From Spark to Ray: Amazon's $120MM/year Cost-Saving Journey
 Kamran Ali
Kamran Ali
Amazon Business Data Technologies (BDT) Team moved EXABYTE scale jobs from Spark to this tech. 🤔
Cost saving of $120MM/year on EC2 on-demand R5 instance charges 🔥
Background
It started with migration from Oracle
To decouple storage and compute, they migrated over 50 PB of data from Oracle to S3 (storage) + Redshift / RDS / Hive / EMR (for compute)
Teams can now subscribe to S3-based table using their choice of analytics framework (e.g. Athena, Redshift, Spark, Flink etc) to run on-demand or scheduled queries.
They further built data cataloging metadata layers, data discovery services, job orchestration infrastructure, web service APIs and UIs, and finally released the minimum viable set of services they needed to replace Oracle.
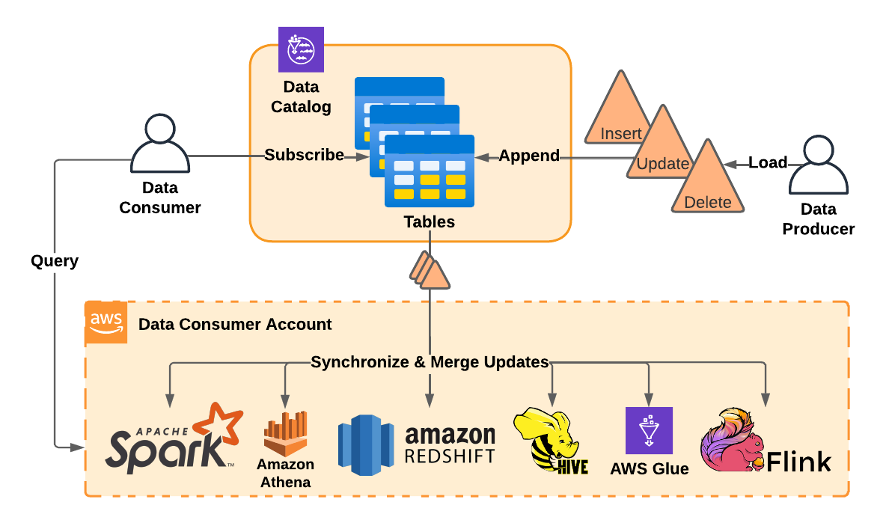
As all tables in their catalog composed of unbounded streams of S3 files, its the responsibility of each subscriber’s chosen compute framework to “merge,” all of the changes (inserts, updates, and deletes) at read time to yield the correct current table state.
Problem 1
With time, data has grown too large that "merge" operation started taking days or weeks to complete a merge, or they would just fail.
Solution
To solve this, BDT leveraged Spark on EMR to run the merge once and write back a read-optimized version of the table for other subscribers to use (copy-on-write)
They called this Spark job as Compactor
Problem 2
With time Amazon’s petabyte-scale data had grown to exabyte-scale.
Compaction jobs were exceeding their expected completion times, and had limited options to resolve performance issues as Spark abstracting away most of the low-level data processing details.
Solution
BDT Team did a PoC on Ray, with proper tuning they could compact 12X larger datasets than Spark, improve cost efficiency by 91%, and process 13X more data per hour
Factors that contributed to these results,
Ray’s ability to reduce task orchestration and garbage collection overhead
Leverage zero-copy intranode object exchange during locality-aware shuffles
Better utilize cluster resources through fine-grained autoscaling.
Flexibility of Ray’s programming model, which let them hand-craft a distributed application specifically optimized to run compaction as efficiently as possible.
They settled on an initial design for serverless job management using Ray on EC2 together with DynamoDB, SNS, SQS and S3 for durable job lifecycle tracking and management.
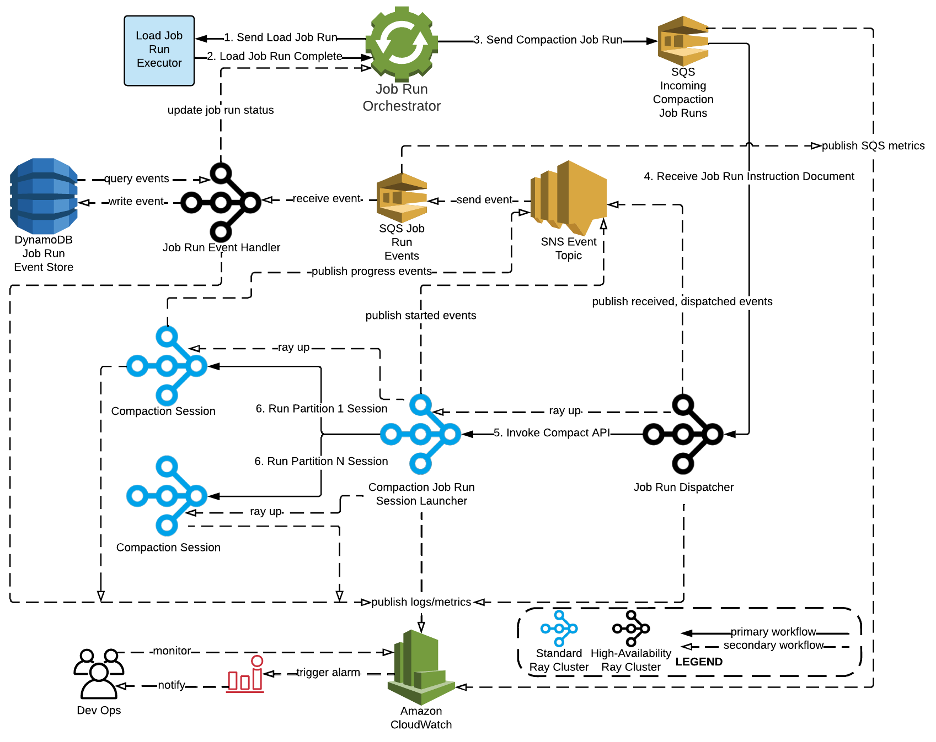
The solid lines of the primary workflow show the required steps needed to start and complete compaction jobs, while the dashed lines in the secondary workflow show the steps supporting job observability.
Migration of Spark Jobs to Ray
Initially they focused on migrating the tables that would yield the biggest impact first.
They targeted the largest ~1% of tables in their catalog, which accounted for ~40% of their overall Spark compaction cost and the vast majority of job failures.
Shadow Testing
They manually shadowed a subset of Spark compaction jobs on Ray by giving it the same input dataset as Spark.
They relied on their Ray-based data quality service to compare their respective outputs for equivalence.
Anything that didn’t pass DQ would be the target of a manual analysis, and either become a known/accepted difference to document or an issue to fix.
Lastly, they built a Data Reconciliation Service which compared the results of Spark and Ray-produced tables across multiple compute frameworks
Later they moved onto fully automated shadow compaction on Ray
This step required automatic 1:1 shadowing of all compaction jobs for any given table between Spark and Ray.
The purpose of this step was to get more direct comparisons with Spark, verify that Ray’s benefits held up across a wide variety of notoriously problematic tables, and to smoke out any latent corner-case issues that only appeared at scale.
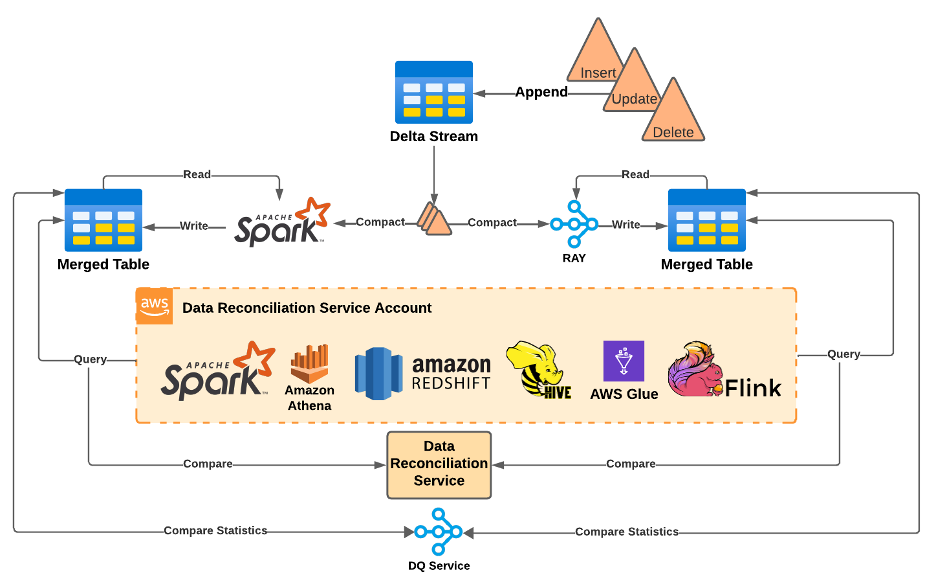
To help avoid catastrophic failure, BDT built another service that let them dynamically switch individual table subscribers over from consuming the Apache Spark compactor’s output to Ray’s output.
Conclusion
BDT team read over 20PiB/day of S3 data to compact across more than 1600 Ray jobs/day.
Ray has maintained a 100% on-time delivery rate with 82% better cost efficiency than Spark per GiB of S3 data compacted, which translates to $120MM/year on EC2 on-demand R5 instance charges.
#systemdesign #architecture #scalability
Understanding the Foundational Principles is the key to Effective Learning!
Follow along to Improve System Design Skills.
Reference and Image Credits
Subscribe to my newsletter
Read articles from Kamran Ali directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Kamran Ali
Kamran Ali
Hi, I'm Kamran Ali. I have ~11.5 years of experience in Designing and Building Transactional / Analytical Systems. I'm actually getting paid while pursuing my Hobby and its already been a decade. In my next decade, I'm looking forward to guide and mentor engineers with experience and resources