From Bag of Words to Self-Attention: The Evolution of Understanding Text in Machine Learning
 pankaj chauhan
pankaj chauhanTable of contents
- Introduction: The Journey of Text Understanding
- The Foundations: How Models Understand Textual Data
- The Leap Forward: Word Embeddings
- The Limitation of Word Embeddings: Static vs. Contextual Understanding
- Enter Self-Attention: The Architect of Context
- Conclusion: From Text Representation to Contextual Understanding

Introduction: The Journey of Text Understanding
In the realm of natural language processing (NLP), one of the most intriguing challenges has always been how machines can effectively understand and interpret human language. This journey has seen the evolution of numerous techniques, each striving to make computers more literate in the language of humans. We’ve come a long way from basic text representation methods like One-Hot Encoding (OHE) and Bag of Words (BoW) to the more sophisticated approaches like Word Embeddings and finally, to the transformative innovation that is Self-Attention. But why did we need Self-Attention in the first place? To answer that, let's start from the beginning.
The Foundations: How Models Understand Textual Data
1. One-Hot Encoding (OHE)
OHE is like the alphabet of machine learning, a fundamental but rudimentary approach. Imagine representing each word in a text with a vector where only one position is marked as '1', and the rest are '0'. For example, if you have a vocabulary of 10,000 words, each word is a vector of 10,000 dimensions with just a single ‘1’ in the position corresponding to that word.
One-Hot Encoding Representation:
OHE(wi)=[0,0,…,1,…,0]
Limitations: While simple, OHE has glaring inefficiencies, particularly its inability to capture the relationships between words. To a model, "cat" and "dog" are as different as "cat" and "banjo," which isn’t very helpful.
2. Bag of Words (BoW)
BoW improves upon OHE by considering the frequency of words in a text. It’s like counting how many times each word appears in a document and representing the document as a collection of these counts. While this method captures some information about word importance, it entirely disregards word order and context.
Limitations: BoW treats words as independent entities. The phrase “not good” might have the same BoW representation as “good not,” which can lead to significant misunderstandings by the model.
3. TF-IDF (Term Frequency-Inverse Document Frequency)
TF-IDF refines BoW by adding the concept of importance. It considers how frequently a word appears in a document (Term Frequency)

and how unique that word is across all documents (Inverse Document Frequency). This helps highlight words that are more meaningful within a specific context.

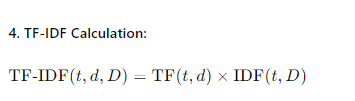
Limitations: Although TF-IDF is a step up, it still doesn’t capture the relationships between words or their order in the text. It’s more sophisticated but still too simplistic for nuanced language understanding.
The Leap Forward: Word Embeddings
Enter Word Embeddings the game changer. Word embeddings are dense vector representations where similar words have similar vector representations. Unlike OHE, which places each word in its own little island, word embeddings place words in a continuous vector space, where semantically similar words are closer together.
Advantages of Word Embeddings:
Semantic Understanding: Words with similar meanings, like "king" and "queen," end up close to each other in the vector space.
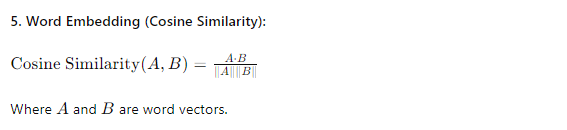
Dimensionality Reduction: Unlike the sparse and high-dimensional vectors in OHE, word embeddings are compact and dense, often in hundreds of dimensions rather than tens of thousands.
Transfer Learning: Pre-trained word embeddings (like Word2Vec or GloVe) can be reused across different tasks, saving time and computational resources.
However, as powerful as word embeddings are, they come with a significant limitation, they are static.
The Limitation of Word Embeddings: Static vs. Contextual Understanding
Word embeddings, once trained, remain fixed. They don’t adapt to the context in which a word is used. For instance, the word “bank” would have the same vector whether you’re talking about a riverbank or a financial institution. This static nature hinders the model's ability to truly understand the nuanced meanings that context can bring.
This is where we hit a roadblock. If we want our models to understand that “bank” in “riverbank” is different from “bank” in “bank account,” we need a new approach something that considers context dynamically. And so, the stage was set for Self-Attention.
Enter Self-Attention: The Architect of Context
The Need for Self-Attention
Traditional models, even with word embeddings, struggled to capture long-range dependencies and contextual meanings in text. RNNs (Recurrent Neural Networks) and LSTMs (Long Short-Term Memory networks) made progress by processing text sequentially, but they were slow and often faced difficulties with very long sentences.
Self-Attention addresses these challenges by allowing the model to consider the entire context at once, not just sequentially.
The Architecture of Self-Attention
Self-Attention works by assigning different "attention" scores to different words in a sentence, depending on how relevant each word is to understanding a particular word. Here’s a simplified breakdown of how it works:
Input Representation: The words are converted into embeddings.
Query, Key, and Value Vectors: For each word, three vectors are created. Query (what we’re looking for), Key (what we have), and Value (the content). These vectors help determine how much focus should be given to each word when considering the context.
Attention Scores: The query of each word is compared with all keys in the sequence to calculate attention scores. These scores determine the weight or focus that each word should have on another.

Contextual Representation: Each word's value is multiplied by its corresponding attention score, and the results are summed to create a new, context-aware representation of each word.
Why Self-Attention is a Game Changer
Parallel Processing: Unlike RNNs, Self-Attention processes all words in a sequence simultaneously, making it significantly faster.
Contextual Embeddings: Self-Attention dynamically adjusts word representations based on context, addressing the limitations of static word embeddings.
Long-Range Dependencies: It captures relationships between words irrespective of their distance in a sentence, making it more effective at understanding complex sentences.
Conclusion: From Text Representation to Contextual Understanding
The journey from OHE to Self-Attention is a story of increasing sophistication in how we teach machines to understand human language. Each method brought us closer to mimicking human-like comprehension, with Self-Attention representing a significant leap towards truly contextual language models.
By acknowledging the limitations of earlier methods and embracing the innovations of Self-Attention, we’ve entered an era where machines can not only read but also understand context as humans do. So next time your model spits out an eerily accurate summary of a long document, remember, it’s all thanks to the magic of Self-Attention. And as we continue to push the boundaries of NLP, who knows what’s next in this exciting journey?
Stay tuned for more deep dives into the fascinating world of AI and NLP!
Subscribe to my newsletter
Read articles from pankaj chauhan directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by