Getting Adventureworks to Fabric
 Kay Sauter
Kay Sauter
Today, I am starting a series of blog posts on how to get the AdventureWorks database to Fabric. This is a series of blog posts that will cover a journey from exporting the AdventureWorks database to csv files, to getting the data to Fabric Lakehouse and then to the Data Warehouse. Along the way, I will be discussing some approaches and tips.
If you don't know the AdventureWorks database, it is a sample database by Microsoft. It is used to demonstrate the capabilities of SQL Server. The database is used in many examples, tutorials and documentation by Microsoft. You can download the database here.
There are many versions of it, and i'll be using the AdventureWorks2022 database. I've got my database on a local SQL Server instance. The first step is to export the data to csv files. If you're using a different database, please make sure that it isn't a productive database as exporting all data to csv files can be expensive process. This is not to say that it can't be used in a productive environment, but test it on a non-productive environment first. This way you'll be able to see how long it takes and how much cpu and memory it uses on your system.
So, let me walk you through the Python code by the comments within it:
# importing some libraries
import pathlib as pl
import pyodbc
import pandas as pd
# define the folder path to where the csv files will be exported to
folder_path = pl.Path(
r"C:\Users\userName\OneDrive\csv"
)
# build connection string to the database
conn = pyodbc.connect(
"DRIVER={ODBC Driver 17 for SQL Server};"
"SERVER=localhost;"
"DATABASE=AdventureWorks2022;"
"Trusted_Connection=yes;"
)
# create cursor
cursor = conn.cursor()
# get all sql server table names
qAllTables = "SELECT * FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_TYPE='BASE TABLE'"
table_names = pd.read_sql_query(qAllTables, conn)
print(f"table_names:{table_names}")
# Loop over all tables, get the data with a SELECT *, put it into a df and
# then save the data to csv
print(f"Number of tables: {len(table_names)}")
for table in table_names["TABLE_NAME"]:
if table == "sysdiagrams" or table == "DatabaseLog": # Skip system tables
continue
query = f"SELECT * FROM {table}"
df = pd.read_sql(query, conn)
file_path = folder_path / f"{table}.csv"
print(f"Saving to: {file_path}")
df.to_csv(file_path, index=False)
conn.close() # close the connection, always a good move.
I am assuming that you already have a Fabric capacity. If you don't you may be eligible for a free trial. In this case, you may want to follow the steps as described on Microsofts documentation website here.
Next, go into your Fabric capacity. Here, you should create a new workspace and a new lakehouse:
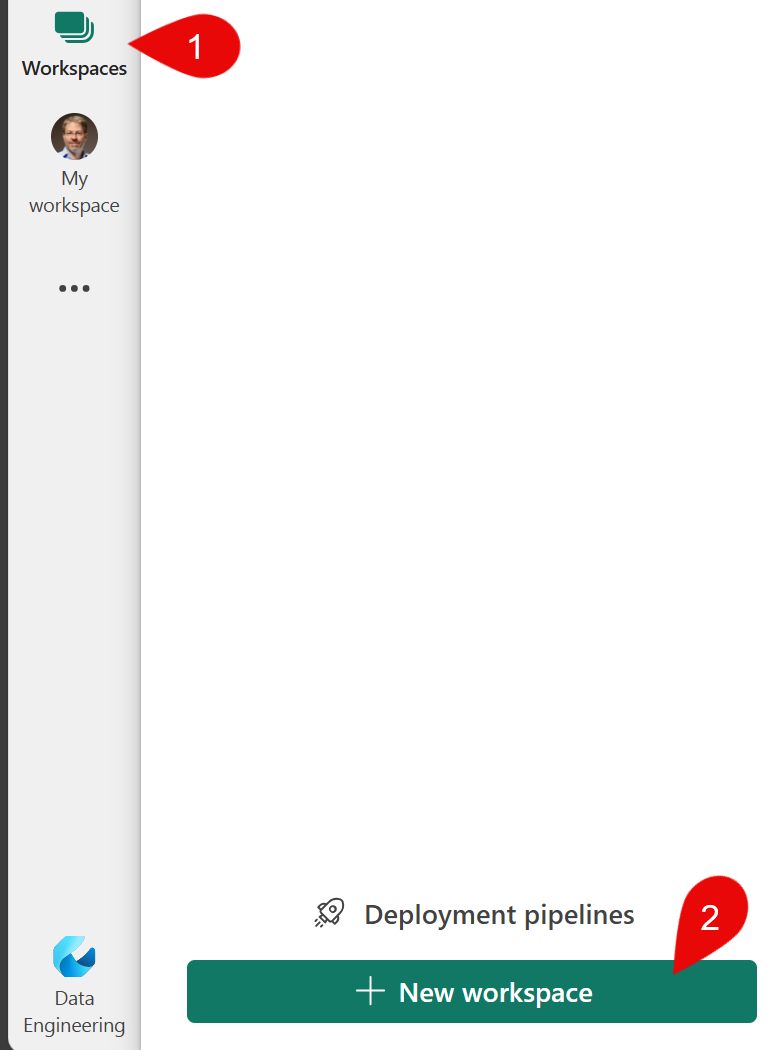
Click on the "Create Workspace" button in the left menu bar (1) which opens a fold-out window. After this, click on the green "+ Create Workspace" button (2) in the bottom left corner.
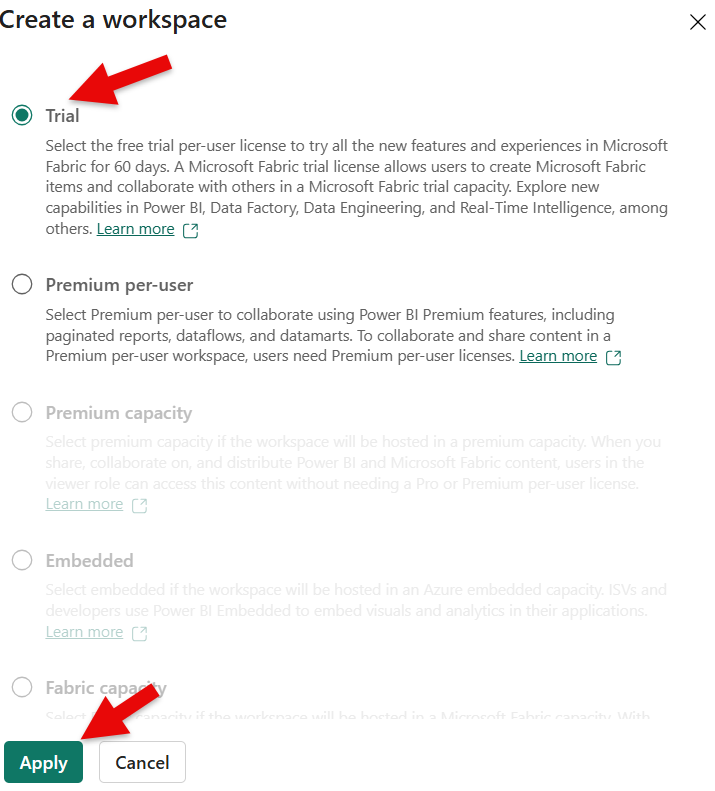
- Next, on the right side, another flap-out window is opening. Here, you can enter your workspace name. The description is optional. If you can, I advise to use the trial capacity that may be available to you. For this click ont he radio button a bit further down in that very window. At the bottom of this very window, you can click on the green "Apply" button to create the workspace. The other options are optional and are not needed for this tutorial.
Go into your workspace you just created. Click on "Workspaces" and you'll find the workspace that you've just created in the flap-out window on the left.
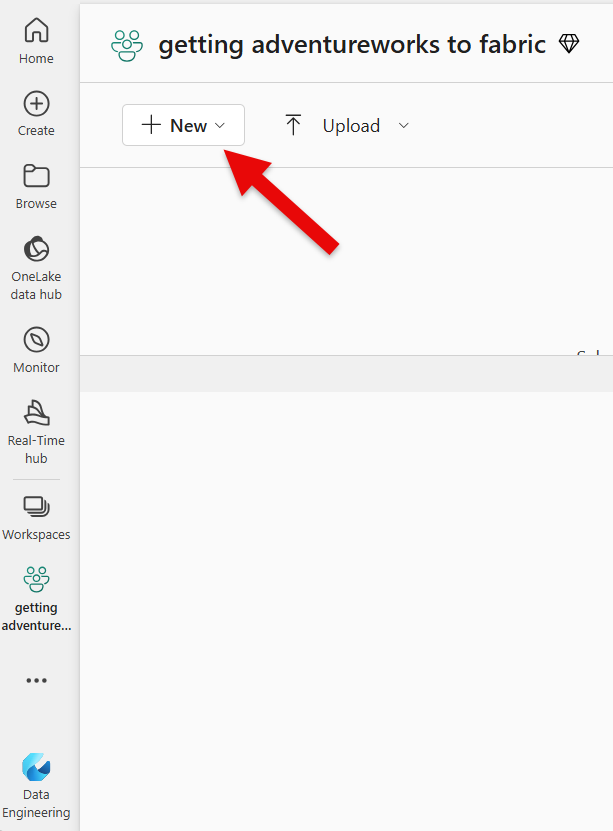
Next, click on the [+ New] button on the left top menu bar. This will open a drop-down window from where you'll be able to choose a new lakehouse. Click on the "Lakehouse" option.
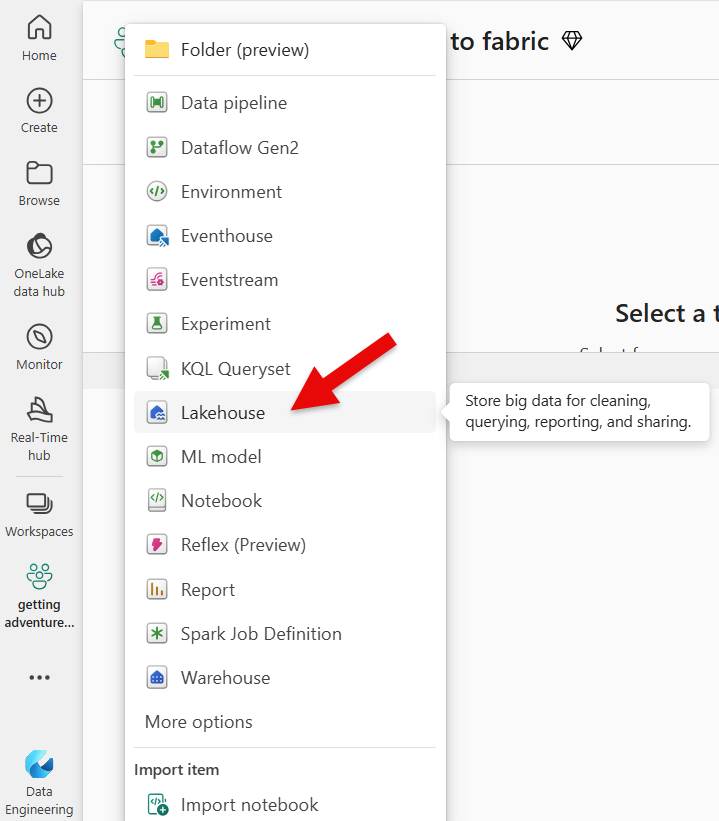
Next, you'll want to enter your lakehouse name into the pop-up window that appeared. I recommend to use a name that is something like adventureworks_bronze. This makes it easier to understand what this lakehouse contains and that it is a bronze layer of the lakehouse. I'll be explaining the layer concept in a later blog post, but for now, we don't have to worry about that. If you have the option to click on "Lakehouse schemas" that is currently in public preview, I recommend not to choose this. The reason is that it can make the concept a bit more complicated which we don't need for this tutorial. In a later post, I'll cover this, but for now, let's skip this. Click on the green "Create" button to create the lakehouse.
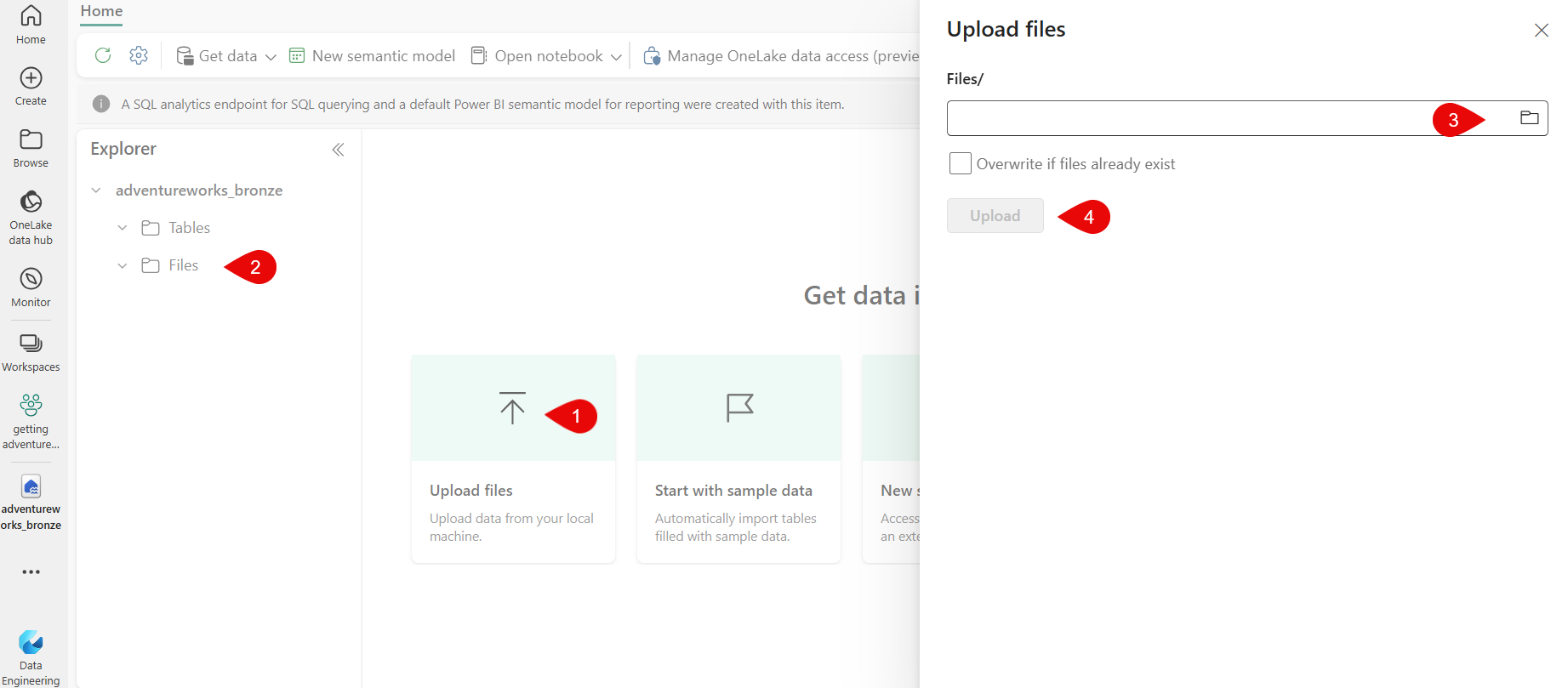
Now that we've created it, we can upload our files. In the middle of the screen (1), we have the possibility to upload the files, but we also could make use of a right click on the folder "Files" (2) that you see on the left side of the screen. The advantage the second "method" is that you actually see the folder where your files will be uploaded to. You can create a folder in that folder if you want to. For this tutorial, i am going to keep this simple and will upload the files directly into this root folder. In the flap-out window on the right (3) you can go to your local folder and select all your files you've just created with the Python script above. If you choose the option "Overwrite if files already exist" you can upload the files again and overwrite the existing ones.
So this is for today, I'll be back with the next blog post on this soon!
Credit: Cover image was created by DALL-E via Microsofts CoPilot.
Subscribe to my newsletter
Read articles from Kay Sauter directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Kay Sauter
Kay Sauter
Kay Sauter has been working with SQL Server since 2013. His expertise covers SQL Server, Azure, Data Visualization, and Power BI. He is a Microsoft Data Platform MVP. Kay blogs on kayondata.com and is actively involved in various community projects like Data TGIF, databash.live, data-conference.ch, and Data Platform Data Platform DEI Virtual Group. He is based in Zurich, Switzerland and in his free time, together with his wife, he loves to travel to discover new cultures and perspectives.