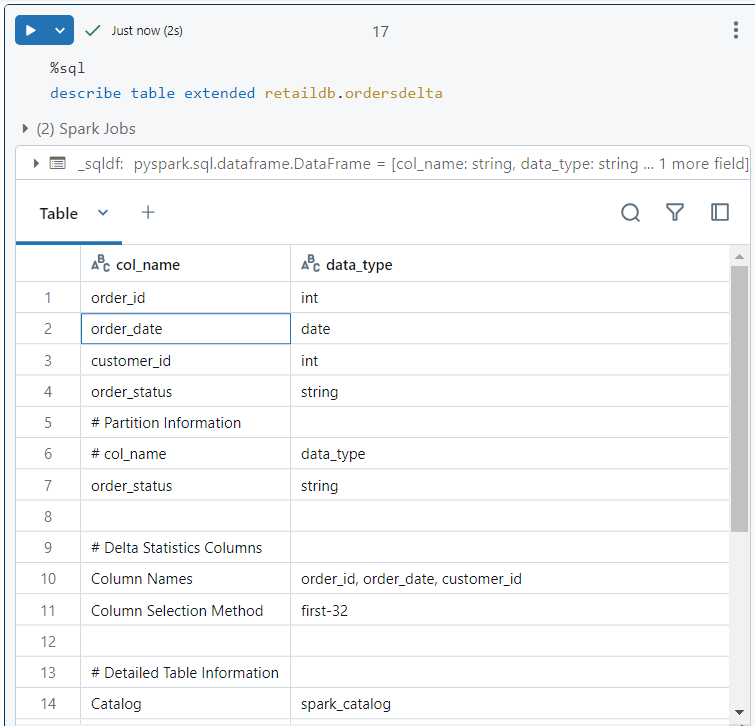
- The following command provides us with a detailed view of the delta table.
- In order to delete the table, the normal drop syntax is used.
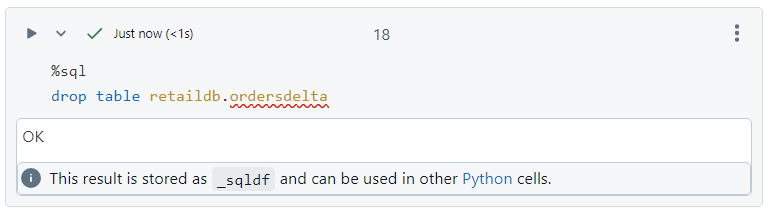
- Even after dropping the table, the data itself does not get deleted since it was an external table.
- We create the table again using the following command.
%sql
create table retaildb.ordersdelta
using delta location "/mnt/retaildb/delta/orders.delta"
- It is interesting to note that both the parquet and delta tables can be accessed from within the Databricks File System as follows.
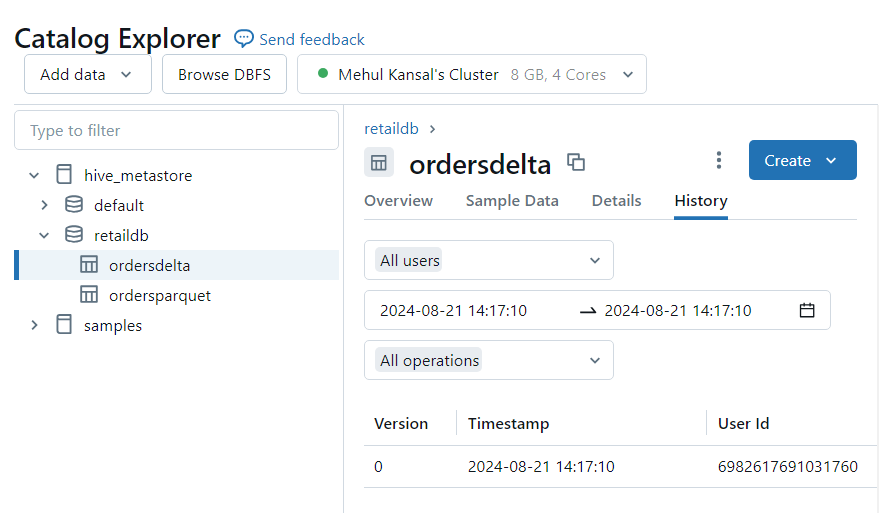
- However, the history of operations is only available in case of delta table.
- It is also possible to create a table while writing the data to the dataframe in a single step.
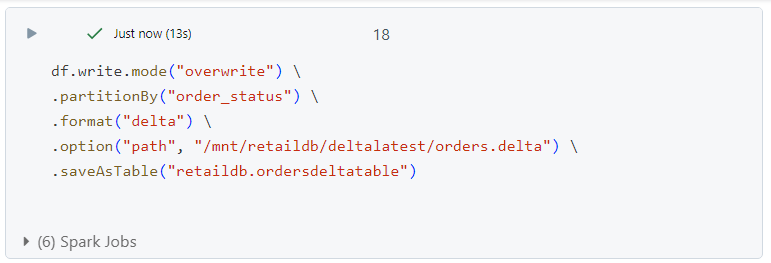
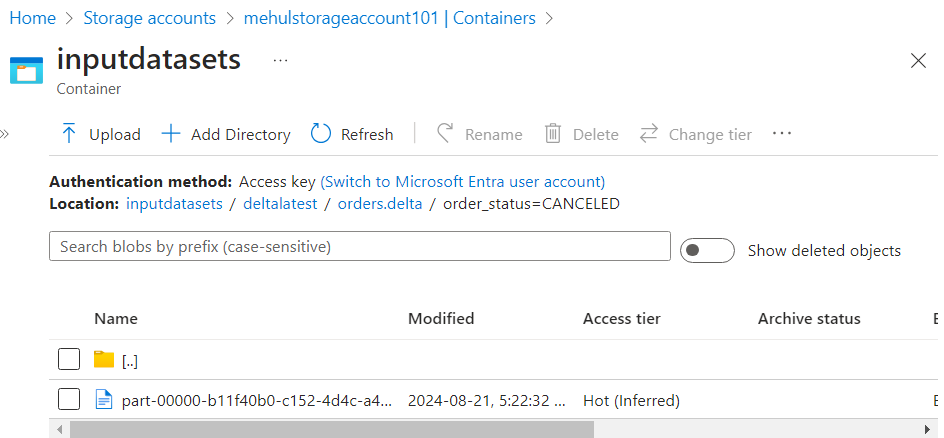
- After running the above command, there is only one part file inside any particular folder.
- Now, if we run the command again as follows.
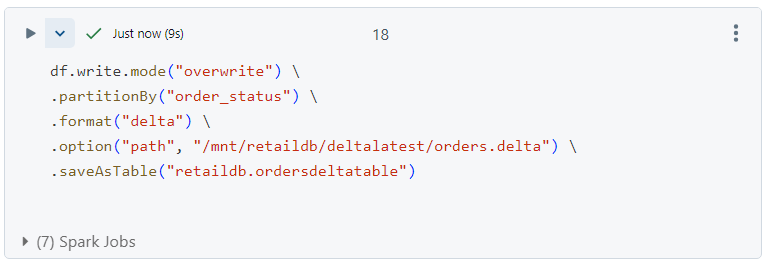
- A new part file will get created.
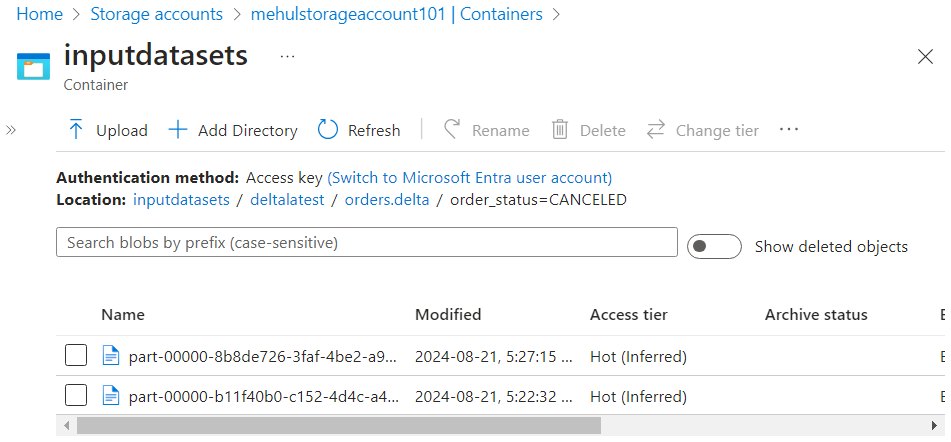
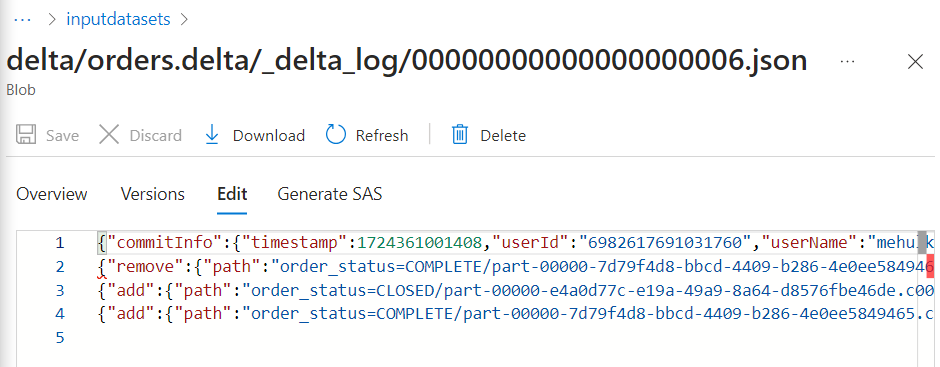
- Inside the log file, corresponding entries get added for adding the new part file and removing the old part file.
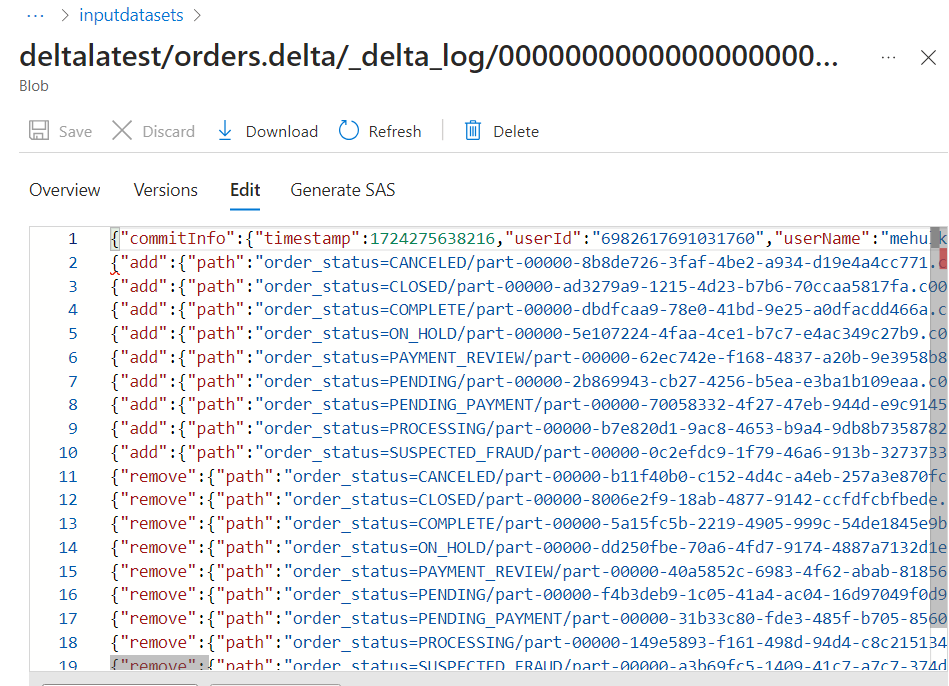
Inserting into delta table
There are three ways of inserting the data into the delta table:
- Insert command
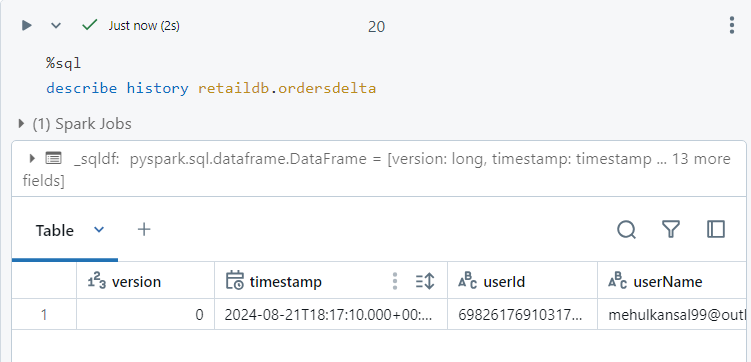
- Firstly, we can see the version of our delta table using the history command.
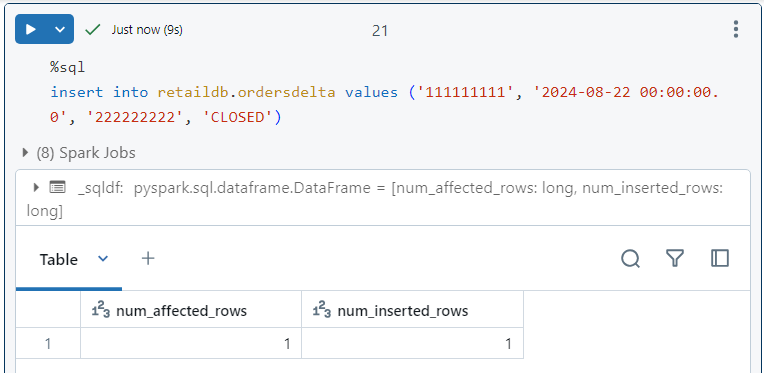
- Now, we insert data into the delta table and it gets inserted successfully.
- If we look at the history again, a new version becomes available.
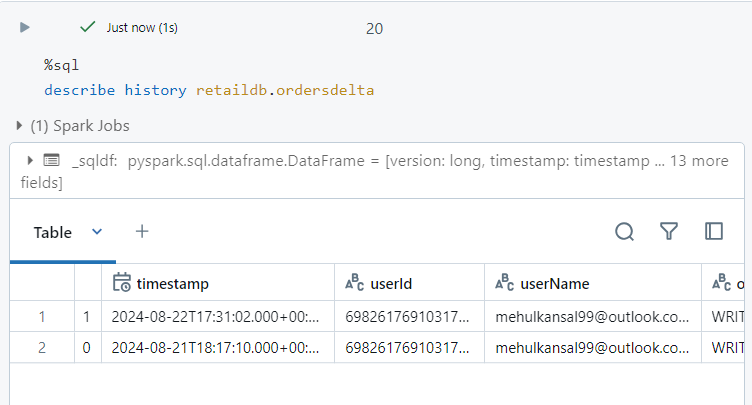
- Also, inside the log file, a 'WRITE' operation entry gets added.
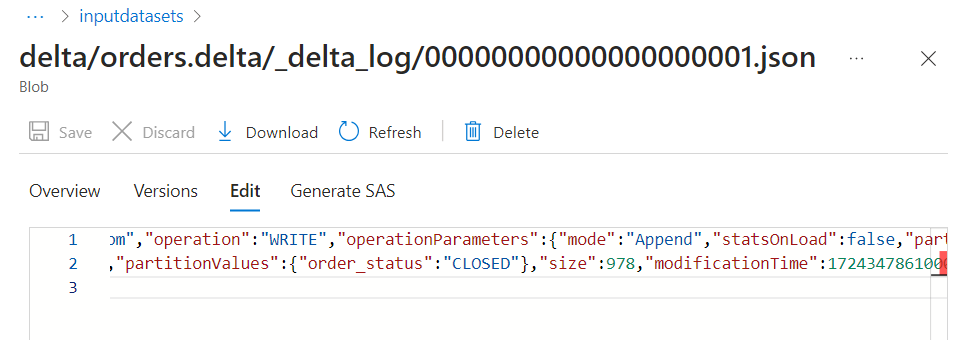
- We can verify the entry as well.
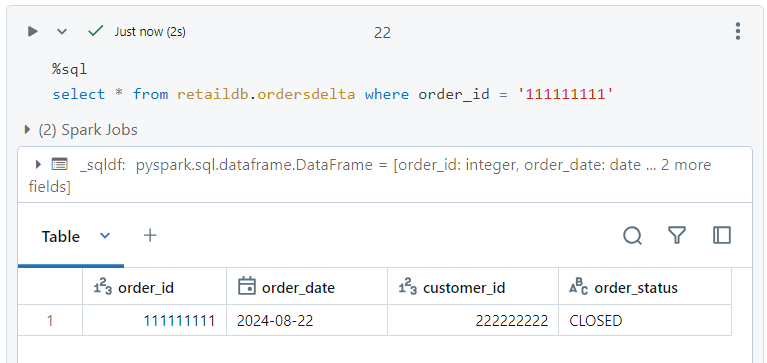
- Append command
- Consider a file 'ordersappend.csv', out of which we create a dataframe and we need to append this into our existing data.
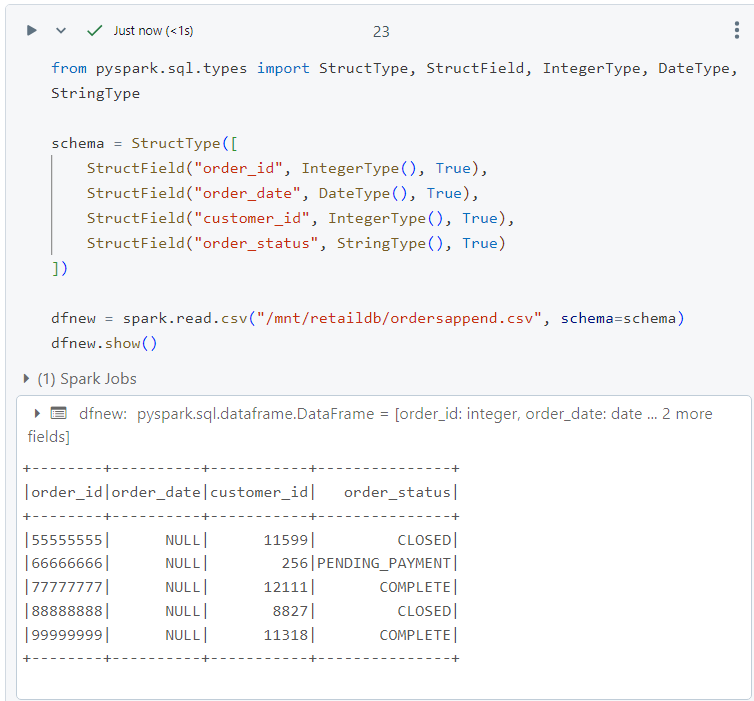
- We can append the above data into our existing data folders as follows. It is interesting to note that a version with 'append' gets added into the history of delta table.
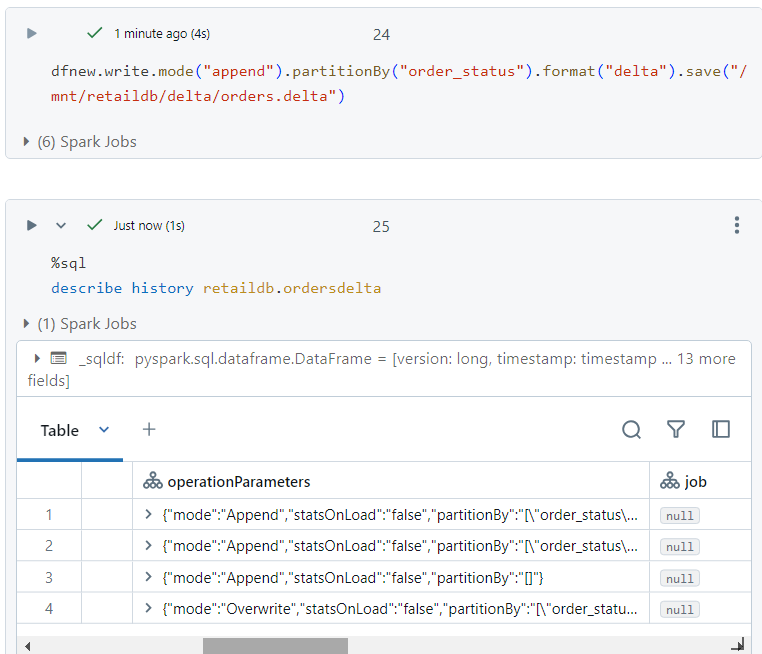
- Inside our delta folder structure, multiple part files corresponding to the appended data get added.
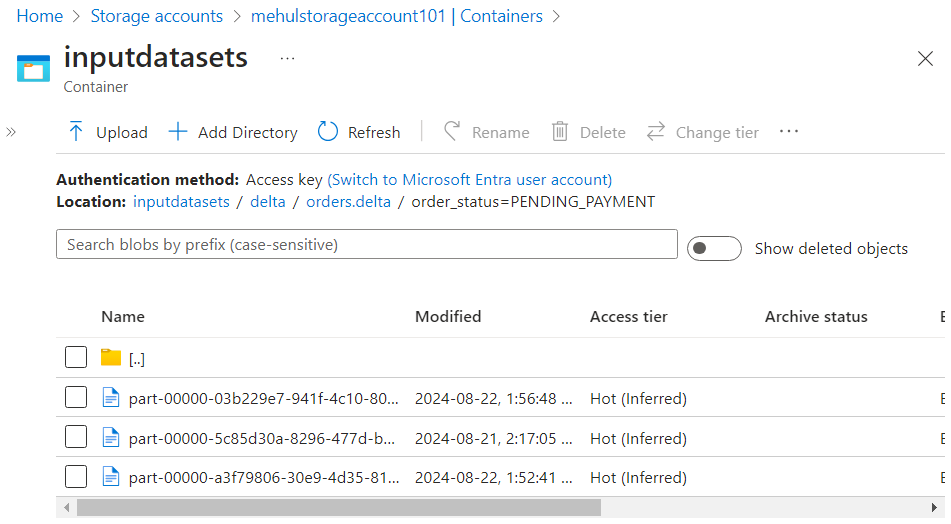
- Copy command
- Consider the following file that needs to be copied into the existing data folders.
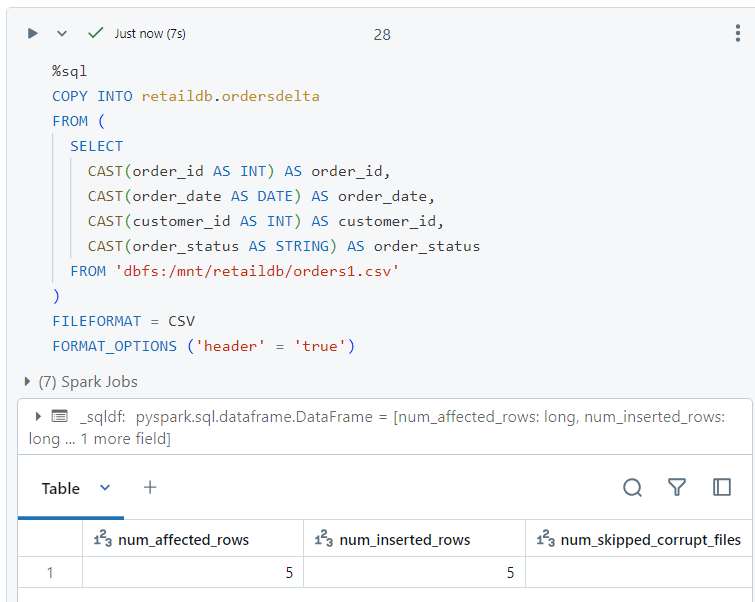
- We use the following 'copy' command to achieve the desired results.
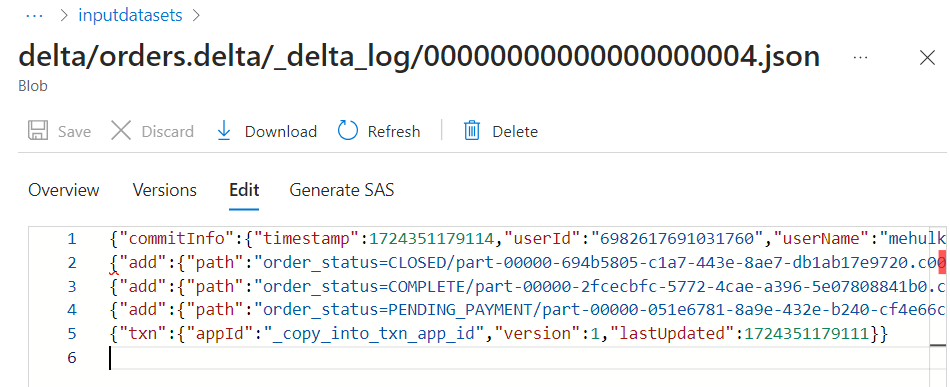
- In the version history, a 'copy into' operation gets added.
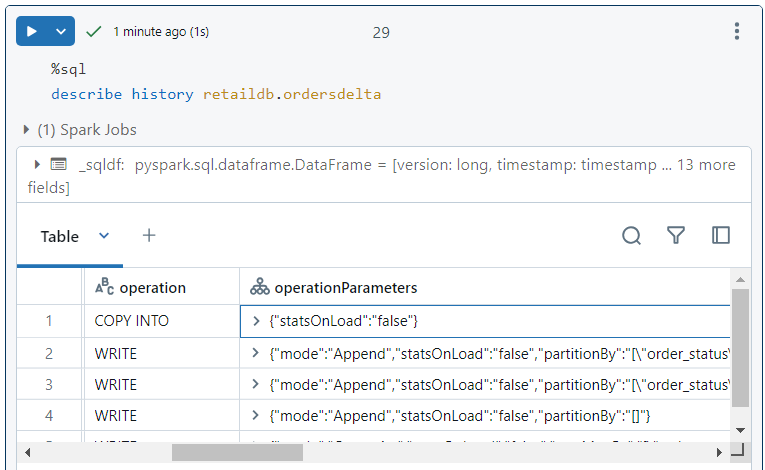
- A '_copy_into' transaction gets added into the delta log file as well.
Performing update and delete
If there is schema mismatch while updating the data in Delta format, it will get identified and an error will be thrown.
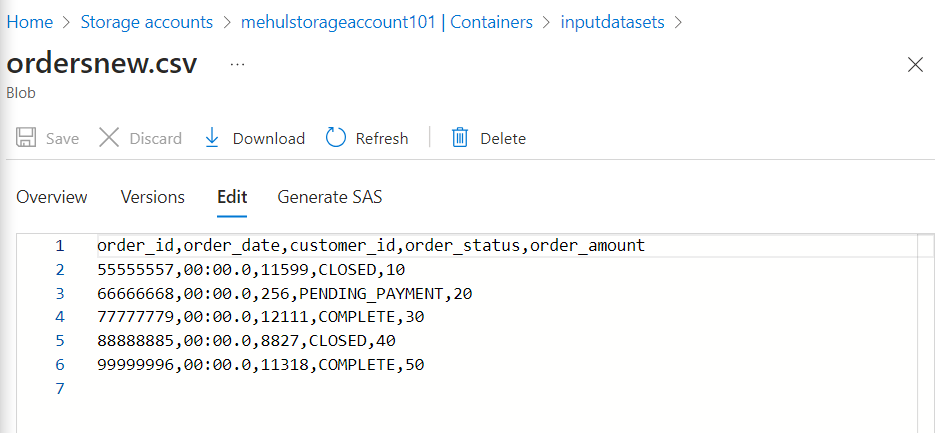
Consider the following file which has an extra column 'order_amount' and we want to append this into our existing data.
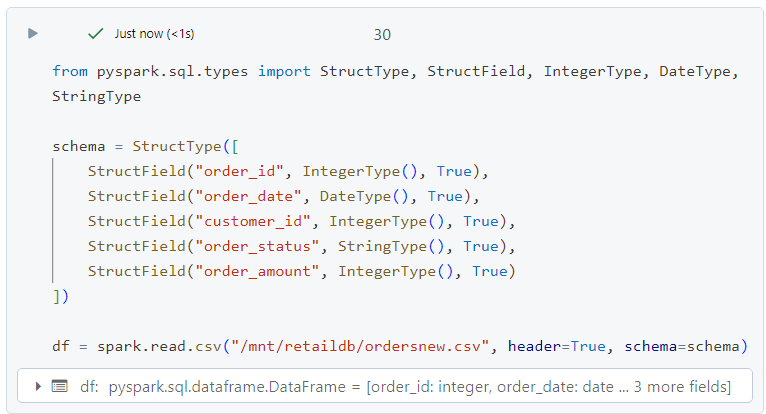
- Firstly, we create a dataframe out of this file.
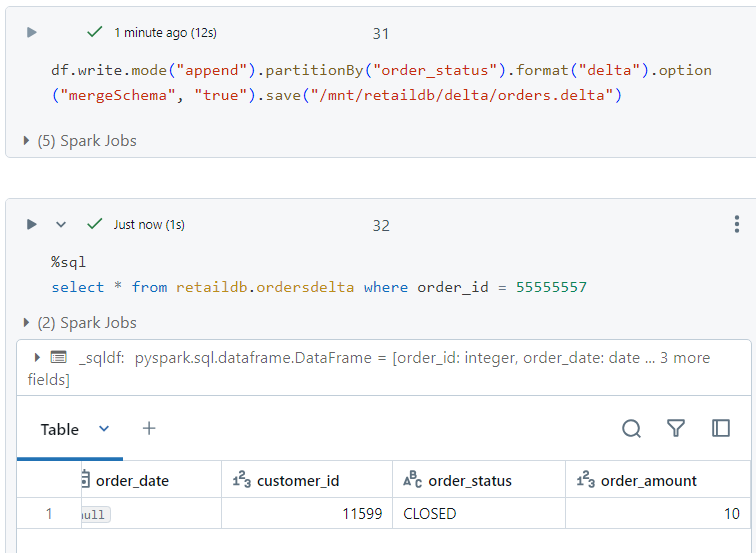
Now, while appending the dataframe into our data in delta format, we provide an option with parameter as 'mergeSchema' and its value as 'true'.
Thereafter, if we select the values from the table, it will start showcasing the fifth column as well.
Simple update
- Presently, we have the following record. We want to update it.
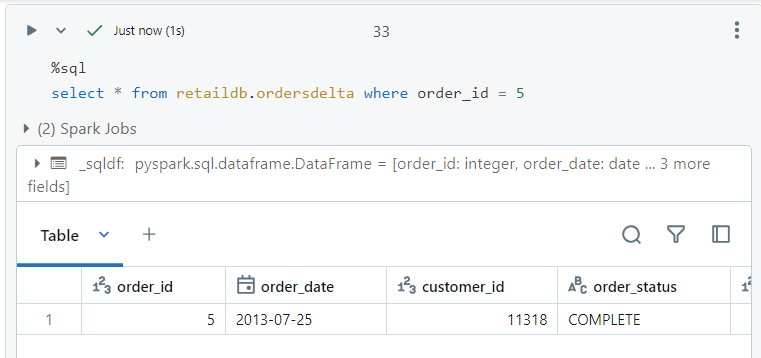
- For updating , simple update SQL command can be used.
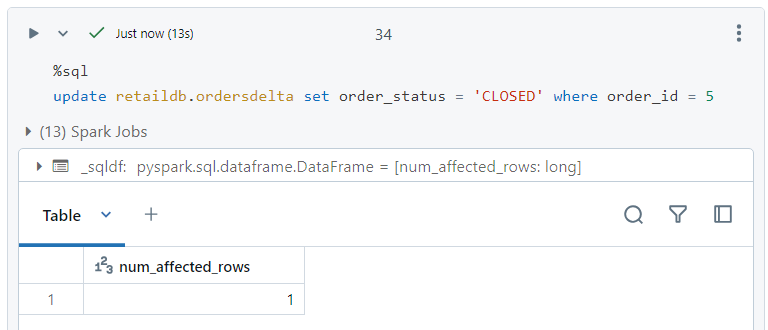
- Inside the delta log file, firstly a new part file gets created with the updated new record and other old records. Then, transaction files get created indicating to add new part file and to remove old part file.
Simple delete
- The syntax for deleting the file is as follows.
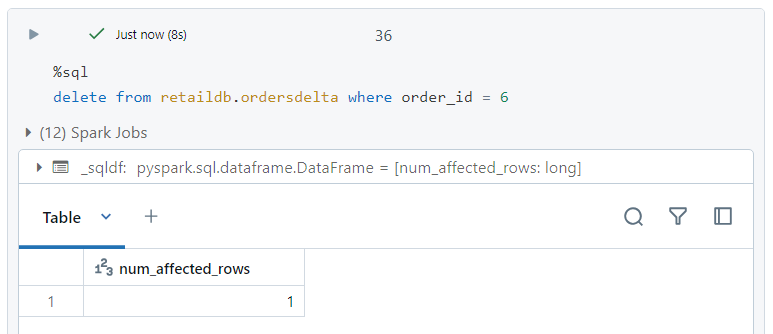
- A new part file gets created with the required record deleted. Then, two transaction logs get created indicating to add the new part file and to remove the old part file.
- After all these operations, the version history of the delta table looks like this.
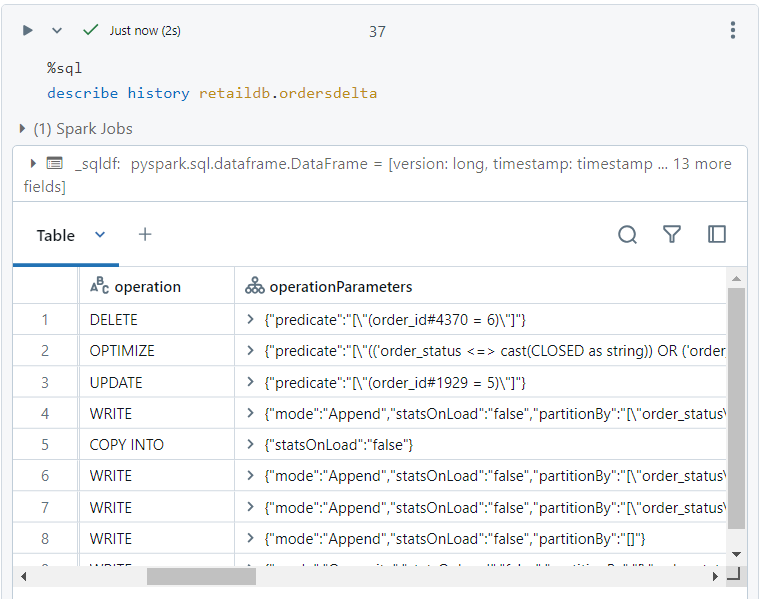
Applying constraints and accessing history using time travel
- We apply the NOT NULL constraint as follows. Note that afterwards, if we try to add 'customer_id' as null, an error gets thrown.
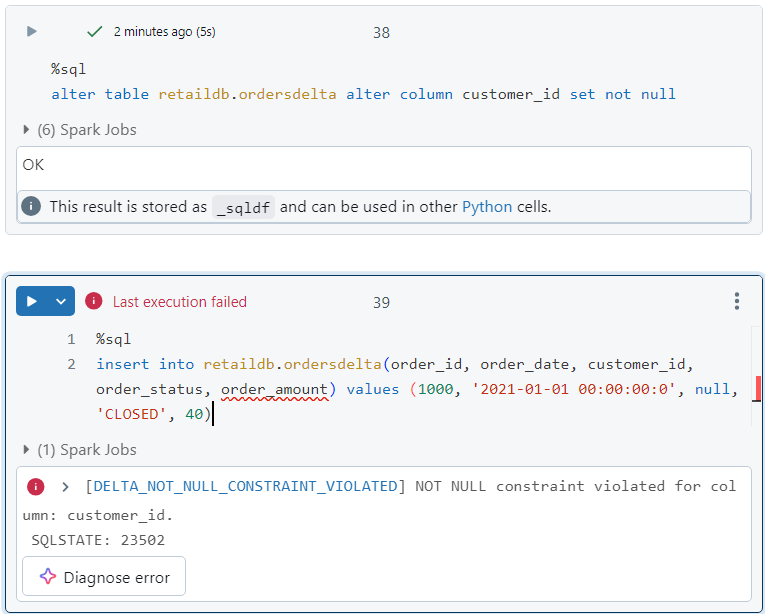
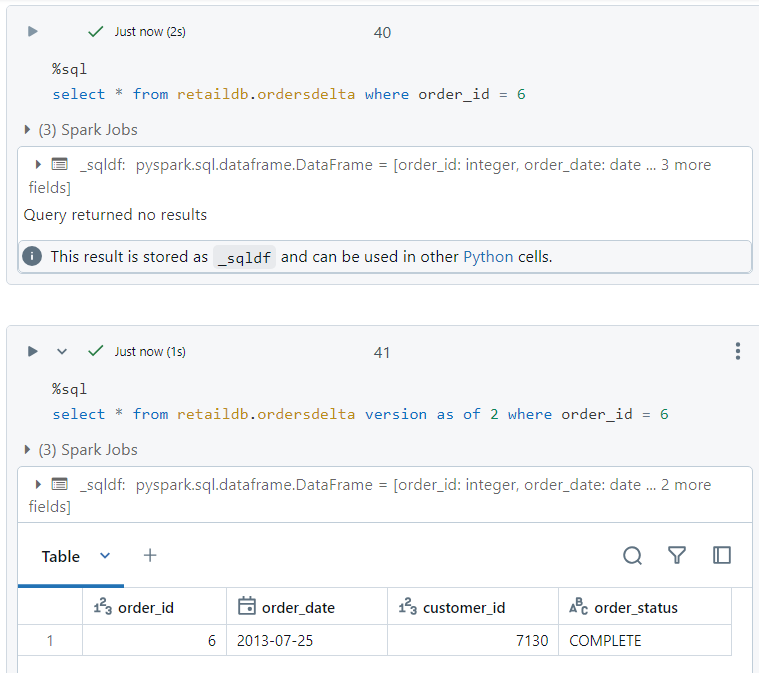
For demonstrating time travel, presently, upon executing the following query, we don't get any results.
But, if we execute the same query on a previous version of the delta table, we get the corresponding entry.
Conclusion
Delta Lake significantly enhances the capabilities of traditional Data Lakes by introducing ACID transactions, schema enforcement, and time travel, making your data management more robust and reliable. Through practical examples, we've seen how Delta Lake simplifies data operations, ensuring data consistency and integrity.
Stay tuned! ⏳
Subscribe to my newsletter
Read articles from Mehul Kansal directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by