2. RAG Data Loading Simplified: With Some Real Use Cases
 Muhammad Fahad Bashir
Muhammad Fahad BashirTable of contents
- Ingestion Step
- i) Loading the Data
- Types of Document Loaders
- Examples of Document Loaders:
- Practical Examples
- Use Cases Example for LangChain Document Loaders
- 1. Legal Document Analysis (PDF Loader)
- 2. Customer Support Knowledge Base (Text File Loader)
- 3. Financial Data Analysis (CSV Loader)
- 4. Academic Research (URL Loader)
- 5. Content Creation for Marketing (YouTube Loader)
- 6. Healthcare Data Aggregation (PDF and CSV Loaders)
- 7. E-commerce Product Review Analysis (Text File Loader)
- 8. Corporate Training Material Organization (PDF and Text File Loaders)
- 9. Historical Data Preservation (PDF Loader)
- 10. Competitive Intelligence Gathering (URL Loader)
- Final Remarks
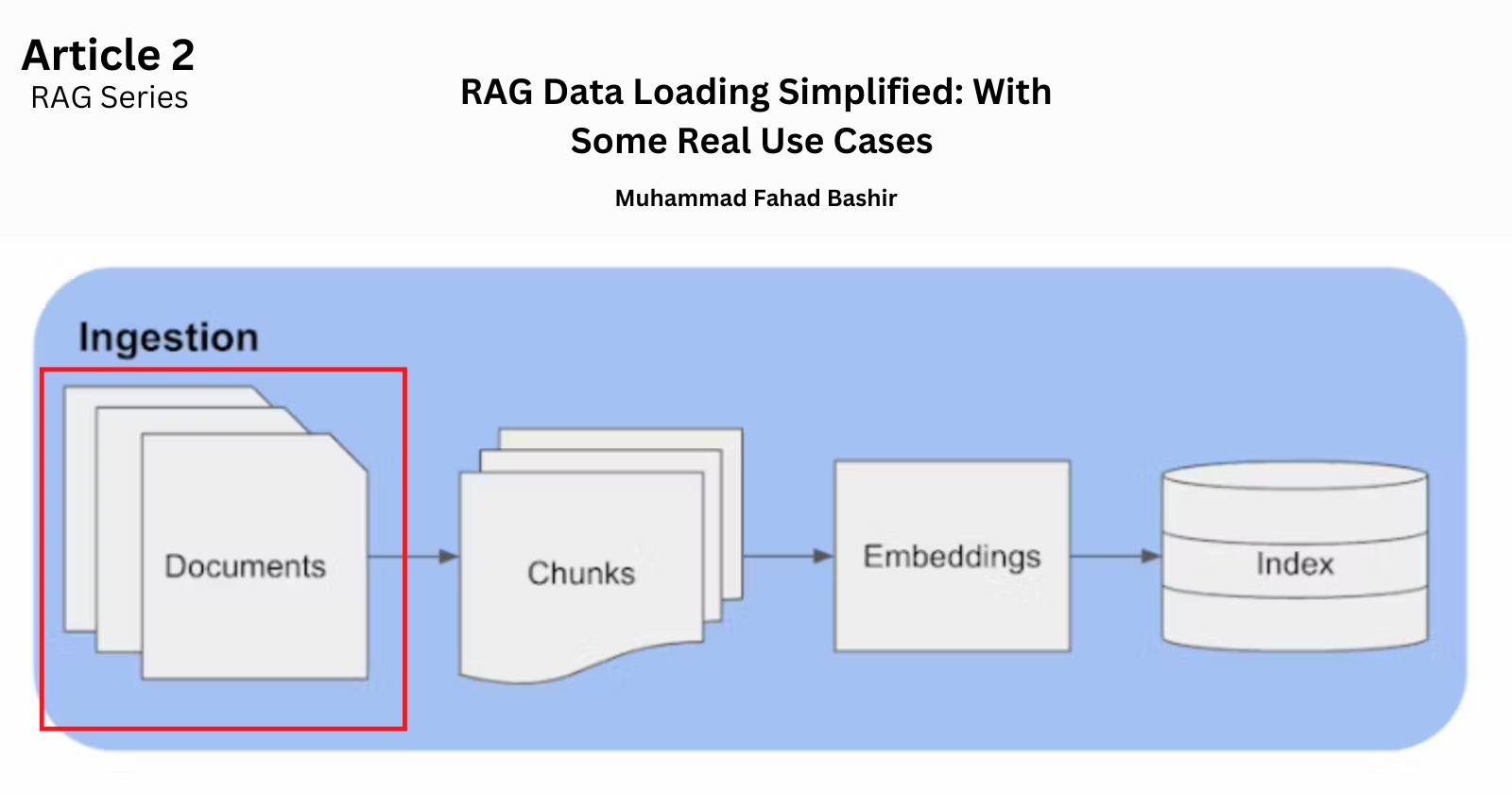
In our previous discussion, we explored why Retrieval-Augmented Generation (RAG) is becoming an essential technique in the AI landscape. We covered its benefits and provided an overview of how it works at a high level. You can read it here Today, we’ll discuss the the first step of the RAG pipeline—Ingestion—which is crucial for setting up an effective RAG system.
Ingestion Step
The ingestion process is a foundational step in the RAG pipeline. This is where data is fed into the system, and its success is crucial for the entire application's performance. The main tasks involved in ingestion are loading the data and breaking it into chunks and then embedding and indexing. But in this article, we will focus on studying loading the data.
The quality of our RAG system depends on how well the data is ingested. So poor ingestion can lead to inaccurate retrievals and ineffective responses.
i) Loading the Data
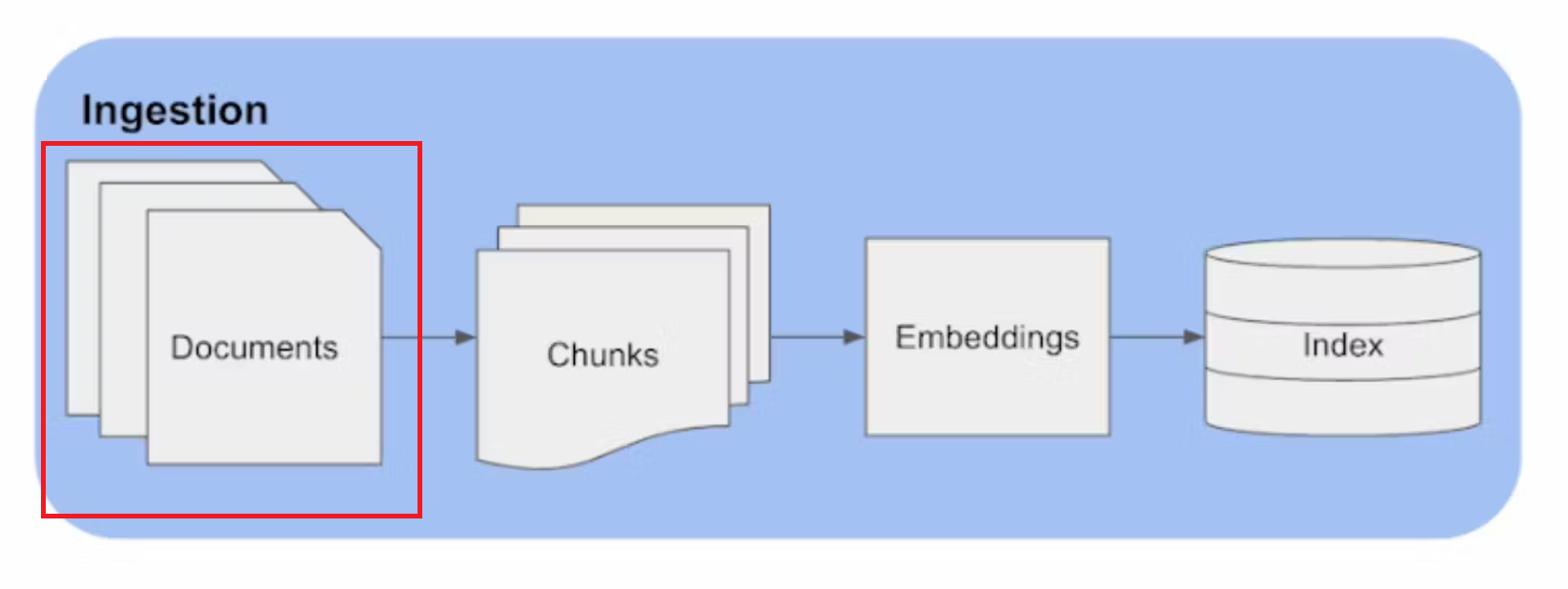
Data can come from various sources and in different formats—PDFs, text files, CSVs, URLs, and more. The first step in the ingestion process is to load this data into the system. To do this effectively, LangChain provides an extensive library of document loaders. We select the appropriate document loader based on the type of document we are dealing with.
Types of Document Loaders
Transform Loaders: These loaders handle different input formats and transform them into the Document format. For instance, consider a CSV file named "data.csv" with columns for "name" and "age". Using the CSVLoader, we can load the CSV data into Documents
Public Dataset or Service Loaders: LangChain provides loaders for popular public sources, allowing quick retrieval and creation of Documents. For example, the WikipediaLoader can load content from Wikipedia:
Proprietary Dataset or Service Loaders: These loaders are designed to handle proprietary sources that may require additional authentication or setup. For instance, a loader could be created specifically for loading data from an internal database or an API with proprietary access.
Examples of Document Loaders:
PDF Documents: If we are working with PDF files, we can use the
PyPDFLoader, a tool designed specifically for loading and processing PDF content.Text Files: For simple text files, a
TextFileLoaderwould be appropriate.CSV Files: When dealing with data stored in CSV format, a
CSVLoadercan be used to load the data efficiently.URLs: If your data is available online, you can use a
URLLoaderto retrieve and load the content from the web.YouTube Videos: For video content, such as YouTube videos, specialized loaders like
YouTubeLoadercan extract and load transcripts or descriptions.
Practical Examples
install the basic packages
- PDF Documents: Loading PDFs using PyPDFLoader is one of the ways to load pdf documents. The output will be into an array of documents, where each document contains the page content and metadata with the page number.
from langchain_community.document_loaders import PyPDFLoader
loader=PyPDFLoader("different_docs/book.pdf") # have to pass the path of file
pages =loader.load()
pages

- Text Document: The simplest loader reads a file as text and places it all into one document. and return in output metadata ( source) and page_content.
from langchain.document_loaders import TextLoader
loader=TextLoader('different_docs/info.txt')
loader.load()

- Loading Data Through URLs: it will load the content of the page that's provided on the mentioned link. It will return output having metadata (source, title, description, language) and page content
from langchain_community.document_loaders import WebBaseLoader
webloader=WebBaseLoader('https://mfahadbashir.hashnode.dev/')
webloader.load()

There are other types of loaders also . You can refer to this Google Colab notebook for a few more examples. Google Colab Link.

You can also view the official documentation from Langchain for in-depth study. Here is the Link.
Use Cases Example for LangChain Document Loaders
1. Legal Document Analysis (PDF Loader)
Use Case: A law firm needs to analyze thousands of legal contracts and agreements stored as PDF files. By using the PyPDFLoader, they can efficiently extract text and metadata from these documents, allowing them to search for specific clauses, compare contract terms, and identify potential risks.
2. Customer Support Knowledge Base (Text File Loader)
Use Case: A customer support team maintains a large repository of text files containing FAQs, troubleshooting guides, and user manuals. Using the TextFileLoader, they can load and organize this content, enabling the creation of a smart chatbot that retrieves relevant answers for customer queries in real-time.
3. Financial Data Analysis (CSV Loader)
Use Case: An investment firm relies on CSV files to store historical stock prices, trading volumes, and other financial data. The CSVLoader allows them to ingest and analyze this data, helping the firm develop predictive models for market trends and investment strategies.
4. Academic Research (URL Loader)
Use Case: A research team is conducting a study on climate change and needs to gather the latest articles, reports, and studies published online. By using the URLLoader, they can scrape and load content from academic journals, news websites, and government portals, making it easier to synthesize findings and identify key trends.
5. Content Creation for Marketing (YouTube Loader)
Use Case: A digital marketing agency wants to extract insights from popular YouTube videos to create engaging content for their clients. Using the YouTubeLoader, they can retrieve video transcripts and analyze audience comments, helping them craft targeted blog posts, social media updates, and ad campaigns.
6. Healthcare Data Aggregation (PDF and CSV Loaders)
Use Case: A healthcare provider needs to aggregate patient records and research papers stored in PDF and CSV formats. By using a combination of PyPDFLoader and CSVLoader, they can integrate this data into a unified database, enabling the development of AI-driven diagnostic tools and personalized treatment plans.
7. E-commerce Product Review Analysis (Text File Loader)
Use Case: An e-commerce company wants to analyze customer reviews to improve product offerings and customer satisfaction. The TextFileLoader helps them load and process thousands of text reviews, allowing them to identify common complaints, feature requests, and overall sentiment towards their products.
8. Corporate Training Material Organization (PDF and Text File Loaders)
Use Case: A corporation needs to organize and distribute training materials to employees, which are available in both PDF and text formats. By using PyPDFLoader and TextFileLoader, they can create a searchable digital library, making it easy for employees to access and review relevant training content.
9. Historical Data Preservation (PDF Loader)
Use Case: A museum is digitizing its collection of historical documents, many of which are stored as PDFs. The PyPDFLoader allows the museum to extract and catalog these documents, enabling researchers and the public to access and study historical records more easily.
10. Competitive Intelligence Gathering (URL Loader)
Use Case: A business intelligence team needs to monitor competitors by gathering information from their websites, blogs, and press releases. The URLLoader helps them retrieve and analyze this web content, providing valuable insights into competitors’ strategies and market positioning.
Final Remarks
The ingestion step is a critical component of the RAG pipeline, setting the foundation for effective data retrieval and generation. By carefully selecting and utilizing the appropriate document loaders, we can ensure that data from various sources and formats is accurately and efficiently ingested into the system. This not only enhances the quality of the retrieved information but also improves the overall performance of the RAG system. Whether dealing with PDFs, text files, CSVs, URLs, or other data types, the right ingestion strategy is key to unlocking the full potential of the Retrieval-Augmented Generation (RAG systems ) .
Subscribe to my newsletter
Read articles from Muhammad Fahad Bashir directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by