Customer Segmentation in Retail Using Vector Search (Qdrant)
 Flora Oladipupo
Flora Oladipupo
INTRODUCTION
Overview of Customer Segmentation in Retail
Customer segmentation in retail is a strategic approach businesses use to divide their customer base into distinct groups based on specific characteristics, behaviors, and needs. Customer segmentation aims to better understand and target each segment with tailored marketing efforts, products, and services that meet their unique preferences and drive customer satisfaction and loyalty. Customers can be segmented based on demographics, geography, behavior, and RFM (recency, frequency, monetary) factors.
Introduction to Vector Search and Qdrant
Vector search is an advanced technique in information retrieval and machine learning that enables the search and retrieval of data based on semantic similarity rather than traditional keyword matching. This approach has become increasingly important when building AI systems that use unstructured or high-dimensional data, particularly in applications involving natural language processing (NLP), image recognition, and recommendation systems.
Qdrant is an open-source, vector search engine designed to handle and search through high-dimensional vectors efficiently. It provides a scalable and high-performance solution for implementing vector search in various applications, making it an essential tool for developers and data scientists working with large datasets and complex queries.
Advantages of Vector Search for Customer Segmentation Over Traditional Methods
Customer segmentation is crucial in marketing, enabling businesses to customize their offerings and communications for specific customer groups. Traditionally based on categorical data like demographics and purchase history, vector search provides a more advanced and nuanced approach, offering key advantages over traditional segmentation methods.
1. Enhanced Understanding of Customer Behavior: Vector search enables enhanced understanding of customer behavior by creating segments based on actual behaviors and preferences, such as purchasing outdoor gear or booking luxury vacations, rather than broad categories like age or income. This approach captures subtle patterns in data that traditional methods often miss, leading to a more accurate understanding of customer desires.
2. Personalization at Scale: Vector search allows for fine-grained targeting by identifying micro-segments within larger groups, enabling businesses to create highly personalized marketing campaigns. For example, instead of targeting broad groups like "tech enthusiasts," vector search can pinpoint specific interests, such as "those interested in the latest wearable technology," leading to more effective engagement and higher conversion rates.
3. Integration of Unstructured Data: Vector search enhances customer segmentation by integrating unstructured data, such as customer reviews, social media interactions, and browsing history, alongside structured data. This approach provides a holistic view of customers, allowing businesses to detect sentiment and intent, enabling more empathetic and responsive segmentation. For instance, it can identify dissatisfied customers and target them with specific retention efforts.
4. Improved Predictive Capabilities: Vector search improves predictive capabilities by uncovering hidden patterns in customer behavior, allowing businesses to anticipate future actions, such as identifying customers likely to churn or predicting which segments will respond best to new products.
5. Scalability and Flexibility: Vector search offers scalability and flexibility, efficiently handling large and complex datasets while maintaining accuracy, making it ideal for businesses with extensive customer bases. Unlike traditional methods, vector search adapts to various types of data and industries, making it a versatile tool for customer segmentation across diverse domains like retail, finance, and healthcare.
6. Higher Accuracy and Relevance: Vector search enhances accuracy and relevance in customer segmentation by reducing bias associated with traditional methods, focusing on actual behaviors and preferences rather than demographic attributes, resulting in more objective and meaningful segments.
Why Qdrant Is Suitable for Customer Segmentation
Qdrant is an advanced vector search engine designed to handle high-dimensional data efficiently, making it particularly well-suited for customer segmentation tasks due to its features like Multi-Vector Search and Payload-Based Reranking. These features provide significant advantages in how businesses can segment their customers more effectively and accurately. Here’s how these capabilities make Qdrant an ideal choice for customer segmentation:
Multi-Vector Search for Enhanced Segmentation: Qdrant’s Multi-Vector Search enhances customer segmentation by capturing multiple aspects of customer behavior and preferences, enabling businesses to create more precise and personalized segments based on various criteria simultaneously.
Payload-Based Reranking for Precision Targeting: Qdrant’s Payload-Based Reranking refines customer segmentation by incorporating metadata, enabling dynamic, contextual, and customizable targeting strategies that align segments with specific business goals.
Advantages for Customer Segmentation: Qdrant’s Multi-Vector Search and Payload-Based Reranking create accurate, personalized customer segments, allowing businesses to scale personalization, improve targeting, and adapt segments in real-time as customer data evolves.
Seamless Integration and Scalability: Qdrant offers easy integration with existing systems and scalable performance, making it suitable for businesses of all sizes to handle large-scale customer segmentation efficiently.
Qdrant enhances customer segmentation by combining Multi-Vector Search and Payload-Based Reranking to create accurate, personalized segments that adapt in real-time. By enabling the creation of complex, multi-dimensional customer profiles and allowing for dynamic reranking based on specific business criteria, Qdrant helps businesses achieve more precise, personalized, and effective customer segmentation.
Implementing Vector Search in Qdrant
Implementing vector search in Qdrant involves several key steps that enable efficient and scalable semantic search capabilities. Here's a summary:
Data Preparation: Convert your data items (e.g., text, images) into high-dimensional vectors using embeddings generated by models like BERT, Word2Vec, or CLIP. These vectors represent the semantic meaning of your data.
Indexing: Ingest the generated vectors into Qdrant. Qdrant creates indexes that optimize the search process, ensuring that queries are handled quickly and accurately, even with large datasets.
Querying: When a search query is issued, it is also transformed into a vector. Qdrant compares this query vector against the stored vectors using distance metrics (e.g., cosine similarity) to retrieve the most semantically similar items.
Payload Filtering: Qdrant supports advanced filtering options that allow you to refine search results based on additional metadata (payloads). This can include tags, categories, or other relevant attributes.
Scalability: Qdrant is designed to scale horizontally, making it capable of handling large volumes of data and high search traffic by distributing the workload across multiple nodes.
Integration: Qdrant offers a user-friendly API that supports various programming languages, making it easy to integrate vector search functionality into your applications.
Follow this link to read an article that shows Qdrant implementation. By following these steps, developers can leverage Qdrant to implement robust vector search solutions, enabling more accurate and context-aware search experiences across various use cases, from recommendation systems to natural language processing and beyond.
Segmentation Techniques Using Vector Search
Segmentation techniques are methods used to divide a larger dataset or population into smaller, more meaningful groups, known as segments. In customer segmentation using vector search, these techniques often combine clustering methods with vector-based representations of customer data.
Similarity-Based Segmentation
Similarity-based segmentation uses vector embeddings to group customers based on behavioral similarities, rather than traditional categorical data, with vector search engines like Qdrant efficiently identifying clusters of similar customers in a multi-dimensional space.
Clustering Algorithms in Vector Space
Clustering algorithms like k-means, DBSCAN, or hierarchical clustering can be applied to vector representations of customer data to identify distinct segments, revealing complex groupings that traditional methods may overlook.
Dynamic Segmentation Based on Real-Time Data
Vector search supports dynamic segmentation, allowing customer segments to be continuously updated with real-time data. This enables instant adjustments to segments as customer preferences and behaviors change, making it ideal for rapidly evolving industries.
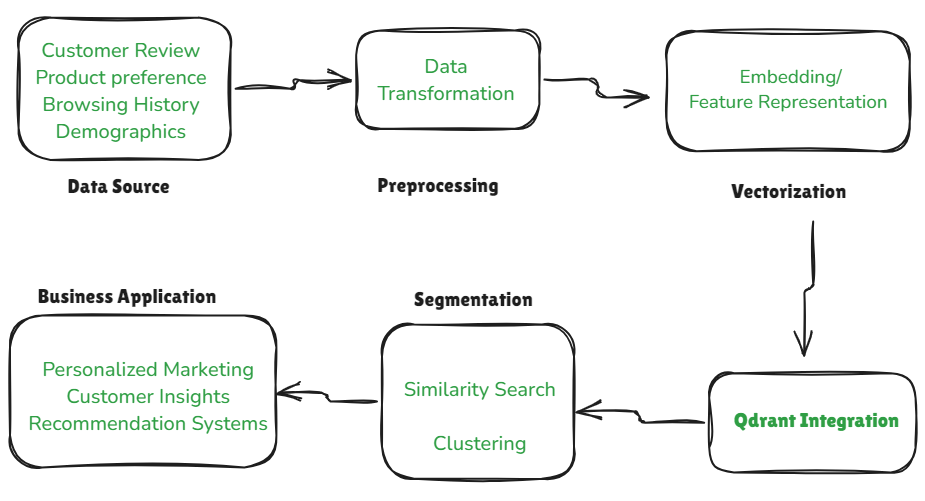
Figure 1: Flowchart to explain Customer Segmentation in Qdrant. Credit: Author.
Implementing Customer Segmentation with Qdrant
Let’s take an example of an e-commerce company that is looking to enhance its marketing strategies by implementing a more dynamic and precise customer segmentation approach that captures customer behavior's complex and evolving nature. To address this, the company decides to explore vector-based segmentation using Qdrant, to understand better and engage their customers.
Implementation Steps
Data Collection and Preparation: Data relating to the organization's retail chain is collected from various sources, including customer purchase history, browsing behavior, and product reviews. Data from 100 distinct customers have been used in this case study. The data is pre-processed to generate feature-rich vectors representing each customer’s behavior. Following these steps:
Categorical Data Encoding: Encoding the categorical features in the dataset such as customer gender, session page customer viewed, etc.
Normalization: Normalizing numeric features like purchase amounts, session durations, age, etc.
Text Embedding: Converting textual data including product reviews into embeddings using the BERT transformers model.
This preprocessing stage has been carried out on Google Colab.
#import libraries needed
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler, LabelEncoder, OneHotEncoder
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import PCA
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
# Load datasets
customers = pd.read_csv("path_to_data.csv")
purchases = pd.read_csv("path_to_data.csv")
sessions = pd.read_csv("path_to_data.csv")
reviews = pd.read_csv("path_to_data.csv")
Here are samples of what the csv files contain in a dataframe form.
The loaded data has been copied to retain the original form of the data after undergoing normalization.
customer_org = customers.copy()
sessions_org = sessions.copy()
purchases_org = purchases.copy()
reviews_org = reviews.copy()
Normalizing the categorical and numerical data:
from sklearn.preprocessing import LabelEncoder, MinMaxScaler
# Initialize encoders and scalers
label_encoder = LabelEncoder()
scaler = MinMaxScaler()
# Encode categorical features
customers['gender'] = label_encoder.fit_transform(customers['gender'])
sessions['page_viewed'] = label_encoder.fit_transform(sessions['page_viewed'])
# Normalize numeric features
customers[['age']] = scaler.fit_transform(customers[['age']])
sessions[['view_duration']] = scaler.fit_transform(sessions[['view_duration']])
purchases[['purchase_amount']] = scaler.fit_transform(purchases[['purchase_amount']])
The text data in the review dataset has been transformed into text embeddings using the SentenceTransformer model due to its efficiency in maintaining contextual integrity.
import pandas as pd
from sentence_transformers import SentenceTransformer
# Load your CSV file
file_path = 'path_to_data.csv' # Update this path with the correct file path
reviews_df = pd.read_csv(file_path)
# Extract the review texts
review_texts = reviews_df['review_text'].tolist()
# Initialize the SentenceTransformer model
model = SentenceTransformer('all-MiniLM-L6-v2')
# Convert the review texts to embeddings
embeddings = model.encode(review_texts)
# Add the embeddings to the DataFrame
reviews_df['review_embedding'] = embeddings.tolist()
Vectorization: After preprocessing, vector embeddings are generated for each customer by combining features from different datasets. To optimize storage and computation, dimensionality reduction techniques like PCA (Principal Component Analysis) have been applied to reduce the size of the vectors while retaining the most significant behavioral features.
The text embeddings have string representations which are converted into actual numpy arrays by stripping the square brackets and splitting the string by commas.
from sklearn.decomposition import PCA
import numpy as np
# Convert the review embeddings from string to numpy array
reviews_df['review_embedding'] = reviews_df['review_embedding'].apply(
lambda x: np.fromstring(x.strip("[]"), sep=','))
Most customers have different reviews about the products, so these review embeddings are aggregated for each customer by calculating the mean embedding across all reviews they have written.
# Aggregate the review embeddings for each customer by taking the mean of their embeddings
customer_embeddings = reviews_df.groupby('customer_id')['review_embedding'].apply(np.mean).reset_index()
The sessions which are based on numerical values in the data including the “view_duration” and the purchase_amount spent by the customer are aggregated for the different products and also aggregated for each customer.
numeric_sessions_df = sessions.select_dtypes(include=[np.number])
sessions_agg_df = sessions[['customer_id']].join(numeric_sessions_df).groupby('customer_id').mean().reset_index()
numeric_purchases_df = purchases.select_dtypes(include=[np.number])
purchases_agg_df = purchases[['customer_id']].join(numeric_purchases_df).groupby('customer_id').mean().reset_index()
All these separate data are combined on customer_id to bring together the different dataframes into one comprehensive data frame, merged_df. These contain all the relevant customer-related features (demographics, review embeddings, session data, purchase data) combined into a single dataframe.
# Merge customer embeddings with other customer features
merged_df = customers.merge(customer_embeddings, on='customer_id', how='left')
merged_df = merged_df.merge(sessions_agg_df, on='customer_id', how='left')
merged_df = merged_df.merge(purchases_agg_df, on='customer_id', how='left')
# Fill any missing values that resulted from the merge
merged_df = merged_df.fillna(0)
# Convert the combined_vector and review_embedding back to string format
merged_df['combined_vector'] = merged_df['combined_vector'].apply(lambda x: str(list(x)))
merged_df['review_embedding'] = merged_df['review_embedding'].apply(lambda x: str(list(x)))
# Display the first few rows after combining vectors
print(merged_df.head())
All these features from multiple sources (reviews, sessions, purchases) are combined into a single vector.
# Combine all features into a single vector for each customer
feature_columns = ['age', 'gender', 'view_duration', 'purchase_amount', 'review_embedding']
merged_df['combined_vector'] = merged_df.apply(
lambda row: np.concatenate([row['review_embedding'], [row['age'], row['gender'], row['view_duration'], row['purchase_amount']]]),
axis=1)
The vectors in numpy arrays are converted back into string format.
merged_df['combined_vector'] = merged_df['combined_vector'].apply(lambda x: str(list(x)))
merged_df['review_embedding'] = merged_df['review_embedding'].apply(lambda x: str(list(x)))
Principal Component Analysis (PCA) has been applied to the data to reduce the dimensionality of the combined vectors. PCA reduces the dimensionality of each combined vector to 5 components.
pca = PCA(n_components=5) # Set n_components to a feasible value, in this case 5
reduced_vectors = pca.fit_transform(np.stack(merged_df['combined_vector'].apply(eval)))
The reduced vectors are converted from a numpy array to a list format using tolist() and assigned to a new column called reduced_vector in the merged_df dataframe. Each reduced vector, which is a list of 5 values, is then converted to a string format using str(x). This makes it easier to store or export the vectors as JSON-like strings in Qdrant.
merged_df['reduced_vector'] = reduced_vectors.tolist()
merged_df['reduced_vector'] = merged_df['reduced_vector'].apply(lambda x: str(x))
The dataframe will be saved to a csv format for use in Segmentation in Qdrant. The merged_df dataframe will be saved to be used for clustering analysis.
# saving the dataframe to a csv file as the normalized data for clustering
merged_df.to_csv("path_to_save_clustered_dataframe.csv
", index=False)
Customer information like gender and age will be retained for the similarity search. So it will be merged with the normalized dataframe.
# merging the original customer information with the new features for the customer similarity search
df = customer_org.merge(merged_df[['customer_id', 'page_viewed', 'view_duration', 'purchase_amount', 'review_embedding', 'combined_vector', 'reduced_vector', 'review_embedding']], on='customer_id', how='left')
df.to_csv("path_to_save_clustered_dataframe.csv", index=False)
Vector Search Implementation with Qdrant
Qdrant Setup: Set up Qdrant by running the command docker run -p 6333:6333 qdrant/qdrant. This allows access to the Qdrant server using http://localhost:6333 from the local machine command prompt.
docker run -p 6333:6333 qdrant/qdrant.
http://localhost:6333
Then a connection is initialized to the Qdrant server. These steps are carried out using Visual Studio Code IDE.
from qdrant_client import QdrantClient
# Initialize the Qdrant client
qdrant = QdrantClient(host="localhost", port=6333)
A collection is created called ‘customer_vectors’. A collection in Qdrant is similar to a table in a relational database, where vectors are stored and their metadata. It is configured to store 5-dimensional vectors based on the dimensionality of the vectors, using the cosine distance metric for similarity searches.
from qdrant_client.http.models import PointStruct, VectorParams, Distance
# Define a collection in Qdrant
collection_name = "customer_vectors"
# Check if the collection exists
if qdrant.collection_exists(collection_name):
# Optionally delete the existing collection if you want to recreate it
qdrant.delete_collection(collection_name)
# Create the collection
qdrant.create_collection(
collection_name=collection_name,
vectors_config=VectorParams(size=5, distance=Distance.COSINE),
)
The core of carrying out segmentation involves inserting customer data into the Qdrant collection. This data includes vectors representing customers and additional payload information:
import pandas as pd
import json
data = pd.read_csv("path/to/your/data.csv")
points = []
for index, row in data.iterrows():
vector = json.loads(row['reduced_vector'].replace('\n', ''))
# Verify the vector structure before storing it
if not isinstance(vector, list) or not all(isinstance(i, float) for i in vector):
print(f"Invalid vector format for row {index}: {vector}")
continue # Skip this entry if the vector format is incorrect
point = PointStruct(
id=index,
vector=vector,
payload={
"customer_id": row['customer_id'],
"age": row['age'],
"gender": row['gender'],
"location": row['location'],
"signup_date": row['signup_date'],
"page_viewed": row['page_viewed'],
"view_duration": row['view_duration'],
"purchase_amount": row['purchase_amount']
}
)
points.append(point)
# Insert the points into the collection
client.upsert(
collection_name="customer_vectors",
points=points
)
Similarity-Based Search: Qdrant’s similarity search features were utilized to group customers into segments based on the proximity of their vectors in the multi-dimensional space. Customers with similar vectors were placed into the same segment.
In this example, the first customer in the dataset is used as a query for the similarity search. After finding the top 20 most similar customers, it reranks them based on specific payloads which are engagement (view_duration) and spending (purchase_amount), prioritizing customers who are more engaged and have spent more.
# Use the first customer's vector for the search as an example
query_vector = eval(data.iloc[0]['reduced_vector'])
# Perform the search
search_result = client.search(
collection_name='customer_vectors',
query_vector=query_vector,
limit=20)
# Rerank the results based on 'view_duration' and 'purchase_amount'
reranked_results = sorted(
search_result,
key=lambda x: (x.payload['view_duration'], x.payload['purchase_amount']),
reverse=True # Sort descending by view_duration and purchase_amount)
The result gives an easy review of the customers who are most similar to the vector queried. By displaying key details such as customer ID, similarity score, age, and gender, immediate insights can be gained into who these customers are and how closely they match the criteria defined in the input vector. This information is useful for applications that involve understanding the nuances of customer similarity.
Customer ID: CUST012, Age: 61, Gender: Female, Purchase Amount: 0.502516008, View Duration: 0.670903955, Location: Robinsontown, Similarity Score: 0.96434647
Customer ID: CUST054, Age: 61, Gender: Female, Purchase Amount: 0.375860696, View Duration: 0.569491525, Location: Santosport, Similarity Score: 0.98017526
Customer ID: CUST088, Age: 34, Gender: Female, Purchase Amount: 0.404189654, View Duration: 0.558050847, Location: Rebeccafurt, Similarity Score: 0.9230489
The results indicate that the input vector likely represents a female customer. The search successfully identified other female customers with similar attributes, with varying degrees of similarity. The results suggest that CUST012 is the closest match to the query customer in terms of vector similarity, followed by CUST054 and CUST088. This ranking can be useful for targeting, recommendations, or further analysis based on the identified similarities.
Clustering: In addition to performing similarity-based searches, another valuable approach to segmenting customers is by using clustering algorithms. This method groups customers into clusters based on the similarity of their vector representations, providing deeper insights into customer segmentation. K-means clustering was applied within the vector space to identify distinct customer segments. Qdrant’s fast search capabilities allows the company to quickly group customers even as new data gets ingested.
The results of the customer similarity search were used for clustering to further categorize customers into different segments. The results are stored in a dataframe This step prepares the vector data for clustering by transforming it into a format that the K-Means algorithm can process, which is the numpy array format.
# Create a list of dictionaries with the relevant data
results_data = [
{
"Customer ID": result.payload['customer_id'],
"Age": result.payload['age'],
"Gender": result.payload['gender'],
"Purchase Amount": result.payload['purchase_amount'],
"View Duration": result.payload['view_duration'],
"Location": result.payload['location'],
"Similarity Score": result.score,
"Vector": result.vector
}
for result in reranked_results
]
# Convert the list of dictionaries to a DataFrame
results_df = pd.DataFrame(results_data)
# Display the DataFrame
print(results_df)
The vectors from the reranked results are extracted and used for clustering with K-Means (with 5 clusters). Cluster labels are generated and added to the DataFrame.
from sklearn.cluster import KMeans
# Extract the vectors from the DataFrame
vectors = np.vstack(results_df['Vector'].values)
# Apply K-Means clustering with 5 clusters
n_clusters = 5
kmeans = KMeans(n_clusters=n_clusters, random_state=42)
cluster_labels = kmeans.fit_predict(vectors)
# Add the cluster labels to the DataFrame
results_df['Cluster'] = cluster_labels
The cluster labels are stored back in the Qdrant collection. The code uses the upsert method to update the existing points with the new cluster information while retaining other payload data.
# Store the cluster labels back in Qdrant by using upsert
for index, row in results_df.iterrows():
point_id = index
updated_payload = row.drop(['Vector']).to_dict() # Drop Vector from the payload, keep the rest
updated_payload['cluster'] = row['Cluster']
client.upsert(
collection_name="customer_vectors",
points=[
PointStruct(
id=point_id,
vector=row['Vector'], # Reuse the existing vector
payload=updated_payload
)
]
)
This summary provides valuable insights into the characteristics of each cluster, helping to understand the common traits of customers grouped together by the K-Means algorithm.
Cluster Customer ID Age Purchase Amount View Duration Similarity Score
0 0 5 51.600000 0.454349 0.468791 0.989517
1 1 2 64.000000 0.503758 0.170904 0.928900
2 2 3 61.333333 0.608626 0.553988 0.946075
3 3 7 39.428571 0.411765 0.457335 0.951946
4 4 3 62.333333 0.355350 0.496219 0.980023
This summary is visualized to see the different cluster categories in a chart. Each cluster is plotted with a different color on a 2D plane (using the first two dimensions of the vectors).
plt.figure(figsize=(10, 7))
# Plot each cluster with a different color
for cluster_label in sorted(results_df['Cluster'].unique()):
cluster_data = results_df[results_df['Cluster'] == cluster_label]
plt.scatter(
np.vstack(cluster_data['Vector'].values)[:, 0],
np.vstack(cluster_data['Vector'].values)[:, 1],
label=f"Cluster {cluster_label}",
s=100 # Marker size
)
plt.title("Customer Segments Based on Clustering")
plt.xlabel("Dimension 1")
plt.ylabel("Dimension 2")
plt.legend()
plt.grid(True)
plt.show()
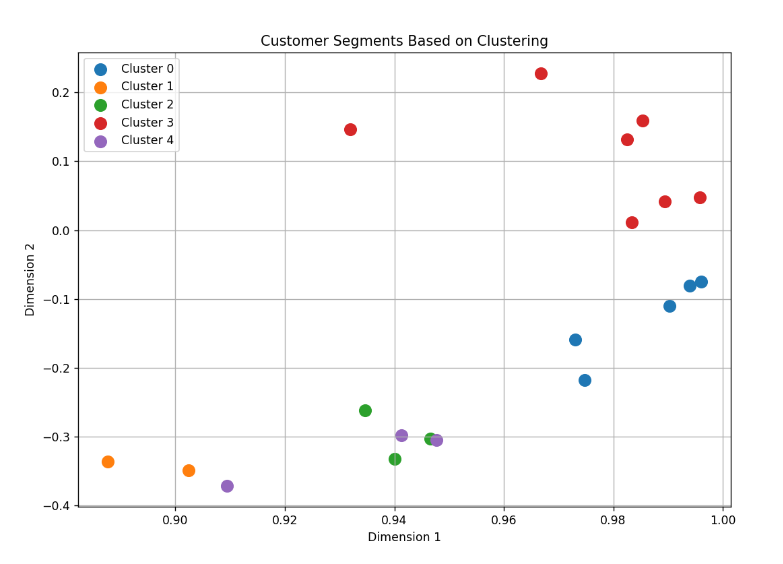
The visualization, combined with the cluster summary, provides a clear view of how different customer segments are distributed. The distinct clusters reflect different customer profiles based on age, purchase behavior, and engagement levels, with varying degrees of similarity to the query vector. Cluster 0 is highly similar to the query vector, as reflected by the highest average similarity score (0.989517). The customers in this cluster are tightly grouped in the plot, suggesting very little variation within the cluster. Clusters 1 and 2 have fewer members and are positioned farther from other clusters, indicating that these customers are outliers with unique characteristics although Cluster 1 has a low engagement level. Cluster 3 has the most customers (7) and shows a diverse yet tightly-knit group with relatively high similarity to the query vector, moderate purchase amounts, and engagement. Cluster 4, like Cluster 2, shows customers with strong similarities but with different purchase behavior. Despite lower purchase amounts, the customers in this cluster are still quite similar to the query vector in other respects. These insights can help in tailoring marketing strategies, targeting specific customer segments, or understanding the diversity within a customer base.
Business Applications of Customer Segmentation Using Qdrant
Customer segmentation is a powerful strategy in business that allows companies to divide their customer base into distinct groups based on various characteristics, behaviors, or preferences. The use of Qdrant, a vector search engine, in customer segmentation enhances this process by enabling businesses to segment customers based on the proximity of their vectors in a multi-dimensional space.
Here are some key business applications of customer segmentation using Qdrant:
Personalized Marketing Campaign: By identifying customers who are similar based on their purchasing behavior, demographics, or interaction patterns, businesses can create highly targeted marketing campaigns.
Product Recommendations: Through segmenting customers based on their similarity scores, businesses can recommend products that other customers in the same segment have purchased.
Customer support and service: Segmentation allows businesses to provide tailored support services to different customer groups.
Revenue optimization: Businesses can use customer segmentation to implement differential pricing strategies.
Customer Experience Enhancement: Segmentation enables businesses to create customized user journeys across digital platforms.
Customer segmentation using Qdrant opens up numerous opportunities for businesses to enhance their operations, from personalized marketing and product recommendations to optimized customer support and revenue strategies. By leveraging advanced vector search capabilities, companies can uncover deep insights into customer behavior, leading to more effective segmentation and, ultimately, greater business success. Identifying and acting on each customer segment's unique needs can empower businesses to deliver more targeted, relevant, and impactful experiences, driving customer loyalty and boosting profitability.
GitHub
This is the link to the GitHub code for this project: https://github.com/shashacode/Qdrant-Customer-Segmentation
References
This project is also documented on my Medium page:
The links to the datasets used:
https://github.com/shashacode/Qdrant-Customer-Segmentation/blob/main/sessions.csv
https://github.com/shashacode/Qdrant-Customer-Segmentation/blob/main/reviews.csv
https://github.com/shashacode/Qdrant-Customer-Segmentation/blob/main/purchases.csv
https://github.com/shashacode/Qdrant-Customer-Segmentation/blob/main/customer_details.csv
https://github.com/shashacode/Qdrant-Customer-Segmentation/blob/main/customers_segment.csv
Subscribe to my newsletter
Read articles from Flora Oladipupo directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Flora Oladipupo
Flora Oladipupo
I am a Data scientist who enjoys working with datasets, solving problems and exploring Artificial Intelligence