A Comprehensive Understanding of Actor Model & How It Acheives Parallel Computation And Scalability In Vara Network
 Rocky Essel
Rocky EsselTable of contents
Introduction
The Vara Network, built on the Gear Protocol, represents a groundbreaking approach in the world of blockchain technology, particularly in terms of parallel computation and scalability. Central to its architecture is the Actor Model, a computational framework that plays a pivotal role in managing complex, concurrent operations. As blockchain technology continues to evolve, the need for efficient and scalable systems becomes increasingly critical. The Actor Model, with its ability to manage parallel computations effectively, provides a robust solution for these demands.
In this article, we delve into the mechanics of the Actor Model, explore how it achieves parallel computation, and examine its implementation within the Vara Network. We will also discuss the specific advantages it brings to the table, particularly in terms of scalability, and efficiency in a distributed environment.
The Actor Model: An Overview
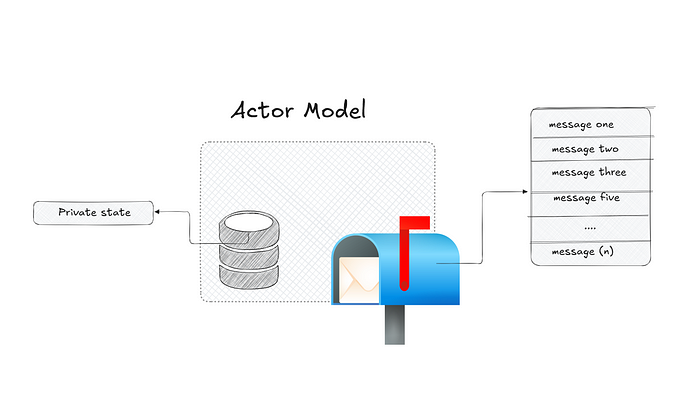
An actor model represents a paradigm shift from traditional sequential programming models. What I mean is that, in traditional sequential programming models, programs execute a series of instructions in a strict linear order, from one operation to another (step by step). This model works well for single-threaded applications where tasks are performed one at a time. However, as computing needs have grown, especially with the rise of multi-core processors, distributed systems, and real-time applications, this sequential model has become less effective.
The Actor Model has introduced a completely different way of thinking about computation. Now, instead of relying on a single, linear flow of control, the Actor Model allows for multiple actors(independent units of computation) to operate concurrently as each actor can perform tasks independently, communicate with each other asynchronously, and handle its own state without needing to share the memory directly with other actors.
Message-passing is the term used when there’s a communication between two or more actors.
The Actor Model introduces a new approach where multiple actors (independent units of computation) operate concurrently. Each actor can perform tasks independently, communicate asynchronously with other actors, and manage its own state without directly sharing memory with other actors.
Instead of waiting or blocking messages, each actor has a mailbox that holds incoming messages. The actor processes these messages sequentially based on its current behaviour. Unlike in traditional concurrency models, actors can share data by passing messages between them.
Now, whenever you hear or think of an Actor Model, you should know it embodies the following properties.
— Message Processing: An actor can perform several actions in response to a received message, including creating new actors, sending messages to other actors, and making local decisions that may alter its internal state. Importantly, an actor’s mutable state can only be accessed by one task at a time, ensuring that no concurrent modifications occur within a single actor.
— State Encapsulation: Actors encapsulate their internal state, which can only be modified through message passing. This encapsulation enforces strict control over how state changes occur, making it easier to reason about the systems; behaviour, and prevent unintended side effects.
— Asynchronous Operation: Actors inherently support asynchronous operations. Since actors process messages one at a time, they naturally handle multiple tasks concurrently without the risk of race conditions or deadlocks that plague traditional concurrency models.
— Persistence: Actors are persistent entities within the system, once they are created, an actor can exist until explicitly terminated or until an unhandled exception causes it to crash.
— Best-Effot Delivery: Communication between actors relies on a bet-effect delivery mechanism, which means that while the Actor Model attempt to deliver messages reliably, there are no guarantees about message ordering or delivery times. This property necessitates careful design to handle potential delays it message losses gracefully. Later we’ll talk about how Gear Protocol which is the foundational pillar for Vara Networks solves this in their own Actor Model.
No contradictions
In the message processing section, I mentioned two things that sounded vague, one was saying “making local decisions”, and the other was saying “Importantly, actors process only one message at a time”. Let’s take the latter part first. You should be asking yourself this question, “If actors process only one message at a time, then how is that concurrent or parallel”, that’s a great question, and the answer is, that it isn’t concurrent or parallel.
How Concurrency Works in the Actor Model
To get to the heart of how concurrency is handled in an Actor Model in general, let’s take this analogy.
Think of a customer service centre where each representative (Actor) can only handle one call (message) at a time. Now, however, the call centre as a whole can handle many calls at once because it has many representatives working together (in parallel) at the same time. So even though each representative is dealing with one customer at a time, the overall centre is highly concurrent because multiple representatives are working independently at the same time dealing with different customers.
Now, coming back to our analogy, while an individual actor processes only one message at a time, the Actor Model enables concurrency by allowing multiple actors to operate simultaneously. So in a system with many actors like the analogy I explained, each actor can be processing its own message independently of others, So, although any single actor is handling message processing sequentially, the entire system as a whole is performing many operations concurrently across different actors.
So let’s go a bit further.
Parallelism with Multiple Actors
The simultaneous execution of multiple computations is referred to as Parallelism. Now, in the Actor Model, especially in the context of modern multi-core processors, means that multiple independent cores can execute instructions simultaneously. For example, a quad-core processor can run four threads in parallel, while an octa-core processor can run eight.
Already, I’ve established with you the fact that each actor operates independently, with its own state and message-processing logic. Now, this independence allows for different actors to be executed on different cores without any risk of interfering with each other. Also, one-way actors utilize the cores through the distribution of actors across multi-core processors, where a runtime system or a scheduler can distribute actors across the available cores in a multi-core processor. For instance, if there are, let’s say 10 actors and the system has a 10-core processor, now each actor can be assigned to a core, and what does means is that, all 10 actors can run at the same time, each on its own assigned core to processing messages concurrently, which falls into the definition of parallelism.
Now, how the Actor Model utilizes the cores leads to significant performance improvements, especially in a network or system that requires high throughput and real-time processing like Gear Protocol.
What making local decisions is about in Actor
Now that you understand that actors have a state, and the only way an actor’s state can alter their internal state is through message-passing. Let’s dive deeper into how this works. An actor’s ability to independently process a message and update its own data or behaviour is at the core of making local decisions Each actor maintains its own internal state, which is completely private and encapsulated. No other actor can directly access or modify this state. The only way for one actor to influence another actor’s state is through message-passing.
Let’s expand on the example of sending VARA tokens between actors:
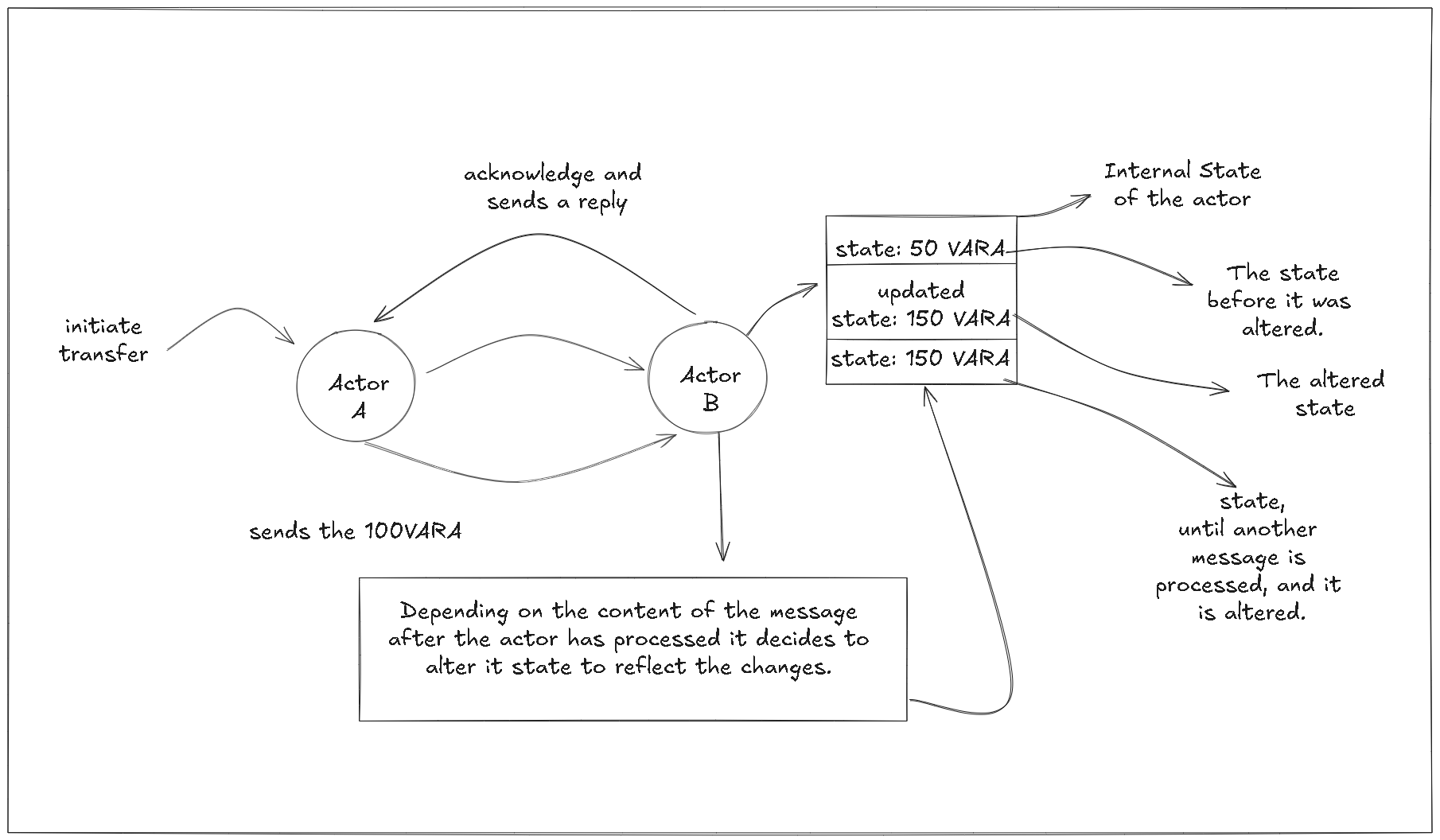
— Initial State: Suppose Actor B starts with 50 VARA tokens in its internal state.
— Message-Passing: Actor A decides to send 100 VARA tokens to Actor B. Now, to do this, Actor A sends a message to Actor B that includes the amount to be transferred.
— Processing the Message: When Actor B receives the message, it processes it. Actor B might have logic to handle the incoming transfer by updating its internal state. After processing the message from Actor A, Actor B decides to add the 100 VARA tokens to its existing balance.
— State Update: Actor B updates its internal state, changing its balance from 50 VARA tokens to 150 VARA tokens.
— Reply: Actor B might then send a reply back to Actor A, acknowledging the receipt of the tokens and confirming that its balance has been updated.
So in this scenario, the local decision-making process of Actor B allowed it to independently decide how to handle the incoming transfer and update its state accordingly. Actor A had no direct influence over the internal state of Actor B, thus it could only send a message requesting the transfer. Actor B processed the message according to its own rules (programming logic) and updated its state based on the content of that message. And that’s the entry interaction between actors.
Gear Protocol’s Solution to Message Ordering and Delivery
One of the properties that embody the Actor Model, as mentioned earlier, is the “Best-Effort Delivery”, and in a nutshell, it means that this model doesn’t guarantee message delivery. This is because, inherently the model doesn’t ensure that every message will reach its intended recipient, and this is a trade-off made for the sake of simplicity and performance. Because of the potential loss of messages, the Gear Protocol introduces a robust solution for managing message ordering and delivery, which is a critical aspect of this concurrent computational model. But before that, let’s explore Gear Protocol’s message-processing architecture.
In the Gear Protocol programs and users are also referred to as actors.
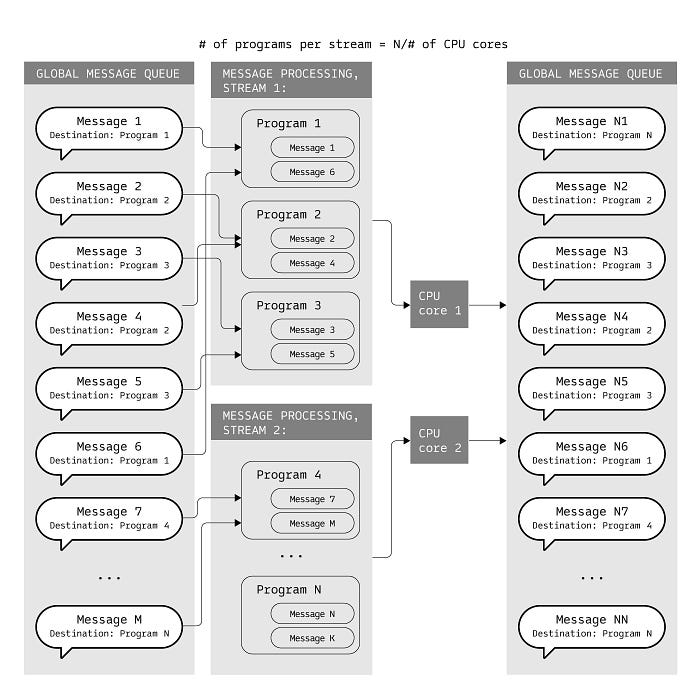
Source: Vara Network (wiki)
The diagram illustrates how a message-processing system works in Gear Protocol, particularly in a concurrent or parallel computing environment, taking into account the relationship between the global message queues, processing streams, programs, and CPU cores. Here’s what each section does:
Global Message Queue: As you can see, this is a centralized queue where all messages destined for various programs are stored together, where each message in the queue has a specific destination, on which a particular program (actor) will process it. Now, the diagram shows two global message queues, but it isn't two, it's one where the other one is
T + 1.Message Processing Streams: The messages from the global queue are distributed to different message processing streams, where each stream is also responsible for processing a subset of the program. In the diagram, two streams are shown, which implies that there are only two CPU cores in this example are utilized. In Gear Protocol, the number of parallel processing streams equals the number of CPU cores.
Programs (actors): So the two streams in the diagram consist of several programs, and these programs are the actual entities that process and execute the necessary logic or operations based on the content of the message.
CPU Cores: As seen in the diagram, the CPU cores are utilized by different processing streams, where each of the two streams is assigned to a specific CPU core, allowing parallel processing of messages, and also this step ensures that the processing workload is distributed across multiple cores, improving the systems overall performance.
Continuous Cycle: After the messages are processed by the program (actor), a reply (response) is generated. For example, if Program 1 processes a message, it might generate a new message to be sent to Program 2 or Program 3. These new messages are then added back to the Global Message Queue, ensuring they are up for subsequent processing by another appropriate program or actor. In the Gear system, this shows a continuous cycle where messages are continuously de-queued from the Global Message Queue, processed by the program (actor) within a stream, and, if any result (message) is generated, re-queued for further processing. This cycle continues as long as there are messages to be processed.
While the Actor Model allows for best-effort delivery, the Gear Protocol enhances this by ensuring that messages are handled robustly through its message processing cycle. Here’s a summary of how Gear deals with message ordering and delivery:
— Parallel Processing Streams: By distributing messages across multiple processing streams, the Gear Protocol ensures that the workload is handled efficiently. This parallelism not only improves the system’s throughput but also reduces the likelihood of message bottlenecks that could lead to loss or delays in delivery.— Re-queuing Mechanism: After a message is processed, if the result generates new messages (for instance, a response or a follow-up task), these messages are added back to the Global Message Queue. This ensures that the system continuously cycles through messages, re-processing them if necessary, and prevents loss by ensuring that messages are always queued until they are fully processed.
— CPU Core Utilization: The assignment of processing streams to specific CPU cores ensures that the system can process multiple messages simultaneously. This reduces the likelihood of messages getting “stuck” in the queue due to a processing bottleneck, thereby improving the reliability of message delivery.
— Message Ordering: The Global Message Queue preserves the order of messages as they are initially queued. Even though the processing happens in parallel across multiple streams, the order within each stream is maintained, ensuring that messages are processed in the order they are received for each specific program (actor).
So in a nutshell, Gear’s message-processing architecture effectively addresses the limitations of best-effort delivery by incorporating the point discussed, to ensure this architecture remains robust.
Gear Protocol & Vara Network
At this point, you heard me mention these two amazing technologies which have created a completely different rhyme in the blockchain industry. Both technologies based on the Actor Model focusing on parallel processing and message handling, provide a robust framework for developing reliable, scalable, and efficient decentralized applications, that can handle the complex demands of modern development.
However, Vara, which is built on top of the Gear Protocol utilizes this actor model into their system by default and has improved this Actor Model with their BIA.
What is Vara Network
Vara is a stand-alone layer-1 decentralized network built and running on top of Gear Protocol.
What is Gear Protocol
Gear is a simple yet powerful framework for writing programs based on the Actor model, automation through deferred messages, gasless and signless transactions, built-in actors to extend program capabilities, and more.
Since I’ve provided a brief introduction to these technologies, and also explored the Actor Model, it is time to explore what a BIA is.
Built-in Actors (BIAs)
In my words of understanding, Built-In Actors (BIAs) are custom-designed tools embedded within the Gear Protocol’s runtime. Which act as special bridges, allowing smart contracts(also known as “programs (actors)” in this context) to tap into the blockchain’s core features. Normally, these core features can only be accessed by users through direct interactions called extrinsics. BIAs break down this barrier, giving programs the ability to indirectly use these powerful blockchain capabilities that were previously out of their reach. In essence, BIAs are like translators that help programs communicate with and utilize the blockchain’s fundamental functions, expanding what these programs can do within the Gear and Vara ecosystems.
What is a Pallet?
A pallet is a modular piece of code that provides specific functionality to the blockchain. Think of it as a “building block” that can be added to the blockchain’s runtime to give it certain features.
Here’s more on pallets in detail:
Core Functionality: Pallets are responsible for implementing core features within Vara, such as staking, governance, or any other. Each pallet operates as a self-contained module within the Vara’s runtime.
Integration with BIAs: While pallets handle the heavy lifting by managing core blockchain functions, BIAs provide an interface for smart contracts (as stated in Vara’s first BIA called BLS12–381) to access these functions indirectly. For instance, a pallet might handle the logic for staking, while a BIA enables a smart contract to initiate a staking process or retrieve staking information without directly interacting with the pallet.
Low-Level Access: Pallets can outsource complex computations to the node and receive the results back, allowing them to perform operations efficiently at the protocol level. This capability makes them suitable for handling tasks that would be too costly or slow if executed directly by smart contracts
For more information, you can check the link above to see other pallets created by the Gear teams. So let’s now focus on the example below to virtually know how it works.
Advantages Of the Actor Model
Now that we have explored Concurrency, Parallelism, and BIA with the Actor Model, let’s explore the advantages of the actor model in a distributed system or network like Vara.
Scalability
The Actor Model enables easy horizontal scaling. Since each actor can be assigned to a stream, the system can scale horizontally by adding more actors as needed without significant restructuring.
Concurrency & Parallelism
Actors can process messages concurrently, meaning that multiple transactions or program executions can occur simultaneously. This greatly improves the overall throughput of the network.
Isolation and Component-Based Design
In both Gear and Vara, programs function like microservices, operating as independent, self-contained units. This component-based architecture allows developers to update or replace specific parts of a decentralized application without disrupting the entire system. This modularity enhances flexibility and simplifies maintenance.
Optimized Resource Utilization
Actors can be designed to manage resources efficiently. For example, the BLS12-381 BIA in Vara’s runtime demonstrates how complex cryptographic operations can be offloaded to specialized components. This approach optimizes performance without overburdening the main blockchain processes.
Conclusion
In summary, we have explored the Actor Model in general and concerning Gear Protocol and Vara Network which offers a powerful and flexible approach to handling concurrency and parallelism. Its ability to isolate state and manage communication through message passing reduces the challenges associated with shared memory models, making it an attractive option for building scalable and resilient applications. As we look to the future, imagine where this model is coupled with AI. This combination has the potential to create an extremely powerful, scalable, and intelligent system. But this possibility isn’t far-fetched, because Vara Network plans to integrate Artificial Intelligence into its system by the end of this year.
Final Thought
While this article covered important details of the Actor Model, I will be writing another piece comparing the Actor Model with other computational models like the shared memory concurrency, and Message Passing Interface (MPI) by focusing on their key differences, advantages, and trade-offs, and also actor hierarchies, supervisor tree, and more.
Also, if you’re a developer, that’s interested in building and deploying decentralized applications on the Vara Network, then check out this comprehensive guide I wrote on FreeCodeCamp.
Subscribe to my newsletter
Read articles from Rocky Essel directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Rocky Essel
Rocky Essel
👩🏾💻