Kubernetes Scheduling - The Complete Guide
 Kunal Verma
Kunal Verma
If you’re involved in the cloud native ecosystem, chances are you’re already familiar with Kubernetes — the open source system for automating deployment, scaling, and management of containerized applications.
There are a lot of different components as part of the Kubernetes architecture, which are responsible for the efficient management of containerized workloads, which is key to running running reliable and scalable applications. One such component is the kube-scheduler, an essential component responsible for deciding where your applications run within the cluster.
But how does it do that? What are the steps involved in scheduling an application within the cluster? And why does it matter so much?
In this guide, we'll break down the essentials of scheduling in Kubernetes. We'll explore how the scheduler works behind the scenes, the techniques used to optimize pod placement, and the best practices to ensure your applications run smoothly.
What Does "Scheduling in Kubernetes" Mean?
In Kubernetes, scheduling is the entire process of assigning a pod (essentially, your application) to "the most appropriate or feasible node" in a cluster.
It’s very similar to assigning tasks to team members based on their strengths and current workload. Imagine you have a team of employees, each having different set of skills and capacity to work. When a new task comes in, you need to decide who is best suited to handle it. You wouldn't want to overload one person while another has nothing to do, right?
Similarly, Kubernetes uses scheduling to decide which node should run a new pod (a task).
This process is crucial because it ensures that your applications run efficiently without overloading any single node. If scheduling is done poorly, some nodes might become overwhelmed while others sit idle, leading to performance issues or even downtime — which we don’t want!
The Basics of Scheduling in Kubernetes
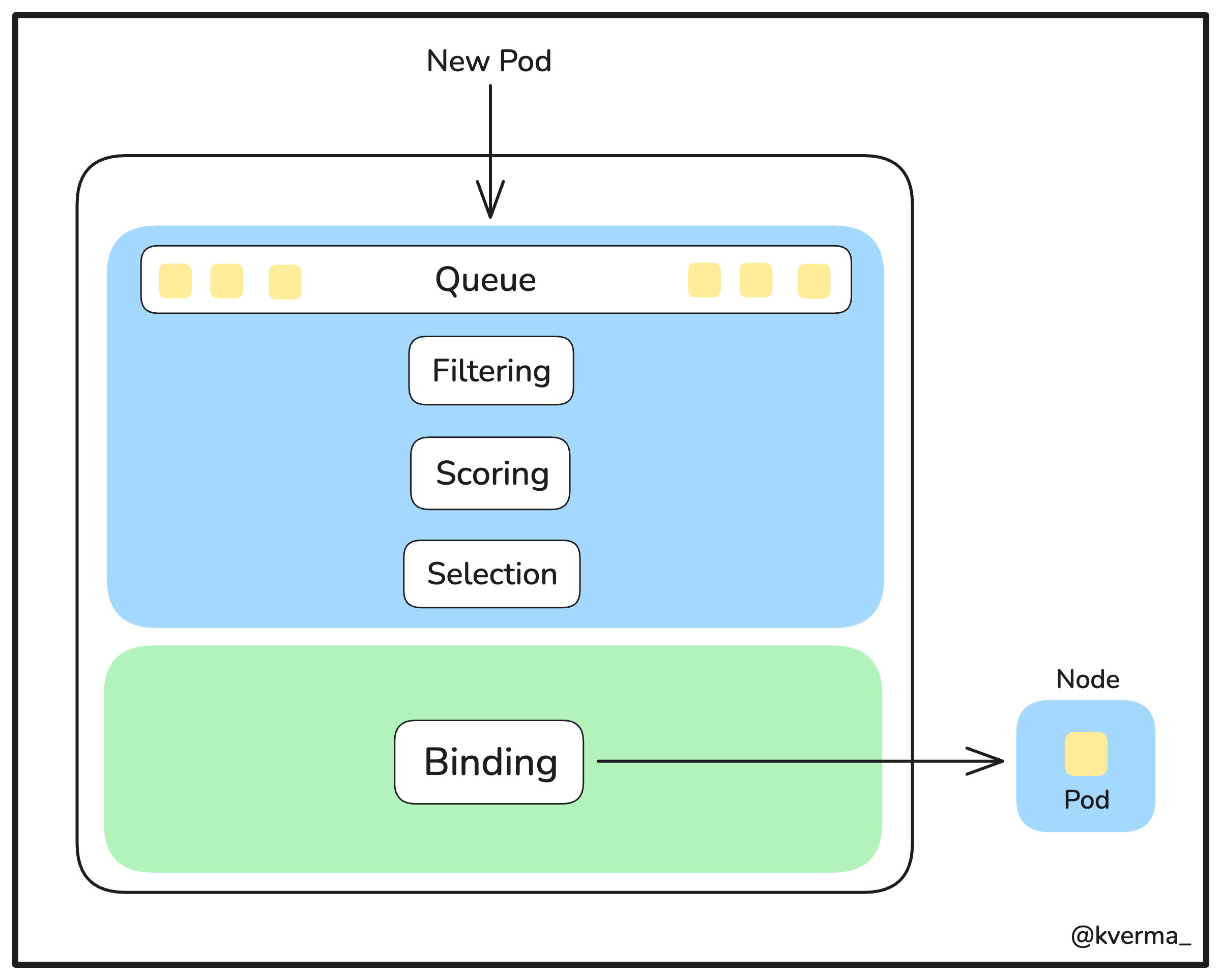
The kube-scheduler component in Kubernetes is responsible for this process. Its primary job is to find the best possible node for each newly created pod.
When a new pod is created, it doesn’t automatically know where to run or which node to choose — thus, it will be in a pending state. This is where the kube-scheduler steps in. It evaluates all the available nodes and selects the one that meets the pod's requirements, such as available CPU, memory, and any specific constraints that are applied by us like node labels or taints (we’ll talk about these next).
The goal is to ensure that each pod is placed in a way that maximizes resource utilization, avoids conflicts, and keeps the entire cluster running smoothly.
Now, there are a series of steps followed by the kube-scheduler to arrive at this decision. Let us have a look at those:
Node Filtering
The scheduler first filters out any nodes that don’t meet the basic requirements of the pod. For example, if a pod requests a specific amount of CPU or memory (let’s say 2GB), the scheduler will remove any nodes that don’t have at least 2GB of memory available. This ensures that only suitable nodes are considered.
Node Scoring
After filtering, the scheduler scores the remaining nodes based on how well they match the pod's needs. This includes factors like resource utilization and affinity rules. The goal is to find the most optimal node, not just one that meets the minimum requirements.
Node Selection
After the scoring phase, the node with the highest score is selected and declared as “the most feasible” one for the pod.
Pod Binding
Once a node is selected, the scheduler communicates this decision back to the API Server. The API Server then updates the pod's status to show that it is "
bound" to a specific node. The kubelet on that node then takes over, pulling the necessary container images and starting the pod.
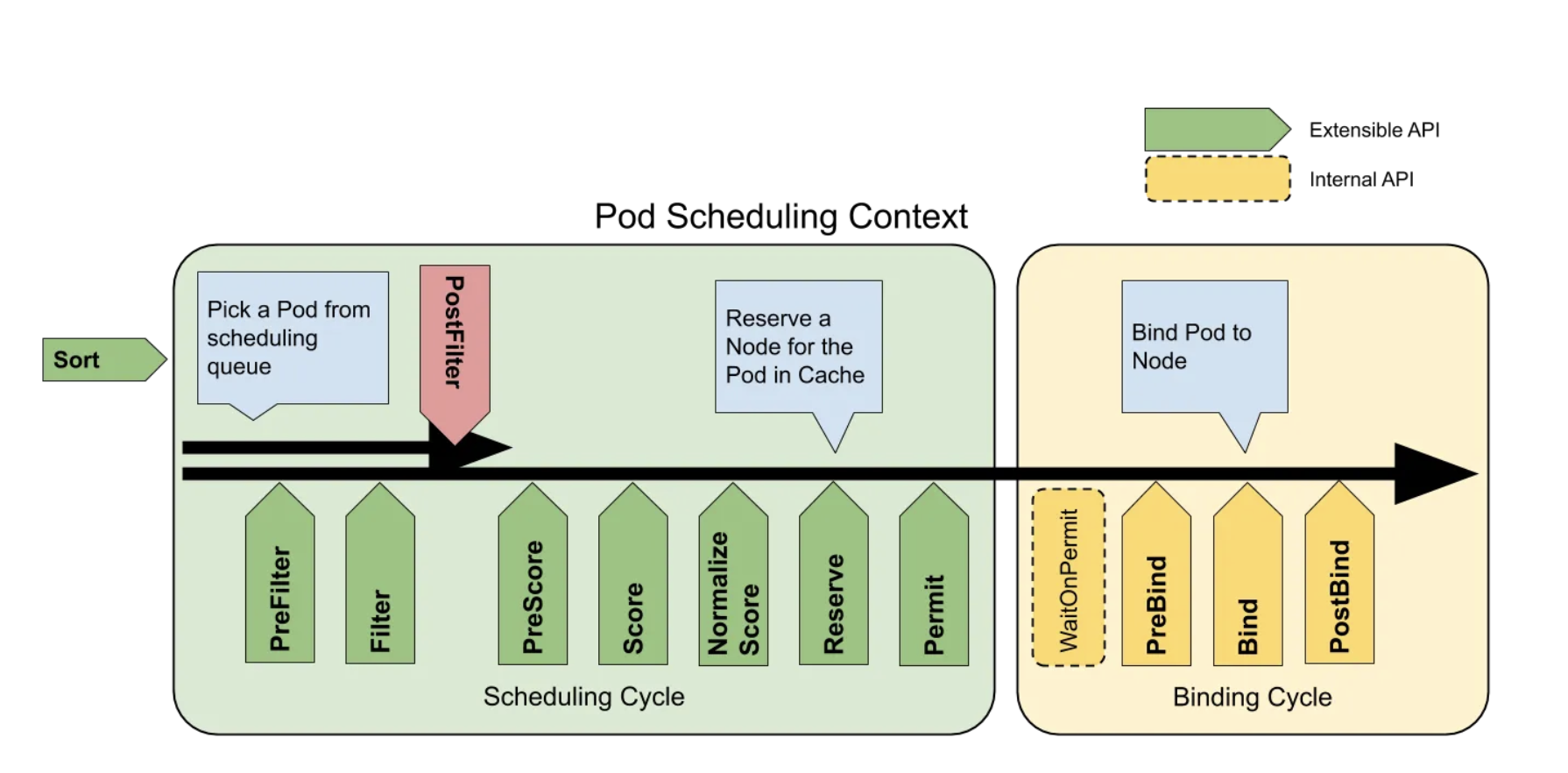
💡 Did you know?
There are two ways to configure how the kube-scheduler filters and scores nodes for pod placement:
Scheduling Policies - These allow you to set up rules called Predicates for filtering nodes and Priorities for scoring them.
Scheduling Profiles - These let you use Plugins to customize different stages of the scheduling process, like
QueueSort,Filter,Score,Bind,Reserve,Permitetc.
Core Scheduling Techniques
In this section, we’ll have a look at several techniques offered by Kubernetes to control and fine-tune how pods are assigned to nodes.
1. nodeName field
The nodeName field allows you to specify exactly which node you want a pod to run on. It’s similar assigning a specific task to a particular team member, ensuring it goes exactly where you want it to.
Here’s an example of using nodeName to schedule a pod on a specific node called node1:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-container
image: nginx
nodeName: node1
In this example, the pod my-pod will be scheduled directly on node1 without considering other nodes in the cluster.
So, when to use the nodeName field? It’s useful in scenarios where you may want to run a pod on a specific node for testing, debugging, or when you have specialized hardware on that particular node.
Note: Using
nodeNamecan bypass Kubernetes’ built-in scheduling logic, which might lead to imbalances in resource utilization if not used carefully.
2. Node Selector (nodeSelector field)
The nodeSelector field is a straightforward and commonly recommended method to ensure that your pods are scheduled on specific nodes based on labels. It’s like saying, "I want this task to go to someone in the marketing department." You assign a label to the node, and any pod with that label will be scheduled on that node.
Here’s how it works:
Assign the label
dept=marketingto the nodenode01, using the following command:kubectl label nodes node01 dept=marketing # Output node/node01 labeledVerify that the labels have been correctly set:
kubectl get nodes --show-labelsHere's the expected output:
NAME STATUS ROLES AGE VERSION LABELS controlplane Ready control-plane 23d v1.30.0 beta.kubernetes.io/arch=amd64,.... node01 Ready <none> 23d v1.30.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,dept=marketing,....Specify the same labels in the
nodeSelectorfield while creating the pod specification:apiVersion: v1 kind: Pod metadata: name: nginx labels: env: test spec: containers: - name: nginx image: nginx imagePullPolicy: IfNotPresent nodeSelector: dept: marketing
Once applied, the pod will get scheduled on the node that has a dept=marketing label — which is node01 in this case.
3. Affinity and Anti-Affinity Rules
Next up we have the concept of affinity and anti-affinity — which are more advanced methods to apply scheduling constraints for placing pods on nodes. Primarily, there are three types of affinity that are important to know.
Node Affinity
Logically, it’s very similar to using the nodeSelector field but is more expressive and flexible. It allows you to specify rules that determine which nodes your pod can be scheduled on based on node labels.
There are two types of node affinity:
requiredDuringSchedulingIgnoredDuringExecutionThis type is like a "must-have" rule. The scheduler will only place the pod on a node if the specified criteria are met. If no nodes satisfy the criteria, the pod will not be scheduled.
However, if the node’s condition changes after the pod is scheduled and running — such that the criteria are no longer met — the pod will continue to run and will not be evicted.
Example:
Here’s how you can use this type of affinity to ensure a pod is scheduled on nodes labeled with region=us-west:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-container
image: nginx
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: region
operator: In
values:
- us-west
preferredDuringSchedulingIgnoredDuringExecutionThis type is more of a "nice-to-have" rule. The scheduler will try to place the pod on a node that meets the criteria, but if no such nodes are available, the pod can still be scheduled on another node that doesn’t meet the preference.
Like the
requiredtype, changes to the node after scheduling will not affect the pod’s placement.
Example:
Here’s an example showing the use of this type of node affinity to prefer nodes in the antarctica-east1 zone:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-container
image: nginx
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: topology.kubernetes.io/zone
operator: In
values:
- antarctica-east1
Note - Using Operators
When using node affinity, you can specify conditions with operators like
In,NotIn,Exists, andDoesNotExist. These operators help define how the pod’s node selection criteria should match the node labels.For example,
Inmeans the pod will only be scheduled on nodes with specific labels, whileNotIn(which we'll see next) excludes certain nodes.For more details, refer to the Kubernetes documentation.
Node Anti-Affinity
As the name may suggest, its the opposite of Node Affinity!
It ensures that a pod is not scheduled on certain nodes based on node labels. This is particularly useful when you want to avoid placing specific workloads on certain nodes, such as keeping high-availability applications away from nodes with less reliable hardware.
Example:
Suppose you want to avoid scheduling a pod on nodes labeled with disktype=hdd. You could use nodeAffinity with the NotIn operator to ensure that the pod only runs on nodes with other disk types.
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-container
image: nginx
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disktype
operator: NotIn
values:
- hdd
Pod Affinity and Anti-Affinity
Pod Affinity and Anti-Affinity rules are similar to Node Affinity but focus on the relationship between pods rather than nodes. These rules allow you to specify whether certain pods should be scheduled close to each other (Pod Affinity) or spread apart (Pod Anti-Affinity).
Pod Affinity
Pod Affinity is used when you want certain pods to be scheduled on the same node or in close proximity to other pods that meet specific criteria. This is often useful for applications that require low latency between services, such as microservices that frequently communicate with each other.
Example: If you have a microservices application where certain services need to be close to each other, you might use Pod Affinity to ensure they are scheduled on the same node:
apiVersion: v1 kind: Pod metadata: name: my-pod spec: containers: - name: my-container image: nginx affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: labelSelector: matchExpressions: - key: app operator: In values: - frontend topologyKey: "kubernetes.io/hostname"Pod Anti-Affinity
Pod Anti-Affinity is used when you want to ensure that certain pods are scheduled away from each other. This can be particularly useful for high-availability applications, so that if one node fails, the other replicas are still running on different nodes.
Example: To ensure high availability, you might want to avoid placing replicas of the same service on the same node. Pod Anti-Affinity can help here by ensuring that pods with the same label are spread across different nodes.
apiVersion: v1 kind: Pod metadata: name: my-pod spec: containers: - name: my-container image: nginx affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: labelSelector: matchExpressions: - key: app operator: In values: - backend topologyKey: "kubernetes.io/hostname"
4. Taints and Tolerations
Taints and Tolerations are like setting up VIP areas in a restaurant. Taints are the "VIP only" signs that prevent certain pods from being scheduled on specific nodes unless they have a matching "VIP pass" called a toleration.
Essentially, taints and tolerations allow you to control which pods can or cannot run on specific nodes. Taints are like "keep out" signs that prevent certain pods from being scheduled on the node unless they have a matching toleration.
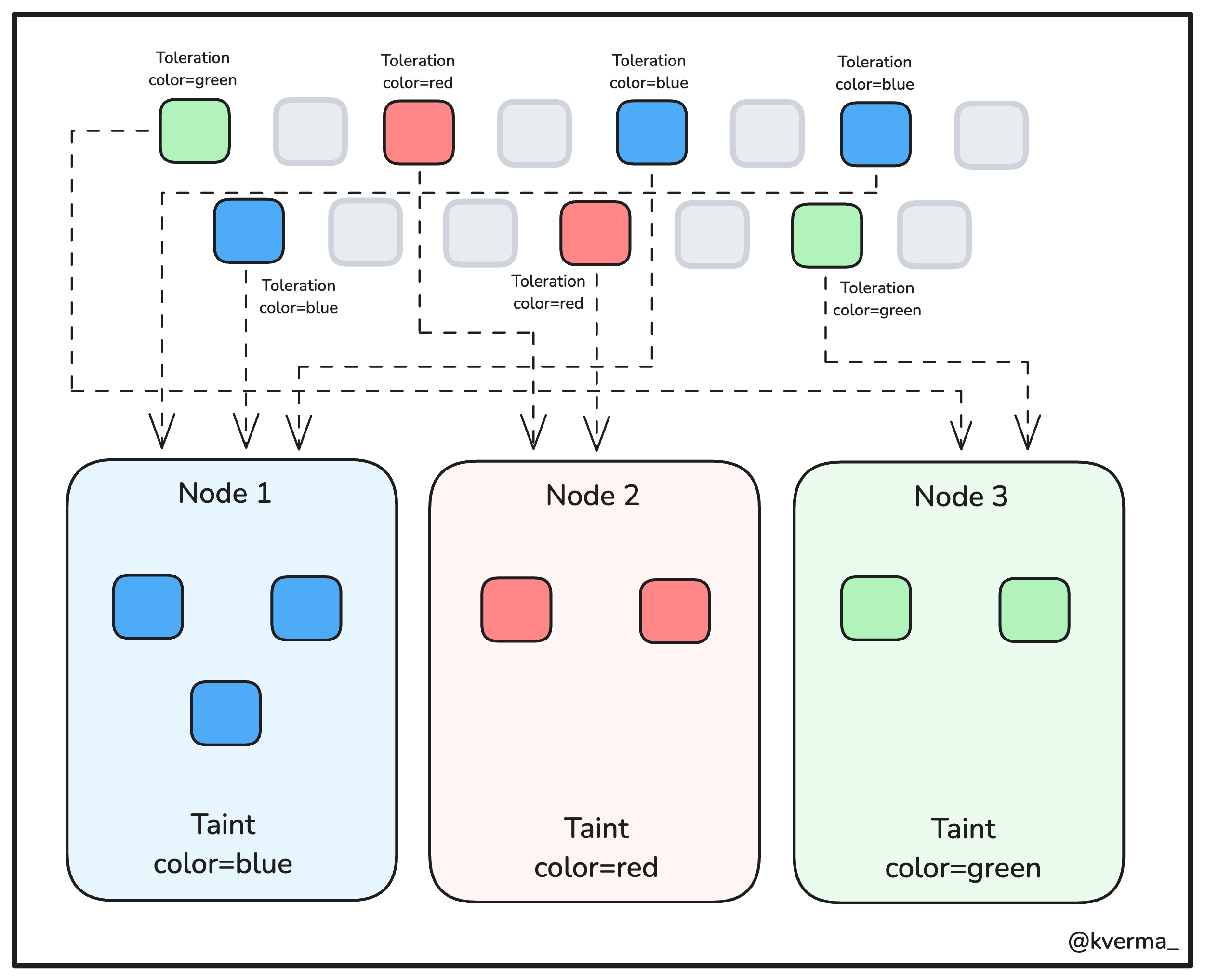
Example:
Let’s say you want only specific pods (with the label team=blue) to run on a particular node. You can taint the node and add a matching toleration to the pods:
kubectl taint nodes node1 team=blue:NoSchedule
This command adds a taint to node1, preventing any pod from being scheduled on it unless the pod has a matching toleration.
Now, add a toleration to the pod so it can be scheduled on the tainted node:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-container
image: nginx
tolerations:
- key: "team"
operator: "Equal"
value: "blue"
effect: "NoSchedule"
💡Tip - Good Scheduling Strategy
An effective scheduling strategy is using a combination of Node Affinity along with Taints and Tolerations.
First, we can apply Taints and Tolerations to prevent other pods from being scheduled on specific nodes. Then, we use Node Affinity to ensure that the selected pods (those allowed by the Tolerations) stay on their designated nodes and don’t end up on other pods’ nodes.
This strategy will give precise control over pod placement, ensuring your workloads are isolated and running where you want them.
Managing Resource Allocation
Now that we've covered the important scheduling mechanisms we can use in Kubernetes, it’s important to understand how resources are allocated to ensure that your applications run efficiently and reliably. Managing resource allocation is crucial because it directly affects how Kubernetes schedules your pods and how well your applications perform within the cluster.
When deploying an application, each pod consumes resources like CPU and memory, and it’s essential to manage these resources wisely. If resource allocation isn’t handled properly, some applications might consume too much, leaving others starved for resources, or pods might not get scheduled at all if the required resources aren’t available on a particular node.
Kubernetes offers several mechanisms to help you manage resource allocation effectively:
1. Resource Requests and Limits
These are the primary parameters that you set to control how much CPU and memory a pod can consume.
Resource Requests:
This defines the minimum amount of CPU and memory that a pod needs to run. When you set a resource request, Kubernetes uses this value to decide if a node has enough available resources to accommodate the pod. If a node doesn’t have the requested resources, the pod won’t be scheduled on that node.
Resource Limits:
This defines the maximum amount of CPU and memory that a pod is allowed to use. Setting limits will ensure that a pod doesn’t consume more than its fair share of resources, which helps prevent any single pod from starving others of necessary resources.
By setting both requests and limits, you can ensure that your applications have enough resources to perform well, without any one application hogging all the resources.
Example:
Here’s an example of how to set resource requests and limits in a pod specification:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-container
image: nginx
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
In this example:
The pod requests
64Mi(mebibytes) of memory and250mof CPU, meaning it needs at least these amounts to be scheduled on a node.The pod is limited to
128Miof memory and500mof CPU, meaning it cannot exceed these amounts, even if more resources are available on the node.
2. Resource Quotas
Resource Quotas are a way to manage resource consumption across different namespaces in a Kubernetes cluster. A Resource Quota sets hard limits on the amount of resources — like CPU, memory, and storage — that a namespace can use.
This is particularly useful in multi-tenant environments, where you want to ensure that no single team or application consumes more than its fair share of cluster resources.
Example:
Here’s an example of setting a Resource Quota in a namespace:
apiVersion: v1
kind: ResourceQuota
metadata:
name: namespace-quota
namespace: demo-ns
spec:
hard:
cpu: "20"
memory: "100Gi"
pods: "50"
In this example:
The namespace
demo-nsis allowed to request up to 20 CPUs,100Giof memory, and a maximum of 50 pods.This ensures that the applications within this namespace cannot exceed the specified resource limits, helping to maintain balance in the cluster.
3. Limit Ranges
A Limit Range is a policy that works within a namespace to enforce minimum and maximum resource requests and limits for individual pods or containers. This helps ensure that every pod in the namespace adheres to a standard set of resource consumption rules, which prevents any pod from having too few or too many resources.
Example:
Here’s how you can set a Limit Range in a namespace:
apiVersion: v1
kind: LimitRange
metadata:
name: resource-limits
namespace: demo-ns
spec:
limits:
- default:
cpu: "500m"
memory: "256Mi"
defaultRequest:
cpu: "250m"
memory: "128Mi"
max:
cpu: "1"
memory: "512Mi"
min:
cpu: "100m"
memory: "64Mi"
type: Container
In this example:
The Limit Range enforces that every container in the
demo-nsmust request between 100m and 500m of CPU and between 64Mi and 512Mi of memory.This prevents any single container from requesting too few resources (which could cause performance issues) or too many resources (which could waste resources).
Priority and Preemption
In a Kubernetes cluster, not all workloads are equally important. Some are mission-critical, while others are less urgent. Priority and Preemption allow you to ensure that the most critical workloads get the resources they need, even if it means evicting less critical ones.
Priority
With priority, you can assign a value to each pod that indicates its importance. Pods with higher priority values are considered more critical by the scheduler. When resources are limited, these high-priority pods are given preference over lower-priority ones.
Preemption
Preemption is a process that works hand-in-hand with priority. If a high-priority pod can’t be scheduled because there aren’t enough resources available, Kubernetes may remove (or "evict") lower-priority pods to make room. This ensures that critical workloads have the resources they need to run.
Example:
Here’s how you might define a PriorityClass for critical workloads:
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000
globalDefault: false
description: "This priority class should be used for critical workloads."
You can then use this PriorityClass in a pod definition:
apiVersion: v1
kind: Pod
metadata:
name: critical-pod
spec:
containers:
- name: my-container
image: nginx
priorityClassName: high-priority
In this example:
The
PriorityClassnamedhigh-priorityis assigned a value of1000, making it a high-priority class.The pod
critical-poduses thisPriorityClass, ensuring that it will be given preference over lower-priority pods when resources are allocated during the scheduling process.
Horizontal Scaling and Scheduling
As your application grows and demand increases, Kubernetes needs to automatically adjust the number of running pods to handle the load. This is where Horizontal Pod Autoscaling (HPA) comes into play. HPA interacts closely with the scheduling process to ensure that new pods are efficiently placed across the cluster.
What is Horizontal Pod Autoscaling (HPA)?
It is a mechanism in Kubernetes that automatically scales the number of pod replicas based on observed resource usage, such as CPU or memory. This helps maintain application performance during fluctuating workloads, which ensures that your application can handle varying loads without manual intervention.
How does it works?
HPA monitors resource usage, such as CPU or memory, and automatically adjusts the number of pod replicas to match the current demand. If resource usage increases, HPA will "scale out" by creating more pod replicas. On the other hand, if resource usage decreases, HPA will "scale in" by reducing the number of replicas.
The scheduler then ensures that these new pods are evenly distributed across the cluster, optimizing resource utilization and avoiding the "hotspots".
Why does Horizontal Scaling matter?
Horizontal scaling is important because it allows your application to be responsive to changing demand without wasting resources. When demand increases, more pods are added to handle the load. When demand drops, excess pods are removed, saving resources and costs.
This dynamic scaling is essential for maintaining application performance and reliability, especially in environments where workload can vary significantly, such as web applications or online services that may experience peak traffic during certain times of the day.
Example:
Here’s how you can configure HPA to scale based on CPU usage:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: app-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-app
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
In this example:
The HPA is configured for a deployment named
my-app.It will maintain a minimum of 2 replicas and can scale up to a maximum of 10 replicas based on CPU usage.
The target CPU utilization is set to 50%, which means that HPA will add or remove replicas to keep the average CPU usage around this level.
Best Practices for Scheduling
To wrap up, let us have a look at some best practices that will help you get the most out of Kubernetes scheduling:
Scheduling for High Availability
As we discussed in a previous section, high availability is about ensuring that your applications remain up and running even in situations of node failures or any other disruptions. By strategically placing your pods across different nodes and zones, you can minimize the risk of downtime.
Use Pod Anti-Affinity to spread replicas across nodes. This ensures that if one node goes down, the other replicas remain available.
Leverage Multi-Zone/Region Scheduling - By running your application in multiple zones or regions, you can ensure that it can withstand a failure in one location, improving overall reliability.
Optimizing Resource Utilization
We’ve already seen the importance of efficient resource allocation and utilization — which is key maintaining a balanced and cost-effective Kubernetes cluster. Here are some pointers to keep in mind:
Set Appropriate Resource Requests and Limits - This will ensure that each pod has the right amount of CPU and memory allocated. Properly setting these values helps prevent resource contention and ensures that your cluster runs efficiently.
Monitor Resource Usage Regularly - We are aware that Kubernetes clusters are dynamic, so it’s important to regularly review resource usage and adjust requests and limits as needed. Tools like the Kubernetes Dashboard or Prometheus can help with this.
Avoiding Common Pitfalls
Even with the best intentions, it’s easy to make mistakes that can negatively impact any scheduling strategies you implement. Here are some common pitfalls to be aware of:
Avoid Over-Requesting Resources - Setting resource requests too high can lead to unscheduled pods and wasted resources. Its important to be realistic in your resource allocations.
Use Priority Wisely - Reserve high priorities for truly critical workloads to avoid unnecessary preemptions that can create instability in your cluster.
Monitor and Adjust Regularly - Using tools like the Kubernetes Dashboard or Prometheus can help automate the process, making it less likely to make mistakes compared to doing it manually.
Conclusion
In this guide, we’ve explored the essential concepts and techniques for effective scheduling in Kubernetes. By understanding and applying these practices, you can ensure that your applications are not only running efficiently but are also resilient and scalable.
For further exploration and more detailed insights, be sure to check out the Kubernetes official documentation and other linked resources.
Happy scheduling!
Resources
Subscribe to my newsletter
Read articles from Kunal Verma directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Kunal Verma
Kunal Verma
Kunal is a DevOps and Cloud Native Advocate with a passion for Open Source. He's been involved in the DevOps and open-source ecosystem for 1.5+ years and has a strong experience in public speaking, community management, content creation etc. He has experience working on and contributing to some of the major projects in the CNCF, including Kubernetes, Layer5 and others. He always strives to empower others with my experiences and believes in growing with the community!