Alibaba Cloud Customer Service Agent: Thoughts, Design, and Practices from Concept to Implementation
 Lara Lee
Lara Lee
1. Background
At the end of 2022, large language models (LLMs) led by ChatGPT pioneered new intelligent capabilities and forms of conversational interaction. Among these, agents, that are developed based on LLMs, have attracted wide attention. Many even believe that agents pave the way to Artificial General Intelligence (AGI) and represent a key technology that facilitates the application of LLMs in various areas. As a result, the agent technology based on LLMs has entered an unprecedented stage of rapid development. As agents become increasingly user-friendly and efficient, they are expected to become basic scenarios in future AI applications.
In the Alibaba Cloud after-sales service context, we have collaborated with Tongyi Lab to build and train the Alibaba Cloud customer service LLM by using Tongyi Qianwen (Qwen) as the base model. With this LLM, we have upgraded the underlying algorithm capabilities of Alibaba Cloud’s after-sales service chatbot, transforming it from a traditional Q&A chatbot into a generative chatbot. One essential module that deserves long-term, continuous optimization and development is an agent. In this article, we’ll see how the Alibaba Cloud customer service agent is designed and implemented and the results achieved so far.
2. Ideal Form of LLM Implementation
The basic logic of traditional Q&A chatbots based on LLMs is to answer questions through plain text conversations. This form is suitable for consultation scenarios involving domain knowledge and common facts, such as questions about China's capital and the Ming dynasty's founding date. These questions are fact-based and can be easily addressed through text. Even when retrieval augmented generation (RAG) is used, it feeds the latest knowledge and common facts into LLMs, such as the champion of the latest World Cup and the recently released Sora model. However, such Q&A scenarios are only the first stage of LLM implementation. Many scenarios require large AI models to connect to the real world to fully unleash their potential.
Imagine this: you’re lying on your bed, ready to sleep, but suddenly you realize that you haven’t drawn the curtains. You can tell an LLM, Please draw my curtains. You don’t want to hear a series of steps on how to do it. Imagine how cool it would be if the LLM could draw the curtains for you like a real person! Even better, you can give it slightly more complex instructions, such as, Don’t close the curtains completely. Leave a crack. If the LLM can understand this instruction and translate the action of leaving a crack in natural language into a quantified parameter like curtain closure percentage, and then actually adjust the curtains to your desired extent, that would be solid proof that LLMs can truly spark a wave of practical applications in all walks of life.
We don’t need a chatbot toy that we can only chat with. What we need is an LLM that has hands and feet and can do things for us. That’s the ideal form of LLM implementation that benefits us the most. Agents are a crucial technical means that leads us to this ideal form. They’re certainly not the only means, but they’re a means of particular importance at this stage.
Figure 1: Various forms of agent capabilities introduced by ChatGPT and Qwen
Nowadays, many companies in the industry have launched their agent products. For example, ChatGPT offers plugins that allow third-party developers to access ChatGPT to implement the capabilities that are not available with native generative pre-trained transformers (GPTs), such as shopping, ordering food, interpreting PDFs, and editing videos simply through conversations. The consumer applications of the Qwen model and other LLMs developed by Chinese enterprises also provide rich agent capabilities, such as role-playing conversations, drawing, and PDF-based Q&A. We believe that as more innovative features are introduced, agents will undoubtedly become the most important, indispensable, and valuable capability of LLMs in the future.
3. From “Explaining” Problems to “Solving” Problems
Back to the scenario of Alibaba Cloud’s after-sales service, why is it necessary to introduce the concept of an agent?
First of all, let’s see how Alibaba Cloud’s after-sales service representatives handle customers’ questions. Customers’ questions mainly fall into the following categories: factual questions, diagnostic questions, vague questions, and other questions. The most common of these are diagnostic questions. They are different from simple factual questions that can be easily addressed based on business experience and references to help documentation, such as failures in remote connection to an Elastic Compute Service (ECS) instance and queries of the filing progress. Instead, for diagnostic questions, help documentation or knowledge bases only provide related troubleshooting solutions or generic procedures. Identifying the root cause of customer problems requires inspecting a variety of platforms, tools, and even customer servers after obtaining authorization. These platforms and tools are mostly provided by the R&D team, while some are encapsulated by the after-sales business team based on APIs for use by after-sales service representatives. Only through inspection can the true status and issues with customers’ cloud resources be identified. Then, based on individual experience and help documentation, after-sales service representatives can solve customers’ problems step by step.
Just like the example provided in the second section, what customers need is the actual execution of drawing the curtains rather than a text description of the steps. Similarly, when a customer asks a LLM about a refund, they expect the model to handle the refund directly, rather than simply providing a bunch of information about refund rules and steps. Few people have the patience to read through lengthy explanations.
The reason we developed a generative chatbot based on an LLM, rather than continuing with the traditional chatbot, was to achieve the goal of solving problems in a humanized way. LLMs have obvious advantages over traditional chatbots, including more powerful semantic interpretation, improved generation and organization capabilities, chain-of-thought (CoT) capabilities, and step-by-step thinking. With these advantages, the “humanized” capabilities of LLMs are impressive. At present, the recognition and response generation capabilities of our customer service LLM are undoubtedly superior to the capabilities of the knowledge base matching and fine-sorting models used by traditional chatbots. The LLM also excels in solving problems through conversations. This is achieved by fine-tuning the Qwen model and utilizing RAG, which enables the LLM to better understand Alibaba Cloud business, stay updated with the latest knowledge and information, and reduce the hallucination rate. However, addressing the most frequently asked diagnostic questions using LLMs remains a challenge. Before the emergence of agents, LLMs could only handle multi-turn Q&A conversations and were unable to solve problems step by step.
Therefore, LLMs alone are not enough. We need to leverage their powerful semantic interpretation capabilities to progress from merely explaining problems to truly solving problems. The differences between the two are well explained in the figure below.

Figure 2: “Explaining” problems vs “solving” problems
4. Agent Design Frameworks
To design agents for LLMs to solve problems step by step, we can draw inspiration from products such as ChatGPT plugins, AutoGPT, and AgentGPT. Lilian Weng, a research director at OpenAI, once posted a blog article titled LLM Powered Autonomous Agents, in which she introduced design frameworks of agents and proposed a basic framework: Agent = LLM + Planning + Memory + Tool Use. In this framework, LLMs play a role as the brain of agents, providing capabilities such as inference, planning, and more [1]. The framework is illustrated in the figure below.

Figure 3: Framework of LLM-powered agents (from OpenAI)
This agent framework consists of four parts: Planning, Memory, Tools, and Action.
Planning: This part consists of subgoal decomposition, as well as reflection and refinement. Subgoal decomposition refers to the ability of agents to efficiently tackle complex tasks by breaking them down into smaller, more manageable subgoals. Through self-criticism and self-reflection on past actions, agents can learn from mistakes and refine them for future moves, thus improving the quality of outcomes.
Memory: Memory includes short-term memory and long-term memory. All types of contextual learning, such as prompt engineering and in-context learning, are considered means of learning that utilize the short-term memory of models. Long-term memory, on the other hand, provides agents with long-term storage and information retrieval capabilities, usually by using external vector storage and quick retrieval methods.
Tools: By learning to call external APIs, agents can obtain the information that is missing from the model weights (usually difficult to change after pre-training), including current information, code execution capabilities, and access to exclusive information sources.
Action: Based on the planning, memory, and tools mentioned above, LLMs can then decide on the action to take.
Let’s take a ReAct agent as an example to illustrate the processing steps of an agent [2], as shown in the figure below. After the agent starts, the LLM thinks based on given prompts and observations at the Thought step. Then, at the Action & Action Input step, the LLM suggests a tool for an agent to execute, along with tool input arguments. Next, at the Observation step, the agent executes the suggested tool and shares the observation or output with the LLM. If the observation or output does not meet expectations, the process returns to the Thought step. This cycle repeats until the LLM suggests the final answer at the Final Answer step, after which the agent finishes.

Figure 4: Overall process of LLM-powered agents (from ReAct Agent)
In short, agent implementation serves the following purposes:
The LLM can combine queries, context, and various APIs (or tools) to plan which APIs need to be called in a given scenario to solve the problem that the customer cares about most.
The LLM can decide on the response to the customer, that is, the final action to take, based on the results returned by the APIs.
5. Design of the Customer Service Agent
In addition to referencing the industry-specific agent design frameworks mentioned above, agent design must also be tailored to specific business needs. Let’s examine the following example to see how after-sales service representatives solve complex problems in real-world situations.
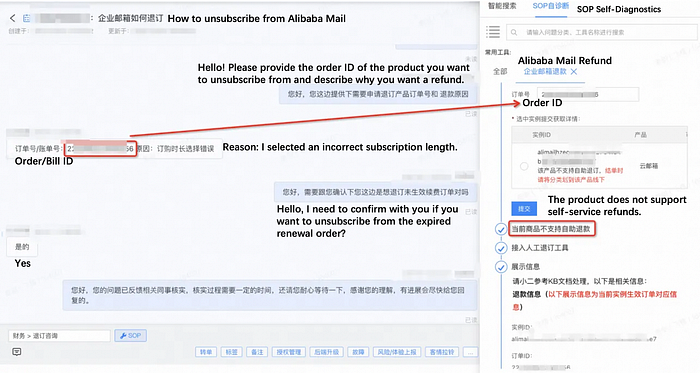
In the first round, the after-sales service representative asks follow-up questions based on the customer’s problem to obtain the basic information required to execute the unsubscription action.

Figure 5: Example of how after-sales service representatives of Alibaba Cloud solve customer problems
In the second round, based on the queried instance and order status, the after-sales service representative further confirms with the customer to solve the customer’s problem step by step. As for the example shown in the images above, the process of handling a ticket is broken down into the following steps:
The customer consults about unsubscribing from Alibaba Mail.
The after-sales service representative replies, Please provide the order ID of the product you want to unsubscribe from and describe why you want a refund.
The customer replies with the order ID and the reason.
The after-sales service representative handles the customer’s request according to the standard operating procedure (SOP) for unsubscribing from Alibaba Mail. First, the representative queries the order status using the order ID provided by the customer. Then, the representative verifies whether the product is indeed Alibaba Mail. Next, based on the API response of the SOP, the representative learns that Alibaba Mail does not support self-service refunds, and employing query, the representative learns that the status of the latest order related to the instance is expired and pending renewal. Therefore, the representative asks the customer whether to unsubscribe from the expired renewal order.
The customer confirms the unsubscription from the latest order. The after-sales service representative then contacts relevant personnel to perform the subsequent operations.
From this real case, we can outline a typical basic problem-solving process of Alibaba Cloud after-sales service as follows:
Identify the problem -> Query the SOP -> Ask follow-up questions to obtain more information from the customer -> Query a tool based on the information -> Retrieve the tool execution result -> Respond to the customer based on the result -> Continue communication with the customer -> … -> Solve the problem
Based on this basic problem-solving process coupled with customer problems, LLMs are expected to perform two types of tasks: Planning (including Action and Observation) and Generation (mainly Response). Planning is a multistep tool-calling process in which LLMs repeatedly call tools and observe the return results until satisfactory information is obtained and actions are performed. This process involves calling APIs, decomposing complex problems for search, and re-searching when search results are unsatisfactory.
Based on the main steps of Alibaba Cloud’s current ticket-handling process, we can summarize the main steps for the LLM-powered agent as follows:

Figure 6: Overall problem-solving process designed for the Alibaba Cloud customer service agent
* Agent judgment: Based on communication with the customer, determine whether the current situation involves a diagnostic question and if it requires applying the agent’s logic.
* Task planning: This step is further divided into the following substeps.
1. API retrieval: Search the APIs that are most relevant to the customer’s query.
2. API selection: Use the LLM to read the current query and context to determine which APIs to call and plan the sequence of API calls.
3. Parameter judgment: Determine whether the required parameters of the APIs to be called have been provided. If not, ask the customer for the information.
4. Parameter assembly: Assemble the parameters provided by the customer to build requests in the expected format, such as the JSON format, to call the APIs.
* Action execution: Act decided in the previous step, such as asking follow-up questions or calling APIs and obtaining the calling results.
* Response generation: Use the LLM to organize the API calling results into a solution and then respond to the customer.
6. Automation, Cost, and Controllability
From the above process analysis, we can see that an agent performs quite a few steps, with the API planning step potentially involving multiple API calls. For example, an API requires an instance ID as a request parameter, but a customer doesn’t know the instance ID and instead provides a server IP address. In this case, the agent must first call an API that retrieves the instance ID based on the server IP address, and then proceed to retrieve other information based on the instance ID. So, two APIs are called. Because the generation speed of LLMs is relatively slow, this solution may cause the customer to wait a long time before receiving a response. Though more intelligent, LLMs are also more time-consuming, especially in that their interface seems frozen during the generation process, resulting in a poor user experience.
Many other agents have also been implemented in the industry, including well-known ones like AutoGPT and AgentGPT. In most cases, the logic of an agent is to first analyze tasks and then complete them through actions such as thinking continuously and adding tasks. This process may involve calling APIs, such as search engine APIs or task-related APIs. As a result, it takes an agent a relatively long time to complete a task. In some cases, an agent may even enter an infinite loop. This occurs when, after thinking, execution, and observation, the LLM produces an unsatisfactory result and repeats these steps without achieving the desired outcome, leading to an endless cycle.
In agent implementation for actual business, several factors must be considered, including execution effect, total time consumption, LLM generation costs (tokens and QPS), and API call cost (QPS). If the execution effect is satisfactory, long total time consumption or high costs associated with LLM generation and API calls can negatively impact user experience. Therefore, we have further optimized the agent process and made adjustments in various aspects, including algorithms, engineering, and front end, to deliver the best user experience possible under the current circumstances. Details are provided below.
First of all, since multistep API calling is the most time-consuming process, our tool APIs are encapsulated based on scenarios to provide an end-to-end, out-of-the-box API calling experience. For example, our refund API supports request parameters such as instance ID and order ID, and our API for ECS instance connection troubleshooting supports request parameters such as instance ID and IP address. This eliminates the need to call an additional API when customers provide only one request parameter, reducing multistep API calling on the algorithm side and shortening the response time.
Second, the time taken by API execution can vary. For some services or business scenarios, customer queries are relatively simple, and LLMs can receive responses quickly. In such cases, LLMs can assemble the reply text based on the return results of the called APIs. However, in many Alibaba Cloud scenarios, especially those related to ECS diagnostics, generating diagnostic results takes longer. If LLMs still wait for the APIs to return results before replying to customers, the user experience will suffer. Therefore, we use asynchronous processing to render a micro application card in the frontend, so that customers can see a dynamic execution progress bar.
Finally, we construct high-quality training datasets to fine-tune the Qwen base model to improve its accuracy in API selection, follow-up questioning, request parameter extraction, and API execution as much as possible. This also streamlines the observation process and reduces execution failures for LLMs, helping achieve the goal of generating satisfactory results on the first attempt.
7. Training and Evaluation of Agent Capabilities
In the above sections, we have introduced the framework design of the customer service agent, with multidimensional considerations including automation, cost, and controllability. To fully implement agent capabilities, we still need to master how to train and evaluate the agent capabilities of the customer service LLM.
The Qwen base model provides official support for agent tool API calling. For details, please refer to the Qwen Agent open-source project [3] on GitHub. The main method of calling an API is to write a prompt that contains the name, description, and request parameters of the API to be called, based on the officially provided sample format. For example, to call an image generation API, you can write a prompt as shown below, use the official prompt constructor provided by Qwen to assemble the information, and then pass the assembled information to the Qwen model, enabling automatic API calling.
name = 'my_image_gen'
description = 'AI painting (image generation) service, input text description, and return the image URL drawn based on text information.' parameters = [{
'name': 'prompt',
'type': 'string',
'description': 'Detailed description of the desired image content, in English',
'required': True
}]
The agent capabilities provided by Qwen lay a solid foundation for us to build the agent capabilities of our customer service LLM. However, since our customer service LLM is more business-oriented, the agent capabilities of Qwen have certain limitations in practical use in specific business scenarios. Therefore, in-depth customization and fine-tuning based on these business scenarios are required to fully meet the needs of customer service.
Given the distribution characteristics of customer queries in Alibaba Cloud customer service scenarios, detailed information is often missing from customers’ problem descriptions, and many queries are simple intent names such as ECS connection failure and filing progress query. This makes it challenging for the agent to extract the required parameters in a single step. Therefore, in most cases, the agent has to ask follow-up questions to gather more information. This requires the agent to have multi-turn conversation capabilities. In other words, after the customer provides certain information, the agent must be able to combine the information with previous intents and continue with the API calling process. In addition, we need to consider scenarios where no API needs to be called and no parameter needs to be extracted. The goal is to enable the LLM to make decisions, such as on which API to call, which action to execute, which parameters to extract, and how to execute APIs. The overall training process is illustrated below.
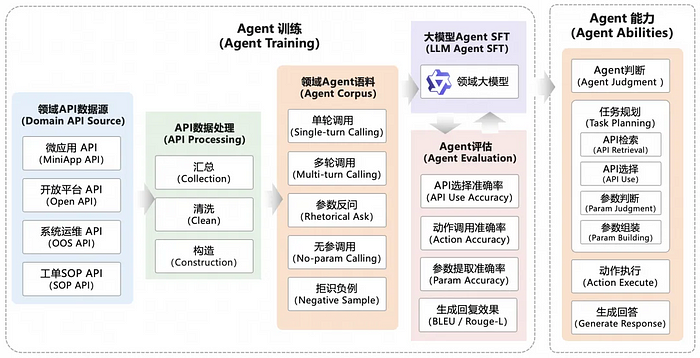
Figure 7: Training, evaluation, and application capabilities of the Alibaba Cloud customer service agent
After the training is completed, we also build a benchmark for the customer service agent, which is used to compare the agent capabilities of different models. This benchmark supports multiple evaluation dimensions, including API selection accuracy, action (follow-up questioning, direct API calling, rejection, etc.) execution accuracy, request parameter extraction accuracy, and end-to-end success rate, as well as the metrics related to generated text like BLEU and Rouge-L. The decision on which version of the model to deploy online depends on a multidimensional consideration of these factors.
8. Actual Effects of Agent Implementation
With all that said, let’s see how the Alibaba Cloud customer service agent works in real-world business.
① Directly triggering the agent: When the agent is triggered directly, it can accurately extract personalized customer information, such as the instance ID, and generate reply text based on the return results of APIs, as well as provide an execution card where the customer can perform operations as needed.

Figure 8: Execution effect when a customer query directly triggers the agent
② Follow-up questioning by the agent and clarification by the customer: When a customer doesn’t provide the request parameters required by the API to be called, the LLM asks follow-up questions and the customer can enter the request parameters directly in the conversation interface. In the next round of conversation, the agent can continue to perform actions. To deliver a better customer experience, we also implement parameter selection capabilities for the card displayed in the first round of conversation.

③ Asynchronous card rendering by the agent: In complex scenarios such as ECS diagnostics, where API execution can be time-consuming, asynchronous card rendering realizes real-time display of diagnostic information, including progress and status. This improves the user experience during the waiting period by providing dynamic feedback.

Figure 9: Execution effect when the agent asks follow-up questions and the customer provides clarification
③ Asynchronous card rendering by the agent: In complex scenarios such as ECS diagnostics, where API execution can be time-consuming, asynchronous card rendering realizes real-time display of diagnostic information, including progress and status. This improves the user experience during the waiting period by providing dynamic feedback.
These three cases illustrate the typical implementation effects of our agent. It is now available in nearly all of the top 30 scenarios. Based on customer needs, the LLM can call various diagnostic tool APIs and cards to solve customer problems efficiently. According to statistics, the agent solution achieves a self-service resolution rate that is over 10% higher compared to the traditional solution of text-based generative answers.

Figure 10: Effect of asynchronous card rendering by the agent
9. Summary
We will keep refining the customer service LLM and develop an accurate, professional, and humanized intelligent chatbot. We also hope that our intelligent chatbot and agent capabilities will continuously improve to better address after-sales problems for customers.
This article is just a summary of some results that we have achieved so far in the design and practices of the Alibaba Cloud customer service agent. Please feel free to leave your thoughts and comments!
Originally published at https://www.alibabacloud.com.
Subscribe to my newsletter
Read articles from Lara Lee directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Lara Lee
Lara Lee
Passionate about Alibaba Cloud! Sharing insights, updates, and tips to help you navigate the world of cloud computing with Alibaba Cloud. Join me as we explore the latest innovations, best practices, and success stories from one of the world's leading cloud service providers.