Database Scalability & Performance
 Oyetola Taiwo
Oyetola Taiwo
To improve the performance of databases serving applications involving a huge volume of data here are a few concepts you can use to improve the performance of the database and as well scale efficiently
Database Indexing:
This is a technique used to improve the speed of data retrieval operations on a database table by creating a data structure that allows for faster searches.
It will help locate desired records in a sublinear time. Without indexing, a full table scan would have to be done to be able to find desired records which would take a long time.
In using index there are trade-offs we are making:
Indexing only helps us optimize for faster reads, however there are some other things we are trading off
i. Additional space for storing the index tables
ii Speed of write operations as we need to write data to a table, we also need to update the index table.
Database Replication
This is a method of copying data from one database server to another, ensuring that all users have access to the same information. It helps in load balancing and provides a backup in case of server failure.
Supported by all modern databases
This helps to make more instances of our database available to our services/systems so that when an instance is down or inaccessible, our entire system is not down as the other available instances continue to serve our system till the instance that is out is restored. This helps ensure high availability
In addition to high availability, database replication can help us increase throughput. Say, we have millions of users, we can load balance our system in such a way that different servers reach out to different instances oof the database to retrieve/store information depending on how busy the instances are, while the internal working of the db ensures that the data across instances are consistent. This way we can serve a large amount of customers faster.
The trade-off here is the complexity involved in designing and maintaining a distributed database, ensuring hat the concurrent read and write don't cause problems.
Database Partitioning/Sharding
The data is split among different database instance
We can store more data when our data has been split into multiple instances. Queries can be performed in parallel.
With partitioning we get both better performance and higher scalability
The drawback is the complexity of splitting up the our data into instances running on different computers. It also introduces an overhead in that a routing has to be introducing before reaching the database layer so that data can be read from and updated to the right shard.
CAP Theorem:
CAP Theorem introduced by Prof Eric Brewer in the lates 90s states that "In the presence of a Network Partition, a distributed database cannot guarantee both Consistency and Availability and has to choose only one of them"
C = Consistency
A = Availability
P= Partition Tolerance
Consistency
Every read request receives either the most recent write or an error
Availability
This means if one or more nodes are down the node still returns the last update it received without throwing an error.
Partition Tolerance
A partition is a communication break within a distributed system. A lost or temporarily delayed connection between two nodes. Partition Tolerance means the system continues to work despite the network outage or delays on certains nodes.
CAP Theorem theorem tells us that when we configure a database we have to drop one of the properties in that we can have systems with:
i) Consistency and Availability - No Partition Tolerance
ii) Consistency and Partition Tolerance - No Availability
iii) Availability and Partition Tolerance - No Consistency
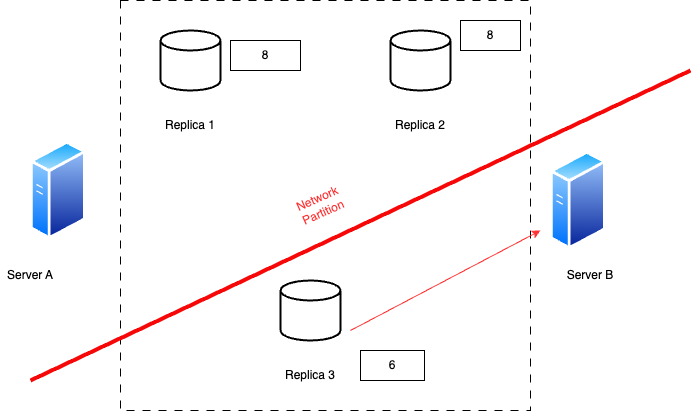
CAP theorem helps with make trade-offs.
From the diagram,
If we are to ensure Partition Tolerance which means that our system will continue to operate wether there are delays of network issues between our servers.
If we prioritise Availability over consistency, because there has been a disconnect for Replica 3, it does not have the latest count in its record. Availability will make sure that the number it has the last update is returned when server B tries to access it.
This is useful for thing like social media likes
If we choose consistency, the Replica 3 will respond with an error because it could at the time not communicate with other replicas to know if there is any update. So it returns an error because Consistency is the priority here.
Conclusion
These are some of the concepts to help scale databases and have a highly performant database. If you have questions please comment and connect with me on X(formerly twitter) @oyetola
Subscribe to my newsletter
Read articles from Oyetola Taiwo directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Oyetola Taiwo
Oyetola Taiwo
Oyetola Taiwo is a Software Engineer who is passionate about personal learning and growth and hence encourage others by sharing his knowledge on programming and devops practices