Introducing GKE Enterprise
 Tim Berry
Tim Berry
This is the first in a new series of long-form posts exploring the features of GKE Enterprise, formerly known as Anthos. GKE Enterprise is an additional subscription service for GKE that adds configuration and policy management, service mesh and other features to support running Kubernetes workloads in Google Cloud, on other clouds and even on-premises. Over the coming months, I'll try to explore all of these features in an easy-to-digest way.
Introduction
Kubernetes is one of the most successful open-source software stories in the history of computing. Its rapid development and adoption can be attributed to the fact that it solves numerous problems that have faced developers and systems administrators for many years. If you have worked in technology for over 10 years, you may recall previous attempts to solve the fundamental problems of deploying, scaling, and managing software, which took various forms from simple scripting to package and configuration management systems, each with its own quirks and compromises. As these attempted solutions were developed, the problems themselves got more complex, as demand for software and services increased by orders of magnitude, complicating the way that we build and deploy software over distributed systems, often in other people’s datacenters.
As a way to package software, container technology was quickly adopted thanks to the developer-friendly toolset developed by Docker, but a logical and consistent way to orchestrate containers was still missing until Kubernetes. Based on Google’s extensive experience running software at an enormous scale over thousands of commodity servers, Kubernetes finally gave us a way to logically deploy, scale, and manage containerized software.
But progress never stops, and with it, complexity always increases. We’ve moved past the early days of mass cloud adoption and we live in a world where complex distributed systems need to run reliably on any combination of cloud or on-premises platforms. These new problems have mandated new solutions and new technologies such as service mesh and a distributed approach to authorization and authentication. Fully managed Kubernetes services evolved to support these new challenges with the launch of Google Cloud’s Anthos, which has now matured into GKE Enterprise.
Of course, not all deployments need to be this complex, and if you’re lucky enough to be working on small-scale projects with moderately sized clusters, you may not need all of these extra features. You certainly should not try to apply over-engineered solutions to every problem, just for the sake of playing with the latest cool new technologies. One of the approaches I want to take in this series is to identify the use case for every new tool, so you can appreciate where – and where not – to use it.
This brings us to our overall objective. Despite the increased complexity I’ve described, thankfully these new technologies are easy enough to integrate into your projects because they operate within Kubernetes’ fundamentally logical model: a clear set of APIs and a declarative approach to using them.
In this series, we’ll explore each advanced feature in a sensible order, explaining what it's for and how you can use it in an approachable, no-nonsense way. We’ll start by revisiting some core Kubernetes topics to set the scene for what we’re going to learn, but we’re not going to teach Kubernetes from scratch. If you don’t already have Kubernetes experience under your belt, you might want to get some more practice in before exploring GKE Enterprise!
A quick recap: Kubernetes Architecture
Like I said, you should already be reasonably familiar with Kubernetes, so we’re not going to deep dive into its architectural nuts and bolts here. However, the topic is worth revisiting to explain the limits of the architecture that the core Kubernetes project cares about, where those sit within managed environments, and how the advanced features of GKE Enterprise extend them to other architectures.
To recap, Kubernetes generally runs on clusters of computers. You can of course run all of its components on a single computer if you wish, but this would not be considered a production environment.
Computers in a Kubernetes cluster are referred to as nodes. These can be provided by physical (bare metal) machines or virtual machines. Nodes provide the raw computing power and the container runtimes to actually run our containerized workloads. Nodes that only run our workloads are often referred to as worker nodes, and there are mechanisms that exist to group worker nodes of the same configuration together. However, we also need some computers to run the Kubernetes control plane.
The control plane can be thought of as Kubernetes’ brain to a certain extent. The control plane’s components make decisions about the cluster, store its state, and detect and respond to events. For example, the control plane will receive instructions describing a new workload and decide where the workload should be run. In production environments, it's common to isolate the control plane to its own set of computers, or even run multiple copies of a control plane for high availability.
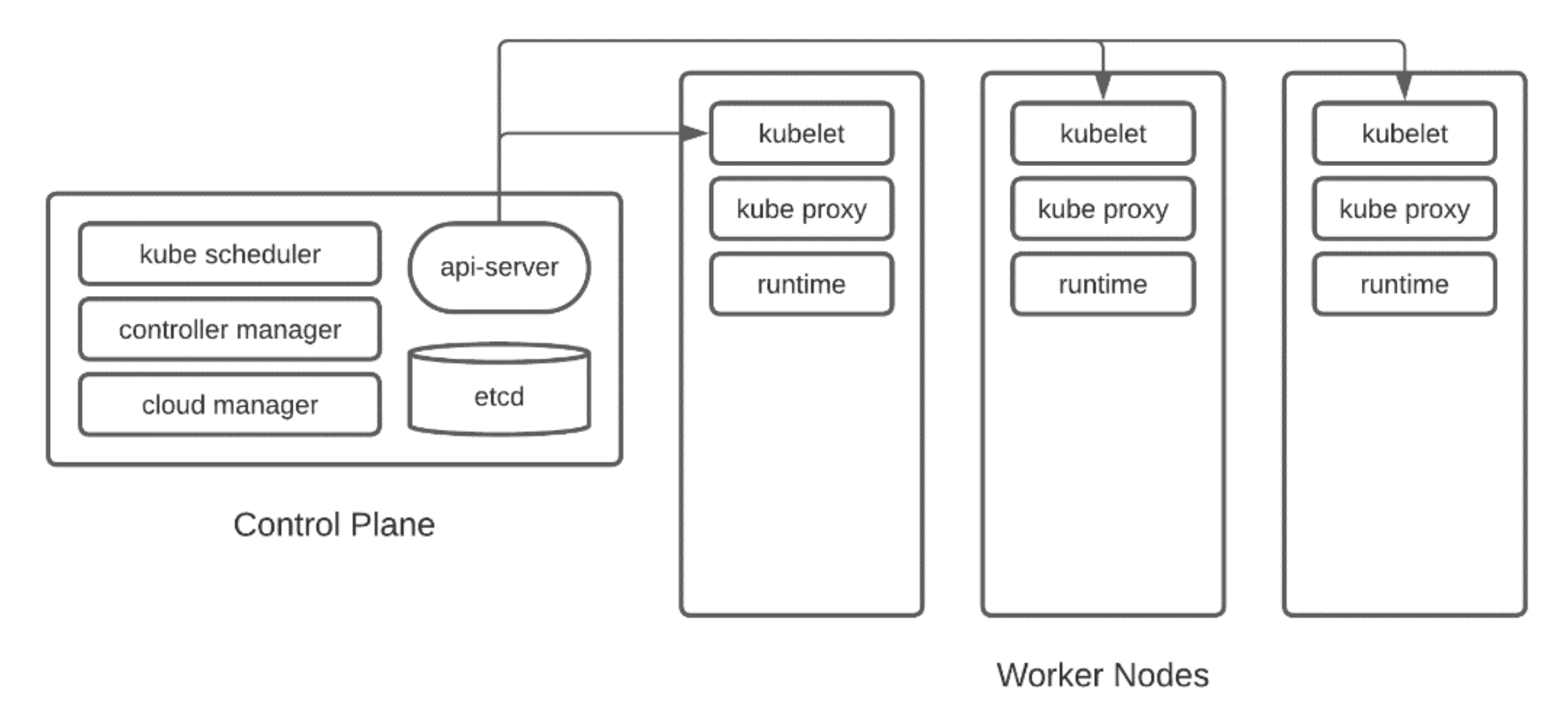
As a reminder, the control plane runs these components:
kube-apiserver: The front-end of the control plane, exposing the Kubernetes API.
etcd: The consistent key-value store for all cluster data such as configuration and state.
kube-scheduler: A watch loop that keeps an eye out for workloads without an assigned node, so that it can assign one to them. Influencing the scheduler is an important but complex topic.
kube-controller-manager: The component that runs controller processes. These are additional watch loops for tasks like monitoring nodes and managing workloads.
cloud-controller-manager: If you’re running your cluster in the cloud, this component links Kubernetes to your cloud provider’s APIs.
Each worker node will run these components:
kubelet: Kubernetes’ agent on each node and the point of contact for the API server. The kubelet agent also manages the container runtime to ensure the workloads it knows about are actually running.
kube-proxy: A network proxy to implement Kubernetes service concepts (more on those in a moment).
Container runtime: The underlying container runtime responsible for actually running containers (such as containerd, CRI-O, or other supported runtime).
Remember that Kubernetes is software that runs on your nodes. Kubernetes itself does not manage the actual nodes, whether they are physical or virtual. If you build Kubernetes for yourself, you will need to provision those computers and operating systems, and then install the Kubernetes software, although the Kubernetes project does provide tools like kubeadm to help you do this. When Kubernetes is running, it can only communicate with its other components and can’t directly manage a node, although the node controller component does at least notice if a node goes down.
It’s for this reason that managed services for Kubernetes have gained so much popularity. Services such as Google Kubernetes Engine (GKE) provide management of the infrastructure required to run Kubernetes as well as the software. For example, GKE can deploy nodes, group them together, manage and update the Kubernetes software on them, auto-scale them and even heal them if they become unhealthy. But this is an important distinction – GKE is managing your infrastructure, while Kubernetes is running on that infrastructure and managing your application workloads.
Within standard Kubernetes and most managed services, your Kubernetes cluster is the perimeter of your service, although of course you can have many clusters, all separately managed. As we’ll learn soon, GKE Enterprise allows us to extend those boundaries and manage multiple clusters in any number of different platforms, all with a single management view and development experience. But before we get into those topics, let’s refresh our memory on some more basic Kubernetes principles. If you’re a Kubernetes expert and you’re just here for the GKE Enterprise specifics, feel free to skip this section!
Fundamental Kubernetes Objects
Let's revisit some fundamental Kubernetes objects, because we need a solid understanding of these before we learn how to extend them with GKE Enterprise’s advanced features in future posts. If you live and breathe Kubernetes on a daily basis, feel free to skip this section! Alternatively, if you're not comfortable with any of them, a good place to start is https://kubernetes.io/docs/concepts/overview/working-with-objects/
Pods
Pods are the smallest deployable object on Kubernetes, representing an application-centric logical host for one or more containers. Arguably, their advanced patterns for colocating sidecar, init, and other patterns of containers provided the flexibility that pushed Kubernetes ahead of other orchestration platforms. The key design principle of Pods is that they are the atomic unit of scale. In general, you increase the number of Pods (not the number of containers inside a Pod) to increase capacity. Aside from some specific circumstances, it’s very rare to deploy an individual Pod on its own. Logical controllers such as Deployments and StatefulSets are much more useful.
ReplicaSets
ReplicaSets are sets of identical Pods, where each Pod in the set shares exactly the same configuration. ReplicaSets pre-date other controller objects, and even though we never explicitly create a ReplicaSet on its own, it is worth understanding their purpose within those other logical objects. You can think of a ReplicaSet as a version of a configuration. If you change a Deployment for example, a new ReplicaSet is created to represent that new version. Because ReplicaSets are just versions of configuration, we can keep a history of them in the Kubernetes data store, and easily roll back versions.
Deployments
Deployments are one of the most commonly used controller objects in Kubernetes. Controller objects are useful because the control plane runs a watch loop to ensure that the things you are asking for in your object actually exist. This is the fundamental concept of declarative configuration in Kubernetes. Individual Pods, for example, may come and go, and to a certain extent, the control plane doesn’t care. But if your Deployment object states that you should have 5 Pods of a specific configuration, the Deployment controller which make sure that this remains true.
Deployments are designed specifically for stateless workloads. This means that the container itself must not attempt to store or change any state locally and that each Pod in the Deployment must be an anonymous identical replica. Of course, you can still affect the state as long as it lives somewhere else, such as in a networked storage service or database. Stateless deployments offer you the most flexibility because your Pods can be scaled – effectively, deleted, and recreated – at will.
StatefulSets
For workloads that are required to manage state, a StatefulSet provides most of the logic of the Deployment object but also introduces some guarantees. Pods are scaled up and down in a logical order, do not have to be identical, and are guaranteed a unique identity. A common design pattern for stateful deployments is to have the first Pod serve as a controller and additional Pods act as workers. Each Pod can determine its own purpose based on its identity and local hostname. Additionally, storage volumes can be attached to Pods on a one-to-one basis.
Services
With Pods coming and going all the time, and workloads being served by multiple Pods at any given time, we need a way to provide a fixed network endpoint. This is the purpose of the Service object. Services come in a few different forms, but all of them provide a fixed internal IP available to the cluster that can route traffic in a round-robin fashion to a group of Pods. The group of Pods is determined by a label selector. For example, if your Service is configured to route traffic to Pods that match the labels app=web and env=prod, all Pods that contain these labels in their metadata will be included in the round-robin group. It’s a very low-level object that we rarely use on its own, but it’s important to understand.
Ingress
Service objects have been used historically to provide external access to workloads running in a Kubernetes cluster, often through the LoadBalancer type of Service, which attaches an external IP address or an external service, depending on where you’re running your cluster. However, there are limitations to using a low-level object that provides such a direct mapping of traffic, so the Ingress object was created.
The Ingress object is designed for HTTP and HTTPS traffic and offers more features and flexibility than the simple Service, such as the ability to route traffic to different back-end services based on request paths. Ingress objects themselves are used in conjunction with an Ingress Controller, which is typically a Deployment of some kind of proxy software, such as the NGINX web server. Depending on which server you use as your Ingress Controller, you can also add annotations to your Ingress objects, for example, to invoke NGINX rewrite rules.
The Ingress pattern has been extremely useful and popular, but due to its limited focus on HTTP the feature has now been frozen, meaning it will not receive any further development. Instead, it has inspired a new approach that takes the same flexible design ideas from Ingress but handles all kinds of traffic.
Gateway API
The Gateway API is the project that enables this approach. Notably, this is an add-on for Kubernetes, not part of its default supported API groups. Gateway API provides three new custom API resources:
Gateway: An object representing how an external request should be translated within the Kubernetes cluster. A Gateway resource specifies protocols and ports and can also offer granular control over allowed routes and namespaces.
HTTPRoute: An object representing how traffic coming through a gateway should be directed to a back-end service, including paths and rules to match. Other protocol-specific objects (such as GRPCRoute) are also available.
GatewayClass: An object representing the controller that provides the actual functionality for gateways, similar to the Ingress Controller we described earlier. Gateways must reference a GatewayClass.
So we've refreshed our memory on some of the most commonly used Kubernetes objects. Of course, there are many more that we haven’t touched on, however, it was important to go back to basics and build up to the Gateway API as it’s a key component of many GKE Enterprise features such as service mesh. Next, to understand where GKE Enterprise fits in with the portfolio of Google Cloud services, let’s discuss the different editions of GKE available.
Anthos, Multi-cloud and GKE Editions
Google Kubernetes Engine (GKE) has evolved through many iterations over the years. As we previously mentioned, Google’s own internal container orchestration work was what originally inspired the open-source project Kubernetes, which was released to the world in June 2014. Google’s cloud platform at the time had a handful of core services, but fast forward to 2017, and something called Google Container Engine was launched at Google’s annual Next conference.
This new service promised to take all of the convenience and power of the Kubernetes project and apply a fully managed service for the infrastructure required to run it, for example by auto-scaling and auto-healing the virtual machines required to run a cluster. It started with a fantastic success story – the global phenomenon of Pokemon Go had recently launched with all of its backend service running on Google Container Engine (with lots of help from Google engineers). Later the same year, the service was renamed more accurately as Google Kubernetes Engine and then certified by the Cloud Native Computing Foundation as a certified Kubernetes platform, guaranteeing its compatibility with open-source Kubernetes implementations.
Over the following years, Google continued to improve GKE by offering the latest versions of Kubernetes as part of their managed service. During this time Google Cloud moved to position itself as a vendor that supported hybrid and multi-cloud portability and began to develop extensions to GKE that allowed it to run nodes on computers that ran in locations other than their own cloud. This new service launched under the product name of Anthos in 2019.
Anthos, as it turns out, was more of a name for a subscription service that you had to pay for rather than an individual product. Paying for Anthos gave you access to new features including GKE On-Prem and Anthos Migrate. GKE On-Prem allowed you to run Kubernetes clusters on bare-metal and VMWare servers which were managed by GKE. Anthos Migrate would (in theory) allow you to migrate virtual machines to stateful Pods on a GKE cluster. Anthos was rough around the edges on launch, but soon added even more useful features such as a managed Istio service mesh, a managed KNative implementation (known as Cloud Run for Anthos), policy agents, and more.
Over the years more features were developed for Anthos, and occasionally they would drift into the core GKE service – and back out again. This occurred for the service mesh features as well as a new service for binary authorization of containers. Support for running clusters in AWS and Azure was added, causing some confusion with the “On-Prem” product name. Anthos rapidly grew into an extremely powerful platform for running GKE anywhere, but its original product name now seemed somewhat incongruous.
From Anthos to GKE Enterprise
So towards the end of 2023, Google announced the launch of GKE Enterprise, which essentially means two things. Firstly, it’s a normalization of everything Anthos was but under the proper GKE product banner. Secondly, it’s a quiet deprecation of the Anthos brand. For most intents and purposes, particularly when it comes to features, technology, or documentation, you can consider the two terms as interchangeable. The main difference is that now Anthos is no longer a separate thing adjacent to GKE, it is an edition of GKE. GKE Enterprise to be exact!
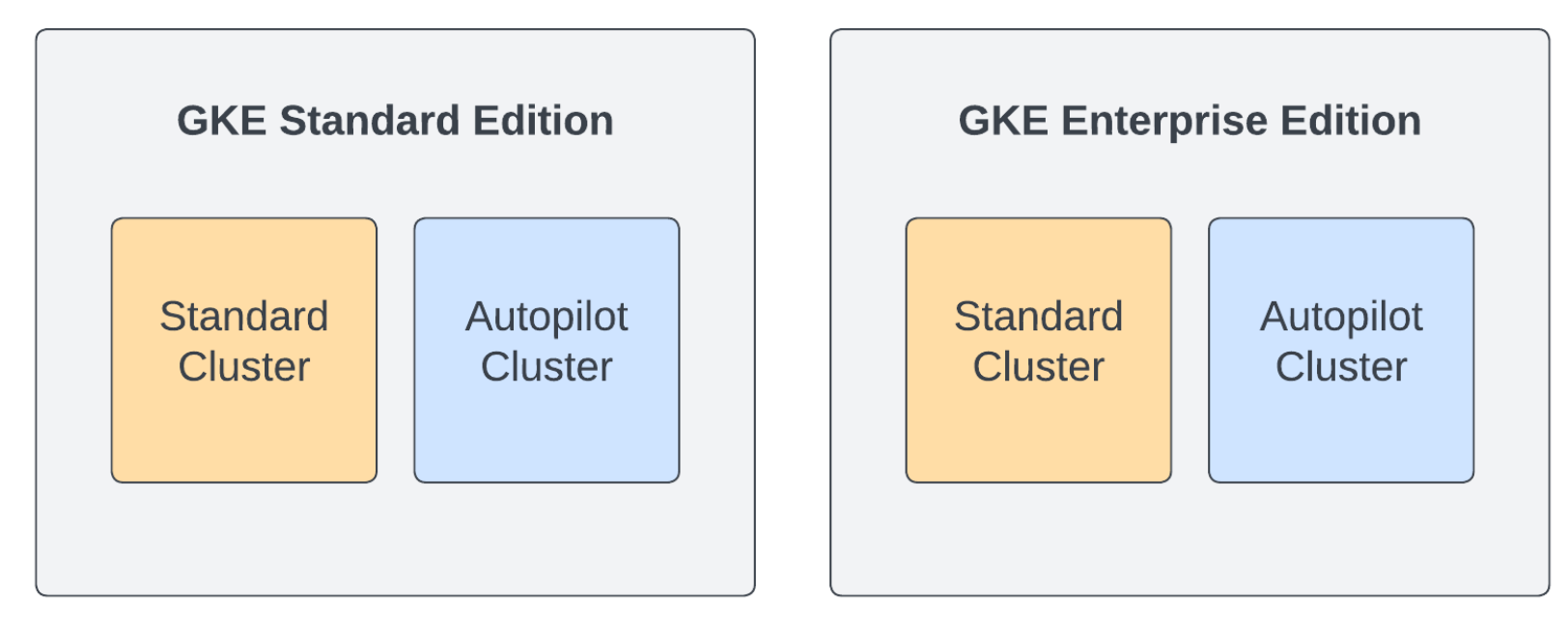
Now, when choosing how to use GKE as a platform, you now have the two options of GKE Standard and GKE Enterprise. At a very high level, GKE Standard provides an advanced managed Kubernetes offering within Google Cloud, while GKE Enterprise extends the offering across multiple clouds and bare metal and adds additional features.
The most important features are presented for comparison in the table below:
| GKE Standard | GKE Enterprise |
| Fully automated cluster lifecycle management | Fully automated cluster lifecycle management |
| Certified open-source compliant Kubernetes | Certified open-source compliant Kubernetes |
| Workload and cluster auto-scaling | Workload and cluster auto-scaling |
| GitOps-based configuration management | |
| Managed service mesh | |
| Managed policy controller | |
| Fleet management | |
| GKE on AWS, Azure, VMWare and Bare Metal | |
| Multi-cluster ingress | |
| Binary authorization |
Pricing changes all the time in the competitive world of cloud computing, but at the time of writing GKE Standard charges a fee per cluster hour, while GKE Enterprise charges a fee per CPU hour.
What about Autopilot?
A separate development in the world of GKE was the launch of Autopilot in 2021, an attempt to bring some of the convenience of the serverless world to Kubernetes. When creating a normal GKE cluster you must make decisions about the type, size, and number of your nodes. You may or may not enable node-autoscaling, but you normally have to continue to manage the overall capacity of your cluster during its lifetime.
With Autopilot, a cluster is fully managed for you behind the scenes. You no longer have the need to worry about nodes, as they are automatically scaled to the correct size for you. All you have to do is supply your workload configurations (for example, Deployments), and Autopilot will make all the necessary decisions to run them for you.
Confusingly, this means that GKE Standard is now an edition of GKE, as well as a type of cluster. A GKE Standard cluster is a cluster where you manage the nodes as well as the workloads, and these clusters can run in either edition of GKE, Standard, or Enterprise. Autopilot clusters are also supported in both the Standard and Enterprise editions of GKE. However, at the time of writing, Autopilot clusters are only supported inside Google Cloud.
Summary
In this first post, we have refreshed our memories on the basic architecture of a Kubernetes cluster and some of the fundamental component objects that are used to build workloads and services. Having these concepts fresh in our memory will be useful as we introduce the advanced features of GKE Enterprise throughout the rest of the series.
We have also clarified the different versions and editions of GKE, and where Anthos fits into the equation. Hopefully, this all makes sense now, despite the best efforts of Google’s product managers! Importantly, we’ve established what makes GKE Enterprise different, and now we’re ready to start learning how to use it. In the next post, we’ll begin by enabling GKE Enterprise and configuring our first GKE clusters.
Subscribe to my newsletter
Read articles from Tim Berry directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by