Create Your Own Cloudflare Workers AI LLM Playground Using NuxtHub and NuxtUI
 Rajeev R. Sharma
Rajeev R. Sharma
You might be wondering, 'Another LLM (Large Language Model) playground? Aren't there plenty of these already?' Fair question. But here's the thing: the world of AI is constantly evolving, and every day one new tool or another pops up. One such AI offering from NuxtHub was launched recently, and I couldn’t resist taking it for a spin. And let’s be honest—some of us just can't resist adding a 'dark mode', something the Cloudflare Workers AI models playground hasn’t embraced yet.
But beyond these practical reasons, there’s something even more satisfying: the joy of creation and learning. So, if you're ready to dive in, maybe you'll pick up some new concepts like Server-Sent Events, response streaming, markdown parsing, and, of course, deploying your own chat playground without any of the usual fuss. So, get comfy—however you like—and let's get started!
Project Overview
Alright, so what exactly are we going to create here? As you might have guessed already, we will be creating a chat interface to talk to different text generation models supported by Cloudflare Workers AI. Below is a brief list of capabilities we will build along the way:
Ability to set different LLM params, like temperature, max tokens, system prompt, top_p, top_k etc while keeping some of these optional
Ability to turn LLM response streaming on/off
Handle streaming/non-streaming LLM responses on both, the server and the client side
Parsing LLM responses for markdown and display it appropriately
Auto-scrolling the chat container as the response is streamed from the LLM endpoint
Adding the dark mode (this one is trivial but let's add it here for completeness)
This is how the interface will look when we are through this article:
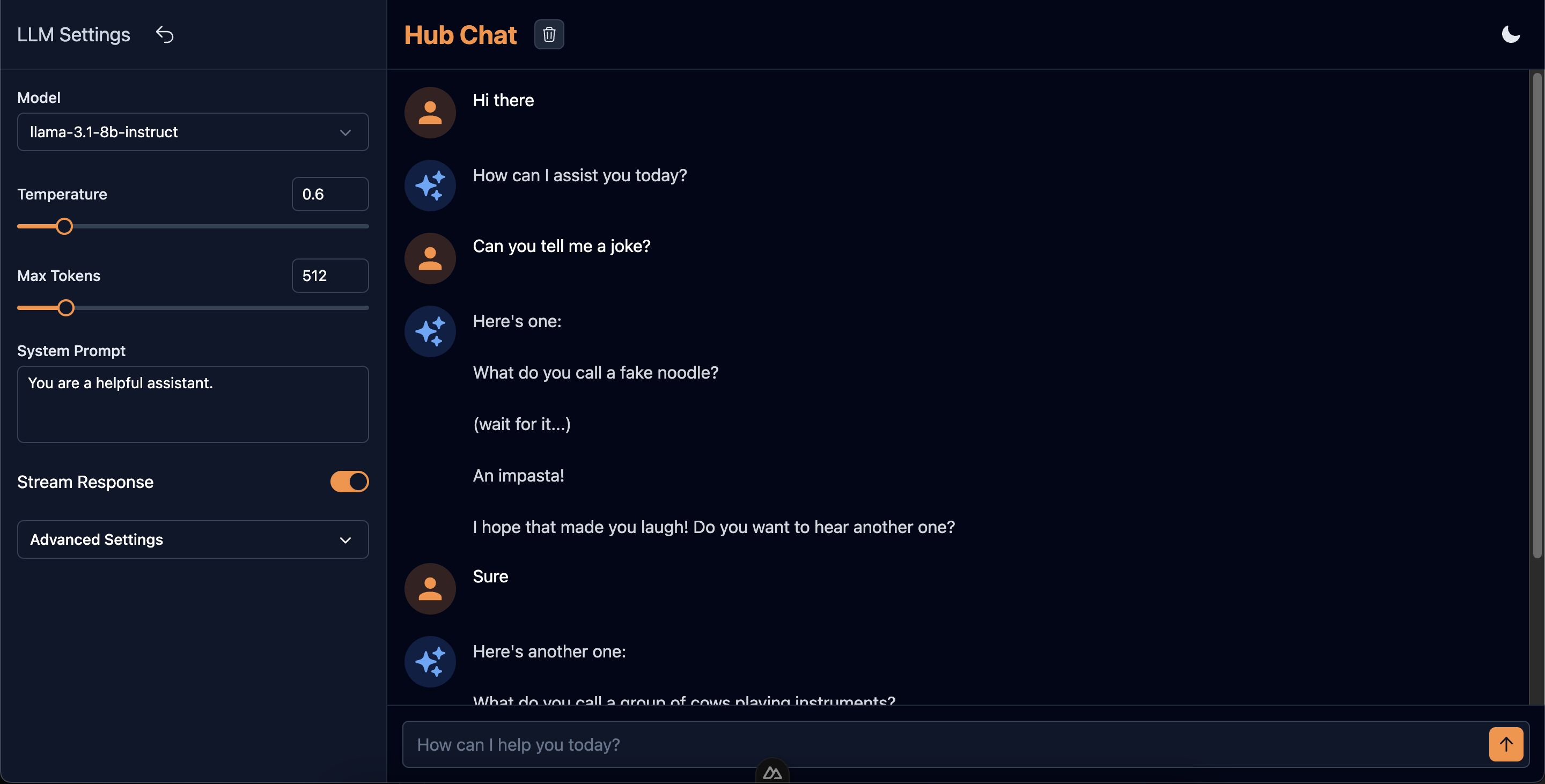
You can try it out live here: https://hub-chat.nuxt.dev/
We will cover each of the tasks in detail in the following sections.
Project Setup
Now that we've set the stage for our LLM playground project, let's dive into the technologies we'll be using and get our development environment ready.
Technologies we'll use
Nuxt 3: Nuxt 3 is a powerful Vue.js framework that will serve as the foundation of our application.
Nuxt UI: A Nuxt module that will help us create a sleek and responsive interface.
NuxtHub: NuxtHub is a deployment and administration platform for Nuxt, powered by Cloudflare. We can use NuxtHub to access different Cloudflare offerings like D1 database, Workers KV, R2 Storage, Workers AI etc. In this project, we'll use it to access the LLMs as well as to deploy our project
Nuxt MDC: For parsing and displaying the chat messages
Prerequisites
Apart from the basic prerequisites like Node/Npm, Code Editors, and some VueJs/Nuxt knowledge, you'll need the following to follow along:
A Cloudflare account: To use the Workers AI models, as well as to deploy your project on Cloudflare Pages for free. If you don't have it already, you can set it up here.
A NuxtHub Admin Account: NuxtHub admin is a web based dashboard to manage NuxtHub apps. You can create your account here.
Setting up the project
We can either start with a Nuxt (or Nuxt UI) template and add NuxtHub on top of it, or we can use the NuxtHub starter template and add Nuxt UI to it. We'll take the second approach:
Create a new NuxtHub project
# Init the project and install dependencies npx nuxthub init cf-playground # Change into the created dir cd cf-playgroundAdd the Nuxt UI module. The below command will install the @nuxt/ui dependency as well as add it as a module in your nuxt config file
npx nuxi module add uiSimilarly, add the Nuxt MDC module
npx nuxi module add mdc
Now we have setup everything that we need for this project. You can try running the project with pnpm dev (or an equivalent command if you're using a different package manager) and visit http://localhost:3000 in your browser. If you've dark mode enabled on your system then you'll notice that dark mode is already up and running in the project (We just need a way to toggle it).
With our development environment set up, we're ready to start building our LLM playground. In the next section, we'll begin implementing our user interface using NuxtUI components.
Creating the UI Components
First, we will create a component that will let us set numerical values for LLM settings using either a range slider or an input box. Let's call it RangeInput.
The RangeInput Component
We utilize a FormGroup component from NuxtUI to create this component. We put a Range slider in the default slot and an input in the hint slot to achieve the desired outcome. Here is the complete component code
<template>
<UFormGroup :label="label" :ui="{ container: 'mt-2' }">
<template #hint>
<UInput
v-model="model"
class="w-[72px]"
type="number"
:min="min"
:max="max"
:step="step"
/>
</template>
<URange v-model="model" :min="min" :max="max" :step="step" size="sm" />
</UFormGroup>
</template>
<script setup lang="ts">
const model = defineModel({ type: Number, default: undefined });
defineProps({
label: {
type: String,
required: true,
},
min: {
type: Number,
default: undefined,
},
max: {
type: Number,
default: undefined,
},
step: {
type: Number,
default: undefined,
},
});
</script>
Instead of taking the model value as a prop and then emitting the changes manually, we use the defineModel macro to achieve two way binding. If the initial model value is undefined the input box will be empty. This will help in making some of the LLM params optional.
The LLMSettings Component
LLMSettings component utilizes many RangeInputs that we created above as most of the settings are numerical values. Apart from RangeInputs we use a textarea for the system prompt, a toggle for enabling/disabling response streaming, a select menu for choosing the LLM model, and an accordion for hiding the optional params.
Here are the relevant parts of the component
<template>
<div class="h-full flex flex-col overflow-hidden">
<!-- Settings Header Code -->
<UDivider />
<div class="p-4 flex-1 space-y-6 overflow-y-auto">
<UFormGroup label="Model">
<USelectMenu
v-model="llmParams.model"
size="md"
:options="models"
value-attribute="id"
option-attribute="name"
/>
</UFormGroup>
<RangeInput
v-model="llmParams.temperature"
label="Temperature"
:min="0"
:max="5"
:step="0.1"
/>
<RangeInput
v-model="llmParams.maxTokens"
label="Max Tokens"
:min="1"
:max="4096"
/>
<UFormGroup label="System Prompt">
<UTextarea
v-model="llmParams.systemPrompt"
:rows="3"
:maxrows="8"
autoresize
/>
</UFormGroup>
<div class="flex items-center justify-between">
<span>Stream Response</span>
<UToggle v-model="llmParams.stream" />
</div>
<UAccordion
:items="accordionItems"
color="white"
variant="solid"
size="md"
>
<template #item>
<UCard :ui="{ body: { base: 'space-y-6', padding: 'p-4 sm:p-4' } }">
<RangeInput
v-model="llmParams.topP"
label="Top P"
:min="0"
:max="2"
:step="0.1"
/>
<!-- Other optional params -->
</UCard>
</template>
</UAccordion>
</div>
</div>
</template>
<script setup lang="ts">
type LlmParams = {
model: string;
temperature: number;
maxTokens: number;
topP?: number;
topK?: number;
frequencyPenalty?: number;
presencePenalty?: number;
systemPrompt: string;
stream: boolean;
};
const llmParams = defineModel('llmParams', {
type: Object as () => LlmParams,
required: true,
});
defineEmits(['hideDrawer', 'reset']);
const accordionItems = [
{
label: 'Advanced Settings',
defaultOpen: false,
},
];
const models = [
{
name: 'deepseek-coder-6.7b-base-awq',
id: '@hf/thebloke/deepseek-coder-6.7b-base-awq',
},
{
name: 'llama-3-8b-instruct',
id: '@cf/meta/llama-3-8b-instruct',
},
// ...other models
]
</script>
The ChatPanel Component
This is the most important component of all as it handles the core chat functionality of the app. It consists of three parts:
Chat Header
It displays the app name/label apart from some global buttons for clearing chats, dark mode toggling and for showing the settings drawer on mobile devices
<template>
<div class="flex items-center justify-between p-4">
<div class="flex items-center gap-x-4">
<h2 class="text-xl md:text-2xl text-primary font-bold">Hub Chat</h2>
<UTooltip text="Clear chat">
<UButton
color="gray"
icon="i-heroicons-trash"
size="xs"
:disabled="clearDisabled"
@click="$emit('clear')"
/>
</UTooltip>
</div>
<div class="flex items-center gap-x-4">
<ColorMode />
<UButton
icon="i-heroicons-cog-6-tooth"
color="gray"
variant="ghost"
class="md:hidden"
@click="$emit('showDrawer')"
/>
</div>
</div>
</template>
<script setup lang="ts">
defineEmits(['clear', 'showDrawer']);
defineProps({
clearDisabled: {
type: Boolean,
default: true,
},
});
</script>
Chats Container
For parsing and displaying the chat messages. It also shows a message loading skeleton when streaming is off, as well as a NoChats placeholder when needed.
<div ref="chatContainer" class="flex-1 overflow-y-auto p-4 space-y-5">
<div
v-for="(message, index) in chatHistory"
:key="`message-${index}`"
class="flex items-start gap-x-4"
>
<div
class="w-12 h-12 p-2 rounded-full"
:class="`${
message.role === 'user' ? 'bg-primary/20' : 'bg-blue-500/20'
}`"
>
<UIcon
:name="`${
message.role === 'user'
? 'i-mdi-user'
: 'i-heroicons-sparkles-solid'
}`"
class="w-8 h-8"
:class="`${
message.role === 'user' ? 'text-primary-400' : 'text-blue-400'
}`"
/>
</div>
<div v-if="message.role === 'user'">
{{ message.content }}
</div>
<AssistantMessage v-else :content="message.content" />
</div>
<ChatLoadingSkeleton v-if="loading === 'message'" />
<NoChats v-if="chatHistory.length === 0" class="h-full" />
</div>
To keep the user informed of the progress, we show a message loading skeleton when streaming is off. To do this we utilize a loading variable which can have three states: idle, message & stream. So when a non-streaming request is made we set the ref to message and the loading skeleton is shown.
User Message Textbox
For entering user message. It shows up as a single line textarea that resizes automatically when needed.
<div class="flex items-start p-3.5 relative">
<UTextarea
v-model="userMessage"
placeholder="How can I help you today?"
class="w-full"
:ui="{ padding: { xl: 'pr-11' } }"
:rows="1"
:maxrows="5"
:disabled="loading !== 'idle'"
autoresize
size="xl"
@keydown.enter.exact.prevent="sendMessage"
@keydown.enter.shift.exact.prevent="userMessage += '\n'"
/>
<UButton
icon="i-heroicons-arrow-up-20-solid"
class="absolute top-5 right-5"
:disabled="loading !== 'idle'"
@click="sendMessage"
/>
</div>
For allowing the user to send message on hitting enter, we use the keydown event listener with the needed modifiers (@keydown.enter.exact.prevent). Similarly, for adding a newline we use enter + shift keys.
Now that we have our UI components in place, let's shift our focus to the backend. We'll set up the AI integration and create an API endpoint to handle our chat requests. This will bridge the gap between our frontend interface and the AI model.
Setting up AI and API Endpoint
Integrating AI into our project is very simple thanks to NuxtHub. Let's look at our nuxt.config.ts file in the root dir of the project.
// https://nuxt.com/docs/api/configuration/nuxt-config
export default defineNuxtConfig({
compatibilityDate: '2024-07-30',
// https://nuxt.com/docs/getting-started/upgrade#testing-nuxt-4
future: { compatibilityVersion: 4 },
// https://nuxt.com/modules
modules: ['@nuxthub/core', '@nuxt/eslint', '@nuxtjs/mdc', "@nuxt/ui"],
// https://hub.nuxt.com/docs/getting-started/installation#options
hub: {},
// Env variables - https://nuxt.com/docs/getting-started/configuration#environment-variables-and-private-tokens
runtimeConfig: {
public: {
// Can be overridden by NUXT_PUBLIC_HELLO_TEXT environment variable
helloText: 'Hello from the Edge 👋',
},
},
// https://eslint.nuxt.com
eslint: {
config: {
stylistic: {
quotes: 'single',
},
},
},
// https://devtools.nuxt.com
devtools: { enabled: true },
});
To enable AI, we just need to add the ai: true flag under hub config options above. If needed, we can enable other NuxtHub Cloudflare integrations like D1 database (database: true), Workers KV (kv: true) etc. While we are here, we can remove runtimeConfig as we don't need it. (You can also remove/modify the eslint config as per your code editor settings).
If we want to use AI in dev mode (which we definitely do), we need to link this project to a Cloudflare project. This is needed as we will be talking directly to the Cloudflare APIs as no workers are running yet (and also because the AI usage will be linked to your Cloudflare account). This is a straight forward task, just run the following command
npx nuxthub link
Running the link command will make sure that we are logged into to our NuxtHub account, and will allow us to create a new NuxtHub project (backed by Cloudflare) or choose an existing one.
Creating Chat API Endpoint
Let's create a chat api endpoint. Create a new file chat.post.ts ("post" in the file name signifies that this endpoint will only accept HTTP POST requests) in the server/api directory and add the following code to it
export default defineEventHandler(async (event) => {
const { messages, params } = await readBody(event);
if (!messages || messages.length === 0 || !params) {
throw createError({
statusCode: 400,
statusMessage: 'Missing messages or LLM params',
});
}
const config = {
max_tokens: params.maxTokens,
temperature: params.temperature,
top_p: params.topP,
top_k: params.topK,
frequency_penalty: params.frequencyPenalty,
presence_penalty: params.presencePenalty,
stream: params.stream,
};
const ai = hubAI();
try {
const result = await ai.run(params.model, {
messages: params.systemPrompt
? [{ role: 'system', content: params.systemPrompt }, ...messages]
: messages,
...config,
});
return params.stream
? sendStream(event, result as ReadableStream)
: (
result as {
response: string;
}
).response;
} catch (error) {
console.error(error);
throw createError({
statusCode: 500,
statusMessage: 'Error processing request',
});
}
});
hubAI is a server composable that returns a Workers AI client for interacting with the LLMs. We pass the messages as well as the LLM params that we received from the frontend and run the requested model.
If you look at the above code carefully you'll notice that this endpoint supports both: streaming and non-streaming responses. To return a stream from the endpoint we just need to call the sendStream utility function.
We are through with our server side code. Let's look at how to handle the stream response on the client side in the next section.
Consuming Server Sent Events
Before diving into how to handle stream responses, let's understand why streaming is crucial for LLM interactions and how Server Sent Events (SSE) facilitate this process.
Why Stream LLM Responses with Server Sent Events?
Large Language Models (LLMs) can take considerable time to generate complete responses, especially for complex queries. Traditionally, web applications wait for the entire response before displaying anything to the user. However, this approach can lead to long waiting times and a less engaging user experience.
Server Sent Events (SSE) offer a solution to this problem.
Here's how SSE benefits LLM responses:
Immediate Feedback: As soon as the LLM starts generating content, it can be sent to the client and displayed, providing immediate feedback to the user.
Improved Perceived Performance: Users see content appearing progressively, giving the impression of a faster, more responsive system.
Real-time Interaction: The gradual appearance of text mimics human typing, creating a more natural and engaging conversational experience.
Technically, SSE works by establishing a unidirectional channel from the server to the client. The server sends text data encoded in UTF-8, separated by newline characters. This simple yet effective mechanism allows for real-time updates in web applications, making it ideal for streaming LLM responses.
Now that we understand the importance of streaming for LLM responses and how SSE enables this, let's look at how to implement this in our Nuxt 3 application.
Handling Server Sent Events with Nuxt 3 POST Requests
Since ours is a POST request, we need handle it differently. Nuxt 3 docs gives you an excellent starting point to do this. Reproducing the code from the docs
// Make a POST request to the SSE endpoint
const response = await $fetch<ReadableStream>('/chats/ask-ai', {
method: 'POST',
body: {
query: "Hello AI, how are you?",
},
responseType: 'stream',
})
// Create a new ReadableStream from the response with TextDecoderStream to get the data as text
const reader = response.pipeThrough(new TextDecoderStream()).getReader()
// Read the chunk of data as we get it
while (true) {
const { value, done } = await reader.read()
if (done)
break
console.log('Received:', value)
}
We need to set the request responseType flag as stream, and set the type of $fetch response as ReadableStream. Then we create a stream reader while decoding the received chunks by piping the events through a TextDecoder.
Below is a glimpse of the events data received from our chat endpoint (sent by the LLM)
data: {"response":"Hello","p":"abcdefghijklmnopqrstuvwxyz0123456789abcdefghij"}
data: {"response":"!","p":"abcdefgh"}
data: [DONE]
These events may contain more than one data line per event, and some events may not contain a complete JSON object (rest of the object will arrive with the next event). To handle this stream we can create a composable with a streamResponse generator function as shown below
export function useChat() {
async function* streamResponse(
url: string,
messages: ChatMessage[],
llmParams: LlmParams
) {
let buffer = '';
try {
const response = await $fetch<ReadableStream>(url, {
method: 'POST',
body: {
messages,
params: llmParams,
},
responseType: 'stream',
});
const reader = response.pipeThrough(new TextDecoderStream()).getReader();
while (true) {
const { value, done } = await reader.read();
if (done) {
if (buffer.trim()) {
console.warn('Stream ended with unparsed data:', buffer);
}
return;
}
buffer += value;
const lines = buffer.split('\n');
buffer = lines.pop() || '';
for (const line of lines) {
if (line.startsWith('data: ')) {
const data = line.slice('data: '.length).trim();
if (data === '[DONE]') {
return;
}
try {
const jsonData = JSON.parse(data);
if (jsonData.response) {
yield jsonData.response;
}
} catch (parseError) {
console.warn('Error parsing JSON:', parseError);
}
}
}
}
} catch (error) {
console.error('Error sending message:', error);
throw error;
}
}
// For handling non-streaming responses
async function getResponse() {}
return {
getResponse,
streamResponse,
};
}
To handle non streaming responses we can also create a simple $fetch call wrapper function in the same composable (check out the code in the linked Github Repo).
Now that we understand how to consume Server Sent Events and handle streaming responses, let's put all the pieces together in our main chat interface. We'll integrate the components we've built, set up the chat API call, and use our useChat composable to manage the LLM responses.
Final Chat Interface Page
The below is the final code of the index page (our app has only one page). Here we use all the components that we created before, and call the chat api endpoint. Then we use the useChat composable to handle the LLM responses.
<template>
<div class="h-screen flex flex-col md:flex-row">
<USlideover
v-model="isDrawerOpen"
class="md:hidden"
:ui="{ width: 'max-w-xs' }"
>
<LlmSettings
v-model:llmParams="llmParams"
@hide-drawer="isDrawerOpen = false"
@reset="resetSettings"
/>
</USlideover>
<div class="hidden md:block md:w-1/3 lg:w-1/4">
<LlmSettings v-model:llmParams="llmParams" @reset="resetSettings" />
</div>
<UDivider orientation="vertical" class="hidden md:block" />
<div class="flex-grow md:w-2/3 lg:w-3/4">
<ChatPanel
:chat-history="chatHistory"
:loading="loading"
@clear="chatHistory = []"
@message="sendMessage"
@show-drawer="isDrawerOpen = true"
/>
</div>
</div>
</template>
<script setup lang="ts">
import type { ChatMessage, LlmParams, LoadingType } from '~~/types';
const isDrawerOpen = ref(false);
const defaultSettings: LlmParams = {
model: '@cf/meta/llama-3.1-8b-instruct',
temperature: 0.6,
maxTokens: 512,
systemPrompt: 'You are a helpful assistant.',
stream: true,
};
const llmParams = reactive<LlmParams>({ ...defaultSettings });
const resetSettings = () => {
Object.assign(llmParams, defaultSettings);
};
const { getResponse, streamResponse } = useChat();
const chatHistory = ref<ChatMessage[]>([]);
const loading = ref<LoadingType>('idle');
async function sendMessage(message: string) {
chatHistory.value.push({ role: 'user', content: message });
try {
if (llmParams.stream) {
loading.value = 'stream';
const messageGenerator = streamResponse(
'/api/chat',
chatHistory.value,
llmParams
);
let responseAdded = false;
for await (const chunk of messageGenerator) {
if (responseAdded) {
// add the response to the current message
chatHistory.value[chatHistory.value.length - 1]!.content += chunk;
} else {
// add a new message to the chat history
chatHistory.value.push({
role: 'assistant',
content: chunk,
});
responseAdded = true;
}
}
} else {
loading.value = 'message';
const response = await getResponse(
'/api/chat',
chatHistory.value,
llmParams
);
chatHistory.value.push({ role: 'assistant', content: response });
}
} catch (error) {
console.error('Error sending message:', error);
} finally {
loading.value = 'idle';
}
}
</script>
This completes bulk of the coding. The only things remaining are:
Response parsing for markdown and display
Auto scrolling the chat container
Let's tackle these in the next section.
Polishing the Chat Interface
We will finish the remaining items in our task list now and call it a day. Stay with me, it won't take long now.
Using Nuxt MDC to Parse & Display Messages
If you look at the Chats Container code in one of the previous sections you'll notice a component AssistantMessage for displaying the response. Reproducing the relevant code here
<div v-if="message.role === 'user'">
{{ message.content }}
</div>
<AssistantMessage v-else :content="message.content" />
We use the parseMarkdown utility function from the MDC module that we included earlier to parse the content, and then use the MDCRenderer component from the same module for displaying it. To take care of streaming response we add a watch for the message content and redo the parsing with useAsyncData composable.
<template>
<MDCRenderer class="flex-1 prose dark:prose-invert" :body="ast?.body" />
</template>
<script setup lang="ts">
import { parseMarkdown } from '#imports';
const props = defineProps<{
content: string;
}>();
const { data: ast, refresh } = await useAsyncData(useId(), () =>
parseMarkdown(props.content)
);
watch(
() => props.content,
() => {
refresh();
}
);
</script>
<MDC> component instead of using parseMarkdown + <MDCRenderer> combination. <MDC> handles the parsing internally using the same parseMarkdown function, then why we didn't use it?The <MDC> component was causing overwriting of previous messages that were similar (the start of the message) to the latest message from the API endpoint. This happens because we don't have a unique key in our messages. Here is the relevant code from the <MDC> component.
const key = computed(() => hash(props.value))
const { data, refresh, error } = await useAsyncData(key.value, async () => {
if (typeof props.value !== 'string') {
return props.value
}
return await parseMarkdown(props.value, props.parserOptions)
})
As you can see, the key for useAsyncData is generated based on the content props value. So if the server streaming responses start with the same letters (e.g., Here's a joke..., Here's another...), the key will be same, and all similar previous responses from the server gets overwritten in the UI.
In the AssistantMessage component we are using useId composable to generate a unique id for each useAsyncData call, so the issue doesn't occur.
Using MutationObserver to Auto Scroll the Chats Container
In the ChatPanel component, the only scrolling part is the chats container. There can be other ways to observe the changes in the container but the simplest one I found is a MutationObserver.
MutationObserver interface provides the ability to watch for changes being made to the DOM tree.In the case of streaming, we keep appending new content to the latest message that is being displayed. So to handle this effectively, we create a MutationObserver, give it a target to watch (the ChatsContainer), and some criteria to watch for (childList, subtree & characterData).
Here is the relevant code to do this
const chatContainer = ref<HTMLElement | null>(null);
let observer: MutationObserver | null = null;
onMounted(() => {
if (chatContainer.value) {
observer = new MutationObserver(() => {
if (chatContainer.value) {
chatContainer.value.scrollTop = chatContainer.value.scrollHeight;
}
});
observer.observe(chatContainer.value, {
childList: true,
subtree: true,
characterData: true,
});
}
});
onUnmounted(() => {
if (observer) {
observer.disconnect();
}
});
When the ChatsPanel gets mounted we create a new MutationObserver which when based on the given criteria, we make the chats container scroll to its fullest.
Bonus: Handling the Dark Mode
As previously mentioned, the dark mode is already working; we just need a way to toggle it. We can also change the flavor of gray we want in the app. This can be done by adding an app.config.ts file in the app directory.
// app.config.ts
export default defineAppConfig({
ui: {
primary: 'orange',
gray: 'slate',
},
});
Add the following in your app.vue file for setting the required background colors.
<script setup lang="ts">
useHead({
bodyAttrs: {
class: 'bg-white dark:bg-gray-900',
},
});
</script>
And add a new ColorMode component in your app/components directory.
<template>
<ClientOnly>
<UButton
:icon="isDark ? 'i-heroicons-moon-20-solid' : 'i-heroicons-sun-20-solid'"
color="gray"
variant="ghost"
aria-label="Theme"
@click="isDark = !isDark"
/>
<template #fallback>
<div class="w-8 h-8" />
</template>
</ClientOnly>
</template>
<script setup lang="ts">
const colorMode = useColorMode();
const isDark = computed({
get() {
return colorMode.value === 'dark';
},
set() {
colorMode.preference = colorMode.value === 'dark' ? 'light' : 'dark';
},
});
</script>
Now you can use this color mode toggle button anywhere you like. In our app we've added it in the ChatHeader component.
Phew! And we have completed all the tasks we had set out to complete at the beginning of this article.
Deploying the App
You can deploy the project in multiple ways. I would recommend to do it through the NuxtHub Admin console. Push your code to a Github repository, link this repository with NuxtHub and then deploy from the Admin console.
But if you want to see it live right away then you can use the below command
npx nuxthub deploy
For more details on deployment you can visit the NuxtHub Docs.
Source Code
I only covered the most important parts of the source code here. You can visit the linked GIthub Repo for the complete source code. It should be self explanatory, but if you have question then please feel free to drop a comment below.
Conclusion
Congratulations! You've successfully built a feature-rich LLM playground using Nuxt 3, NuxtUI, and Cloudflare Workers AI through NuxtHub. We've covered a wide range of topics, including:
Handling streaming responses using Server Sent Events
Parsing and displaying markdown content in chat messages
Implementing auto-scrolling for a better user experience etc.
You can take this project as the starting point and improve it further by:
Adding the ability to talks to other types of LLMs, e.g. text-to-image, image-to-text, speech recognition etc.
Implementing user authentication and session management
Adding support for multiple conversation threads etc.
Thank you for staying till the end. I hope you learned some new concepts from this article. Do let me know your learnings in the comments section. Your feedback and experiences are valuable not just to me, but to the entire community of developers exploring this fascinating field.
Until next time!
Keep adding the bits and soon you'll have a lot of bytes to share with the world.
Subscribe to my newsletter
Read articles from Rajeev R. Sharma directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Rajeev R. Sharma
Rajeev R. Sharma
I build end-to-end apps in JavaScript with various frameworks and libraries, sharing detailed write-ups along the way. Lately, I've been experimenting with simple AI tools, while Nuxt remains my go-to fullstack framework. Occasionally, I dive into fun side projects, like crafting simple games with Python Turtle.