How I Built an Image Search Engine with CLIP and FAISS
 SANDEEP CHAKRABORTY
SANDEEP CHAKRABORTY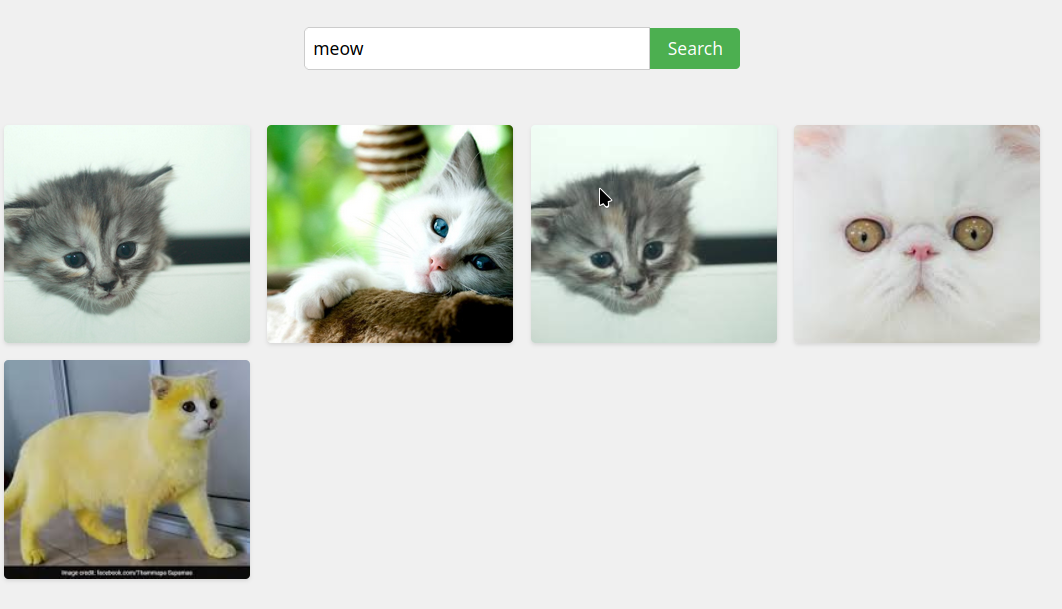
It all started one Sunday evening when I got an email from Medium's daily digest. Among the articles was a blog post titled Building an Image Similarity Search Engine with FAISS and CLIP by Lihi Gur Arie. As someone who's always eager to learn new things, I was instantly hooked. I loved the idea of building an engine using vector dimensions (we tinker a lot with vector databases and vector search at my workplace). Even though I was in the midst of mid-semester exams and had some pending tasks at work, I couldn't resist the pull of this project. The idea of searching images using natural language felt almost magical to me. Although it’s a common concept, building something on your own always holds a special place, and you truly understand how it works. So, I knew I had to get a good cup of coffee and get started.
What exactly is CLIP and FAISS
CLIP (Contrastive Language-Image Pretraining) by OpenAI is an impressive piece of technology. It's a multi-modal vision and language model that maps images and text to the same latent space. CLIP generates dense embeddings for both images and text, allowing them to exist in a shared space, making image search using text incredibly intuitive.
Here’s a simple example of how you can use the CLIP model:
import clip
import torch
model, preprocess = clip.load("ViT-B/32")
images = preprocess(images)
texts = clip.tokenize(texts)
with torch.no_grad():
image_features = model.encode_image(images)
text_features = model.encode_text(texts)
FAISS (Facebook AI Similarity Search), on the other hand, is all about speed and efficiency. It’s designed to handle large-scale datasets, making it perfect for indexing the embeddings generated by CLIP. The combination of CLIP and FAISS almost made sure that the image search time would get much faster if both were used together, which was exactly what I wanted to build
Here’s a snippet of how FAISS is typically used:
import faiss
index = faiss.IndexFlatIP(d) # d is the dimension of the vectors
index.add(vectors) # indexing
distances, indices = index.search(query_vectors, k) # k is the number of nearest neighbors to search for
Building the Pipeline
With the knowledge I gathered from the blog and the official documentation, I started building the pipeline. My goal was to create a system that could take a natural language query, process it through CLIP to generate an embedding, and then search for similar image embeddings using FAISS.
The first step was to preprocess and encode all the images in the dataset using CLIP:
# Load and preprocess images
images = preprocess(images)
# Encode images into embeddings
with torch.no_grad():
image_features = model.encode_image(images)
Next, I indexed these embeddings using FAISS:
# Initialize FAISS index
index = faiss.IndexFlatIP(image_features.shape[1])
# Add embeddings to the index
index.add(image_features.numpy())
Overcoming Challenges
No project is complete without its bugs (or challenges, perhaps). My laptop (a heavy gaming laptop), an RTX 3050 notebook GPU with 4GB of VRAM, decided to crash three times during testing. But honestly, these setbacks were all part of the fun. These hiccups taught me a lot about batch processing for more efficient hardware utilization.
To overcome the issue of processing large datasets, I implemented batch processing. This fixed the crashes and reduced the RAM utilization to nearly 12GB:
batch_size = 32
image_features = []
for i in range(0, len(images), batch_size):
batch_images = images[i:i + batch_size]
image_input = torch.tensor(np.stack(batch_images)).to(device)
with torch.no_grad():
batch_features = model.encode_image(image_input).float()
batch_features /= batch_features.norm(dim=-1, keepdim=True)
image_features.append(batch_features.cpu().numpy())
image_features = np.concatenate(image_features, axis=0)
The Dataset
For this project, I used a dataset of animal images that I sourced from Dataset Source. The dataset contains a variety of animal images, each categorized by species. This allowed me to experiment with different types of queries, such as "meow meow" or "a dog playing fetch."
The dataset's structure looked like this:
images/dogs/cats/lions/tigers/
Each sub directory contained numerous .jpg images of the respective animal. I made sure to preprocess and normalize these images before feeding them into the CLIP model.
The Outcome
In the end, after a lot of debugging, I had one working image search engine which provides precise outputs (almost). This project is not really just a test project; this tool has some real-life applications (at least to me) to sort personal photos. This made me want to learn more about image recognition systems, which I will work on next.
The journey from stumbling upon that Medium post to completing this project was good, and I’m eager to see more advancements in this field with better models/libraries. If you’re curious to see the code or try it out yourself, I’ve made the repository available on GitHub. Feel free to clone it, tinker with it, and maybe even build something better!
Wrapping Up
This project taught me a lot—not just about CLIP and FAISS, but also about building something efficient. Whether you’re a seasoned developer or someone just starting out, I highly recommend trying something similar. It’s challenging, educational, and most of all, a lot of fun.
Thank you for following along, and if you enjoyed this post, don’t forget to click the 👍 button to show your appreciation—it might just boost the algorithm’s self-esteem! 🤓
Subscribe to my newsletter
Read articles from SANDEEP CHAKRABORTY directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by