Understanding Data Replication in Databases: What It Is and How It Works
 Amitesh Verma
Amitesh Verma
Data is a crucial part of any organization because it drives the entire business. Therefore, it's essential for any organization to securely store and serve data to clients.The following properties are important for any database:
Scalability (ability to serve growing requests from users)
Performance (low latency and high throughput)
Availability (low risk of failure)
It's very difficult to achieve all these with a single node so we use replication techniques to manage data.
What is replication?
Replication means keeping multiple copies of data at different nodes to ensure availability, scalability, and performance. Many people might think it is easy to maintain multiple copies of data at different locations. This is partly true if the data does not require frequent updates.
However the main problem arises when we have to manage changes to the data in multiple places. This is because it is difficult to maintain consistency of data in multiple copies and manage failure of different replicas in the system.
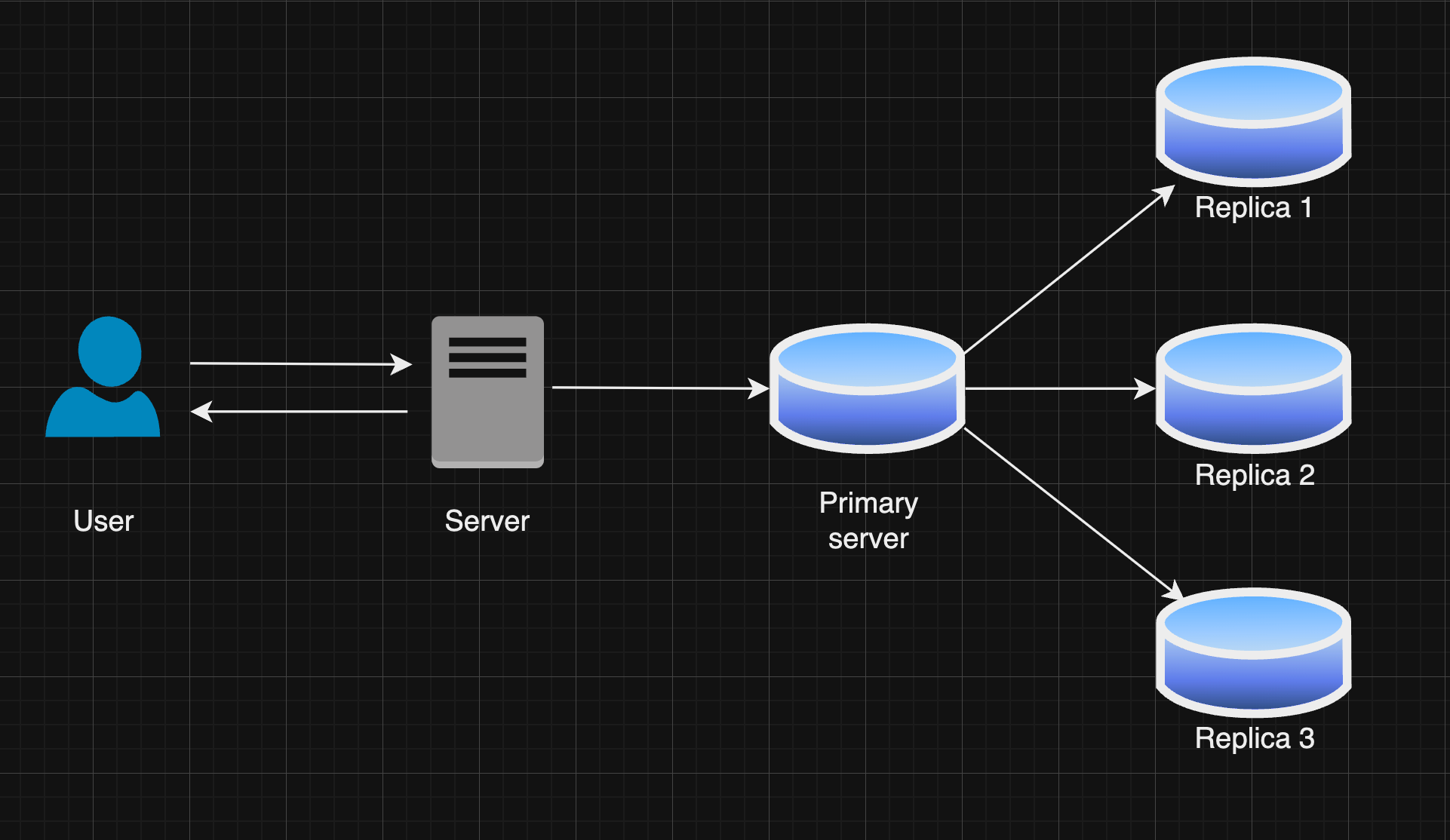
Before we discuss the types of replication, let's start with the different methods of replicating data.
Methods of replication data
There are two primary methods of replicating data.
Synchronous replication:-
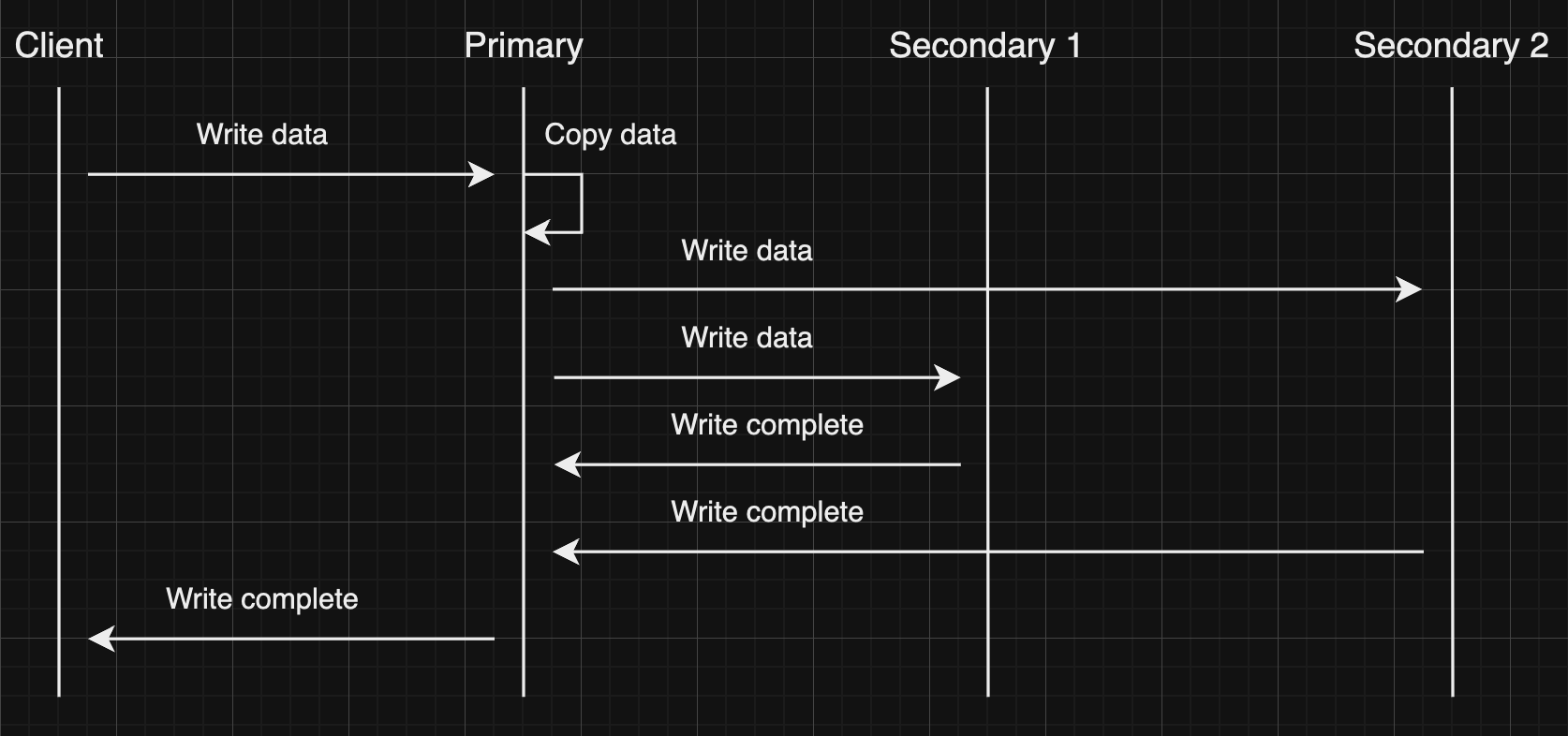
In synchronous replication, the primary node waits for acknowledgments from secondary nodes after updating the data. Once all secondary nodes acknowledge, the primary node reports success to the client.
The advantage of here is that all secondary nodes are always up to date with the primary node. However, the downside is that if one of the secondary nodes fails to acknowledge due to a failure or network issue, the primary node cannot acknowledge the client until it receives a successful acknowledgment from the failed node. This results in high latency in the response from the primary node to the client.
Asynchronous
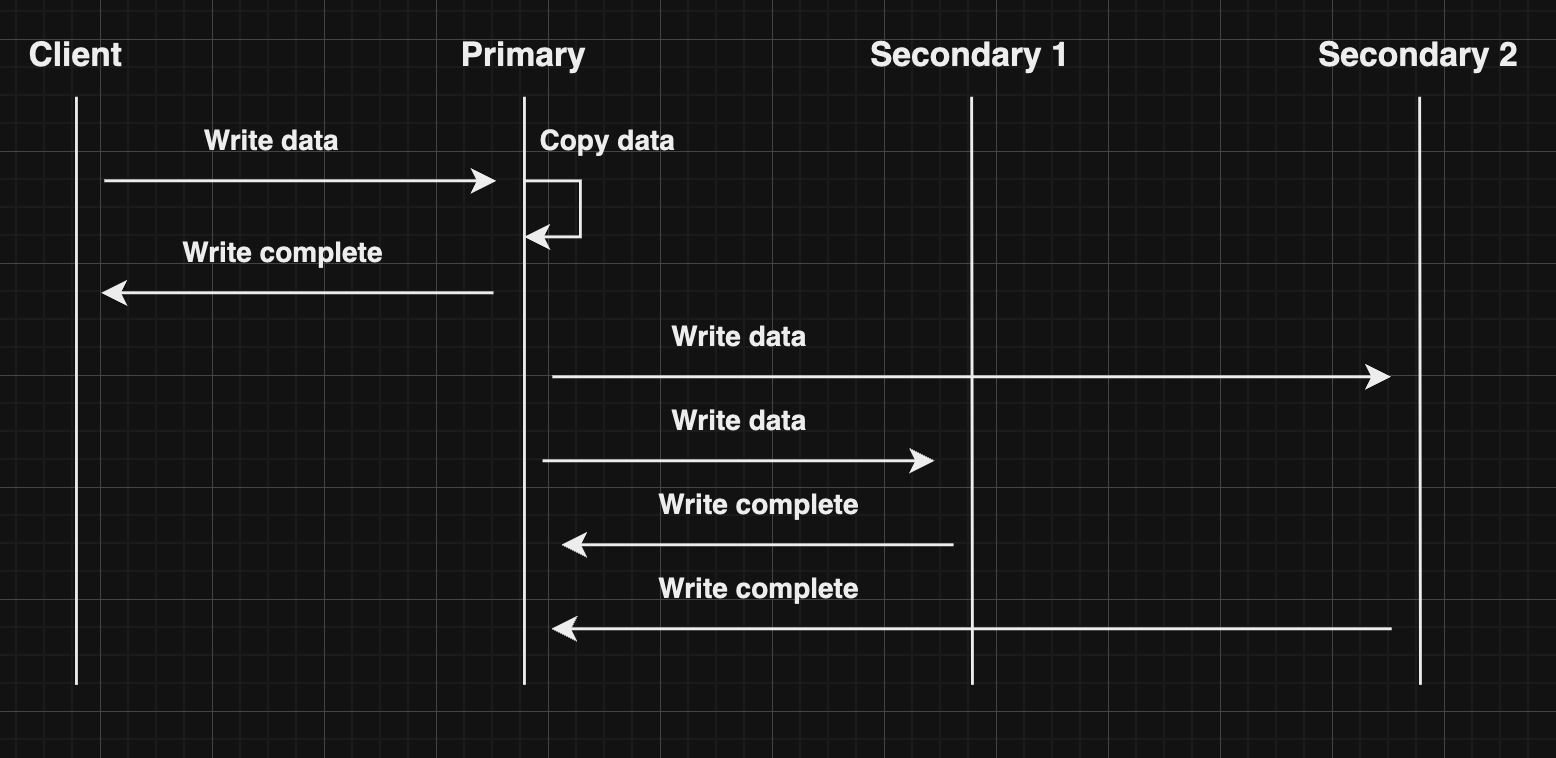
In asynchronous replication, the primary node does not wait for acknowledgments from secondary nodes and reports success to the client after updating itself.
The advantage of asynchronous replication is that the primary node can continue its work even if all the secondary nodes are down. However, if the primary node fails before propagating the updates, the writes that weren’t copied to the secondary nodes will be lost.
Data replication models
Now, let’s talk about different ways to replicate data. In this section, we’ll go over the following models and try to understand them:
Single leader or primary-secondary replication
Multi-leader replication
Peer-to-peer or leaderless replication
Single leader or primary-secondary replication:-
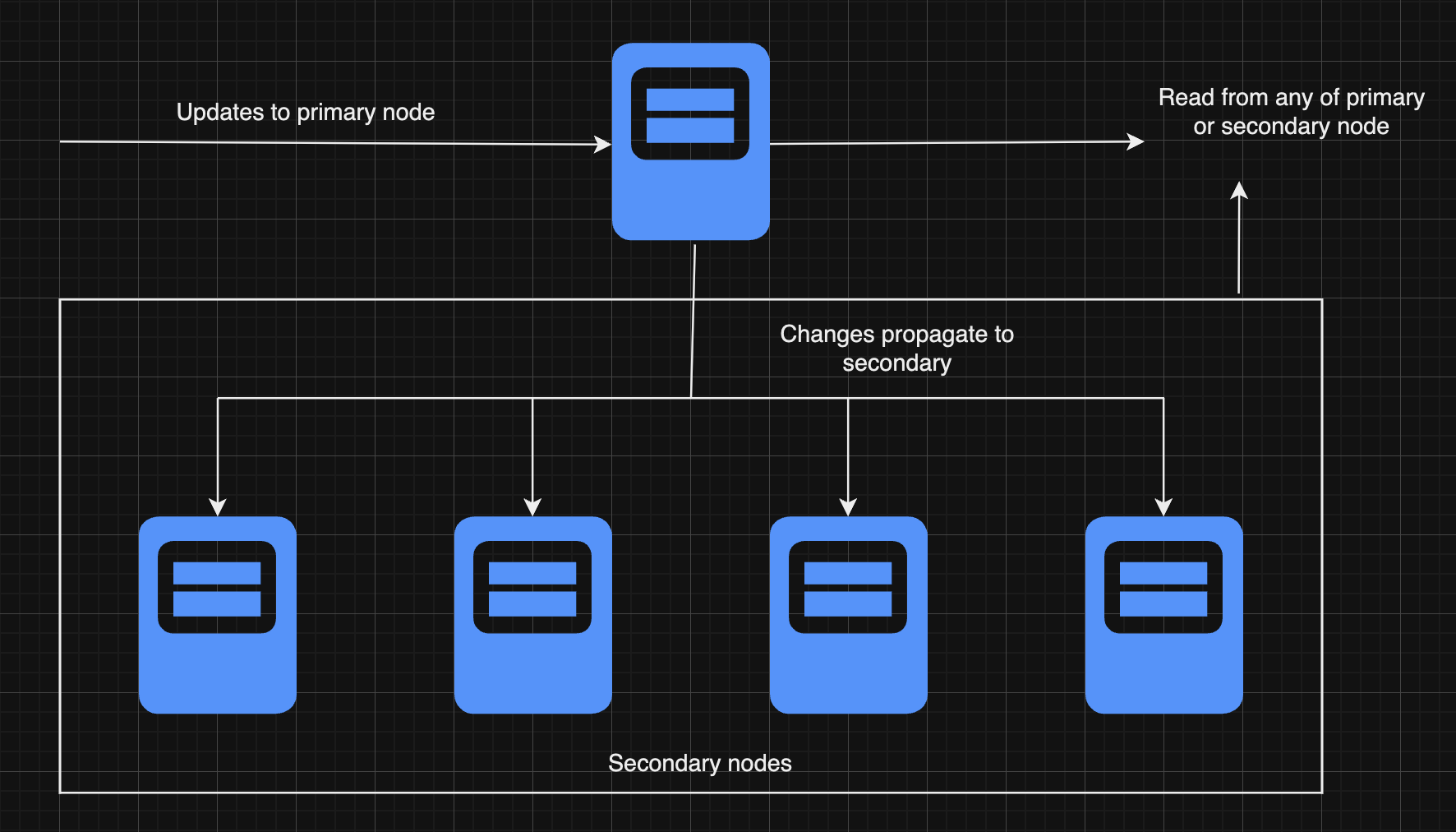
In this replication architecture, there is one primary node (often called the "master") and one or more secondary nodes (referred to as "slaves" or "replicas"). The primary node handles all write operations, such as data updates, inserts, and deletes. After processing these changes, the primary node then pushes the changes to the secondary nodes.
How It Works:
Write Operations: All write operations go to the master node, which processes and replicates changes to the slave nodes.
Read Operations: Reads can be distributed across both master and slave nodes to balance the load, though some setups may have all reads handled by the master.
Data Consistency: Slave nodes are read-only copies of the master, ensuring they have the latest data.
Failover: If the master node fails, a slave can be promoted to master to maintain continuity.
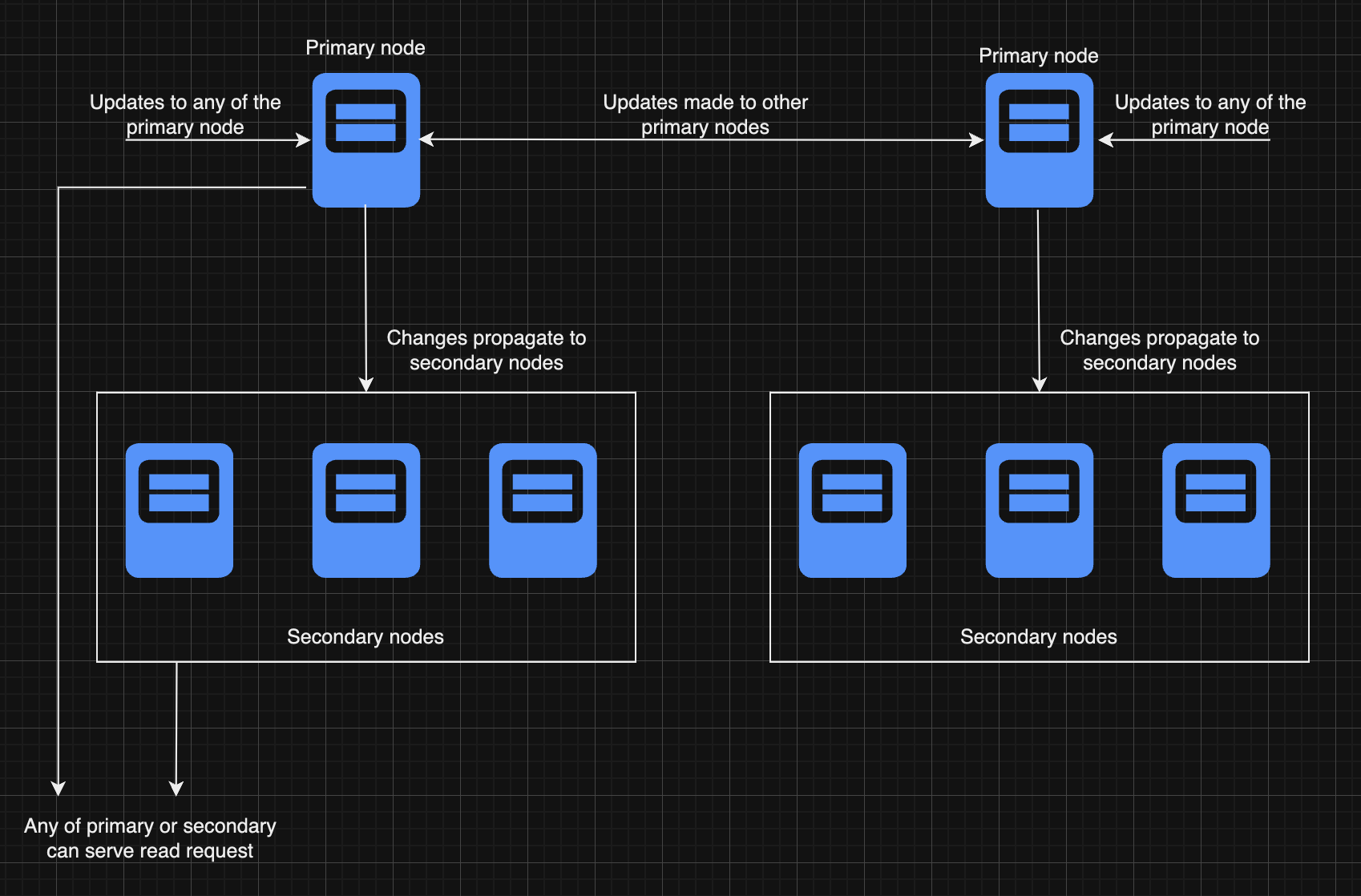
Multi-Leader Replication:-
Multi-leader replication is a more complex setup where multiple nodes act as "masters," each capable of handling write operations. This allows write operations to occur in different geographic locations or across different nodes in the system.
How It Works:
Write Operations: Write operations can be performed on any of the master nodes. Each master node then replicates the changes to the other masters.
Conflict Resolution: Since multiple nodes can accept writes independently, conflicts can happen when two nodes receive conflicting changes at the same time. Conflict resolution strategies (e.g., timestamp-based, priority-based) are essential to ensure data consistency.
Data Consistency: The system must ensure eventual consistency, meaning that while changes might not be immediately reflected across all nodes, all nodes will eventually have the same data.
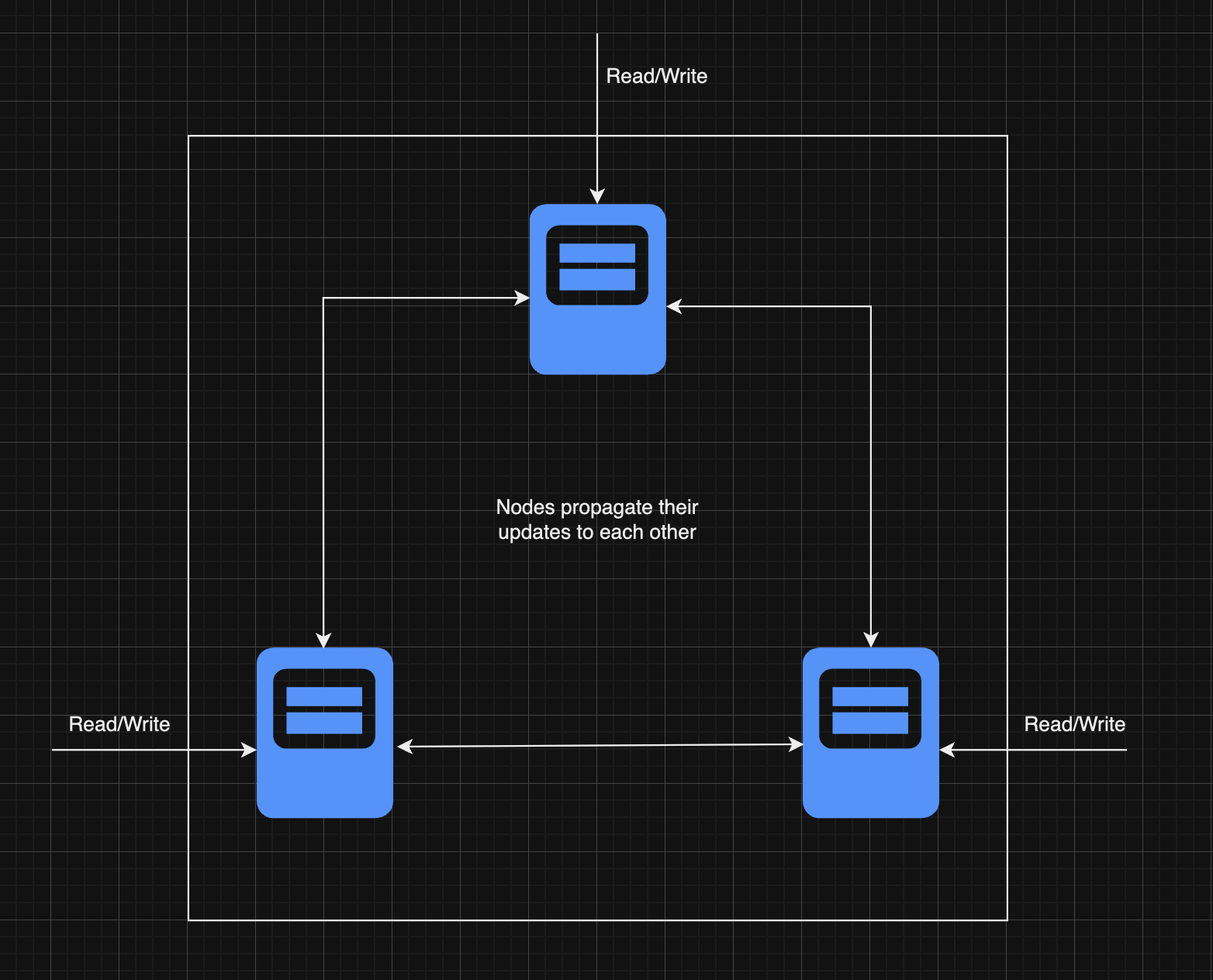
Peer-to-Peer Replication
In peer-to-peer replication, all nodes are equal, with each node able to both read and write data. There is no central master node, making this a fully decentralized system.
How It Works:
Write Operations: Any node in the system can accept write operations. These changes are then propagated to all other nodes in the network.
Data Consistency: Like in multi-leader replication, ensuring consistency across all nodes is crucial, especially since there’s no master to resolve conflicts. Different algorithms and protocols are often used to propagate changes and ensure eventual consistency.
Scalability and Flexibility: This architecture is highly scalable and flexible, as any node can handle both reads and writes, and new nodes can be easily added to the network.
Each of these replication architectures serves different needs based on requirements for availability, consistency, and performance. The choice between them often depends on the specific use case and the desired balance between data consistency and system availability.
Conclusion
Data replication is essential in modern database management, providing better availability, reliability, and disaster recovery. By learning about different replication methods like synchronous or asynchronous you can choose the best one for your business needs, balancing consistency, performance, and scalability. As data-driven applications become more complex, mastering data replication helps keep your systems strong and responsive.
Subscribe to my newsletter
Read articles from Amitesh Verma directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by