Comprehensive Guide to ETCD in Kubernetes
 Hari Kiran B
Hari Kiran BTable of contents
- 1. Introduction to ETCD
- 2. ETCD Architecture
- 3. ETCD's Role in Kubernetes
- 4. ETCD Performance and Scalability in Kubernetes
- 5. ETCD Operations and Maintenance in Kubernetes Clusters
- 6. Advanced ETCD Features in Kubernetes
- 7. ETCD Performance Considerations in Kubernetes
- 8. Monitoring and Troubleshooting ETCD in Kubernetes
- 9. ETCD Security in Kubernetes
- 10. Best Practices for ETCD in Kubernetes Production Environments
- 11. Quick Start Guide: Setting Up ETCD in Kubernetes
- 12. ETCD Architecture Visualization
- 13. ETCD Troubleshooting Guide
- 14. ETCD Performance Tuning
- 15. ETCD vs. Other Distributed Key-Value Stores
- 16. Visualizing ETCD Metrics
- 17. ETCD in Cloud-Native Kubernetes Distributions
- Conclusion

Version Information:
ETCD version discussed: v3.5.x (latest stable as of August 2024)Kubernetes version: 1.29.x (latest stable as of August 2024)
Note: While the principles discussed in this article apply broadly, some specific features or configurations may vary in different versions. Always refer to the official documentation for your specific versions of ETCD and Kubernetes.

1. Introduction to ETCD
ETCD (pronounced "et-see-dee") is a distributed, reliable key-value store that plays a crucial role in maintaining configuration data, state, and metadata for distributed systems, most notably Kubernetes. Its name is derived from the Linux directory structure: "/etc" + "d" for "distributed".
Key Features of ETCD in Kubernetes:
Distributed: ETCD runs across multiple nodes in a Kubernetes cluster, ensuring high availability and fault tolerance. This means that even if one node fails, the system can continue to operate.
ETCD is not just a single server but runs on multiple control plane servers (often called master nodes) within a Kubernetes cluster. This distributed setup ensures that ETCD is highly available and fault-tolerant. In production environments, ETCD typically runs on an odd number of control plane nodes—usually 1, 3, 5, or 7. The reason for using an odd number is to achieve a majority (quorum) during decision-making processes, which is crucial for maintaining consistency and avoiding split-brain scenarios where different parts of the cluster might have conflicting data.
Imagine ETCD as a team working together; if one team member (master node) is unavailable, the rest can still carry on the work. For instance, in a 3-node setup, even if one node fails, the remaining two nodes can still form a majority and keep the cluster operational. This ensures that your Kubernetes cluster remains resilient, maintaining its functionality even in the face of failures.
In simpler terms: Think of ETCD as a group chat. For any decision (like a vote), the group needs a majority to agree. With an odd number of people, there's always a clear majority, ensuring that decisions can be made even if one or more members are unavailable.
Consistent: It uses the Raft consensus algorithm to maintain data consistency across all nodes. This ensures all Kubernetes components have a consistent view of the cluster state.
Jargon explained: The Raft consensus algorithm is a protocol that helps a group of machines agree on a shared state, even in the face of failures.
Key-Value Store: Data in ETCD is stored as key-value pairs, making it simple and efficient to read and write. This structure is ideal for storing Kubernetes objects and their metadata.
For beginners: Think of a key-value store as a digital dictionary. The "key" is like a word, and the "value" is its definition. In ETCD, the "key" might be the name of a Kubernetes resource, and the "value" would be all the information about that resource.
Watch Mechanism: ETCD provides a watch feature that allows Kubernetes components to monitor changes to specific keys or directories. This is particularly useful for controllers that need to react to changes in the cluster state in real-time.
Simplified: Imagine you're watching a social media feed. Instead of constantly refreshing the page, you get notified when there's a new post. That's similar to how ETCD's watch mechanism works for Kubernetes components.
Security: ETCD supports SSL/TLS encryption and authentication for client-server communication, ensuring that your Kubernetes cluster data remains secure.
Jargon explained: SSL (Secure Sockets Layer) and its successor TLS (Transport Layer Security) are protocols that provide secure communication over a network.

Real-World Example:
Imagine you're running a large e-commerce platform on Kubernetes. Your website has multiple microservices, each running as separate pods. ETCD stores critical information about these pods, such as which node they're running on, their current status, and configuration details. When a customer places an order, Kubernetes needs to ensure that the order processing service is available and properly configured. It consults ETCD to get this information quickly and reliably, allowing for seamless operation of your e-commerce platform.
2. ETCD Architecture
Understanding the architecture of ETCD is crucial for grasping its functionality and importance in Kubernetes.
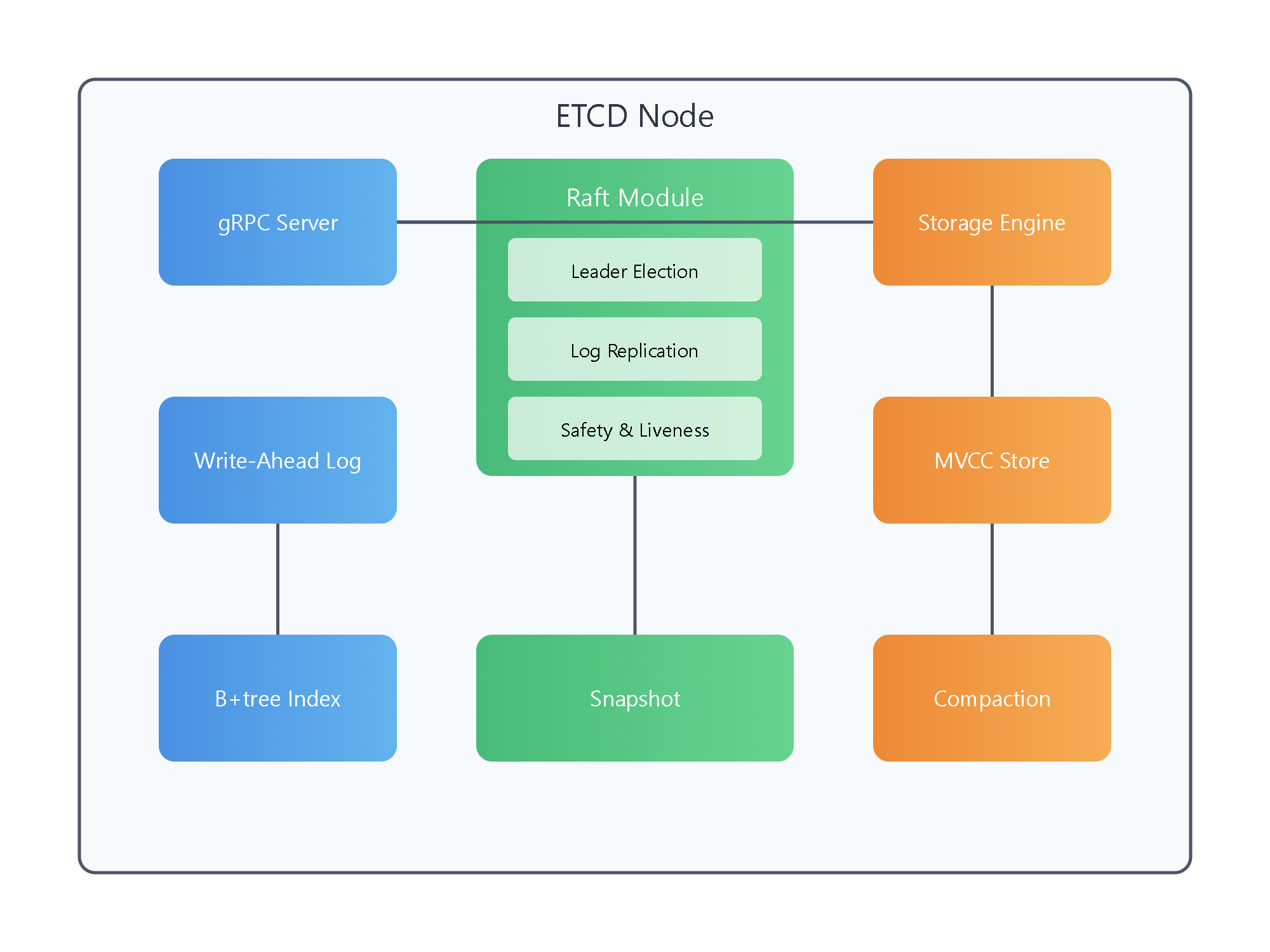
Core Components:
gRPC Server: This is the interface through which Kubernetes components communicate with ETCD.
Jargon explained: gRPC is a high-performance, open-source framework developed by Google for remote procedure calls (RPC). It allows different services to communicate efficiently.
Raft Module: This implements the Raft consensus algorithm, which maintains consistency across the ETCD cluster. It handles leader election, log replication, and safety checks, ensuring that all Kubernetes nodes have a consistent view of the cluster state.
WAL (Write-Ahead Log): This component records all changes before they are applied to the key-value store. It's crucial for crash recovery and ensuring data integrity in Kubernetes clusters.
For beginners: Think of WAL as a detailed diary of all changes. Before making any change to the main data, ETCD writes it in this diary. If something goes wrong, ETCD can look back at this diary to recover.
Storage Engine: This is where the actual Kubernetes data is stored. ETCD uses a persistent B+tree for efficient storage and retrieval of key-value pairs representing Kubernetes objects and their states.
Jargon explained: A B+tree is a data structure that allows for efficient searching, insertion, and deletion of data, even when dealing with large amounts of information.
MVCC (Multi-Version Concurrency Control) Store: This allows multiple versions of the same key to coexist, enabling features like snapshots and historical queries. This is particularly useful for Kubernetes' optimistic concurrency control and auditing capabilities.
Simplified: Imagine you're writing a document with Google Docs. MVCC is like the feature that allows you to see previous versions of the document. In ETCD, this helps Kubernetes manage and track changes to its resources over time.
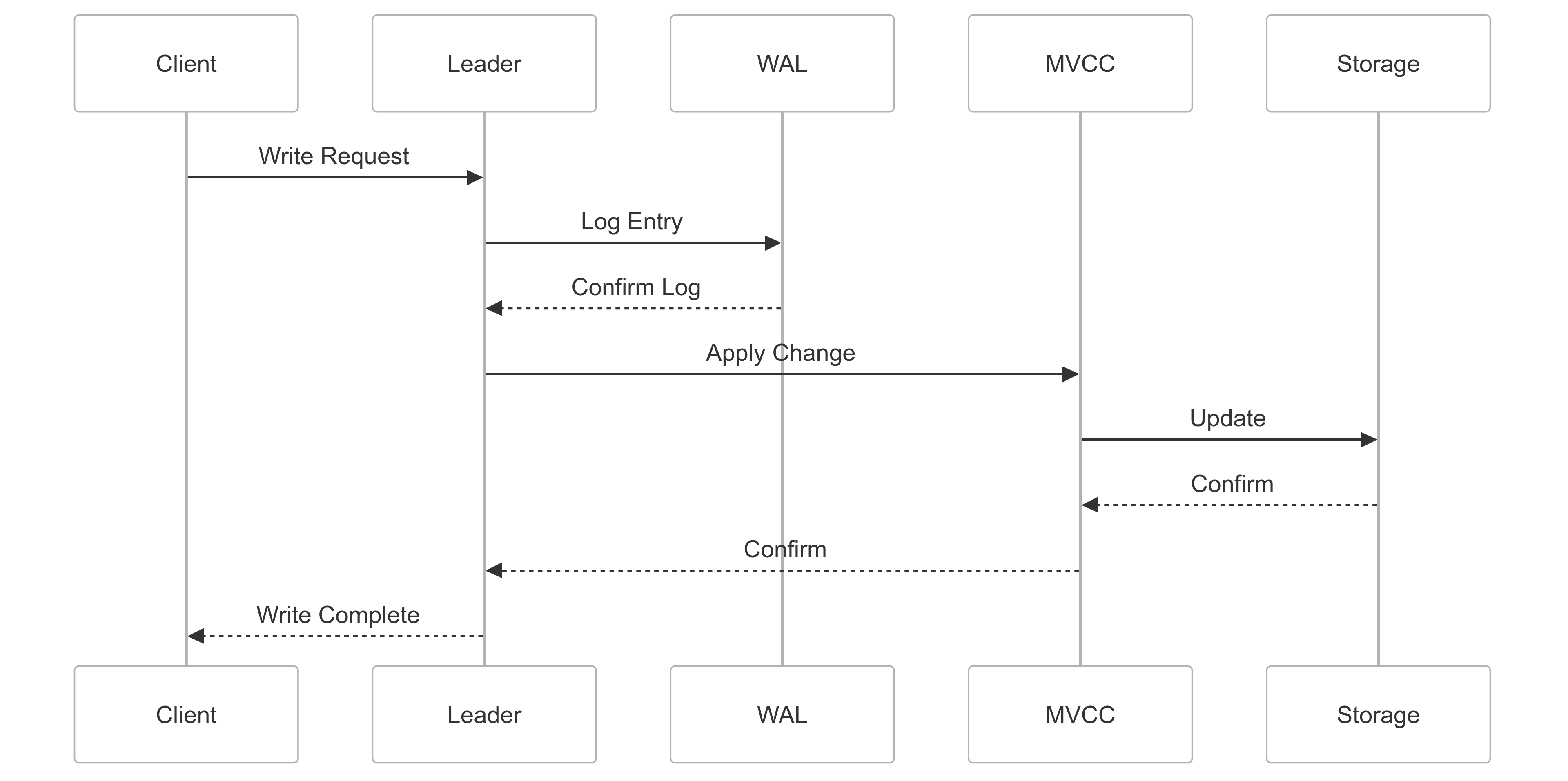
Raft Consensus Algorithm:
The Raft algorithm is the heart of ETCD's distributed nature. In Kubernetes, it ensures that all ETCD nodes agree on the state of the cluster, even in the face of network partitions or node failures.
Note: Slide the bar from right to left if you don't see the Animation.
Key Raft concepts in the context of Kubernetes:
Leader Election: One ETCD node is elected as the leader, responsible for handling all write requests from Kubernetes components.
Log Replication: The leader replicates its log to all followers, ensuring that changes to the Kubernetes cluster state are propagated consistently.
Safety Check: Ensures that if any ETCD node has applied a particular log entry to its state machine, no other node may apply a different log entry for the same index. This guarantees consistency in Kubernetes object states across the cluster.
Real-World Example:
Let's say you're running a global ride-sharing application on Kubernetes. Your ETCD cluster consists of five nodes spread across different regions. When a new driver joins your platform in Tokyo, the information is written to the ETCD leader node. The Raft algorithm ensures this information is replicated to all other ETCD nodes. Even if the Singapore data center experiences a network issue, the system remains consistent and operational, allowing riders in New York to see the updated driver pool.
3. ETCD's Role in Kubernetes
In Kubernetes, ETCD serves as the primary datastore, holding all cluster data. This includes:
Node Information: Details about each node in the cluster, including its capacity, condition, and current state.
Pod Definitions: The desired state of each pod, including its containers, volumes, and networking requirements.
ConfigMaps and Secrets: Configuration data and sensitive information used by applications running in the cluster.
Service Endpoints: Information about how to access services running in the cluster.
Cluster State: The overall state of the cluster, including the state of all Custom Resources.
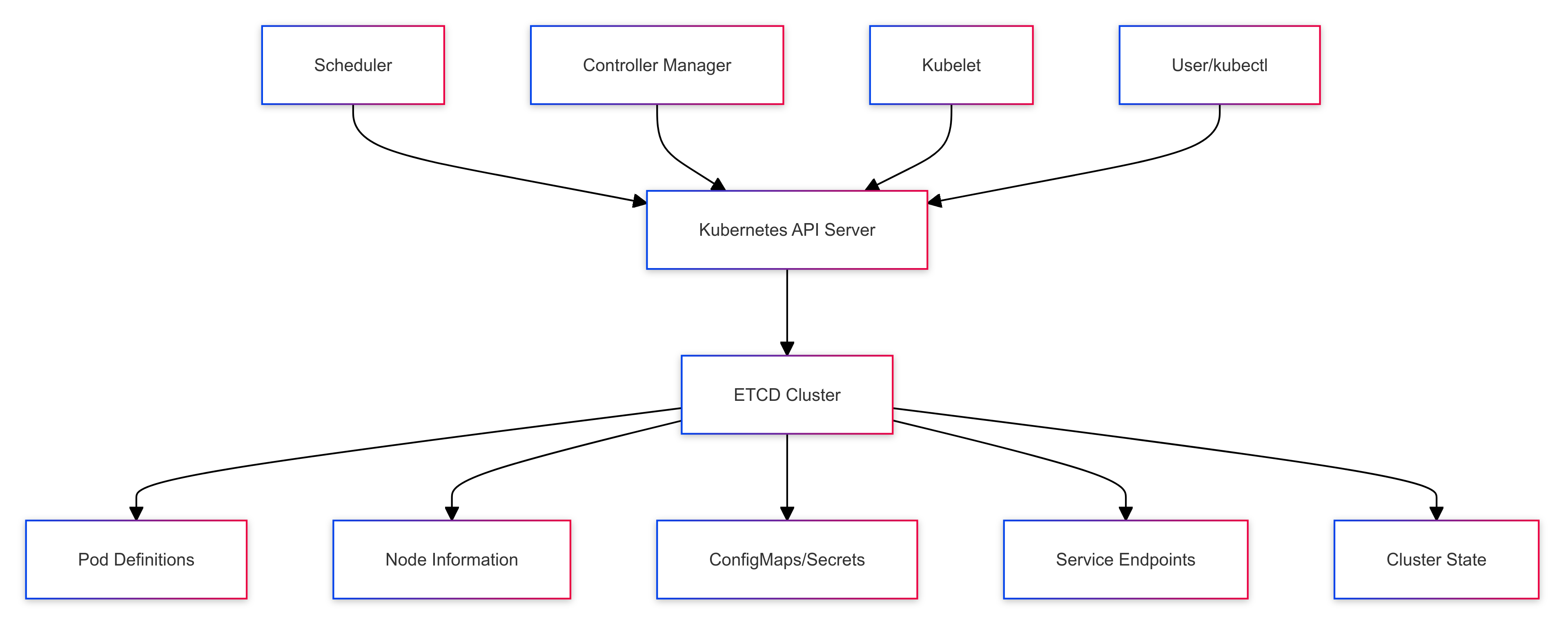
How Kubernetes Components Interact with ETCD:
API Server: The primary point of interaction between Kubernetes components and ETCD. It reads from and writes to ETCD based on user commands and internal processes.
Scheduler: Reads the state of unscheduled pods from ETCD and writes back scheduling decisions.
Controller Manager: Continuously watches ETCD for changes and ensures the actual state of the cluster matches the desired state.
Kubelet: Regularly updates the status of its node and the pods running on it in ETCD.
Real-World Example:
Imagine you're managing a news website using Kubernetes. When breaking news occurs, you need to quickly scale up your web servers. You issue a command to increase the number of pod replicas. Here's what happens:
The API server writes the new desired state to ETCD.
The controller manager, watching ETCD, notices this change and creates new pod objects.
The scheduler, also watching ETCD, sees these new unscheduled pods and assigns them to nodes.
The kubelet on each assigned node sees it has new pods to run and starts them up.
Each step of this process involves reading from or writing to ETCD, ensuring a consistent and reliable scaling operation.
4. ETCD Performance and Scalability in Kubernetes
ETCD's performance and scalability are critical for the overall performance of a Kubernetes cluster. Here are key factors to consider:
Latency:
In Kubernetes, ETCD aims for sub-millisecond latency for reads and writes. This is crucial for responsive cluster operations.
For beginners: Latency refers to the time delay between an action and its result. Low latency means Kubernetes can quickly retrieve or update information, leading to faster overall performance.
Throughput:
A well-tuned ETCD cluster can handle thousands of requests per second from various Kubernetes components.
Simplified: Throughput is like the number of cars that can pass through a tunnel in a given time. Higher throughput means ETCD can handle more Kubernetes operations simultaneously.
Scalability:
While ETCD supports clusters of up to 7 nodes for optimal performance, most Kubernetes deployments use 3 or 5 ETCD nodes for a balance of performance and fault tolerance.
Example benchmark results in a Kubernetes context:
Write throughput: 10,000 writes/sec (e.g., pod creations, updates)
Read throughput: 50,000 reads/sec (e.g., listing pods, getting node status)
Latency (99th percentile):
Write: 10ms
Read: 5ms
Important Note on Performance Metrics: The performance numbers provided are examples based on specific hardware configurations and workloads. Actual performance can vary significantly based on factors such as:
Hardware specifications (CPU, RAM, storage type)
Network latency and bandwidth
Cluster size and configuration
Workload characteristics (read/write ratio, key size, value size)
For accurate performance metrics in your environment, it's crucial to conduct benchmarks on your specific infrastructure with workloads that mirror your actual usage patterns.
Real-World Example:
Consider a large-scale video streaming platform running on Kubernetes. During prime time, you might experience a sudden surge in user activity, leading to rapid scaling of microservices, frequent updates to ConfigMaps, and constant service discovery operations. All these activities translate to a high number of read-and-write operations on ETCD. With proper tuning and scaling, ETCD can handle this load, ensuring your platform remains responsive even during peak hours.
5. ETCD Operations and Maintenance in Kubernetes Clusters
Backup and Restore
Backing up ETCD is crucial for disaster recovery in Kubernetes clusters. There are two main methods:

Snapshot: A point-in-time copy of the ETCD database.
WAL (Write-Ahead Log): Continuous backup of all transactions.
Creating a Snapshot in a Kubernetes Cluster:
Use the etcdctl command-line tool to create a snapshot:
ETCDCTL_API=3 etcdctl --endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
snapshot save /backup/etcd-snapshot-$(date +%Y-%m-%d_%H:%M:%S).db
For beginners: This command is like taking a photograph of your ETCD database at a specific moment. The resulting file can be used to restore your cluster if something goes wrong.
Automating Backups:
You can automate this process using a CronJob in Kubernetes:
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: etcd-backup
spec:
schedule: "0 1 * * *" # Daily at 1 AM
jobTemplate:
spec:
template:
spec:
containers:
- name: etcd-backup
image: k8s.gcr.io/etcd:3.4.13-0
command: ["/bin/sh"]
args: ["-c", "etcdctl snapshot save /backup/etcd-snapshot-$(date +%Y-%m-%d_%H:%M:%S).db"]
volumeMounts:
- name: etcd-certs
mountPath: /etc/kubernetes/pki/etcd
- name: backup
mountPath: /backup
restartPolicy: OnFailure
volumes:
- name: etcd-certs
hostPath:
path: /etc/kubernetes/pki/etcd
type: Directory
- name: backup
hostPath:
path: /var/etcd-backup
type: DirectoryOrCreate
Explained: This YAML file defines a job that runs automatically every day at 1 AM to create a backup of your ETCD data.
Restoring from a Snapshot:
To restore ETCD from a snapshot in a Kubernetes cluster:
ETCDCTL_API=3 etcdctl snapshot restore /backup/etcd-snapshot-2023-08-28_14:30:00.db \
--data-dir /var/lib/etcd-restore \
--initial-cluster etcd-0=https://10.0.0.1:2380,etcd-1=https://10.0.0.2:2380,etcd-2=https://10.0.0.3:2380 \
--initial-cluster-token etcd-cluster-1 \
--initial-advertise-peer-urls https://10.0.0.1:2380
After restoration, update the ETCD configuration to use the new data directory and restart the ETCD service.
For beginners: This process is like restoring your computer from a backup after a crash. It brings your Kubernetes cluster back to the state it was in when the snapshot was taken.
Compaction and Defragmentation
ETCD uses MVCC (Multi-Version Concurrency Control), which can lead to increased storage usage over time, especially in busy Kubernetes clusters. Regular compaction and defragmentation are necessary for optimal performance.
Compaction:
Compaction removes old versions of keys:
ETCDCTL_API=3 etcdctl compact $(etcdctl endpoint status --write-out="json" | egrep -o '"revision":[0-9]*' | egrep -o '[0-9].*')
Simplified: This is like clearing out old, unnecessary files to free up space and improve performance.
Defragmentation:
Defragmentation reclaims disk space:
ETCDCTL_API=3 etcdctl defrag
For beginners: This is similar to defragmenting your computer's hard drive. It reorganizes data to use disk space more efficiently and improve performance.
Real-World Example:
Imagine you're running a financial trading platform on Kubernetes. Your ETCD cluster stores critical information about trades, user accounts, and market data. Regular backups ensure that even in the event of a catastrophic failure, you can recover quickly with minimal data loss. Compaction and defragmentation help maintain ETCD's performance, ensuring that trade executions and market updates happen without delays, even as your platform handles millions of transactions daily.
6. Advanced ETCD Features in Kubernetes
Watch Mechanism
The watch mechanism is crucial for Kubernetes' reactive architecture. Components like the scheduler, controller manager, and kubelets use watches to monitor changes in the cluster state.
Example of how a Deployment controller watches for changes to Deployment objects:
watchInterface, err := client.AppsV1().Deployments(namespace).Watch(context.TODO(), metav1.ListOptions{})
if err != nil {
// Handle error
}
for event := range watchInterface.ResultChan() {
deployment, ok := event.Object.(*appsv1.Deployment)
if !ok {
// Handle unexpected type
continue
}
switch event.Type {
case watch.Added:
// Handle new deployment
case watch.Modified:
// Handle updated deployment
case watch.Deleted:
// Handle deleted deployment
}
}
For beginners: This is like setting up notifications on your phone. Instead of constantly checking for updates, Kubernetes components get notified when something changes, allowing them to react quickly and efficiently.
Leases and TTL
ETCD supports key expiration through leases and Time-To-Live (TTL) settings. In Kubernetes, this is used for implementing features like node heartbeats and controller leader election.
Example of creating a lease and attaching a key:
# Create a lease with TTL of 100 seconds
LEASE_ID=$(etcdctl lease grant 100 | awk '{print $2}')
# Attach a key to the lease (e.g., for a controller leader lock)
etcdctl put --lease=$LEASE_ID /controller/leader "controller-1"
Explained: This is like setting an expiration date on information. It's useful for temporary data or ensuring that stale information gets automatically cleaned up.
Transactions
ETCD supports multi-key transactions, ensuring atomicity for complex operations. This is used in Kubernetes for operations that need to update multiple related objects atomically.
Example of a transaction in Go for a Kubernetes operation:
_, err := cli.Txn(context.Background()).
If(clientv3.Compare(clientv3.Value("/pods/mypod"), "=", "running")).
Then(clientv3.OpPut("/services/myservice", "active")).
Else(clientv3.OpPut("/services/myservice", "inactive")).
Commit()
For beginners: This is like making sure a series of related actions either all happen successfully or none of them happen at all. It's crucial for maintaining data consistency in complex operations.
Real-World Example:
Consider a microservices-based e-commerce platform running on Kubernetes. When a user places an order, multiple services need to be updated atomically: inventory needs to be decreased, the order needs to be created, and the user's account needs to be updated. Using ETCD's transaction feature, Kubernetes can ensure that all these updates happen together, maintaining data consistency even if there's a failure midway through the process.
7. ETCD Performance Considerations in Kubernetes
In a Kubernetes environment, ETCD performance is critical for the overall cluster performance. Here are some key considerations:
Resource Allocation
CPU: ETCD is CPU-intensive, especially during leader elections and when handling a high number of writes. Allocate at least 2 dedicated CPU cores for ETCD in production environments.
Memory: ETCD keeps its working set in memory. Allocate enough RAM to keep the entire dataset in memory, plus extra for write buffers. A good starting point is 8GB for small to medium clusters.
Storage: Use SSDs for ETCD storage. The high I/O operations, especially during heavy write loads, can cause significant performance degradation on HDDs.
For beginners: Think of these resources like ingredients for a recipe. You need the right amount of each to ensure your ETCD "dish" comes out perfectly.
ETCD Cluster Size
The size of your ETCD cluster can significantly impact performance:
3 nodes: Recommended for most production environments. Can tolerate 1 node failure.
5 nodes: For larger clusters. Can tolerate 2 node failures. Offers better read performance but slightly lower write performance compared to 3 nodes.
7 nodes: Maximum recommended size. Can tolerate 3-node failures. Use only for very large clusters.
Remember, an odd number of nodes is crucial for leader election in the Raft consensus algorithm.
Simplified: It's like choosing the right size team for a project. Too few members might not be able to handle the workload, while too many can slow down decision-making.
Network Latency
ETCD is sensitive to network latency. In a geographically distributed Kubernetes cluster:
Keep ETCD nodes in the same data center or region if possible.
Use low-latency, high-bandwidth network connections between ETCD nodes.
Consider using dedicated network interfaces for ETCD traffic in large clusters.
For beginners: Think of network latency like the delay in a long-distance phone call. The closer ETCD nodes are to each other, the faster they can communicate, leading to better overall performance.
Configuration Tuning
--snapshot-count: Adjust the number of commits before creating a snapshot. This can be tuned based on the write load in your Kubernetes cluster.--heartbeat-intervaland--election-timeout: Fine-tune these for your network conditions to ensure proper leader election and cluster stability.
Example configuration for a Kubernetes ETCD setup:
etcd:
snapshot-count: 10000
heartbeat-interval: 100ms
election-timeout: 1000ms
Explained: These settings are like fine-tuning a car engine. The right adjustments can significantly improve ETCD's performance in your specific Kubernetes environment.
Real-World Example:
Imagine you're running a global social media platform on Kubernetes. Your users are spread across multiple continents, and you need to ensure low latency for all of them. By carefully positioning your ETCD nodes, using high-performance networks, and fine-tuning your configuration, you can maintain responsive performance for users worldwide, even as your platform handles millions of posts, likes, and comments every minute.
8. Monitoring and Troubleshooting ETCD in Kubernetes
Effective monitoring is key to maintaining a healthy ETCD cluster in Kubernetes.
Prometheus Monitoring
Here's an example of setting up Prometheus monitoring for ETCD in a Kubernetes cluster:
scrape_configs:
- job_name: 'etcd'
static_configs:
- targets: ['localhost:2379']
scheme: https
tls_config:
ca_file: /etc/kubernetes/pki/etcd/ca.crt
cert_file: /etc/kubernetes/pki/etcd/healthcheck-client.crt
key_file: /etc/kubernetes/pki/etcd/healthcheck-client.key
For beginners: This configuration is like setting up a health monitor for ETCD. It allows you to keep track of ETCD's vital signs and get alerted if something goes wrong.
Troubleshooting Common Issues
Split Brain: This occurs when network partition leads to multiple leaders.
- Resolution: Ensure proper network connectivity and adjust election timeout.
High Disk I/O: This can lead to increased latency in Kubernetes operations.
- Resolution: Use SSDs, optimize compaction settings, and consider scaling out the ETCD cluster.
Memory Leaks: Can cause OOM kills, disrupting the Kubernetes control plane.
- Resolution: Upgrade to the latest ETCD version, adjust heap size, monitor, and restart if necessary.
Simplified: These issues are like common health problems. Just as you'd treat a fever or manage blood pressure, these resolutions help keep ETCD healthy and functioning optimally.
Example of checking ETCD health in a Kubernetes cluster:
ETCDCTL_API=3 etcdctl endpoint health
Key metrics to monitor:
etcd_server_has_leader: Should always be 1 for a healthy cluster.etcd_mvcc_db_total_size_in_bytes: Monitor the growth of the ETCD database.etcd_network_peer_round_trip_time_seconds: Network latency between ETCD nodes.etcd_server_slow_apply_total: Number of slow apply operations (should be 0 or very low).
Example Prometheus query to alert on ETCD database size:
etcd_mvcc_db_total_size_in_bytes > 858993459
For beginners: These metrics are like vital signs for ETCD. Just as a doctor monitors heart rate or blood pressure, these metrics help you keep track of ETCD's health in your Kubernetes cluster.
Real-World Example:
Let's say you're managing a large-scale online gaming platform using Kubernetes. During a major game release, you notice increased latency in matchmaking. By monitoring ETCD metrics, you identify that the ETCD database size has grown significantly due to the influx of new player data. You use this information to trigger a compaction job, reducing the database size and restoring normal performance, ensuring players can join matches quickly.
9. ETCD Security in Kubernetes
Security is paramount when dealing with ETCD in a Kubernetes environment, as it contains all the sensitive data of your cluster.
Encryption at Rest
Enable encryption at rest for ETCD:
- Create an encryption configuration file:
apiVersion: apiserver.config.k8s.io/v1
kind: EncryptionConfiguration
resources:
- resources:
- secrets
providers:
- aescbc:
keys:
- name: key1
secret: <base64-encoded-secret>
- identity: {}
- Update the API server configuration to use this encryption config:
apiVersion: v1
kind: Pod
metadata:
name: kube-apiserver
namespace: kube-system
spec:
containers:
- command:
- kube-apiserver
...
- --encryption-provider-config=/etc/kubernetes/encryption/config.yaml
volumeMounts:
- name: encryption-config
mountPath: /etc/kubernetes/encryption
readOnly: true
volumes:
- name: encryption-config
hostPath:
path: /etc/kubernetes/encryption
type: DirectoryOrCreate
For beginners: Encryption at rest is like putting your valuables in a safe. Even if someone gains physical access to the storage where ETCD data is kept, they won't be able to read the sensitive information without the encryption key.
TLS Configuration
Ensure all ETCD communications are encrypted using TLS:
etcd:
certFile: /path/to/server.crt
keyFile: /path/to/server.key
trustedCAFile: /path/to/ca.crt
clientCertAuth: true
peerCertFile: /path/to/peer.crt
peerKeyFile: /path/to/peer.key
peerClientCertAuth: true
peerTrustedCAFile: /path/to/peer-ca.crt
Explained: TLS is like using a secure, private tunnel for all communication. It ensures that data transmitted between ETCD nodes and clients, can't be intercepted or tampered with.
RBAC for ETCD Access
Implement Role-Based Access Control (RBAC) to restrict access to ETCD:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: kube-system
name: etcd-manager
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["services"]
verbs: ["get"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: etcd-manager-binding
namespace: kube-system
subjects:
- kind: User
name: etcd-manager
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role
name: etcd-manager
apiGroup: rbac.authorization.k8s.io
For beginners: RBAC is like having different keys for different rooms in a building. It ensures that users and services only have access to the specific ETCD data they need, improving overall security.
Note: Slide the bar from right to left if you don't see the Animation.
ETCD Security Best Practices in Kubernetes
Encrypt ETCD Data at Rest: Use Kubernetes' encryption at rest feature to encrypt sensitive data in ETCD.
Regularly Rotate Certificates: Implement a process for rotating ETCD's TLS certificates.
Limit Access: Restrict access to ETCD endpoints and ensure they're not exposed to the public internet.
Use Strong Authentication: Implement certificate-based authentication for ETCD clients.
Real-World Example:
Consider a healthcare application running on Kubernetes that stores patient data. Implementing these security measures ensures that sensitive patient information in ETCD is encrypted, access is strictly controlled, and all communications are secure. This helps maintain patient privacy and comply with regulations like HIPAA.
Recent Security Enhancements and Best Practices:
Mutual TLS (mTLS): Implement mTLS for all ETCD communications to ensure both client and server authenticate each other.
Least Privilege Principle: Use Kubernetes RBAC to grant minimal necessary permissions to pods that need to interact with ETCD.
Regular Security Audits: Conduct periodic security audits of your ETCD configuration and access patterns.
Encryption Key Rotation: Implement a process for regularly rotating encryption keys used for ETCD's at-rest encryption.
Network Policies: Use Kubernetes Network Policies to restrict which pods can communicate with ETCD.
Secure ETCD Ports: Ensure ETCD client and peer ports (typically 2379 and 2380) are not exposed outside the cluster.
Use Security Scanning Tools: Regularly scan your ETCD instances with container security scanning tools to identify vulnerabilities.
Always refer to the latest ETCD and Kubernetes security documentation for the most up-to-date best practices.
10. Best Practices for ETCD in Kubernetes Production Environments
To ensure optimal performance and reliability of ETCD in your Kubernetes cluster:
Use an odd number of ETCD nodes (3, 5, or 7) for proper consensus.
Implement regular automated backups.
Monitor ETCD performance and set up alerts for key metrics.
Use high-performance SSDs for ETCD storage.
Keep ETCD nodes in close network proximity.
Regularly defragment and compact the ETCD database.
Use separate disks for ETCD data and WAL (Write-Ahead Log) for better performance.
Implement proper security measures including TLS and RBAC.
Regularly update ETCD to the latest stable version compatible with your Kubernetes version.
Perform regular disaster recovery drills to ensure your backup and restore procedures work as expected.
For beginners: Think of these best practices as a checklist for maintaining a high-performance vehicle. Regular maintenance, using the right parts, and periodic check-ups ensure your ETCD "vehicle" runs smoothly in your Kubernetes "race".
11. Quick Start Guide: Setting Up ETCD in Kubernetes
For those who want to get hands-on quickly, here's a step-by-step guide to setting up a basic ETCD cluster in Kubernetes:
- Create an ETCD StatefulSet:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: etcd
namespace: kube-system
spec:
serviceName: "etcd"
replicas: 3
selector:
matchLabels:
app: etcd
template:
metadata:
labels:
app: etcd
spec:
containers:
- name: etcd
image: quay.io/coreos/etcd:v3.4.13
ports:
- containerPort: 2379
name: client
- containerPort: 2380
name: peer
volumeMounts:
- name: data
mountPath: /var/run/etcd
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 1Gi
- Create a Service for ETCD:
apiVersion: v1
kind: Service
metadata:
name: etcd
namespace: kube-system
spec:
ports:
- port: 2379
name: client
- port: 2380
name: peer
clusterIP: None
selector:
app: etcd
- Apply these YAML files:
kubectl apply -f etcd-statefulset.yaml
kubectl apply -f etcd-service.yaml
- Verify the ETCD cluster is running:
kubectl get pods -n kube-system | grep etcd
Note: This is a basic setup for demonstration purposes. For production use, you'll need to configure security settings, and persistent storage, and integrate with your Kubernetes control plane components.
12. ETCD Architecture Visualization
To better understand how ETCD integrates with Kubernetes, let's look at a visual representation:
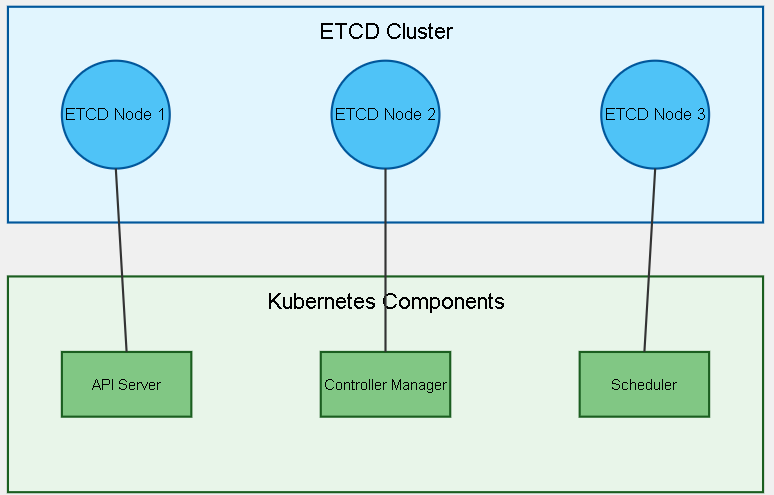
This diagram illustrates the relationship between the ETCD cluster and key Kubernetes components. The ETCD cluster, typically consisting of three or five nodes, forms the backbone of Kubernetes' data storage. The API server, Controller Manager, and Scheduler all interact with ETCD to read and write cluster state information.
13. ETCD Troubleshooting Guide
When encountering issues with ETCD in your Kubernetes cluster, follow this decision tree to diagnose and resolve common problems:
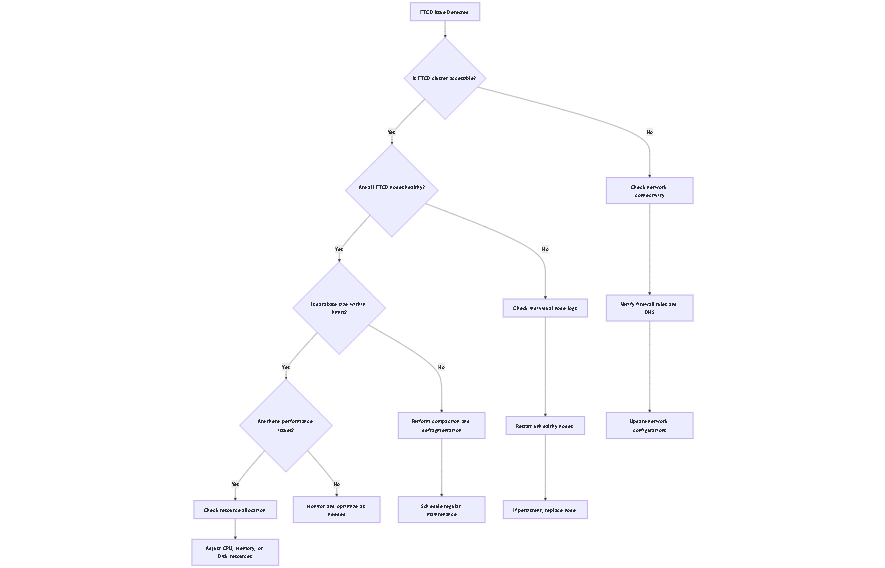
This troubleshooting tree provides a systematic approach to identifying and resolving ETCD issues in your Kubernetes cluster. Always start by checking if the ETCD cluster is accessible, then proceed through the various branches based on your observations.
14. ETCD Performance Tuning
Optimizing ETCD performance is crucial for maintaining a responsive Kubernetes cluster. Here are some advanced tuning techniques:
Adjust snapshot frequency:
etcd: snapshot-count: 10000Increase this value for high-write environments to reduce I/O overhead.
Optimize WAL (Write Ahead Log) sync:
etcd: wal-sync-interval: "5ms"Adjust based on your storage performance and consistency requirements.
Fine-tune compaction:
etcd: auto-compaction-mode: "periodic" auto-compaction-retention: "1h"Set shorter intervals for high-churn clusters to manage database size effectively.
Adjust heartbeat and election timeouts:
etcd: heartbeat-interval: 100ms election-timeout: 1000msTune these values based on your network latency for faster leader election.
Remember to benchmark your cluster before and after changes to measure the impact of your optimizations.
15. ETCD vs. Other Distributed Key-Value Stores
While ETCD is the default for Kubernetes, it's useful to understand how it compares to alternatives:
| Feature | ETCD | Consul | ZooKeeper |
| Consistency Model | Strong (CP) | Strong (CP) | Strong (CP) |
| API | gRPC | HTTP/DNS | Custom |
| Watch Support | Yes | Yes | Yes |
| Transactions | Yes | No | Limited |
| TTL Support | Yes | Yes | No |
| Multi-Datacenter | Limited | Yes | Limited |
| Kubernetes Integration | Native | Possible | Possible |
Detailed Comparison of ETCD Alternatives:
Consul:
Strengths: Built-in service discovery, health checking, and multi-datacenter support
Weaknesses: Less native integration with Kubernetes, more complex setup
Use case: Better suited for microservices architectures that need service discovery beyond what Kubernetes provides
ZooKeeper:
Strengths: Mature project with strong consistency guarantees
Weaknesses: More complex API, less suitable for rapid read/write operations
Use case: Better for scenarios requiring complex coordination primitives
Redis:
Strengths: Extremely fast, supports complex data structures
Weaknesses: Eventual consistency (in clustered mode), less suitable for storing critical cluster state
Use case: Better for caching and scenarios where eventual consistency is acceptable
When to Consider Alternatives:
Multi-cloud or hybrid deployments where Consul's multi-datacenter features are beneficial
When additional features like service discovery (Consul) or complex data structures (Redis) are required
In specialized use cases where ZooKeeper's strong consistency and coordination primitives are necessary
For most Kubernetes deployments, ETCD remains the recommended choice due to its native integration and optimization for Kubernetes' specific needs.
16. Visualizing ETCD Metrics
Monitoring ETCD metrics is essential for maintaining a healthy Kubernetes cluster. Here's a simple React component that demonstrates how you might visualize some key ETCD metrics:
Note: Slide the bar from right to left if you don't see the animation.
This dashboard provides a real-time view of important ETCD metrics such as database size, Raft term, and leader changes. In a production environment, you'd connect this to real data from your ETCD cluster, possibly using Prometheus as a data source.
17. ETCD in Cloud-Native Kubernetes Distributions
Cloud providers often offer managed Kubernetes services with optimized ETCD configurations:
AWS EKS (Elastic Kubernetes Service):
Manages ETCD as a hidden service
Automatically handles scaling, backups, and upgrades
Uses encrypted EBS volumes for ETCD storage
Google GKE (Google Kubernetes Engine):
Offers a fully managed control plane with ETCD
Provides automatic upgrades and security patches
Supports regional clusters for high-availability
Azure AKS (Azure Kubernetes Service):
Manages ETCD as part of the control plane
Offers managed upgrades and scaling
Provides integration with Azure Key Vault for enhanced security
DigitalOcean Kubernetes:
Fully manages ETCD as part of the control plane
Handles automatic updates and security patches
Provides daily ETCD snapshots for backup
Considerations for Cloud-Native ETCD:
Reduced operational overhead: Cloud providers handle most ETCD management tasks
Limited customization: Less control over specific ETCD configurations
Integrated security: Often integrated with the cloud provider's security features
Cost: The convenience of managed services often comes with higher costs
When using cloud-native Kubernetes distributions, it's important to understand the provider's specific implementation of ETCD, including any limitations or unique features that may affect your application's behavior or performance.
Conclusion
ETCD plays a crucial role in Kubernetes, serving as the backbone for storing all cluster data. Understanding its intricacies, from basic operations to advanced features and production best practices, is essential for maintaining robust and scalable Kubernetes clusters.
By mastering topics such as ETCD's interaction with Kubernetes components, performance optimization, security configuration, and disaster recovery procedures, you'll be well-equipped to handle ETCD in production Kubernetes environments. Remember that both ETCD and Kubernetes are actively developed, so staying updated with the latest releases and best practices is essential for optimal performance and security.
This comprehensive guide to ETCD in the context of Kubernetes should provide you with a solid foundation for working with this critical component in modern container orchestration systems. As you continue to work with ETCD and Kubernetes, you'll discover their combined power and flexibility in solving complex distributed system challenges.
Additional Resources
For readers who want to dive even deeper into ETCD and Kubernetes, here are some valuable resources:
Kubernetes The Hard Way - A tutorial that includes setting up ETCD for Kubernetes
Always refer to the most up-to-date documentation, as both ETCD and Kubernetes evolve rapidly.
Acknowledgments: I'd like to thank ClaudeAI for providing valuable insights and detailed explanations that enriched this article. The assistance was instrumental in crafting a comprehensive overview of ETCD's role in Kubernetes.
Subscribe to my newsletter
Read articles from Hari Kiran B directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by