ETL Process: A Beginner’s Guide 🚶♂️➡️
 Shreyash Bante
Shreyash Bante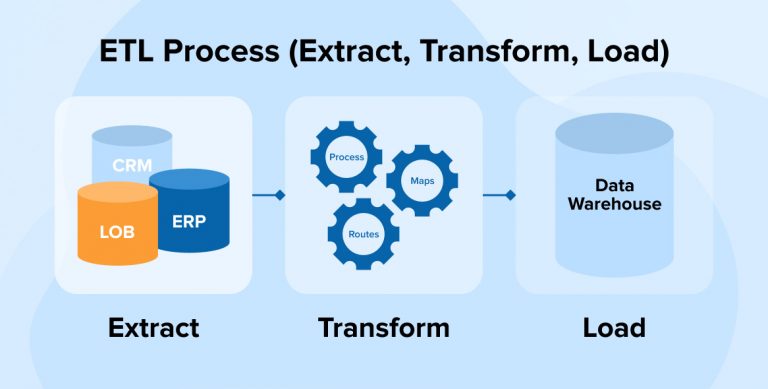
What is ETL?
ETL stands for Extract, Transform, Load. It is a core process in data engineering used to integrate data from multiple sources, transform it into a usable format, and load it into a target system, such as a data warehouse or data lake.
Extract: The first step involves extracting data from various source systems. These sources can be databases, files, APIs, or streaming data. The goal is to gather raw data in its original form without any modifications.
Transform: Once data is extracted, the next step is to transform it. Transformation involves cleaning, filtering, enriching, aggregating, and formatting the data to meet the analytical requirements. This step ensures that data is structured and standardized, making it suitable for analysis.
Load: The final step is loading the transformed data into a destination system. This could be a data warehouse, data lake, or another type of data store where it can be accessed for reporting, analytics, or further processing.
Importance of ETL
Data Integration: ETL helps integrate data from multiple sources into a single, unified view.
Data Quality: Transformation steps ensure the data is clean, consistent, and formatted correctly.
Scalability: ETL processes can handle large volumes of data, making them suitable for big data applications.
Timely Access: Regular ETL processes ensure that data is updated and available for timely decision-making.
ETL in Apache Spark
Apache Spark is widely used for ETL processes due to its ability to process large datasets quickly and efficiently across distributed computing clusters. Spark provides robust APIs for all three phases of ETL, allowing for easy integration with a wide range of data sources and formats.
By leveraging Spark for ETL, organizations can build scalable data pipelines that efficiently handle massive amounts of data, supporting real-time analytics and decision-making.
Extract ⭐ :
As it sounds you extract data from various sources. How can you do it? Write code that connects to a database or an API call which gets you the data. there are tools like Azure Data Factory which lets you authenticate to a source securely and copy data from there, Multiple ways are available. Sometimes Different teams in a project share your data to your Storage accounts. The extract process can be of different forms depending on your client's requirements.
1. Understanding Data Sources
The extract phase involves retrieving data from various sources. Spark provides a unified API to read data from a wide range of formats and storage systems, such as:
Relational Databases: MySQL, PostgreSQL, Oracle, SQL Server, etc.
NoSQL Databases: MongoDB, Cassandra, HBase, etc.
File Systems: Hadoop Distributed File System (HDFS), Amazon S3, Azure Blob Storage, Google Cloud Storage, local file systems, etc.
File Formats: CSV, JSON, Parquet, Avro, ORC, XML, etc.
Streaming Data Sources: Kafka, Kinesis, Azure Event Hubs, etc.
2. Connecting to Data Sources
To extract data, you need to connect Spark to the data source. Spark’s DataFrameReader API is used to read data into a DataFrame. Here’s a breakdown of how to connect to different types of data sources:
a. Reading from Relational Databases
To read data from relational databases, Spark uses JDBC (Java Database Connectivity). Here's an example of how to read data from a MySQL database:
pythonCopy codejdbc_url = "jdbc:mysql://hostname:port/dbname"
table_name = "your_table"
properties = {
"user": "your_username",
"password": "your_password"
}
df = spark.read.jdbc(url=jdbc_url, table=table_name, properties=properties)
JDBC URL: Specifies the protocol (jdbc), the sub-protocol (mysql), the host, port, and database name.
Table Name: The name of the table you want to extract data from.
Properties: A dictionary containing connection properties like username and password.
b. Reading from NoSQL Databases
Different NoSQL databases have different connectors. For example, to read from MongoDB, you need the MongoDB Spark Connector. Here’s how you could read from MongoDB:
pythonCopy codedf = spark.read.format("mongodb").option("uri", "mongodb://localhost:27017/dbname.collection").load()
Format: Specifies the format to be read; in this case, it's
"mongodb".Option: Used to provide additional configurations like URI for MongoDB.
c. Reading from File Systems
Spark can directly read files stored on HDFS, S3, Azure Blob Storage, etc. Here’s how you can read from HDFS:
pythonCopy codedf = spark.read.format("parquet").load("hdfs://namenode:8020/user/hadoop/data/")
Format: Specifies the file format (e.g.,
parquet,csv,json).Load: Takes the path to the file or directory in the file system.
For reading from S3:
pythonCopy codedf = spark.read.format("csv").option("header", "true").load("s3a://bucket_name/path/to/file.csv")
- Use
s3a://for reading and writing to AWS S3 with support for Amazon’s authentication.
d. Reading from Streaming Sources
Spark can also read data from streaming sources like Apache Kafka:
pythonCopy codedf = spark.readStream.format("kafka").option("kafka.bootstrap.servers", "localhost:9092").option("subscribe", "topic_name").load()
ReadStream: Used instead of
readfor streaming data sources.Kafka Options: Specify the Kafka broker and the topic to subscribe to.
3. Configurations and Options for Data Extraction
Different data formats and sources have specific options that can be set to customize the read behavior:
Schema Definition: When reading formats like CSV or JSON, you can define the schema to enforce data types:
pythonCopy codefrom pyspark.sql.types import StructType, StructField, StringType, IntegerType schema = StructType([ StructField("name", StringType(), True), StructField("age", IntegerType(), True) ]) df = spark.read.format("csv").schema(schema).option("header", "true").load("path/to/file.csv")Header: For CSV files, use
.option("header", "true")to specify that the first row contains column names.Delimiter: Use
.option("delimiter", ",")to specify a custom delimiter for CSV files.Compression: For formats that support compression (like Parquet or Avro), specify the compression codec (e.g.,
.option("compression", "gzip")).
4. Best Practices for Extracting Data
Pushdown Predicate Filters: When extracting data, apply filters as early as possible to reduce the amount of data transferred. This is especially important for databases and cloud storage.
Minimize Data Movement: Extract only the necessary data to reduce network I/O and improve performance.
Use Partitioning: When reading large datasets, use partitioning to parallelize data extraction. For instance, reading from a database table, you can use the
partitionColumn,lowerBound,upperBound, andnumPartitionsoptions to split the data into chunks.Handling Schema Evolution: When reading from data sources like Parquet or Avro, where schema evolution is possible, plan how to handle changes in the schema.
To Sum it Up :
ETL is a comprehensive process with multiple phases, each tailored to specific project requirements. In this section, we focused on EXTRACT, exploring how data extraction varies based on the needs of the project. It can be achieved using different tools or code, depending on the source and security requirements. We also discussed best practices and provided some sample codes to illustrate these methods.
Subscribe to my newsletter
Read articles from Shreyash Bante directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Shreyash Bante
Shreyash Bante
I am a Azure Data Engineer with expertise in PySpark, Scala, Python.