Enhancing Recommendations with Neural Collaborative Filtering
 Pranjal Chaubey
Pranjal Chaubey
Introduction to Recommender Systems
Ever wondered how Netflix always seems to know you better than your own friends? Or how Amazon recommends that one weird gadget you didn’t know you needed? Welcome to the world of recommender systems, the tech equivalent of a friend who’s way too into your personal preferences.
Recommender systems are the unsung heroes behind the curtain, tirelessly working to figure out what you might want to watch, buy, or listen to next. They’re like the personal shoppers of the digital world, except they don’t judge you for binge-watching the entire season of a reality show in one night. Whether you’re browsing on an e-commerce platform, discovering new tunes, or finding your next binge-worthy series, these systems are pulling the strings, making your life a little easier (and your wallet a little lighter).
But how do they work? Well, let’s just say there’s a lot more going on under the hood than simple guesswork. Recommender systems are powered by sophisticated algorithms that try to understand what makes you tick. And, much like your favorite coffee order, there’s more than one way to get the job done.
Understanding Key Terms in Recommender Systems
When exploring recommender systems, a few important concepts often come up. Let’s take a closer look at some key terms that help us better understand how these systems work.
Feedback: Explicit vs. Implicit
Explicit Feedback
Explicit feedback is straightforward—users directly tell the system what they like or dislike. For example, when you rate a movie with five stars, leave a review, or click the “like” button on a song, that’s explicit feedback. The system doesn’t have to guess your preferences because you’re clearly stating them.Implicit Feedback
Implicit feedback, on the other hand, is more subtle. The system observes your actions, like which products you browse, how long you watch a video, or what items you add to your cart. You’re not directly telling the system your preferences, but it infers them from your behavior. While this type of feedback is less direct, it’s often more abundant and can provide valuable insights.
Different Types of Recommendations
Personalized Recommendations:
Personalized recommendations are customized specifically for you, based on your previous actions and preferences. The system analyzes what you’ve liked, watched, or purchased and suggests new items that align with your interests. This is why your streaming service knows exactly what show to suggest next or why your shopping app always seems to have just the right product in mind.Non-Personalized Recommendations:
Non-personalized recommendations are one-size-fits-all. They’re the same for everyone, often based on what’s trending or universally popular. Examples include “Top 10” lists or bestsellers. While these recommendations are helpful, they don’t consider your individual tastes.Semi-Personalized Recommendations:
Semi-personalized recommendations strike a balance. They’re based on broad factors like demographics or location but don’t delve deeply into your specific preferences. For example, you might get suggestions for seasonal items based on where you live, even if the system doesn’t know your exact style.
Types of Recommender Systems
Recommender systems come in different forms, each with its own way of making suggestions. Here’s a look at the main types:
Collaborative Filtering (User Similarity):
Collaborative filtering works by finding patterns among users. It assumes that if you and another user have similar tastes, you might enjoy the same things. For example, if both you and another user liked Inception, the system might recommend another sci-fi movie that the other user enjoyed. It’s a recommendation strategy based on the idea that people with similar preferences will like similar items.Content-Based Filtering (Item Similarity):
Content-based filtering focuses on the items themselves rather than other users. It looks at what you’ve liked in the past and recommends similar items based on their features. If you enjoyed a documentary about deep-sea creatures, the system might suggest other nature documentaries or anything related to the ocean. This method tailors recommendations to your specific interests without relying on the preferences of others.Hybrid Methods:
Hybrid methods combine collaborative filtering and content-based filtering to create more accurate recommendations. By using multiple approaches, these systems aim to balance the strengths of each method. For example, they might use collaborative filtering to find items liked by similar users and content-based filtering to ensure the recommendations match your personal tastes. This way, they deliver suggestions that are more likely to be relevant and appealing.
Challenges in Traditional Recommender Systems
Traditional recommender systems, despite their widespread use, face several key challenges:
Scalability Issues:
Traditional algorithms like collaborative filtering struggle with scalability as the number of users and items grows. The computational resources required to process and update recommendations can become prohibitively large, leading to slower performance and less timely recommendations.Cold Start Problem:
Recommender systems rely on historical data to make predictions. When a new user joins or a new item is added, the system lacks the necessary data to make accurate recommendations. This is known as the cold start problem and can lead to poor user experience until the system gathers enough information about the new user or item.Sparse Data:
In many recommender systems, users interact with only a small fraction of the available items, creating sparse data matrices. This sparsity makes it difficult for traditional methods to find meaningful patterns, often resulting in less accurate recommendations.Linear vs. Non-Linear Data Patterns:
Traditional collaborative filtering methods, such as matrix factorization, are typically designed to capture linear relationships between users and items. However, user preferences and item characteristics often follow more complex, non-linear patterns. For example, a user’s preference for a movie might depend on multiple interacting factors like genre, director, and mood, which are not easily captured by linear models. This limitation can lead to suboptimal recommendations, as traditional systems may oversimplify the relationships between users and items.
Introduction to Neural Collaborative Filtering (NCF)
Neural Collaborative Filtering (NCF) is an advanced approach that addresses many of the challenges faced by traditional recommender systems, especially the difficulty in modeling non-linear data patterns.
Overview:
NCF replaces the linear models used in traditional collaborative filtering with deep neural networks that can capture complex, non-linear interactions between users and items. By leveraging deep learning, NCF overcomes the limitations of traditional methods, providing more accurate and personalized recommendations even in the face of challenges like sparse data and cold starts.
Architecture:
The NCF architecture consists of two main components: GMF (Generalized Matrix Factorization) and MLP (Multi-Layer Perceptron). Let’s break down their roles in the model:
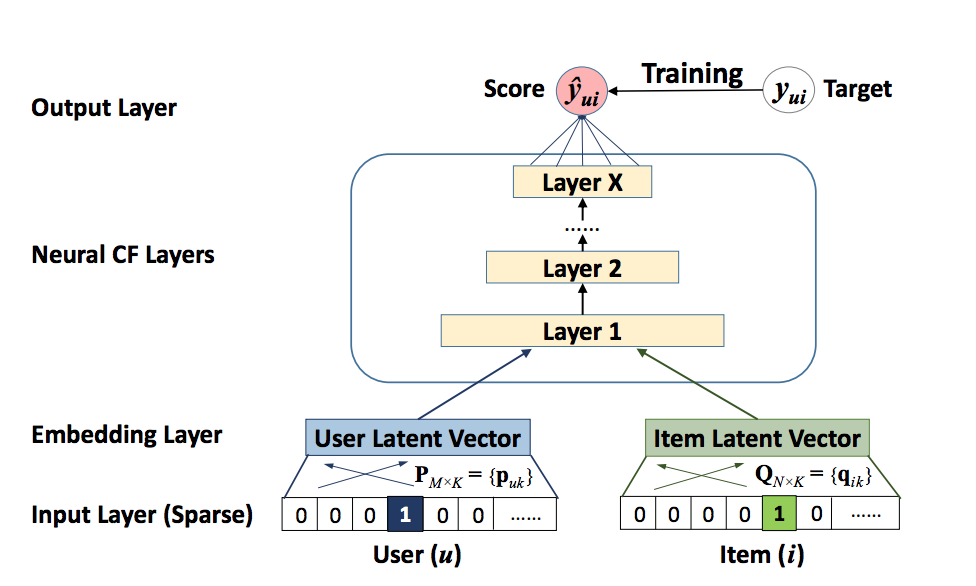
Generalized Matrix Factorization (GMF):
GMF is a generalization of the traditional matrix factorization technique used in collaborative filtering. In matrix factorization, users and items are represented as latent vectors, and their dot product predicts the interaction (e.g., a rating). GMF extends this concept by introducing a learned weight for each interaction, allowing the model to capture more complex relationships.Embedding Layers:
Similar to traditional matrix factorization, GMF uses embedding layers to represent users and items as dense vectors. However, instead of just taking the dot product, GMF applies element-wise multiplication to these vectors, which is then combined with learned weights to produce an interaction score.Output:
The output of GMF is a single scalar value representing the predicted interaction strength between a user and an item.Multi-Layer Perceptron (MLP):
The MLP component in NCF is responsible for capturing complex, non-linear interactions between users and items. While GMF handles the linear aspects of user-item relationships, MLP dives deeper by applying multiple layers of non-linear transformations, enabling the model to learn more intricate patterns.Concatenation Layer:
The MLP starts by concatenating the user and item embeddings, rather than multiplying them. This combined vector is then fed into a series of fully connected layers (the MLP), each of which applies non-linear activation functions like ReLU. These layers progressively learn higher-order interactions between users and items.Output:
The final output of the MLP is a vector that captures complex features of the user-item interaction, which will later be combined with the GMF output.Fusion Layer (Final Prediction):
Combining GMF and MLP:
After both GMF and MLP have processed the user and item embeddings, their outputs are merged to produce a final prediction. This fusion can be done in various ways, such as adding or concatenating the GMF and MLP outputs. The combined output leverages the strengths of both approaches—GMF’s linear modeling and MLP’s non-linear interactions—to predict the final recommendation score.Final Output
The merged result is passed through a final layer (usually with a sigmoid activation function) to produce the ultimate prediction. This could be a rating, a ranking score, or the probability of a user interacting with an item.
Implementing NCF in TensorFlow
Data Preparation: Preprocessing and Generating Samples
In building a Neural Collaborative Filtering (NCF) model using the MovieLens dataset, effective data preparation is crucial. This involves preprocessing the dataset and generating interaction samples categorized into positive and negative interactions. Here's a summary of the process:
Categorizing Interactions:
Positive Interactions (Label = 1):
Hard Positive: Movies rated above 4 stars, indicating a strong preference.
Soft Positive: Movies rated between 3 and 4 stars, showing moderate interest.
Negative Interactions (Label = 0):
Hard Negative: Movies rated below 2 stars, indicating clear disinterest.
Soft Negative: Movies rated between 2 and 3 stars, suggesting mild disinterest.
Generating the Training Data:
Positive Samples: Extract all hard and soft positive interactions for each user, labeled as
1.Negative Samples: For each positive sample, generate four corresponding negative samples, including both hard and soft negatives, labeled as
0.
Balancing the Dataset:
1:4 Ratio of Positive to Negative Samples: For every positive sample, there are four negative samples. This ratio helps in balancing the dataset and prevents the model from being biased towards predicting either class too frequently.
Diverse Negative Samples: Include a mix of hard and soft negatives to help the model differentiate between items the user is unlikely to interact with and those they might consider.
Final DataFrame Structure:
- The dataset will include columns for
user_id,item_id, andinteraction_label, with each user’s data featuring positive samples and their associated negative samples, maintaining the 1:4 ratio.
- The dataset will include columns for
By preparing the data with this approach, the NCF model is well-equipped to learn from both positive and negative interactions, leading to more accurate and personalized recommendations.
# -*- coding: utf-8 -*-
"""Neural_Collaborative_Filtering.ipynb
Automatically generated by Colab.
Original file is located at
https://colab.research.google.com/drive/1XegSnw0tecn4emqKmQtVxD0Bxwk9ewDf
"""
!pip install kaggle==1.5.12
!mkdir -p ~/.kaggle
!cp kaggle.json ~/.kaggle/
!chmod 600 /content/kaggle.json
!kaggle datasets download -d rounakbanik/the-movies-dataset
!unzip the-movies-dataset.zip
import pandas as pd
import numpy as np
ratings_df = pd.read_csv('/content/ratings.csv')
# drop time stamp
ratings_df.drop('timestamp', axis=1, inplace=True)
print(f"Ratings_df shape : {ratings_df.shape}")
print("\n")
print("-----------------------------------------")
print("\n")
print(f"describe : \n {ratings_df.describe()} ")
print("\n")
print("-----------------------------------------")
print("\n")
print(f"info : \n {ratings_df.info()}")
print("\n")
print("-----------------------------------------")
print("\n")
print(f"Intitally unique user`s : {ratings_df['userId'].nunique()}")
print("\n")
print("-----------------------------------------")
print("\n")
# due to size, we are only going to use first 500 unique users
# ratings_df = ratings_df[ratings_df["userId"].isin(ratings_df["userId"].unique()[:500])]
# print("\n")
# print(f"After filtering, Ratings_df shape : {ratings_df.shape}")
# print("\n")
# print("-----------------------------------------")
# print("\n")
# print(f"After filtering, unique user`s : {ratings_df['userId'].nunique()}")
# print("\n")
# print("-----------------------------------------")
"""# Creating an Interaction Matrix
## Positive Interaction -> Will be labelled as 1
### Hard Positives: rating >= 4
### Soft positive: 4>rating>= 3
## Negative Interaction -> will be labelled as 0
### Soft Negative: 3>rating>=2
### Hard Negative: 2>rating>=1 or less than 1
---
## Ratio of positive : negative for every user : 1:4
---
"""
hardpositve = 4.0
softpositive = 3.0
softnegative = 2.0
hardnegative = 1.
ratings_df["interaction"] = 0
ratings_df.interaction[ratings_df["rating"] >= softpositive] = 1
positive_samples = ratings_df[ratings_df["interaction"] == 1]
negative_samples = ratings_df[ratings_df["interaction"] == 0]
print(f"positive_samples shape : {positive_samples.shape}")
print(f"negative_samples shape : {negative_samples.shape}")
negative_grouped = negative_samples.groupby('userId')
count = 0
for userId, group in negative_grouped:
if count >= 3:
break
print(f"User ID: {userId}")
print(group)
print("--------------------")
count += 1
"""
Some groups have a length of fewer than 4. So we only include groups where len >= 4. only these user
will be added to final balanced dataset .
"""
negative_grouped_with_size4 = negative_grouped.filter(lambda x: len(x) >= 4)
# convert the negative_grouped_with_size4 df to group_by object
negative_grouped = negative_grouped_with_size4.groupby('userId')
count = 0
for userId, group in negative_grouped:
if count >= 3:
break
print(f"User ID: {userId}")
print(group)
print("--------------------")
count += 1
# number of unique user_id in neagtive grouped. we will only use first 5000 unique users.
len(negative_grouped['userId'].unique())
# unique instance of positive interactin
unique_positive_samples = positive_samples.drop_duplicates(subset=['userId'])
print(f"unique_positive_samples shape : {unique_positive_samples.shape}")
unique_positive_samples.head()
balanced_list = []
for user_id in list(negative_grouped.groups.keys())[:5000]:
# Append the positive samples for the user
balanced_list.append(unique_positive_samples[unique_positive_samples['userId'] == user_id])
# Append the negative samples for the user
negative_samples_for_user = negative_grouped.get_group(user_id)
# Sample 4 negative samples for the user
balanced_list.append(negative_samples_for_user.sample(4, replace=False))
# Concatenate all the samples into a single DataFrame
balanced_df = pd.concat(balanced_list).reset_index(drop=True)
print(balanced_df)
positive_count = len(balanced_df[balanced_df["interaction"] == 1])
negative_count = len(balanced_df[balanced_df["interaction"] == 0])
print(f"Number of positive samples: {positive_count}")
print(f"Number of negative samples: {negative_count}")
ratio = positive_count / negative_count
print(f"Ratio of positive to negative samples: {ratio}")
Model Building: Constructing the NCF Model
With the data preprocessed, it’s time to build the NCF model using TensorFlow. The model consists of embedding layers, MLP layers, and an output layer.
from keras.layers import Input, Embedding, Flatten, concatenate, Dense, Dropout
from keras.models import Model
from keras.callbacks import EarlyStopping
from keras.regularizers import l2
def build_model(num_users, num_items, embedding_dim):
user_input = Input(shape=(1,))
item_input = Input(shape=(1,))
# GMF Part
user_embedding_gmf = Embedding(num_users, embedding_dim)(user_input)
item_embedding_gmf = Embedding(num_items, embedding_dim)(item_input)
gmf_vector = Flatten()(user_embedding_gmf) * Flatten()(item_embedding_gmf)
# MLP Part
user_embedding_mlp = Embedding(num_users, embedding_dim)(user_input)
item_embedding_mlp = Embedding(num_items, embedding_dim)(item_input)
mlp_vector = concatenate([Flatten()(user_embedding_mlp), Flatten()(item_embedding_mlp)])
# mlp_vector = Dense(64, activation='relu',kernel_regularizer=l2(0.001))(mlp_vector)
# mlp_vector = Dropout(0.3)(mlp_vector) # Dropout layer added here
mlp_vector = Dense(32, activation='relu',kernel_regularizer=l2(0.001))(mlp_vector)
mlp_vector = Dropout(0.3)(mlp_vector) # Dropout layer added here
mlp_vector = Dense(16, activation='relu',kernel_regularizer=l2(0.001))(mlp_vector)
mlp_vector = Dropout(0.3)(mlp_vector) # Dropout layer added here
# Concatenate GMF and MLP parts
ncf_vector = concatenate([gmf_vector, mlp_vector])
# Final output layer
output = Dense(1, activation="sigmoid")(ncf_vector)
# Build and compile the model
ncf_model = Model(inputs=[user_input, item_input], outputs=output)
ncf_model.compile(optimizer="adam", loss="binary_crossentropy", metrics=["accuracy"])
ncf_model.summary()
return ncf_model
# Example usage
num_users = balanced_df.userId.max() + 1
num_items = balanced_df.movieId.max() + 1
embedding_dim = 50
model = build_model(num_users, num_items, embedding_dim)
early_stopping = EarlyStopping(monitor='val_loss', patience=3, restore_best_weights=True)
model.fit([X_train.iloc[:, 0], X_train.iloc[:, 1]], y_train, epochs=10, batch_size=64,
validation_data=([X_test.iloc[:, 0],X_test.iloc[:, 1]], y_test),callbacks=[early_stopping])
loss, accuracy = model.evaluate([X_test.iloc[:, 0], X_test.iloc[:, 1]], y_test)
print(f'Test Accuracy: {accuracy:.4f}')
Issues With NFC
Neural Collaborative Filtering (NCF) models, while powerful, can face several issues that might impact their effectiveness. Here are some common challenges associated with NCF:
1. Scalability
Challenge: NCF models can be computationally expensive and memory-intensive, particularly when dealing with large datasets. Training deep neural networks on massive user-item interaction matrices can require substantial resources.
Solution: Employing distributed training, efficient data processing pipelines, and hardware accelerators like GPUs can help manage scalability issues.
2. Cold Start Problem
Challenge: NCF models struggle with new users or items that have limited interaction data. The model has insufficient information to make accurate predictions for these "cold" entities.
Solution: Incorporating content-based features or leveraging hybrid methods that combine collaborative filtering with content-based approaches can mitigate cold start problems.
3. Sparse Data
Challenge: Interaction matrices in recommendation systems are often sparse, meaning that users have interacted with only a small fraction of available items. This sparsity can hinder the model’s ability to make accurate recommendations.
Solution: Techniques like matrix factorization or advanced imputation methods can help address data sparsity by predicting missing interactions and leveraging latent factors.
4. Overfitting
Challenge: Deep learning models, including NCF, are prone to overfitting, especially when trained on limited data. Overfitting occurs when the model performs well on training data but poorly on unseen data.
Solution: Regularization techniques, dropout, and proper validation strategies can help prevent overfitting. Additionally, employing early stopping during training can be beneficial.
5. Complexity of Model Tuning
Challenge: Tuning the hyperparameters of an NCF model, such as the number of layers, units per layer, and learning rate, can be complex and time-consuming.
Solution: Using automated hyperparameter optimization techniques, such as grid search or Bayesian optimization, can simplify the tuning process and improve model performance.
6. Interpretability
Challenge: Deep learning models, including NCF, are often seen as "black boxes," making it difficult to interpret how recommendations are generated.
Solution: Incorporating explainability techniques and models that provide insight into the features and interactions influencing recommendations can help address this issue.
7. Handling Non-Linear Relationships
Challenge: While NCF can capture complex non-linear relationships, it may struggle with certain types of non-linearity or interactions if not properly designed.
Solution: Experimenting with different architectures, such as deeper networks or incorporating attention mechanisms, can enhance the model's ability to handle non-linear relationships effectively.
By being aware of these challenges and implementing appropriate strategies, you can improve the performance and robustness of NCF models in recommendation systems.
Conclusion
Neural Collaborative Filtering (NCF) enhances recommendation systems by combining deep learning with traditional collaborative filtering, enabling more personalized and sophisticated recommendations. While NCF models offer powerful insights into user preferences, they come with challenges such as scalability, cold start problems, data sparsity, and overfitting.
Addressing these issues involves efficient data handling, hybrid approaches, and careful model tuning. Despite these challenges, NCF's ability to capture complex patterns and provide nuanced recommendations makes it a valuable tool for modern recommendation systems. By effectively managing its limitations, NCF can significantly improve user experiences with more accurate and relevant suggestions
Subscribe to my newsletter
Read articles from Pranjal Chaubey directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Pranjal Chaubey
Pranjal Chaubey
Hey! I'm Pranjal and I am currently doing my bachelors in CSE with Artificial Intelligence and Machine Learning. The purpose of these blogs is to help me share my machine-learning journey. I write articles about new things I learn and the projects I do.