Enterprise Level Micro-frontend on AWS
 Omid Eidivandi
Omid Eidivandi
Micro-frontends, a center of interest for some years now, have evolved rapidly and have become a great choice for achieving independent, autonomous, and well-defined teams and services that improve the velocity and agility of applications.
This article delves into different concepts and details regarding adopting micro-frontends, giving more clarity and vision about tradeoffs and the under-the-hood parts. To learn more about the impacts and goals of a MicroFrontend design, I highly recommend the Building Micro-Frontends book by Luca Mezzalira.
The conception at the root of the proposal applies to achieve the above ideas, but when it comes to design and implementation, this leads to a lot of discussions and details to take into account and consider. choosing the right approach depends on the tradeoffs and the priorities that business follows.
Micro-frontends are not far from microservice design approach, as they apply the same goals fundamentally, but at the same time brings exact or partial complexities and challenges the microservices introduce.
The Primer
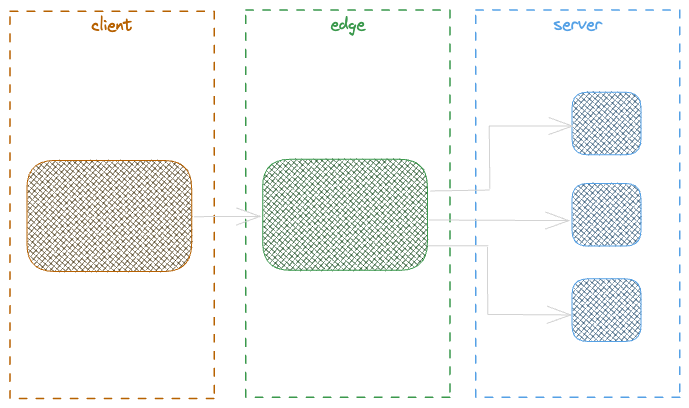
At high level a micro-frontend architecture leads to answer achieving independent and autonomous collaboration to satisfy a final result asset within a distributed system.
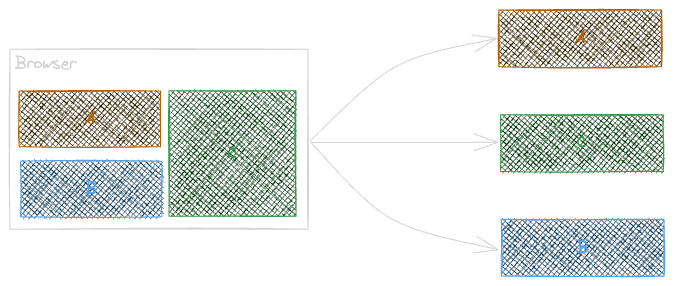
In the above schema, the 3 services are deployed, maintained, and scale independently and will be composed together as a final result asset.
This is a simple, small and straight forward example but at higher scale we need to think about:
Templating
Discovery
Routing
Composition
Boundary Definition Challenges
One principal challenge when designing Micro-Frontends is how evaluate the boundaries of each MFE. Often having too many small distributed micro frontends seems to bring more flexibility and reusability opportunities, so a MFE can be composed in as many places as the client app needs. While having MFEs with small defined contexts bring the advantage of having self managed and autonomous MFEs but at the same time, adds more complexity at Discovery & Routing part, also adds the communication chattiness into MFEs by calling the downstream services multiple times while the result asset will be in the same context. In the other side, having too big MFEs can improve some challenges small MFEs brings but gives less flexibility and opportunity of reusability, and will introduce the rendering performance issues, complexities and performance degradation at client side.
Having MFEs with a logical size based on the context is a key to success, at the same time it brings more logic at MFE side but avoid adding complexity at other parts of the system.
Some factors to consider while defining a micro-frontend context
Performance
Lifecycle
Co-existence
Reusability
Ownership
Clarity & Vision
Team Topology possibilities
Horizontal vs Vertical Splitting
The splitting refers to the fact of composing the MFEs on the horizontal or vertical axis.
In horizontal splitting the composition introduces a coupling like having a web app page dedicated to a micro-frontend in this case the components inside that given page have less opportunity to be reused in other contexts and pages. an example will be a widget that renders the active products for a given customer, while it can be shown in different pages like customer detail page or in the own customers admin page. Horizontal splitting leads to duplicated components, this seems ok but can be tricky when the number of reusable components raises or the standardisation and governance becomes a concern like applying design systems, complex business logic, etc.
In a vertical splitting the chance of reusability increases and a component has the chance of being reused in any other contexts and result assets. but it adds some layer of duplicated communication and data fetching but also at some points introduces useless decomposition.
When it comes to splitting a better approach is to pragmatically define the right boundary but also composition layer. often teams stands for applying MFE composition at a single layer being Web Server, Edge or shell. but the better approach seems to define right decomposition at server side while giving flexibility to future reuse but also right composition in shell ( kernel ).
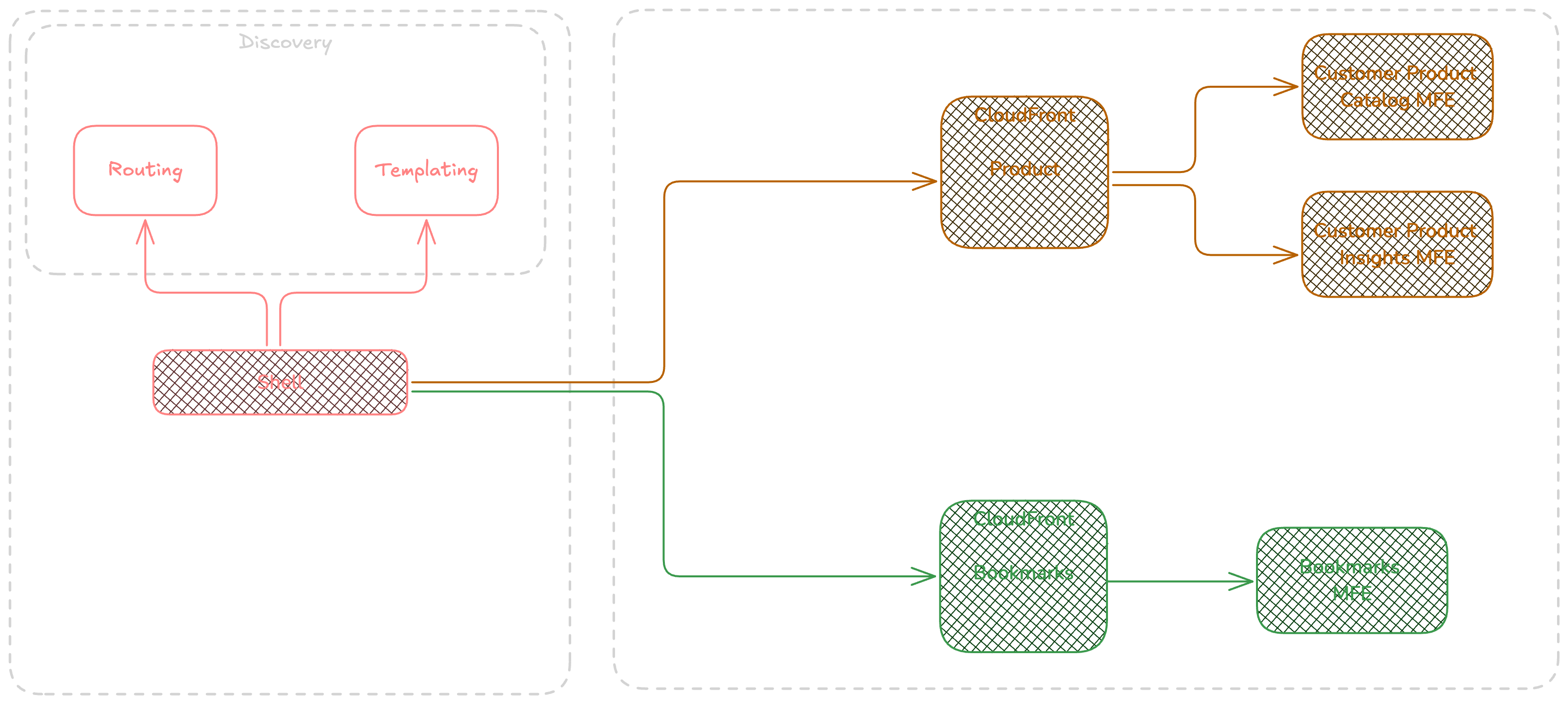
In the above diagram having product catalog and insights at the same layer ( server side ) helps to reduce the unnecessary downstream service calls but adds some challenges such as cache configuration. So putting two Components in the same MFE must be considered when those components follow the same lifecycle.
This is important to think about different decision axis to adopt the right approach based on requirements and tradeoffs.
Rendering
The choice of rendering approach depends on functional requirements and technical possibilities. My journey began with front-end development using VBScript, where code ran on the client side. However, limitations such as database connectivity and security concerns led to a shift towards server-side development with ASP.NET, where interactions and rendering were handled on the server. As JavaScript technologies advanced, particularly with the introduction of Ajax, the drawbacks of server-side latency became apparent. This prompted a shift back to client-side rendering, allowing for partial or full application rendering on the client side, with DOM manipulation and updates occurring after API responses were received. This approach was well-suited to the era of limited server resources and networking constraints.
However, as server capabilities improved, particularly with the advent of cloud computing and rapid scaling, it became advantageous to offload processing back to the server. Today, server-side rendering (SSR) is a crucial front-end design decision, thanks to its ability to respond in milliseconds and scale efficiently. However, it's not always the optimal choice and should be considered within the context of the overall architecture.
Rendering choices are critical and involve several factors, including:
User Experience
Performance
Cost
Search Engine Optimization (SEO)
While other considerations like Separation of Concerns (SoC) and polyglot ecosystems are important, the ones listed above are the primary focus here. In the context of Micro-Frontends, various rendering strategies can be employed, such as Client-Side Rendering (CSR), Edge-Side Rendering (ESR), Server-Side Rendering (SSR), and Server-Side Generation (SSG), which is a variation of SSR.
Client Side Rendering
CSR applies rendering of HTML content in the browser using javascript dynamically, But with CSR a preliminary content is received from the server containing the javascript and CSS, further the execution of those javascript in client side will lead to content rendering by calling the required api or backend services. Before the script execution, the content will be appeared and will be interactive.
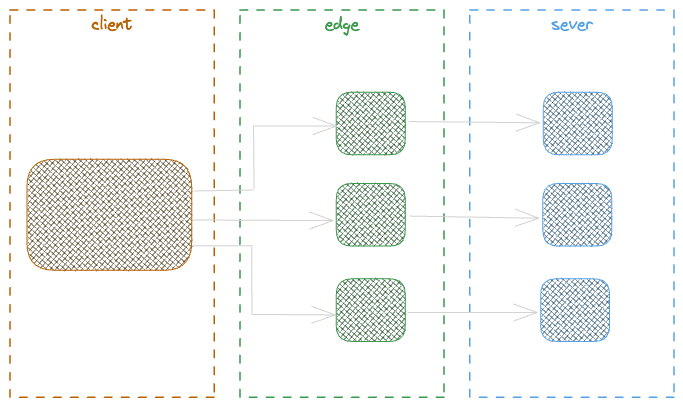
To see more how the CSR and SSR behave this video by Scott Hanselman is a nice one.
Server Side Rendering
SSR is all about rendering the HTML content at server side before returning to the client (browser), The server request can be done at the page load or behind any action with the ability to trigger a request. The server response contains the content but also all necessary scripts that lead to have interactive content on the client side.
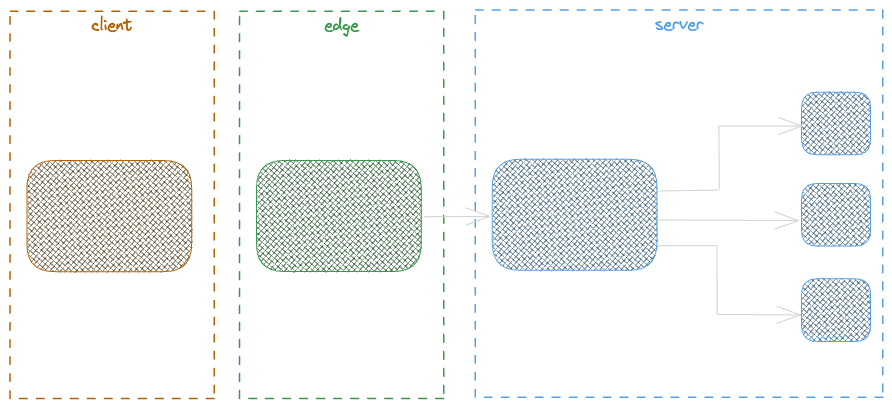
SSR can be applied in a variety of ways but listening to experts like Luca Mezzalira helps to capture enough and this video is a rich and detailed one
Server Side Generation
SSG is the technique of generating HTML assets in server side and let the client use the pre rendered assets, This is really close to the fact of using static assets but in SSG the asset content is HTML. The SSG is great if the number of required assets are limited but this can be tricky when dealing with millions of items. when using SSG it s important to consider how long and till when that assets is really required and estimate the resulting costs.
Edge Side Rendering
ESR helps to tackle some SSR challenges such as latency and performance, The ESR helps to respond to client request at Edge and benefit from the global Point of presence close to the user, aside of latency improvements by removing the full load on origin, ESR also helps to remove the load of processing on client side being a browser, mobile app or etc.. to achieve a more device friendly approach.
Orchestration
The Micro-Frontend orchestration is a pattern that is used to apply composition of different micro frontends and makes a final result that represents a page or a representable and meaningful part of a UI. The orchestration can be done in different levels being Client side, Server side or Edge side. and also an intelligent mix of them can be applied.
This article fundamentally focuses on Server Side Rendering and demonstrates some challenges the teams face while designing SSR.
Kernel / Shell
As discussed earlier, while Micro Frontends (MFE) offer significant benefits to the overall system, they can also introduce cross-domain challenges and coordination issues among teams as they work to integrate distributed components into a cohesive solution. To address these complexities, a shell (or kernel) adds a layer of abstraction between the client and the distributed services, streamlining communication and simplifying the composition process, ultimately leading to a more flexible design.
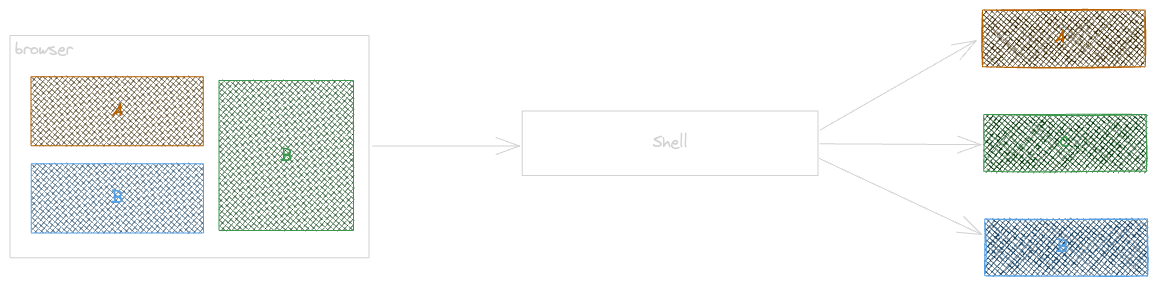
Implementing a shell offers the advantage of simplifying the previously mentioned requirements. It facilitates easier discovery of services and their versions, resolves template details, routes requests to the appropriate service based on the resolved template, and ultimately handles the composition.
A shell (or kernel) is particularly valuable when managing various types of rendering—whether client-side, edge-side, server-side, or a combination of these approaches.
A shell can respond to the following requirements if applied:
Service Discovery
Template Discovery and rendering
Service deployment strategy ( Canary, Rolling, All-At-Once )
Error handling and fallbacks
Instrumenting for Observability
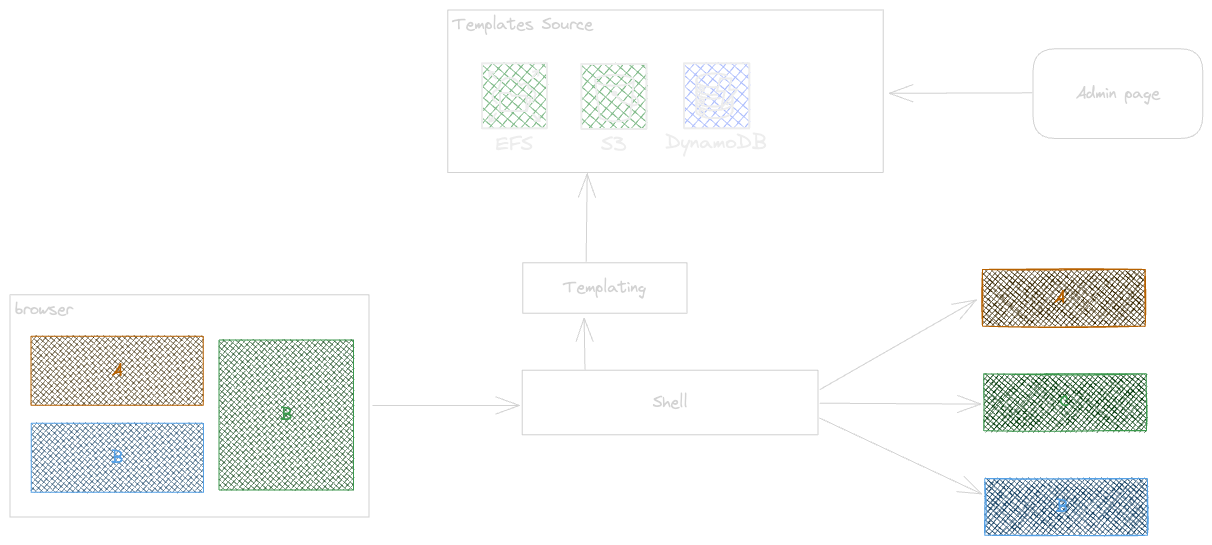
Templating
A template serves as a predefined framework that outlines the structure of the result set required by a client application, whether it's a browser or a mobile app. Consequently, the templating module must identify the appropriate template based on the request information received from the client. For instance, a template represents a page that includes various components such as scripts, meta tags, CSS references, and more.
At the first glance maybe templating is not really interesting approach but it helps to resolve a lot of frontend cross cutting concerns like shared scripts, design systems , and etc, without changing and deploying all MFEs or client app.
Discovery & Routing
Discovery is the process of locating the appropriate services based on identifiers, versions, and other factors. It provides a more granular approach to integrating services and the fundamental aspects of a distributed design with reduced complexity.
A high-level implementation of discovery would look like this:
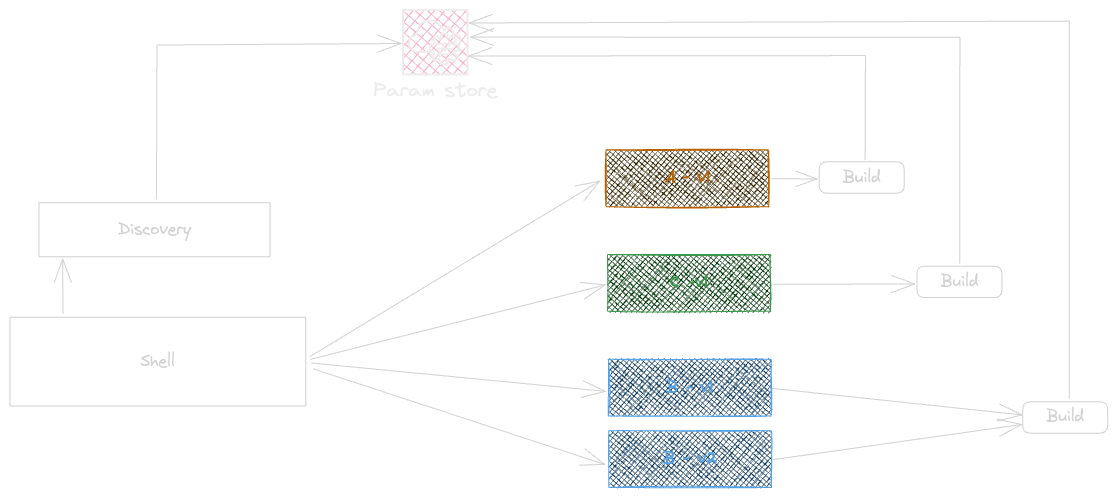
The routing module is responsible for directing external and public service requests to the appropriate internal or private distributed services. An effective routing module takes into account the deployment strategy and the type of composition, whether server-side, client-side, or edge-side.
The diagram illustrates the routing process when server-side composition is used.
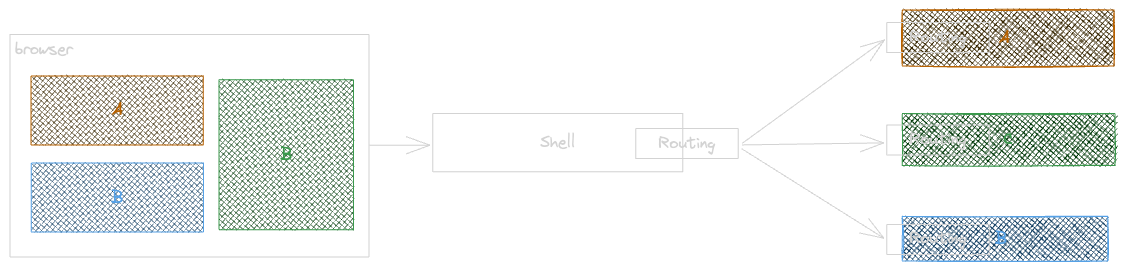
Routing can be handled either by the Web Server or the Shell. When the Shell manages routing, it performs lightweight mapping based on the incoming request and the associated micro-frontend. The Shell directs traffic to the appropriate service and conducts basic contextual and generic checks. More detailed routing, which requires domain-specific knowledge, is managed within the micro-frontend itself. This includes scenarios such as applying a specific version for an individual customer or a particular list of products.
Shell Challenges
When designing a shell the most important thing to consider is to design a shell agnostic of business details, often the teams start light and brings incrementally the complexity into shell for a single reason, and this is the shell is already there and the easiest way for change. But at longterm this will lead to have a higher risk of changes and distributed knowledge. why this is risky ? a shell can be central and need to be evolved by a wide range of teams, this becomes tricky in long run.
What we gonna build
The following diagram shows the application we are building for this article, we will build a simple react application providing a client application that interact with server side resources via a shell ( Kernel ) that provides the discovery & routing, and templating and a light Api to help the micro-frontends communicate together. Each micro-frontend provides the html in response which will be shown in our Web App.
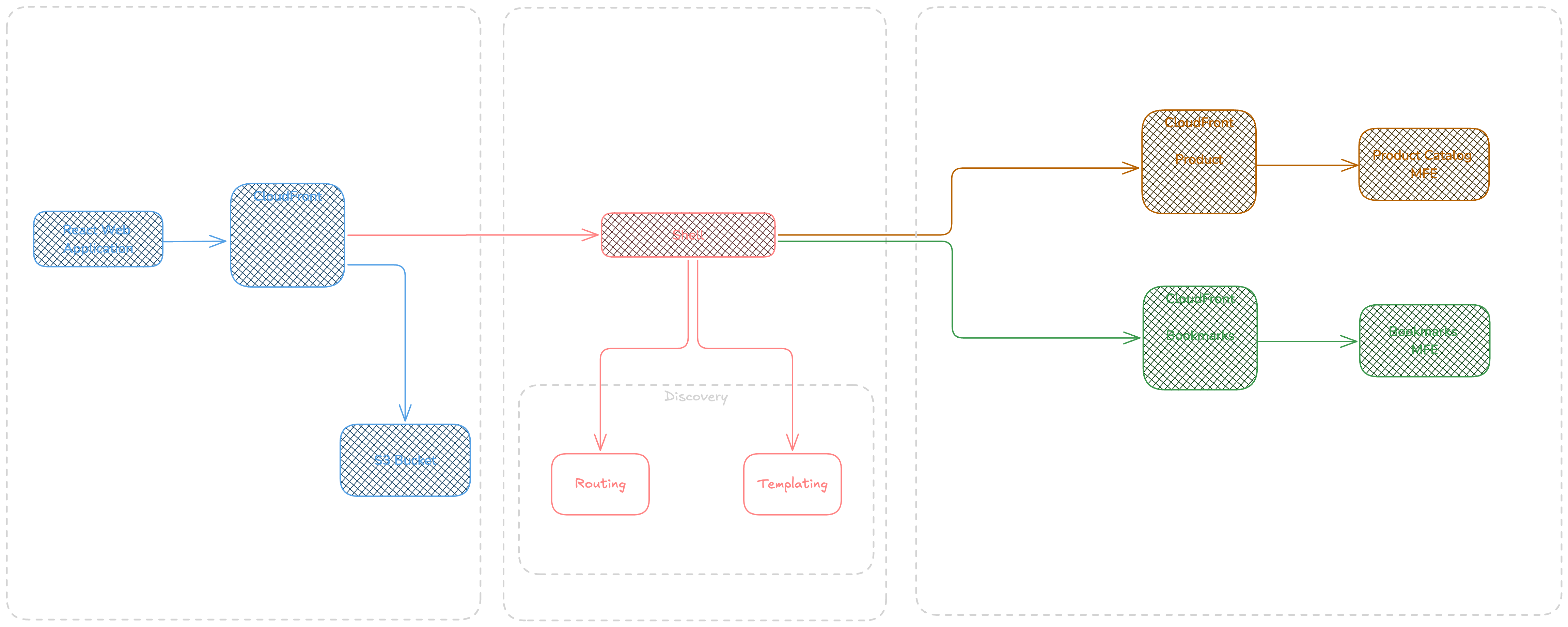
Source Code
The example related to this part of series is Part-01 branch in following Github repository.
Bookmarks
The Bookmarks Micro frontend stack has the responsibility of returning the bookmarks for a given userid, the bookmarks MFE validates the presence of UserId parameter and returns the results for the corresponding user.
In bookmarks service, the bookmarks list MFE is vertically sliced, but all downstream service calls can be managed if required.
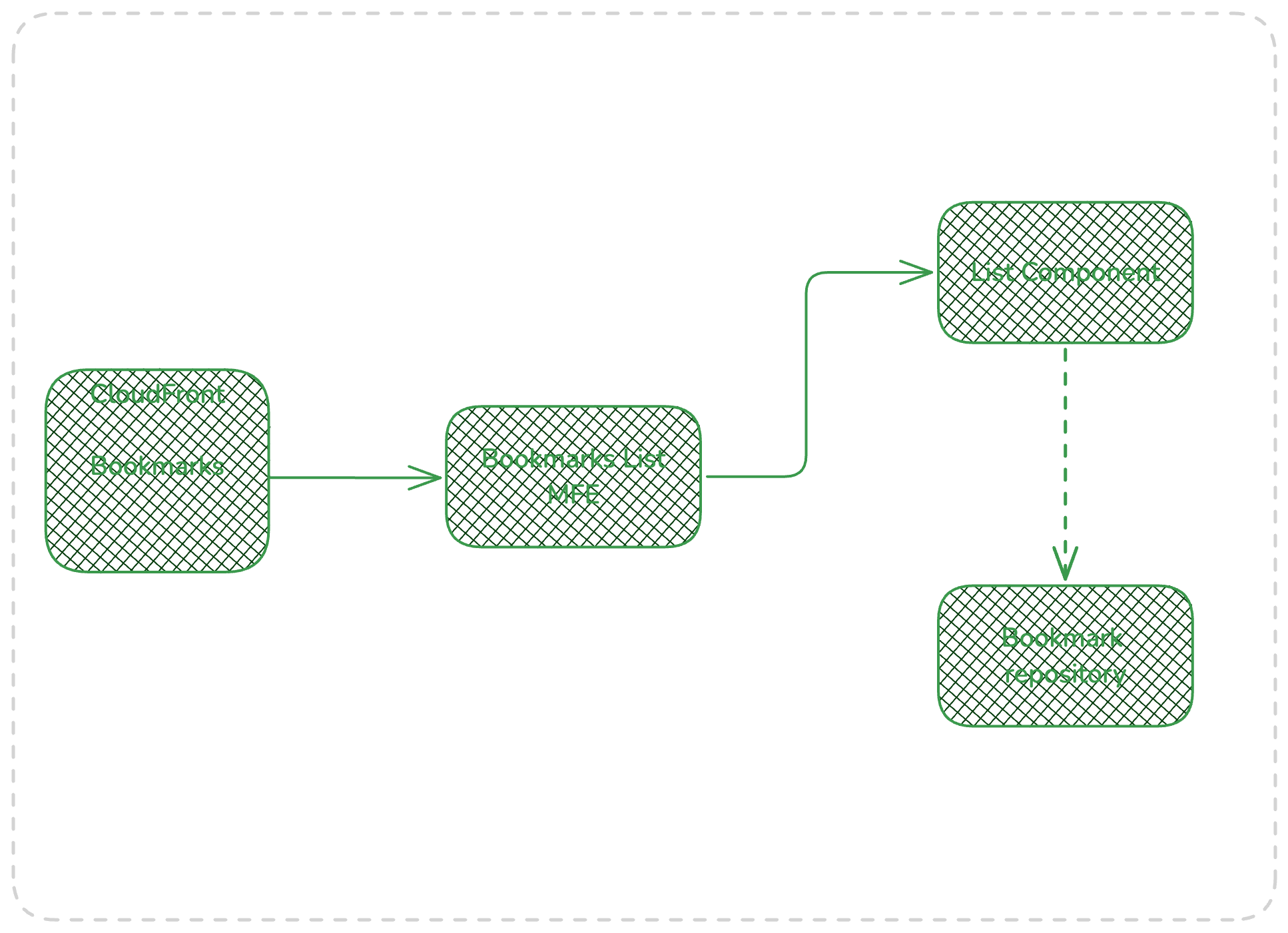
The bookmarks list mfe returns all bookmarks for given userid and returns an 4xx error if the userid not provided. also it applies the filtering of user bookmarks per product reference and name if applied.
The caching is applied per query string parameters including userid, ref, name. the following snippet represents the CDK example for bookmark service and related configuration.
The bookmarks distribution owns the caching requirements of bookmarks service, this is related to the way that each service owns and master its proper requirements.
this.Distribution = new Distribution(this, 'BookmarkDistribution', {
...
defaultBehavior: {
origin: new FunctionUrlOrigin(props.DefaultOriginListBookmarksFunctionUrl, {
connectionAttempts: 3,
connectionTimeout: Duration.seconds(1),
keepaliveTimeout: Duration.seconds(5),
}),
allowedMethods: AllowedMethods.ALLOW_ALL,
cachedMethods: AllowedMethods.ALLOW_GET_HEAD_OPTIONS,
cachePolicy: new CachePolicy(this, 'BookmarksCachePolicy', {
queryStringBehavior: CacheQueryStringBehavior.allowList(
'userid',
'ref',
'name'
),
defaultTtl: Duration.hours(1),
minTtl: Duration.hours(0),
maxTtl: Duration.hours(24),
}),
viewerProtocolPolicy: ViewerProtocolPolicy.REDIRECT_TO_HTTPS,
originRequestPolicy: OriginRequestPolicy.ALL_VIEWER_EXCEPT_HOST_HEADER,
},
});
const cfCfnDist = this.Distribution.node.defaultChild as CfnDistribution;
const bookmarksOriginAccessControl = new CfnOriginAccessControl(this, 'LambdaUrlOAC', {
originAccessControlConfig: {
name: `Bookmarks-Lambda-OAC`,
originAccessControlOriginType: 'lambda',
signingBehavior: 'no-override',
signingProtocol: 'sigv4',
}
});
cfCfnDist.addPropertyOverride(
'DistributionConfig.Origins.0.OriginAccessControlId',
bookmarksOriginAccessControl.getAtt('Id')
);
The cloudfront and function url integration is done using OAC Signature V4, the function url grants the permissions to let the calls only be authorized only from cloudfront.
this.FunctionUrl.grantInvokeUrl(new ServicePrincipal('cloudfront.amazonaws.com', {
conditions: {
ArnLike: {
'aws:SourceArn': `arn:aws:cloudfront::${account}:distribution/XXXXXXXXX`,
},
StringEquals: { 'aws:SourceAccount': account},
}
}));
Products
The Product service provides two distinct MFEs being catalog and Product Details Page ( PDP ), those are independent and isolated ones.
The product service follows same implementation and application architecture principles as bookmarks so vertically sliced and optimized for potential reusability needs. Here, the important note is possibility of sharing the repository layer, this is not an interest from programming perspective but more communication, as this let us to simply have multiple MFEs and apply composition for different components inside one MFE and reducing the number of network calls or Database calls.
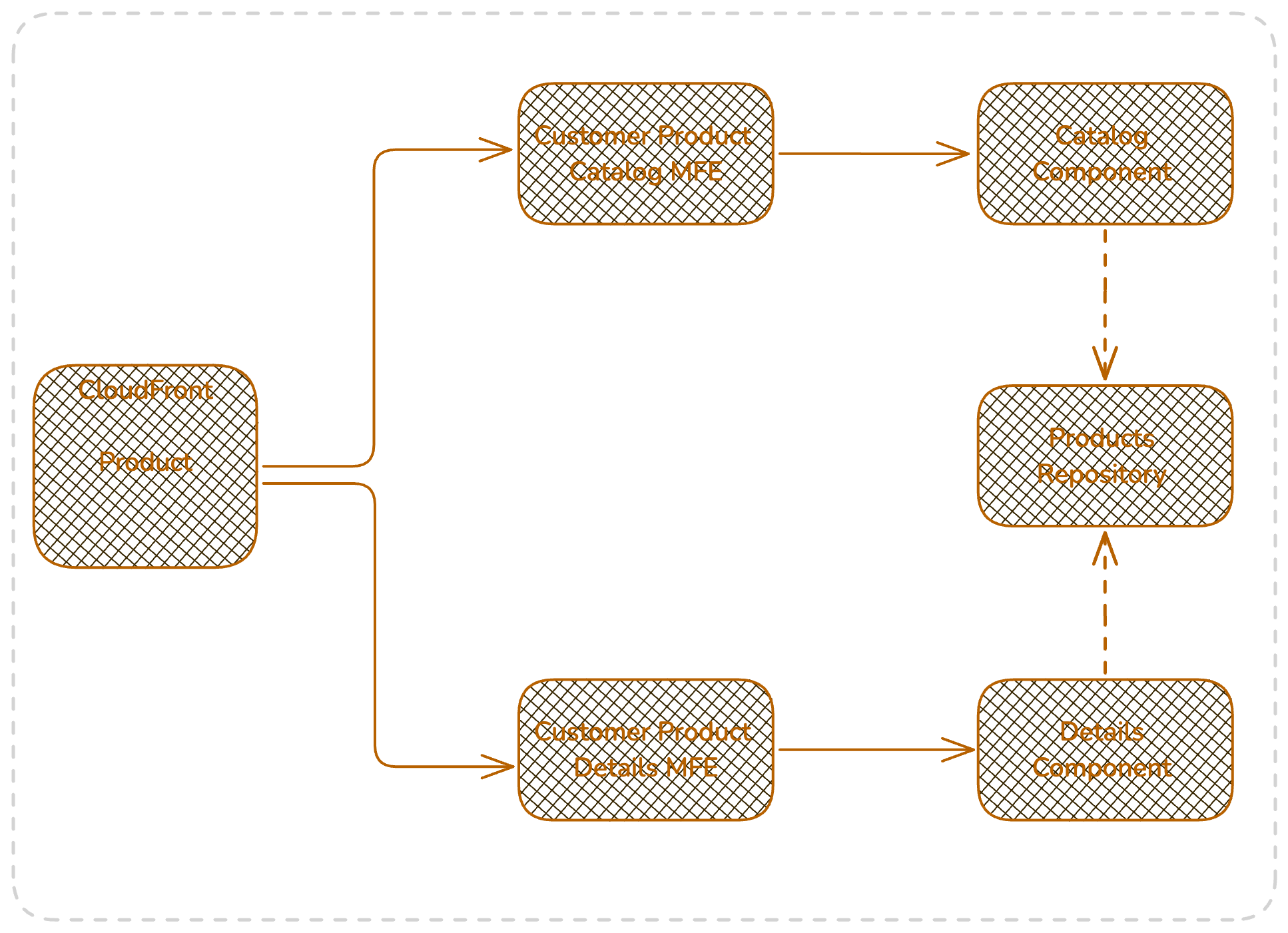
The products service follows the same principals as bookmarks in terms of caching, security and uses also lambda function url for api invocations.
Web Application
The web application consists of Two pages , home page and product details page, the home page serves as a landing for bookmarks , and catalog micro frontends, while the PDP hosts only the product details micro frontend.
The Web app home page includes two MFEs , Product Catalog and bookmarks list, but this is a different case from the previous interests we had when optimizing to reduce network calls. The interest here applies more on organizational and bounded context.
Each micro-frontend is owned and runs by different team
Each one has its proper context so database or downstream service calls
There is no domain context based relation between them.
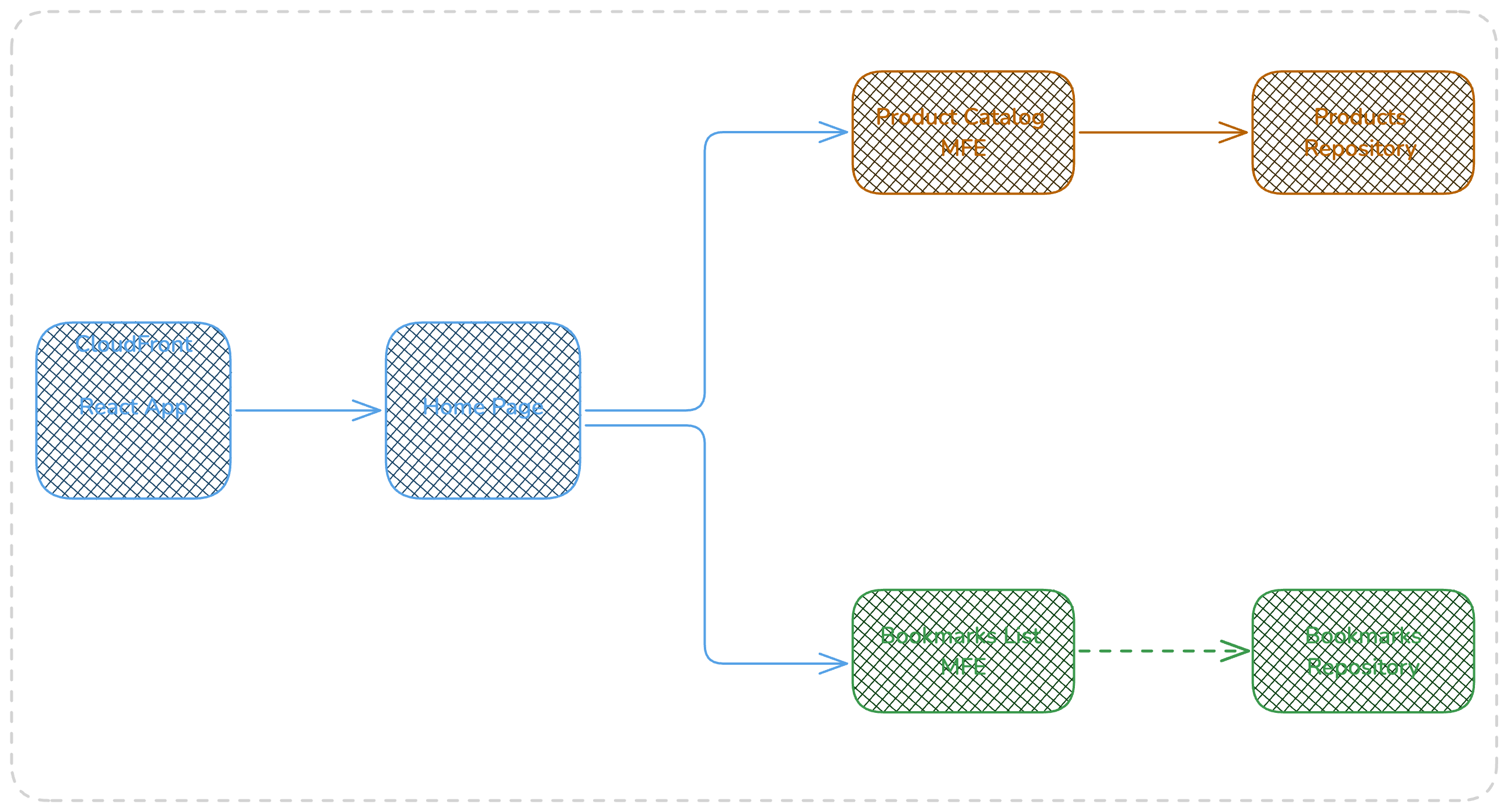
In this diagram the react app calls both MFEs in parallel and use the received results as html assets that live side by side. The website build assets will be uploaded on a dedicated bucket that will be as the default behavior of web app cloudfront. The web app cloudfront applies the required caching for static web site assets, but for dynamic routes as the ones related to home page calls, bookmarks and catalog, and product details page applies no caching but only forward the requests to the downstream MFE servies.
Bundling
To bundle the website app, the build is done using react-scripts build command, the bundle results will be deployed to the web app s3 bucket using CDK BucketDeployment construct.
new BucketDeployment(this, 'BucketDeployment', {
sources: [ Source.asset(join(process.cwd(), '/front-app/website/build')) ],
cacheControl: [CacheControl.fromString('max-age=1800,must-revalidate')],
destinationBucket: frontStack.Bucket,
distribution: ditribution.Distribution,
distributionPaths: ['/*'],
});
The use of BucketDeployment is for sake of demonstration but in real projects the deployment process must be under a dedicated cicd pipeline with multiple stages including CI ( linting, testing, analysis, etc.) and CD.
Caching
The cloudfront behavior for the dynamic content will use a dedicated CachePolicy and OriginAcessPolicy applying no caching but forwarding all request QueryString parameters.
const dynamicContentCachePolicy = new CachePolicy(this, 'DynamicContentCachePolicy', {
headerBehavior: CacheHeaderBehavior.none(),
cookieBehavior: CacheHeaderBehavior.none(),
queryStringBehavior: CacheHeaderBehavior.none(),
defaultTtl: Duration.seconds(0),
minTtl: Duration.seconds(0),
});
const dynamicContentOriginRequestPolicy = new OriginRequestPolicy(this, 'DynamicContentOriginRequestPolicy', {
queryStringBehavior: OriginRequestQueryStringBehavior.all(),
headerBehavior: OriginRequestHeaderBehavior.none(),
cookieBehavior: OriginRequestCookieBehavior.none()
});
this.Distribution.addBehavior('api/v1/bookmarks/*', new HttpOrigin(props.BookmarkServiceDomainName), {
allowedMethods: AllowedMethods.ALLOW_ALL,
cachePolicy: dynamicContentCachePolicy,
viewerProtocolPolicy: ViewerProtocolPolicy.REDIRECT_TO_HTTPS,
originRequestPolicy: dynamicContentOriginRequestPolicy
});
Rendering
The underlying code for the example website will be a simple react app, using useEffects react hook to fetch the data on page load.
useEffect(() => {
async function RenderMFEs() {
const promiseProcessSuccess = 'fulfilled';
await Promise.allSettled([
fetchMfe(Mfes.BOOKMARKS_LIST),
fetchMfe(Mfes.PRODUCT_CATALOG),
]).then((results) => {
results.forEach((result) => {
if (result.status === 'rejected') console.error('HP error :', result.reason) });
if (results[0].status === promiseProcessSuccess) setBookmarks(results[0].value);
if (results[1].status === promiseProcessSuccess) setCatalog(results[1].value);
});
};
if (!bookmarks || !catalog)
RenderMFEs();
}, [bookmarks, catalog]);
The following code demonstrates the FetchMfe() function, which is called in useEffect react hook.
export const enum Mfes {
'PRODUCT_DETAILS',
'BOOKMARKS_LIST',
'PRODUCT_CATALOG',
}
export const Paths: Record<Mfes, string> = {
[Mfes.PRODUCT_DETAILS]: '/api/v1/products/details/',
[Mfes.PRODUCT_CATALOG]: '/api/v1/products/catalog/',
[Mfes.BOOKMARKS_LIST]: '/api/v1/bookmarks/',
}
export const fetchMfe = async (MFE: Mfes, host?: string): Promise<string> => {
const hostDomain = `${window.location.protocol}//${window.location.host}/`;
let urlPath = '';
urlPath = urlPath.concat(Paths[MFE]);
const url = new URL(urlPath, hostDomain);
const queryParameters = new URLSearchParams(window.location.search);
if(queryParameters) url.search = queryParameters.toString();
const res = await fetch(`${url.href}`);
return await res.text();
}
Redirection
As per requirement the redirection of certain URLs are important for SEO and brand trustworthy on the public, this is the case when certain links are no more valuable or has no corresponding result ( ex. when a product get out of stock or a url is deleted permanently).
The following CDK shows how to use a CloudFront Function to apply simple redirection for specific paths. The CloudFront functions use a lightweight version of Javascript. This way we can easily apply the redirection on top of specific urls under a distribution behavior and let the crawler to accumulate the old url score and brings them to the new redirected url ( this is how google indexation works when the permanent redirection is applied)
Thanks to David Behroozi sharing the great and cost effective solution for redirection. This sections use the mentioned solution for our dedicated purpose.
defaultBehavior: {
allowedMethods: AllowedMethods.ALLOW_GET_HEAD,
origin: webbucketOrigin,
cachedMethods: AllowedMethods.ALLOW_GET_HEAD,
cachePolicy: WebCachePolicy,
viewerProtocolPolicy: ViewerProtocolPolicy.REDIRECT_TO_HTTPS,
functionAssociations: [
{
function: new Function(scope, `ProductRedirectFunctionViewerResponse`, {
code: FunctionCode.fromFile({ filePath: `front-app/src/url-redirect.js`}),
runtime: FunctionRuntime.JS_2_0
}),
eventType: FunctionEventType.VIEWER_RESPONSE,
},
]}
The CloudFront function will be triggered at viewer response CloudFront event source trigger stage and applies a 301 permanent redirection.
The solution uses the s3 user-defined metadata to register the redirection target link.
// @ts-ignore
function handler(event) {
console.log(JSON.stringify(event, null, 2));
const response = event.response,
headers = response.headers,
request = event.request;
const header = 'x-amz-meta-location';
if (
'GET' == request.method &&
200 == response.statusCode &&
headers[header] &&
headers[header].value
) {
headers.location = { value: headers[header].value };
return {
statusCode: 301,
statusDescription: 'Moved Permanently',
headers,
};
}
return response;
}
The example ues BucketDeployment construct to upload a single file with corresponding metadata.
new BucketDeployment(this, 'RedirectionDeployment', {
sources: [ Source.asset(join(process.cwd(), '/front-app/src/redirection-files')) ],
metadata: {
'location': `https://${ditribution.Distribution.distributionDomainName}/?category=ON_SOLD`,
},
destinationBucket: frontStack.Bucket,
prune: false,
});
In this example all files in redirection-files folder will be uploaded with a location to the s3 bucket. but in real projects it can be any dedicated back-office generating files with corresponding metadata.
Shell
The shell is responsible for composing a template from different independent micro-frontends and returning the final result asset to the client app. The shell also applies some cross cutting concerns such as Authentication/Authorization, Graceful Degradation and Logging while acceding server side resources.
One of the most popular responsibilities of a shell is service (MFEs) discovery, a service discovery considers also the deployment strategy if applies, such as wighted , canary or Blue/Green.
A shell often impose an standard such as following example that can be integrated in a template as demonstrated below
<MfeTag
src='...'
error-handling='fallback'
fallback='...'
options='cors,auth,apikey,tls'
timeout=1000
passthrough='cookies=[...],query=[...],headers=[...]'
strategy='canary'
/>
The above example represent a a simple custom HTML tag indicating under which constraints the MFEs communication shall be done.
in this example the shell will send a http call to the backend
| Attribute | Description | Remarks |
| Src | The path to the MFE | This is often over HTTPS protocol but can be any other protocol such as TCP, WSS direct Lambda Request/Response invocation, StepFunctions sync execution, etc. |
| Erro-Handling | Indicates how will handle the overall template behavior in case of failures | The possible values are: Fail, Fallback, Degradation |
| Fallback | The fallback url to call if the src will be unavailable | This is often over HTTPS protocol but can be any other protocol such as TCP |
| Options | The options indicates standard cross cutting concerns related to this call | Possible values are: ApiKey, Authorization, Cors, mTLS, SignatureV4 |
| Timeout | The MFE corresponding max waiting time for a response | This is in milliseconds |
| Passthrough | How the shell transfers the cookies , query string or headers to the MFE, if not present all parameters will be transited to the MFE | This can be customised based on the enterprise requirements |
| Strategy | This indicates the how the shell must consider the deployment strategy, Possible values are canary, bluegreen, weighted | The extra details per strategy will be fetched from discovery service , for example for canary the shell fetch the corresponding canary strategy like 10PercentPer5Minutes, To achieve an effective strategy the shell must be able to track state ( stateful ) |
In the next part of this series we will deep dive in the implementation details and design tradeoffs while considering a shell as a candidate to be user or not. The next part will focus on how to achieve a valuable shell and when consider applying a shell or adopt a simplified approach with less cognitive load but with a distributed responsibility at MFE sides per servie or Context.
Running the Example
To run the example locally, The backend MFEs must be ran on a local host server to let the local react website be functional. We use a simple way of running the typescript services locally over localhost( port 4242) to achieve local distributed MFEs and let the website communicate over localhost with MFEs.
The provided local server script is a simplified version of the script i used previously to run the backend lambda services with a minimum overhead and dependencies. A thanks to Zied Ben Tahar for giving the indications and helps to make this functional while we worked together at Aviv.
First, Lets deep a bit to see how this works. The script simply loop through an array of entrypoint and invoke the configured function which is exported.
const handleRoute = async (lambdaEntry: { entryPoint: string, handlerFn?: string, action?: (...args: any) => void }, req: Request, res: Response ) => {
const module = await import(lambdaEntry.entryPoint);
const lambdaFunctionHandler = module[lambdaEntry.handlerFn ?? "handler"];
const result = await lambdaFunctionHandler(
generateEvent(req),
createLambdaContextObjectFromContextPayload(req.body.context)
);
return res.send(result.body).end();
}
The entrypoints are the ts or tsx files, imported using dynamic import.
also the script uses the express to setup a local server using some defined middleware to use and the express router and provide all http verbs for each entrypoint.
const app = express();
app.use(cors());
app.use(express.json());
app.use(express.text());
app.use(express.raw());
app.use(express.urlencoded({ extended: true }));
const router = express.Router();
lambdasEntrypoints.forEach((lambdaEntry) => {
router.all(`/${lambdaEntry.endpoint}/`, async (req: Request, res: Response) => {
return handleRoute(lambdaEntry, req, res);
});
});
The Entrypoints configs are configured as an array of entrypoints and are fetched using the glob package. The paths correspond to the corresponding MFEs real origin behavior to avoid changing the website code just for local testing.
export type ConfigSource = { path: string, source: string, handlerFn?: string, action?: (...args: any) => void };
const configs: ConfigSource[] = [
{ path: "api/v1/bookmarks/", source: 'micro-fronends/bookmarks/src/handlers/list/index.ts' },
{ path: "api/v1/products/catalog/", source: 'micro-fronends/products/src/handlers/catalog/index.ts' },
{ path: "api/v1/products/details/", source: 'micro-fronends/products/src/handlers/details/index.ts', action: (req: Request, res: Response) => { console.log(req); res.writeHead(302, {Location: `/api/v1/products/catalog/v1/?category=ON_SOLD`}).end();} },
];
export const lambdasEntrypoints = globSync(configs.map(src => src.source ?? './') , {
ignore: [
"**/**/node_modules/**",
"**/**/*..test.ts",
"**/**/*..spec.ts",
] }).map((entry: string) => {
const config = configs.find(c => c.source.includes(entry));
const entryPoint = join(process.cwd(), entry.split(path.sep).join(path.posix.sep)),
lambdaName = entry
.split(path.sep)
.slice(-1)[0]
.replace(".(ts|js)", ""),
endpoint = config?.path,
handlerFn = config?.handlerFn,
action = config?.action;
return { entryPoint, lambdaName, endpoint, handlerFn, action };
});
The example local MFEs can be started using following comand
$ npm run local:start
------------
[Local λ debugger]: Local lambda invoke debug server is running at http://localhost:4242
[Local λ debugger]: Discovered 3 lambdas entrypoints
[λ endpoint]: api/v1/bookmarks/
[exported functions]: handler
[λ endpoint]: api/v1/products/catalog/
[exported functions]: handler
[λ endpoint]: api/v1/products/details/
[exported functions]: handler
The website can be ran using folling command
$ npm run local:website
The package.json local:website script passes the local url using env variable and the Shared FetchMFE function look at this environment variable to decide where to look, principal host or the local.
{
"local:website": "REACT_APP_LOCAL_URL=http://localhost:4242 npm run start --prefix front-app/website"
}
Addressing the navigation to `http://localhost:3000/?userid=HJ-HnhYul_sm` url will fetch the user bookmarks and also the product catalog page as below

By adding the product reference as a query parameter the bookmarks and catalog will show only the corresponding references ( example http://localhost:3000/?userid=HJ-HnhYul_sm&ref=REF_2 )

The user auth will be as part of next article with shell implementation. the actual system pass all query string params to all the MFEs without considering the requirements of each MFE separately.
Conclusion
Applying a well architected Micro Frontend approach is highly similar to the micro services, it starts with curiosity, enthusiasm and rigor but can become complex and introduce the obstacles against the approach primer et goals.
Simplicity a principal to success but putting the right part in the right place and defining the responsibilities and boundaries are the crucial things to achieve a long term decision and design.
In this part of series, some simple and straightforward parts was discovered by a focus on representing the overall design goals and possibilities while adopting Micro Frontends.
The next part will deep dive in Shell implementation and all corresponding modules such as Discovery, Templating, Routing, and putting all pieces together for achieving run and build time advantages.
Subscribe to my newsletter
Read articles from Omid Eidivandi directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by