Arquitectura Hexagonal con Java y Spring 3 + CQRS / Casos de uso
 Gabriel Eguia
Gabriel Eguia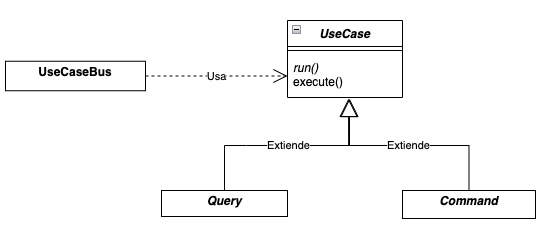
Esta es la tercera parte de una serie, que comenzó llamándose “Arquitectura Hexagonal con Java y Spring”. Ciertamente, creo que el título nos quedó “corto” porque, además de conceptos de arquitectura hexagonal, también hemos visto algunas cosas de Arquitecturas limpias, Domain-driven design y otras. En esta nueva entrega, vamos a hablar sobre como podemos encapsular la lógica de negocio en pequeñas unidades reutilizables a las que nos referiremos como casos de uso, y nos apoyaremos en algunos conceptos de CQRS y de los casos de uso tratados por el Tío Bob en su libro “Arquitectura limpia”.
Este artículo parte y toma como base el código y los conceptos mencionados en las entregas anteriores. Si aún no las leíste, te dejo los enlaces:
Introducción
Hasta el momento, tenemos un API REST con un endpoint para obtener los clientes, y otro para crear clientes. Supongamos ahora que nos piden poder cambiar el nombre a un cliente. ¿Que cambios necesitaríamos hacer? En principio, crear un endpoint con el método PUT, cuya ruta incluya el ID del cliente y que en el body reciba el nuevo nombre para el cliente. Luego deberíamos recuperar el cliente con el ID proporcionado, cambiarle el nombre y volver a persistirlo. Como vemos, hay varias operaciones “atómicas” o sencillas que utilizamos en esta funcionalidad que seguramente necesitemos reutilizar en muchas otras partes de nuestra lógica de negocio, como el buscar un cliente por ID y el actualizar un cliente. Podríamos decir que nuestro caso de uso “Cambiar nombre cliente” incluye los casos de uso “Buscar cliente por ID” y “Actualizar cliente”.
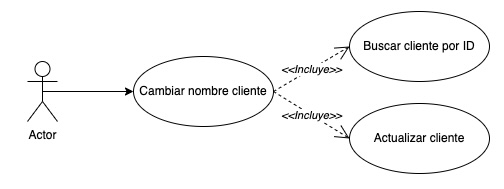
Encapsular estos casos de uso en objetos nos permitiría reutilizar la lógica donde sea que la necesitemos, y simplificaría el mantenimiento del código, ya que para modificar alguno sólo tendríamos que modificar un objeto. Para esto podemos basarnos en CQRS (Command-Query Responsibility Segregation). Veamos cómo...
Creando la estructura de objetos para nuestros casos de uso
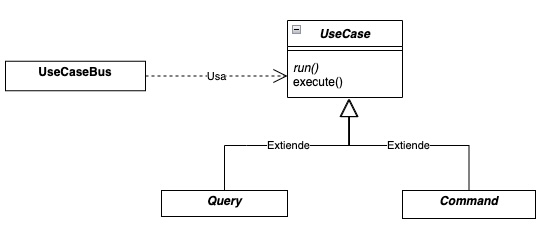
En primer lugar, vamos a construir nuestro modelo de casos de uso. Un caso de uso será o bien una consulta (Query), ya que no produce cambios en el sistema; o bien un comando (Command), ya que se producen un cambio en el estado o los datos del sistema.
En segundo lugar, necesitamos una forma única de ejecutar nuestros casos de uso. Haría las veces de un servicio que inyectaríamos allí donde necesitemos ejecutar un caso de uso. Esto podemos lograrlo modelando un UseCaseBus, que será el encargado de saber como se ejecuta cada Command y cada Query. Adicionalmente, si lo deseamos, este bus nos permitiría ejecutar interceptores antes y después de la ejecución de cada caso de uso para realizar tareas que necesitemos que se ejecuten con cada caso de uso, pero que no queremos incluirla en la implementación de cada uno para mantener el código lo más simple posible.
Nuestro modelo quedaría algo así:
La pregunta ahora es ¿donde deberían estar estos objetos? Tenemos varias opciones. Podemos, bien extraerlos a un proyecto de arquitectura y agregar en el nuestro la dependencia con este (esta sería la opción ideal, en mi opinión), o colocarlos en un módulo de arquitectura aparte. Para mantener nuestro ejemplo sencillo, utilizaremos esta última opción.
Nos quedaría algo así:

Aprovechamos también para crear un wrapper para el contexto, para poder utilizar dentro de nuestra capa domain la inyección de dependencias sin acoplarnos a Spring. No vamos a entrar en detalle de la implementación de este punto en este tutorial, pero más adelante vamos a ver la ventaja que nos aporta.
Cómo podemos ver, toda la lógica se encuentra dentro de UseCase. Esta define el método abstracto run(), que es el que deberemos implementar en nuestros casos de uso del dominio, e implementa el método execute(), que es el que utiliza el UseCaseBus para ejecutar los distintos Query y Command que le indiquemos:
public abstract class UseCase<T> {
protected abstract T run();
protected T execute() {
return run();
}
}
@Service
public class UseCaseBus {
public <R> R invoke(UseCase<R> useCase) {
return useCase.execute();
}
}
El UseCaseBus está anotado con @Service de Spring. Cómo nuestra lógica de negocio debería ser completamente agnóstica a los detalles de las implementaciones (la base de datos que utilicemos, la forma que decidamos usar para ejecutarla (API REST), y del framework utilizado, etc) , este es un buen motivo para colocar estas clases en un módulo architecture. Esto nos da la posibilidad de poder cambiar cualquiera de estas cosas sin afectar a la lógica de negocio. El mismo objetivo que perseguimos al separar los puertos primarios de los secundarios, reducir al mínimo posible el acoplamiento entre los distintos componentes de nuestro sistema.
Cómo vemos, las clases Query y Command no tienen lógica. De momento, sólo nos van a servir para diferenciar entre Query y Command, pero más adelante podríamos agregar la posibilidad de ejecutar otros casos de uso desde los mismos, y acá es donde cobran valor: Desde un Command, deberíamos poder ejecutar tanto otros commands como queries. Pero desde una Query, no deberíamos poder ejecutar comandos. Esto es así porque una Query no puede modificar el estado del sistema, pero un Command si.
Nuestros primeros Query y Command
Primero veamos el caso de uso para recuperar un cliente por su ID. Necesitemos crear una clase que extienda de Query, que reciba el ID de cliente por parámetro, e implementar la lógica para recuperar al cliente en el método abstracto run().
public class GetClientByIdQry extends Query<Client> {
private final Long clientId;
private final ClientOutboundPort clientPort;
GetClientByIdQry(
Long id,
ClientOutboundPort clientOutboundPort
) {
clientId = id;
clientPort = clientOutboundPort;
}
public GetClientByIdQry(
Long id
) {
this(id, locate(ClientOutboundPort.class));
}
@Override
protected Client run() {
return clientPort.findById(clientId);
}
}
Vemos que el código queda bastante sencillo. Tenemos dos constructores, uno protected, que utilizaremos para poder proveer un mock del puerto en nuestros tests unitarios, y el público, que cómo vemos acepta sólo un ID de cliente y luego utiliza el método locate() para obtener una instancia del puerto secundario en tiempo de ejecución. Aquí es donde estamos utilizando el wrapper del contexto, al que llamamos ServiceLocator, para poder “inyectar la dependencia” que necesitamos. De esta forma, estamos utilizando de forma desacoplada el contexto de aplicación de Spring. Si en un futuro quisiéramos o necesitásemos cambiar el framework, por ejemplo a Micronaut, simplemente crearíamos un wrapper para ellos contexto de este y el ServiceLocator se encargaría de buscar la dependencia en el contexto que corresponda, de forma completamente transparente para nuestro dominio.
En el caso del comando para actualizar un cliente, es un poco más de lo mismo:
public class UpdateClientCmd extends Command<Client> {
private final Client client;
private final ClientOutboundPort clientPort;
UpdateClientCmd(
Client clientToUpdate,
ClientOutboundPort clientOutboundPort
) {
client = clientToUpdate;
clientPort = clientOutboundPort;
}
public UpdateClientCmd(
Client clientToUpdate
) {
this(clientToUpdate, locate(ClientOutboundPort.class));
}
@Override
protected Client run() {
return clientPort.update(client);
}
}
Orquestando las llamadas entre varios casos de uso
Ahora, sólo nos queda implementar el caso de uso para cambiar el nombre del cliente. Para esto orquestaremos las llamadas y la lógica que no tenga un caso de uso propio en otro objeto, como por ejemplo el adaptador primario. Para esto, uno de los cambios que tenemos que hacer es que el adaptador ya no dependa del puerto secundario, ya que en lugar de interactuar con la capa de persistencia, necesitamos ejecutar casos de uso. Ahora necesitamos inyectar en nuestro ClientInboundAdapter el UseCaseBus:
@Singleton
class ClientInboundAdapter implements ClientInboundPort {
private final UseCaseBus bus;
public ClientInboundAdapter(UseCaseBus useCaseBus) {
bus = useCaseBus;
}
@Override
public Client create(Client client) {
return bus.invoke(new CreateClientCmd(client));
}
@Override
public List<Client> findAll() {
return bus.invoke(new GetClientsQry());
}
@Override
public Client updateClientNameById(Long clientId, String newName) {
Client client = bus.invoke(new GetClientByIdQry(clientId));
Client clientToUpdate = new Client(
client.id(),
newName,
client.lastName()
);
return bus.invoke(new UpdateClientCmd(clientToUpdate));
}
}
Y cambiar nuestra lógica para llamar a los casos de uso en lugar de ir directamente al adaptador secundario. Aprovechamos y creamos GetClientsQry y CreateClientCmd para actualizar la lógica de la entrega anterior al nuevo esquema.
Conclusiones
Los casos de uso son una herramienta muy potente. Permite tener lógicas acotadas y probadas, y reutilizar estas para componer otros casos de uso más complejos, facilitando la comprensión y el mantenimiento del sistema al generar un código mucho más expresivo y fácil de comprender. Cómo vemos, toda la lógica de negocio queda estructurada de forma clara y transparente, plantea un claro flujo entre los puertos primarios y secundarios: orquestando las peticiones que llegan desde los primarios, aplicando la lógica y validaciones necesarias, obteniendo los datos necesarios desde los puertos secundarios, y generando la respuesta correspondiente en los casos necesarios.
Les dejo el repositorio de GitHub para que puedan analizar el código con más detalle, y les cuento que hay una versión anterior de este artículo en Adictos al trabajo.
Subscribe to my newsletter
Read articles from Gabriel Eguia directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Gabriel Eguia
Gabriel Eguia
Full Stack Developer. Application Analyst, Designer and Developer in many programming languages. Best practices, Clean Code, DevOps and Software craftsmanship enthusiastic. My goals are to grow in my career, learning new technologies and becoming a technical leader and referent, leading and influencing teams, and helping teammates to grow.