What is Gemini ? How to use Vertex AI and Google AI Studio?
 Md Shahriyar Al Mustakim Mitul
Md Shahriyar Al Mustakim MitulWe have 4 versions of Gemini now
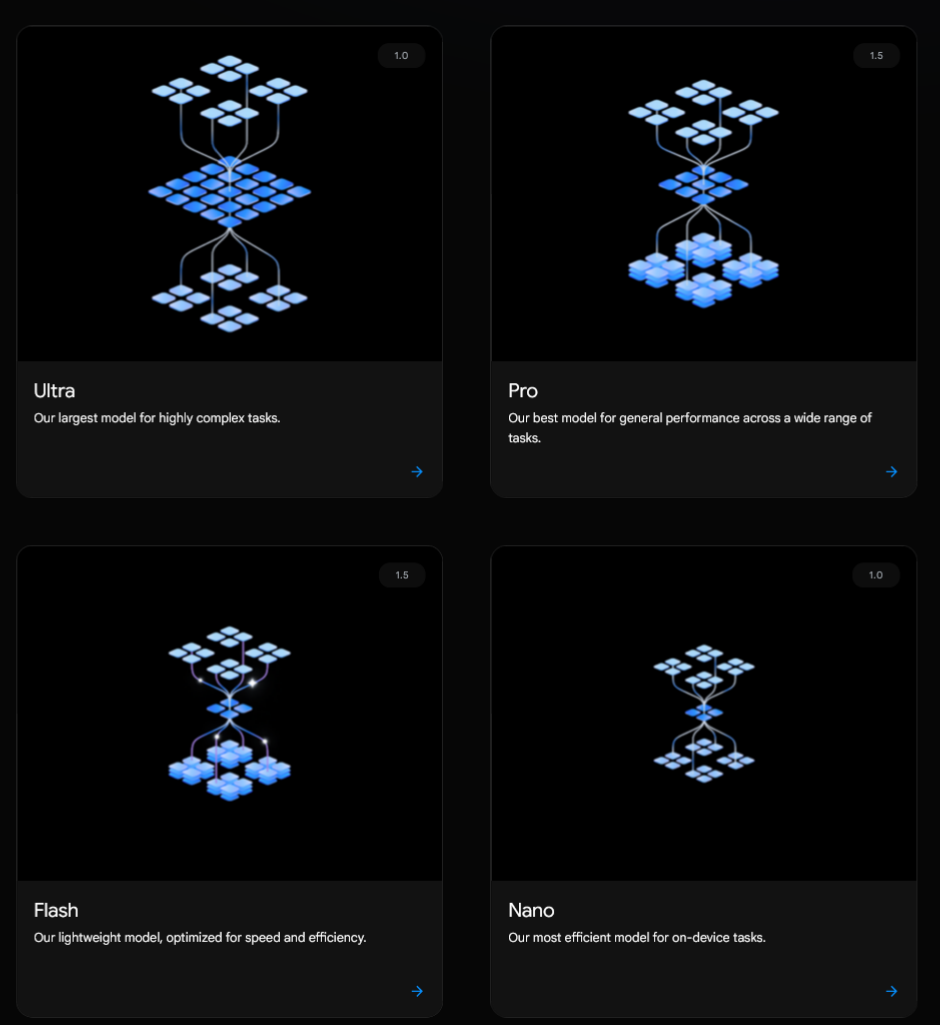
Some information about them:

Prompt engineering
A good prompt (question you want Gemini to answer) should have these three

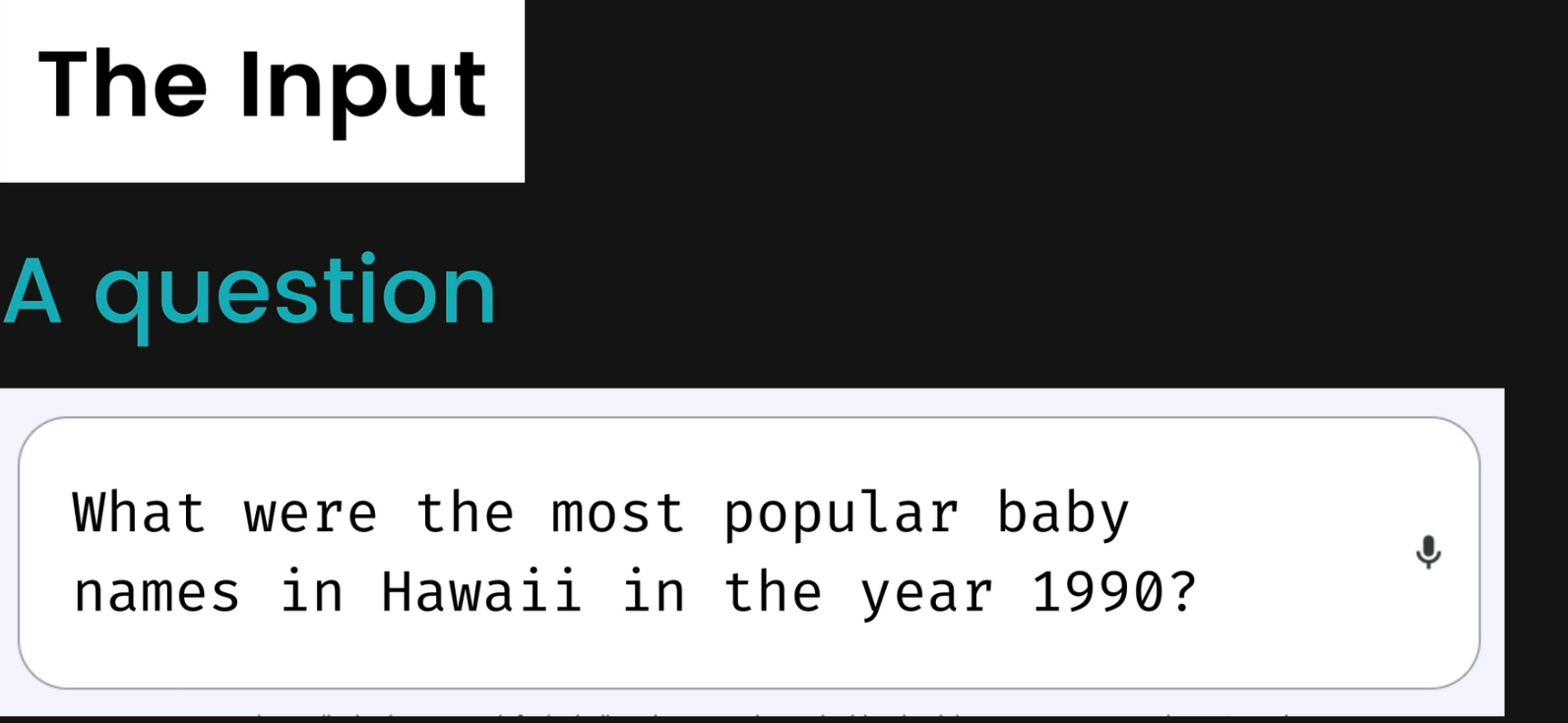
Initially we can give inputs like these
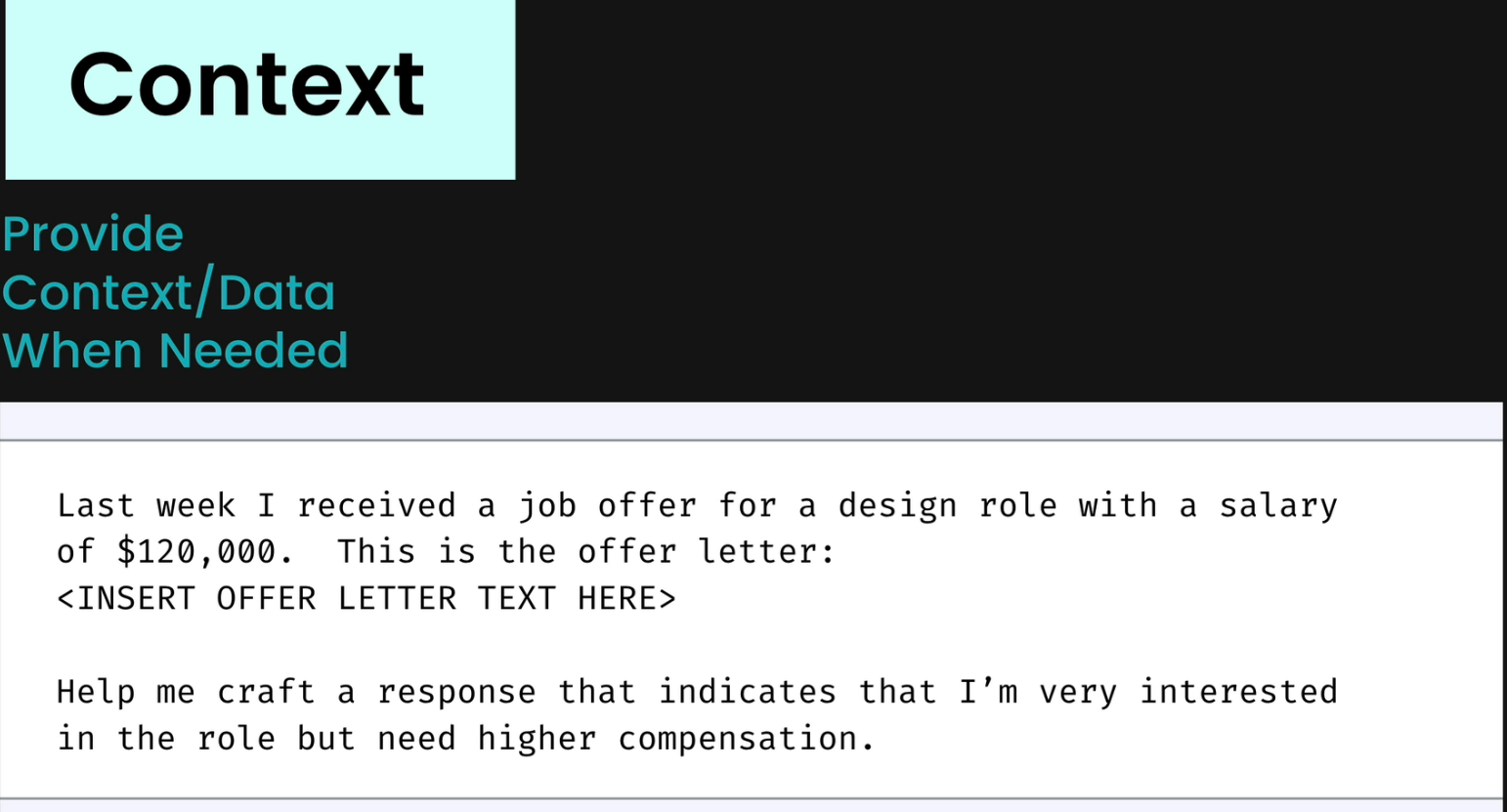
But some questions might need additional data . Without that, gemini might give you wrong output
And sometimes, rather than a simple question , you may need to give the model some output , so that it can learn from that. For example,
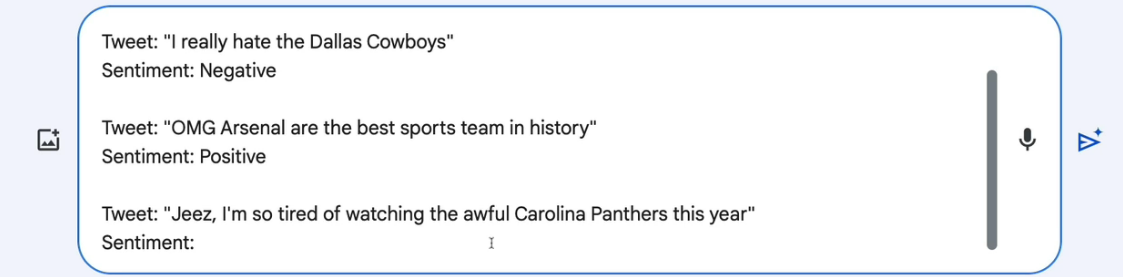
here 2 tweet and their sentiments have been given and we asked for the sentiment for the 3rd tweet
So, this was the output we got!
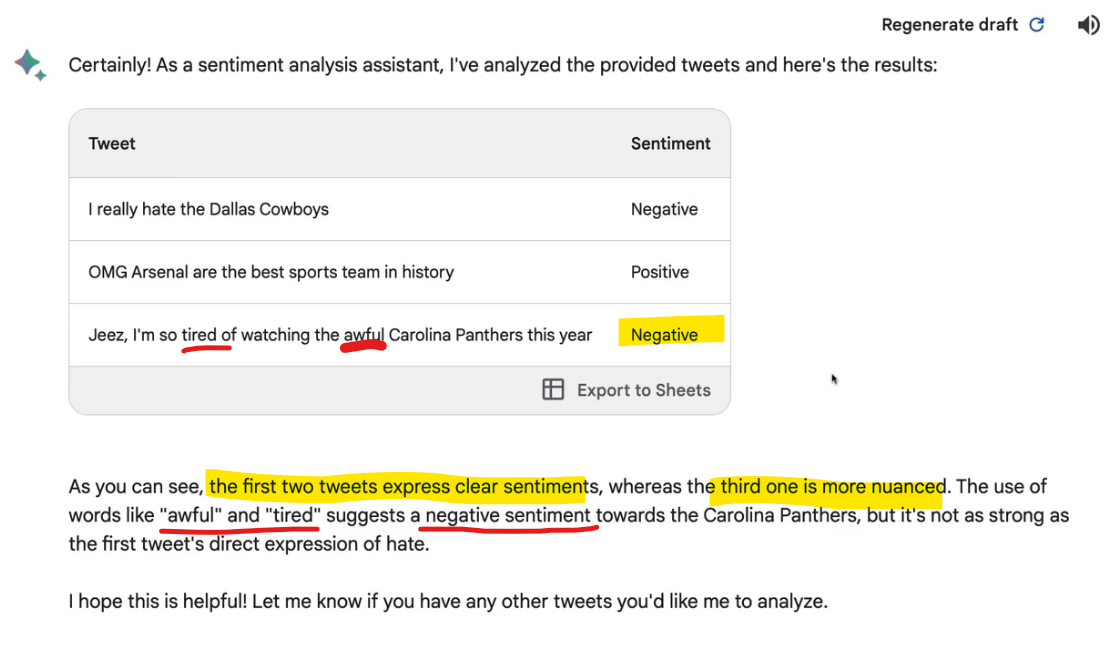
You can see , how Gemini learned from our inputs.
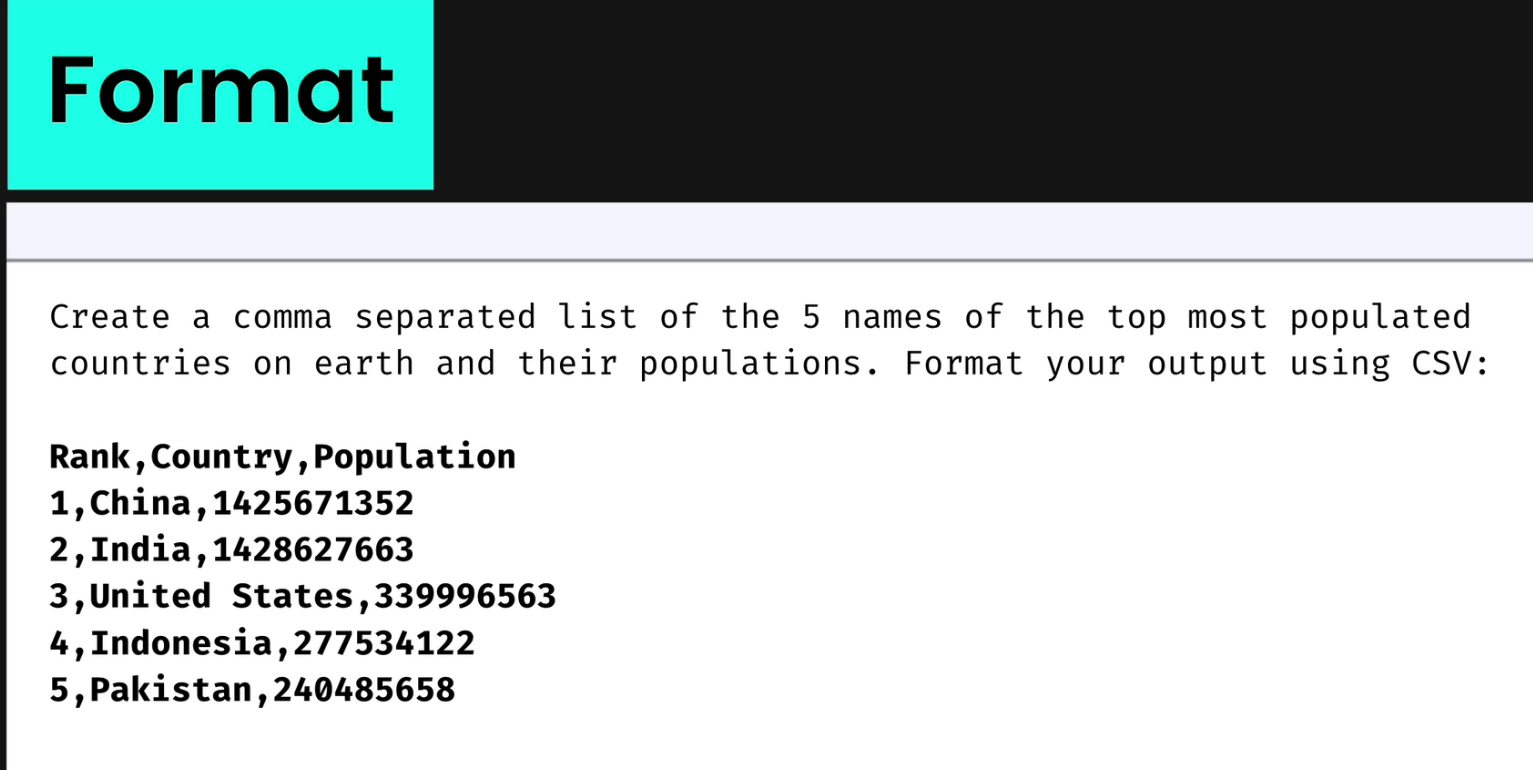
You also need to specify the output format
Google AI Studio vs Vertex AI

Google AI Studio
To sign up, you just need a Google account.
You don't need a Google Cloud account, you don't need a credit card attached. And now we have basically unlimited requests that we can make to Gemini Pro and Gemini Pro Vision. It's rate limited, of course, but there's not a quota where it's like you get, you know, $10 or $100 of credits. You can do as many as you want as long as you're within that rate quota.
For example, now let's ask it some questions
"How far are we from the moon?"

We got this!
Now, let's look into settings
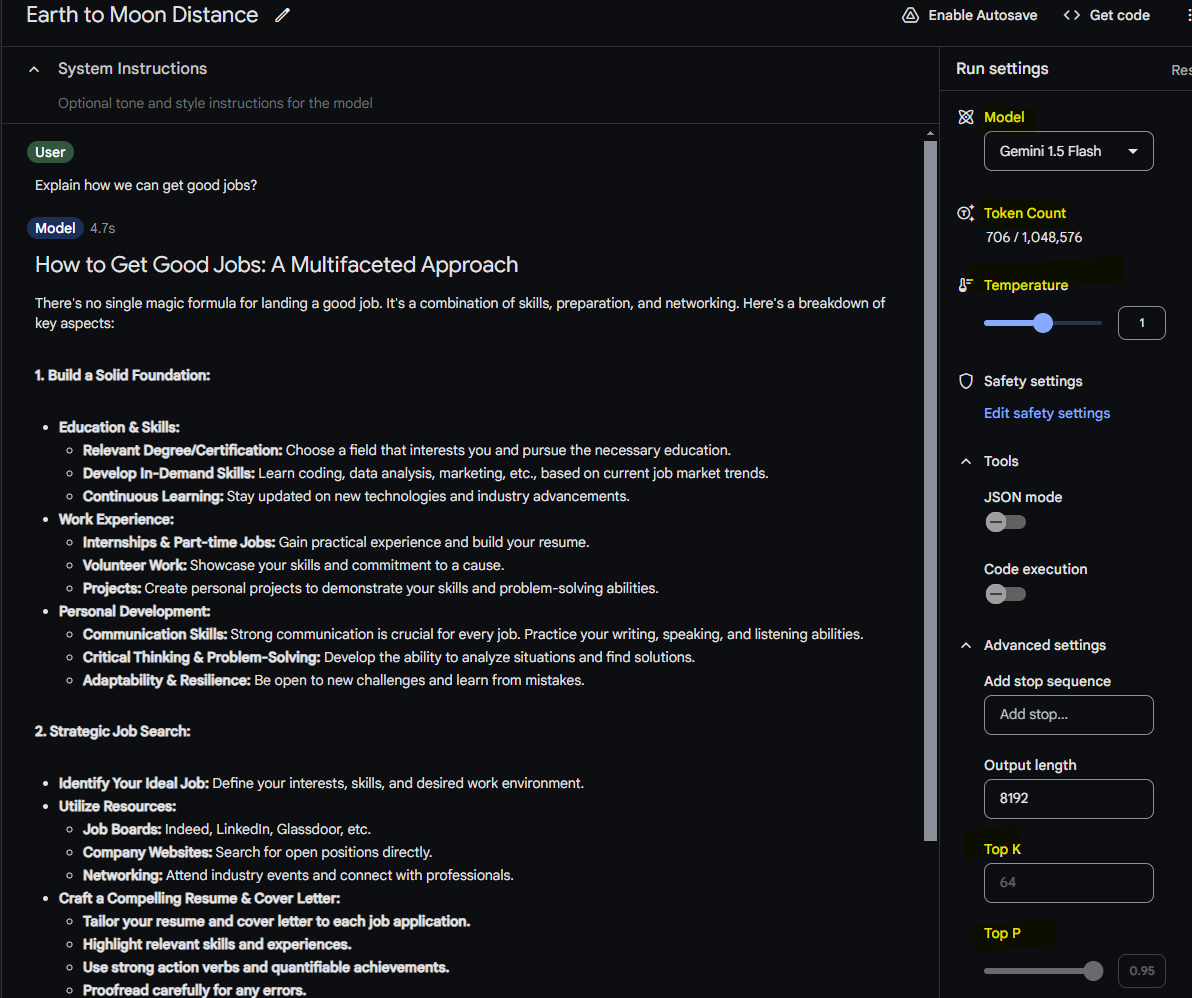
We have Model drop down menu, token count, temperature, Top K, Top P
What about the model selection?
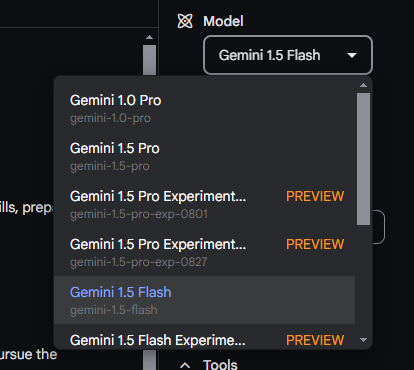
We have a lot's of options here and you can see which are in preview modes as well.
Gemini Pro has these features for us (When using AI Studio)

What about those tokens?
Tokens are basically bunch of words. Or you may say a token is a fundamental unit of data that is processed by algorithms, especially in natural language processing (NLP) and machine learning services.
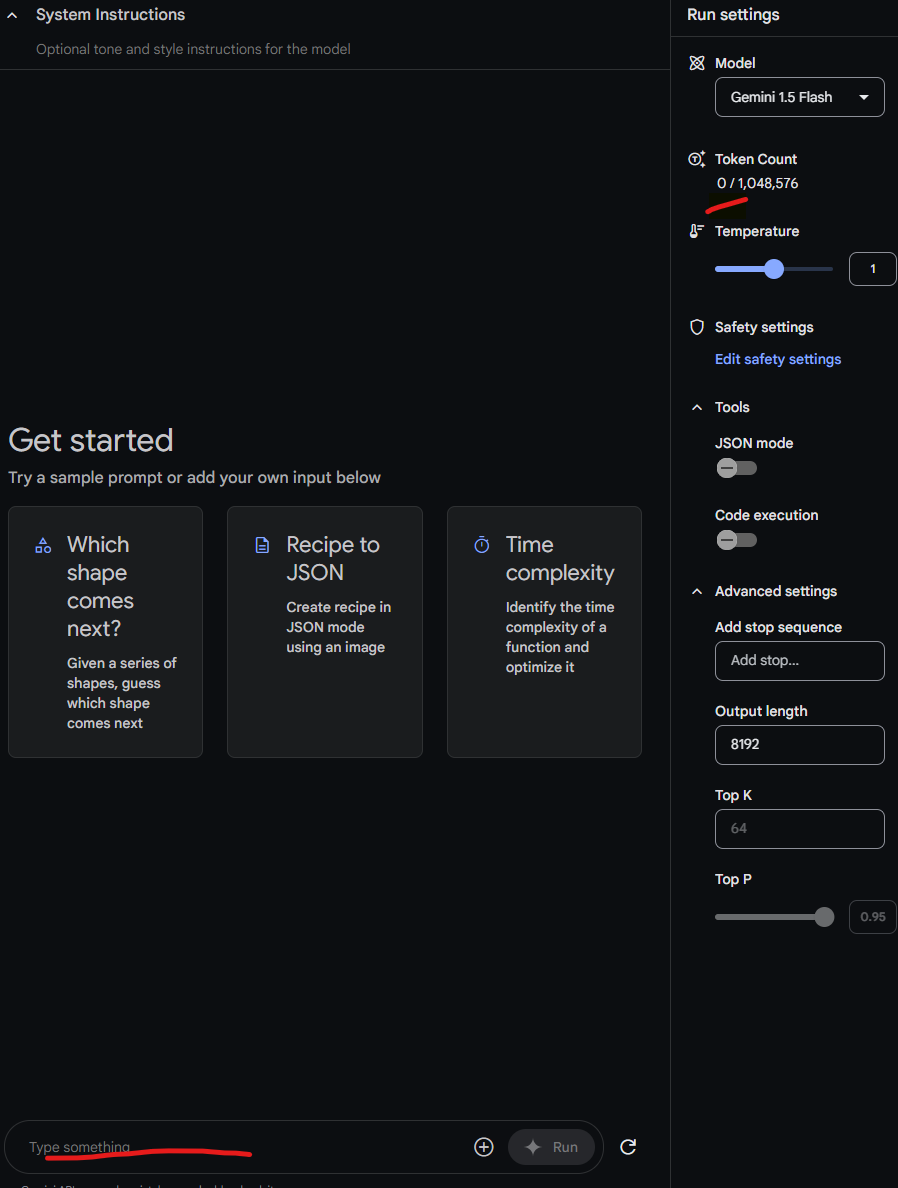
When we have no text in the AI Studio, we can see 0 tokens here.
You can also see the limit of tokens 1,048,576 for Gemini 1.5 Flash model
That changes to 2,097,152 when we choose Gemini 1.5 Pro
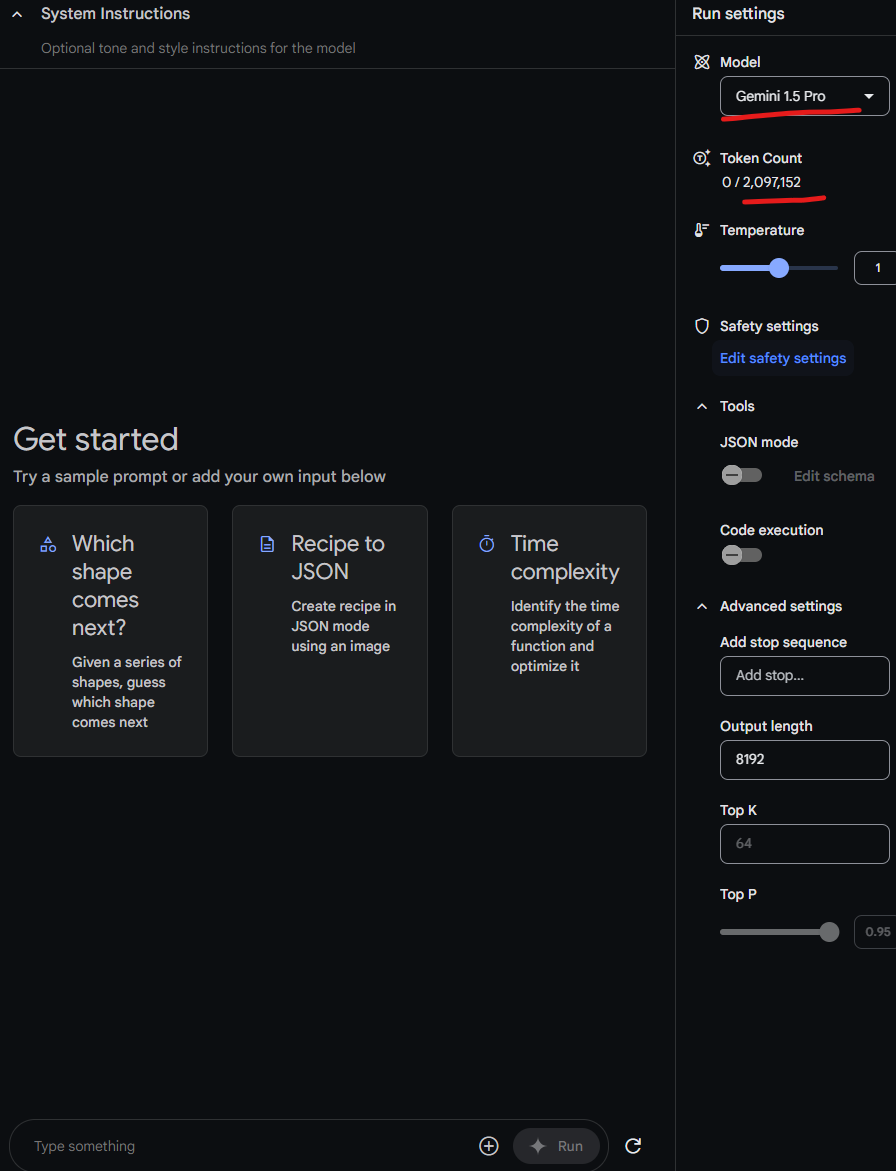
So, this is the token limit we have. We can use a model but that's the limit for us.
Now, let's see how that's counted
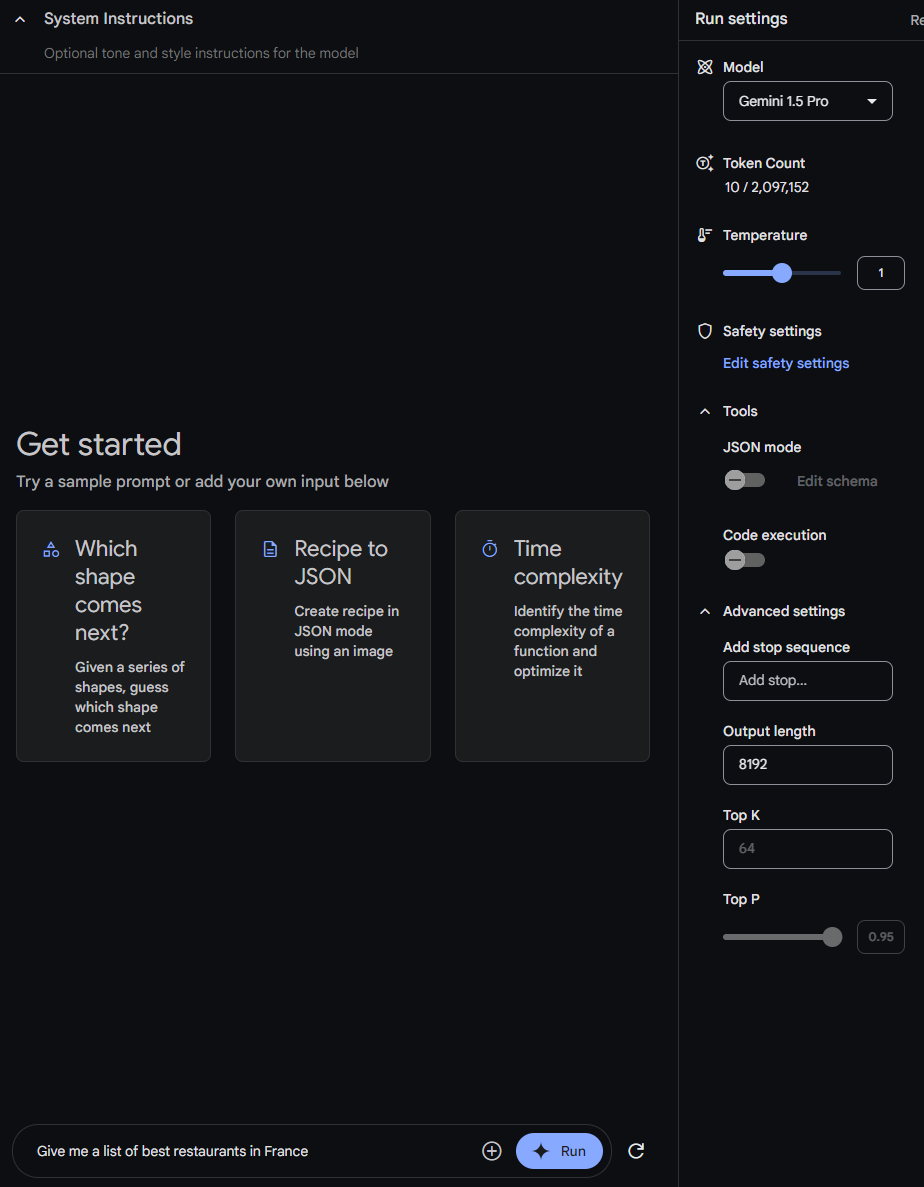
I have written "Give me a list of best restaurants in France" and you can see the AI Studio predicted that, it's 10 tokens.
We can't say exactly how it defined 10 sentences from these 9 words. There are various ways and techniques. But Consider the sentence "Hello, world!" - it might be tokenized into ["Hello", ",", "world", "!"]. ]
These tokens are then used as inputs for the model to learn patterns and relationships between them.
If we want to use images as prompt, this is the limit we need to keep in mind

Here is an example,
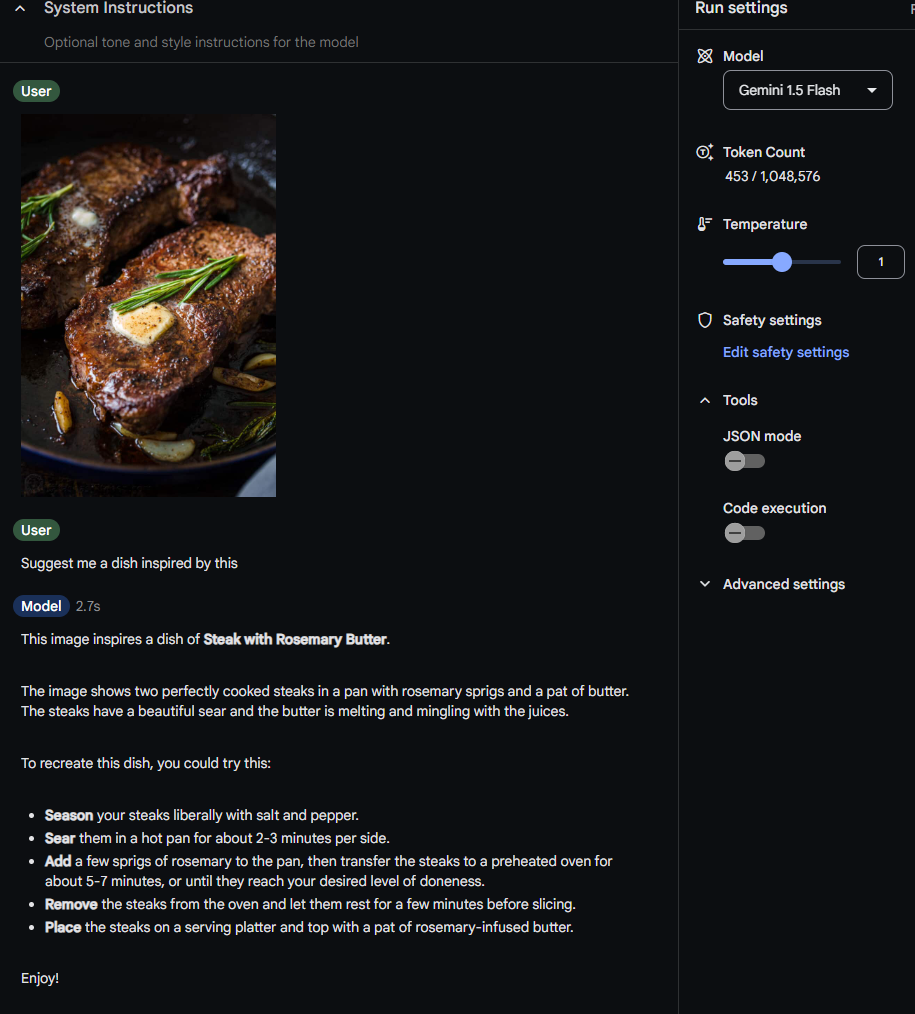
Now if you want to use this one in your code, you can get the python code
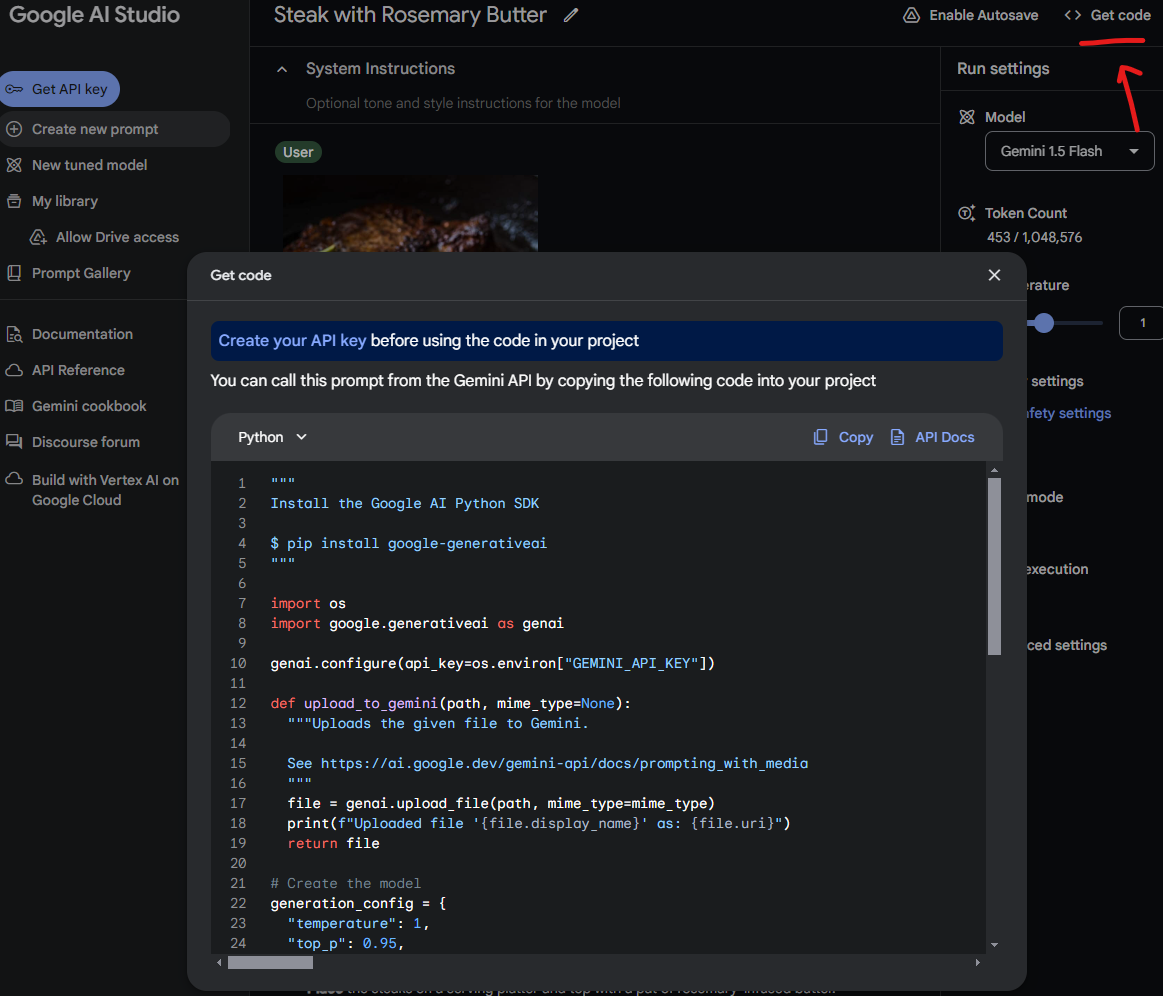
Follow these best practices

Other parameters
Check the blog
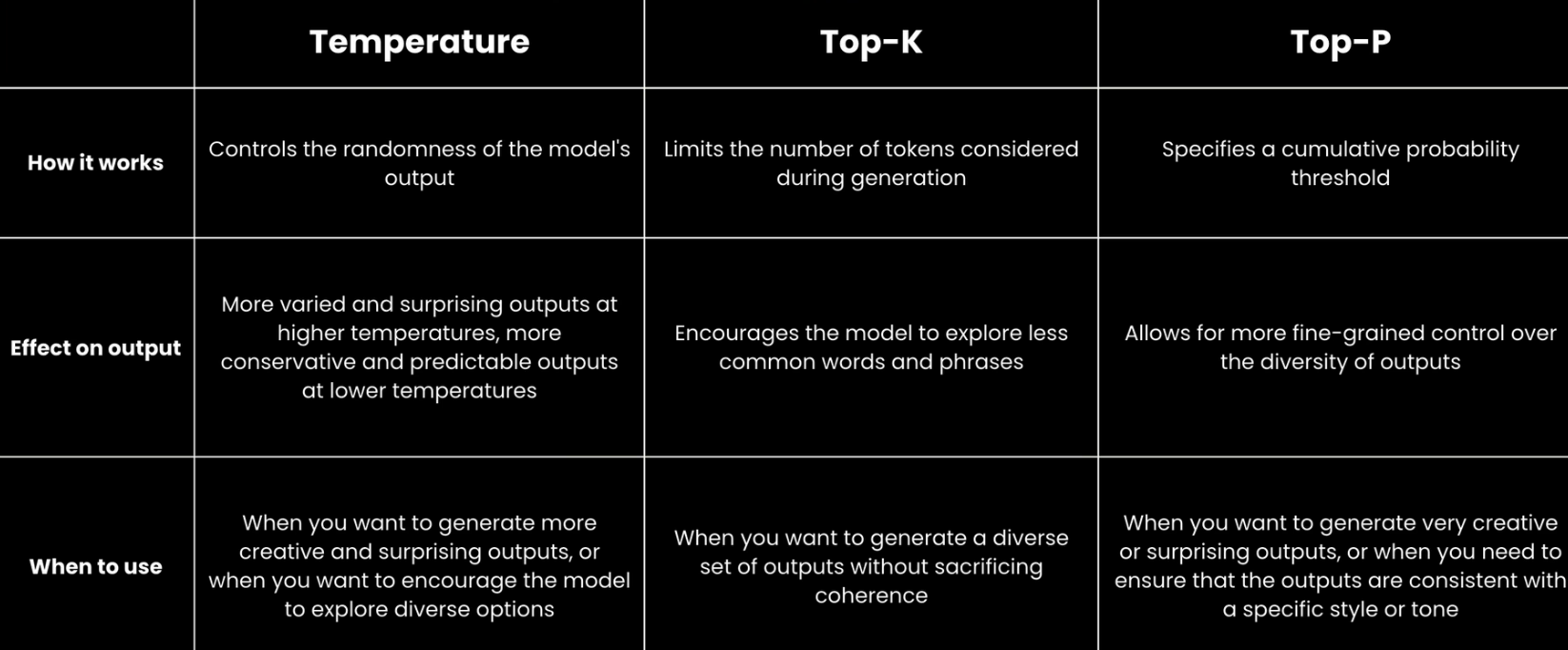
Temperature

It controls the randomness. Currently the range of temperature has changed to 0-2

for example, here we can see that
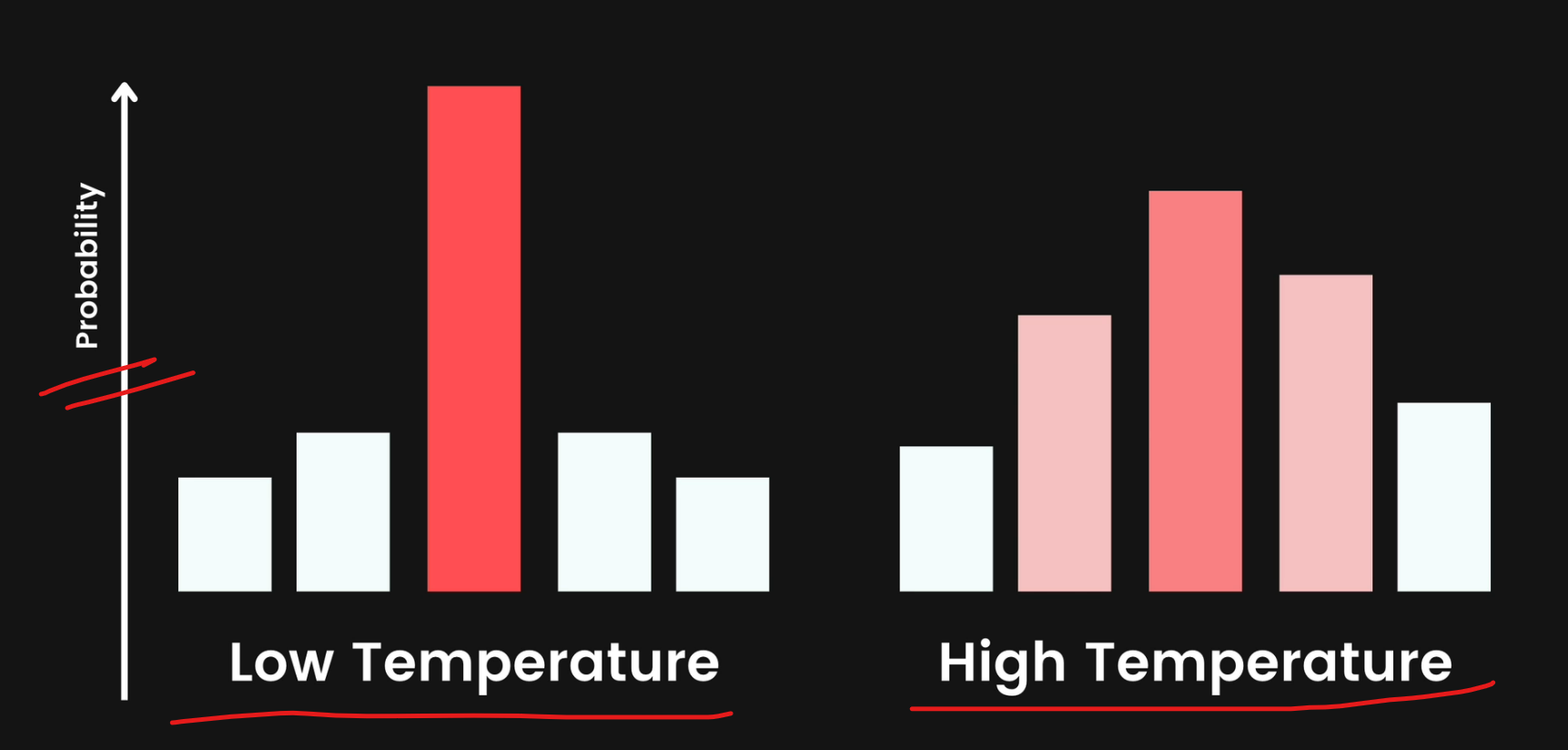
There's essentially a mathematical equation ;behind the scenes that is going to apply the temperature in such a way that it impacts the probabilities of that, that generated list of tokens.
A lower temperature is going to result in a curve that is a lot sharper, where we'll have one token with a significant, maybe not just one, but 1 or, 2 tokens that are significantly more likely to be chosen.
Here you can see this one value (token) to be the most
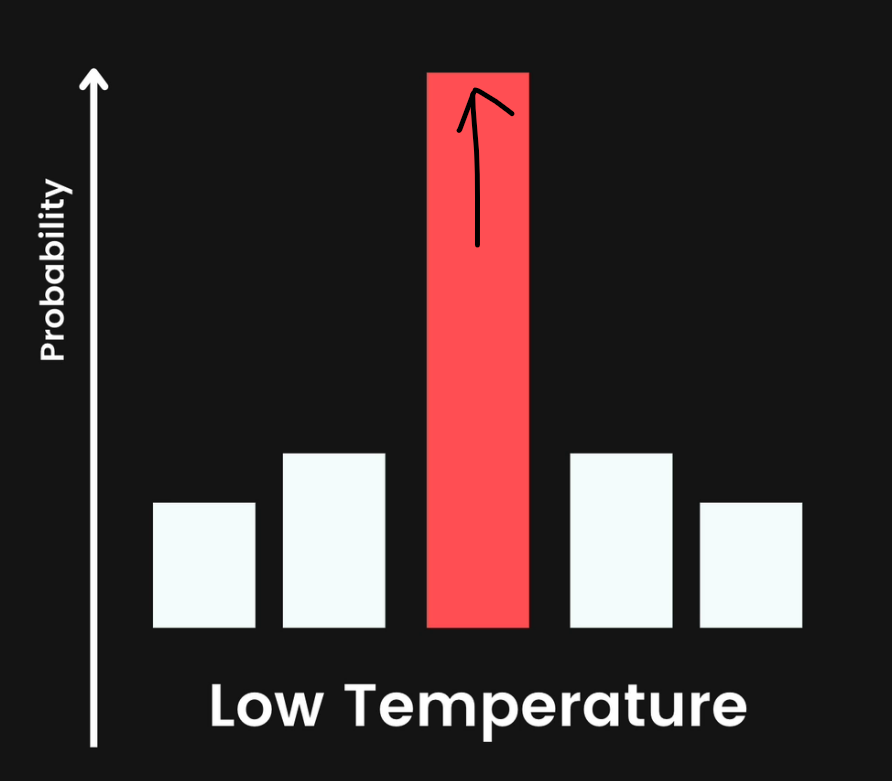
A higher temperature leads to more diverse or creative results, but also sometimes wackier results.
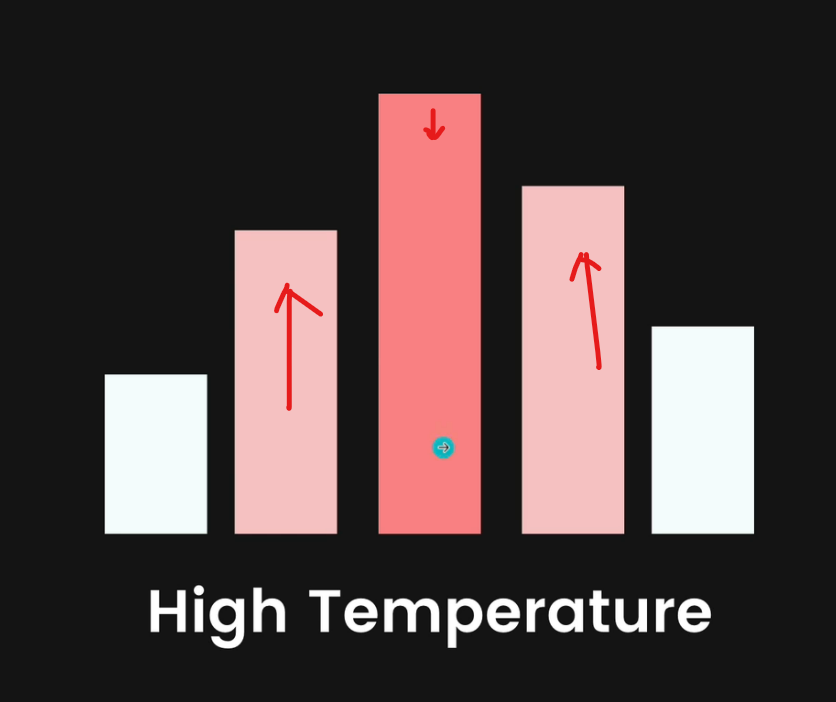
Here you can see rather than just one token, there are other tokens which also has now high chance to get picked.
That's why using those tokens, we can see more innovative results.
If you set temperature to 0, there will be no randomness of the token and therefore, we will have same output everytime.
Stop sequence

Here we go,
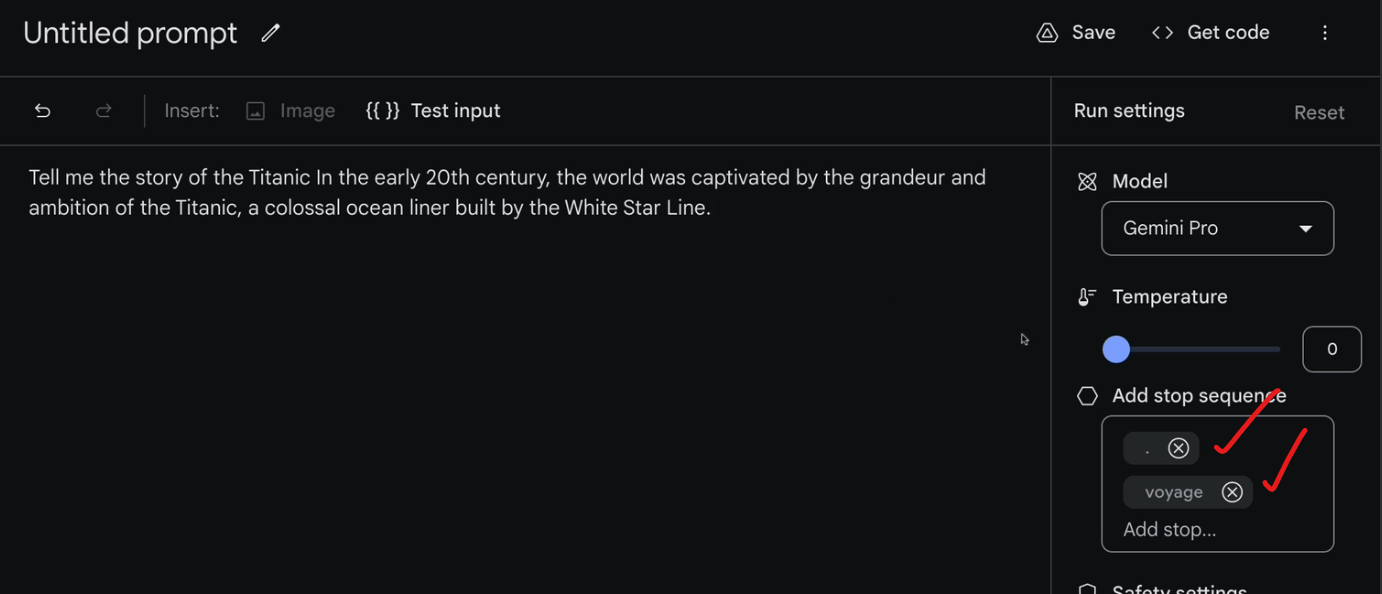
Here the output stopped when it found a comma as comma and voyage are stop sequence
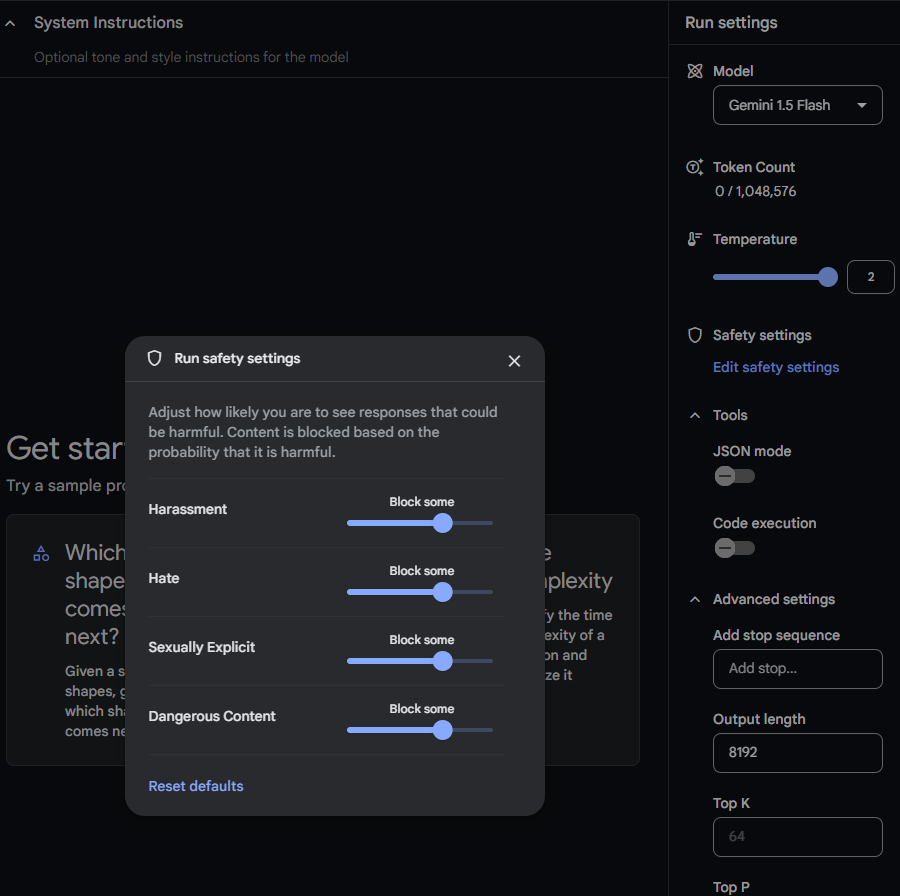
Safety settings
You can also fine tune the safety settings to ignore unwanted things
Top K

Top-K changes how the model selects tokens for output. A top-K of 1 means the next selected token is the most probable among all tokens in the model's vocabulary (also called greedy decoding),
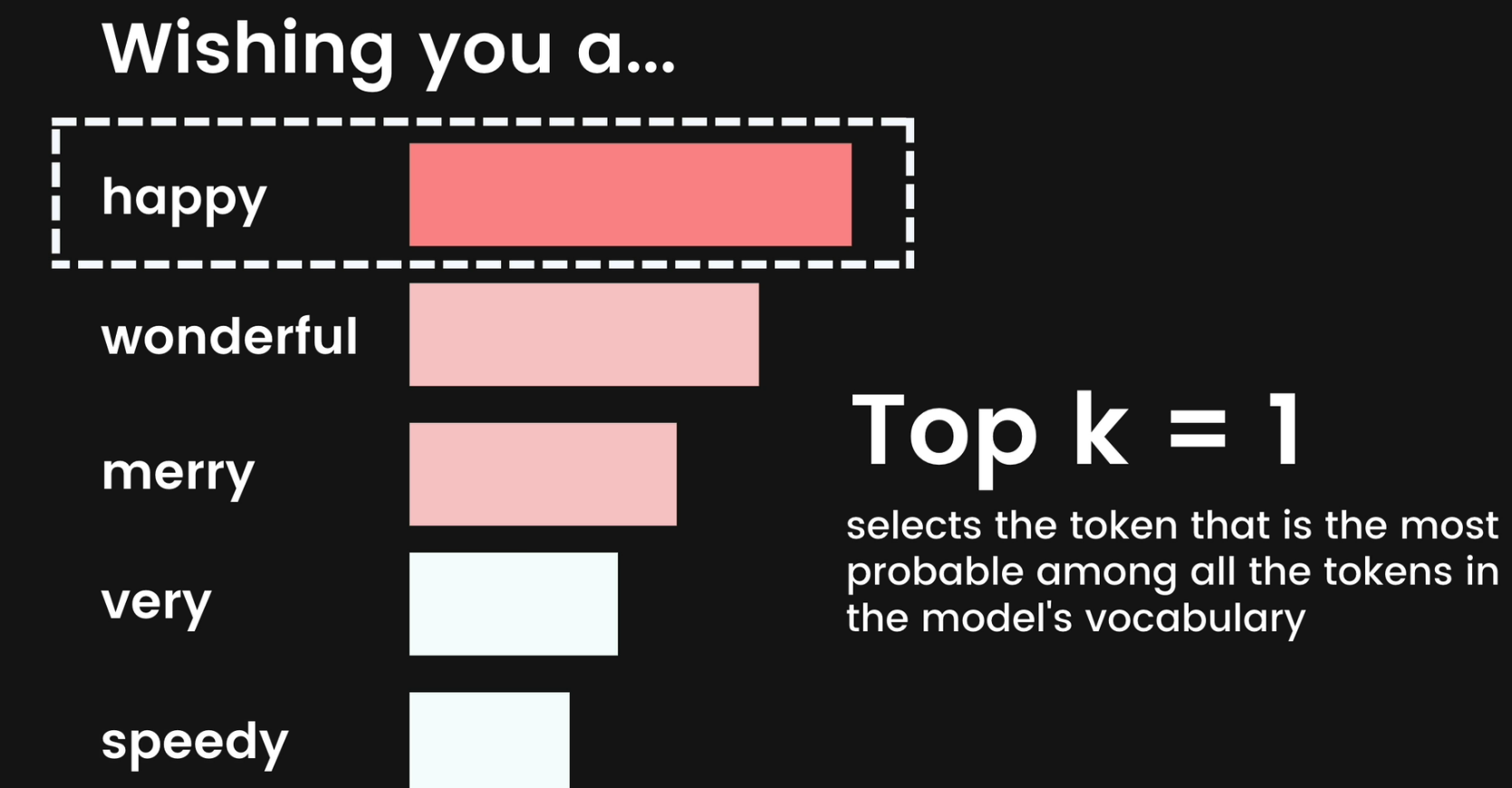
Here only the top 1 token is selected.
while a top-K of 3 means that the next token is selected from among the three most probable tokens by using temperature.

So, setting k to 3 selects top 3 tokens from the list which we got from temperature.
For each token selection step, the top-K tokens with the highest probabilities are sampled. Then tokens are further filtered based on top-P with the final token selected using temperature sampling.
Specify a lower value for less random responses and a higher value for more random responses.
Top P

Top-P changes how the model selects tokens for output. Tokens are selected from the most (see top-K) to least probable until the sum of their probabilities equals the top-P value.
For example, if tokens A, B, and C have a probability of 0.3, 0.2, and 0.1 and the top-P value is 0.5, then the model will select either A or B as the next token by using temperature and excludes C as a candidate.
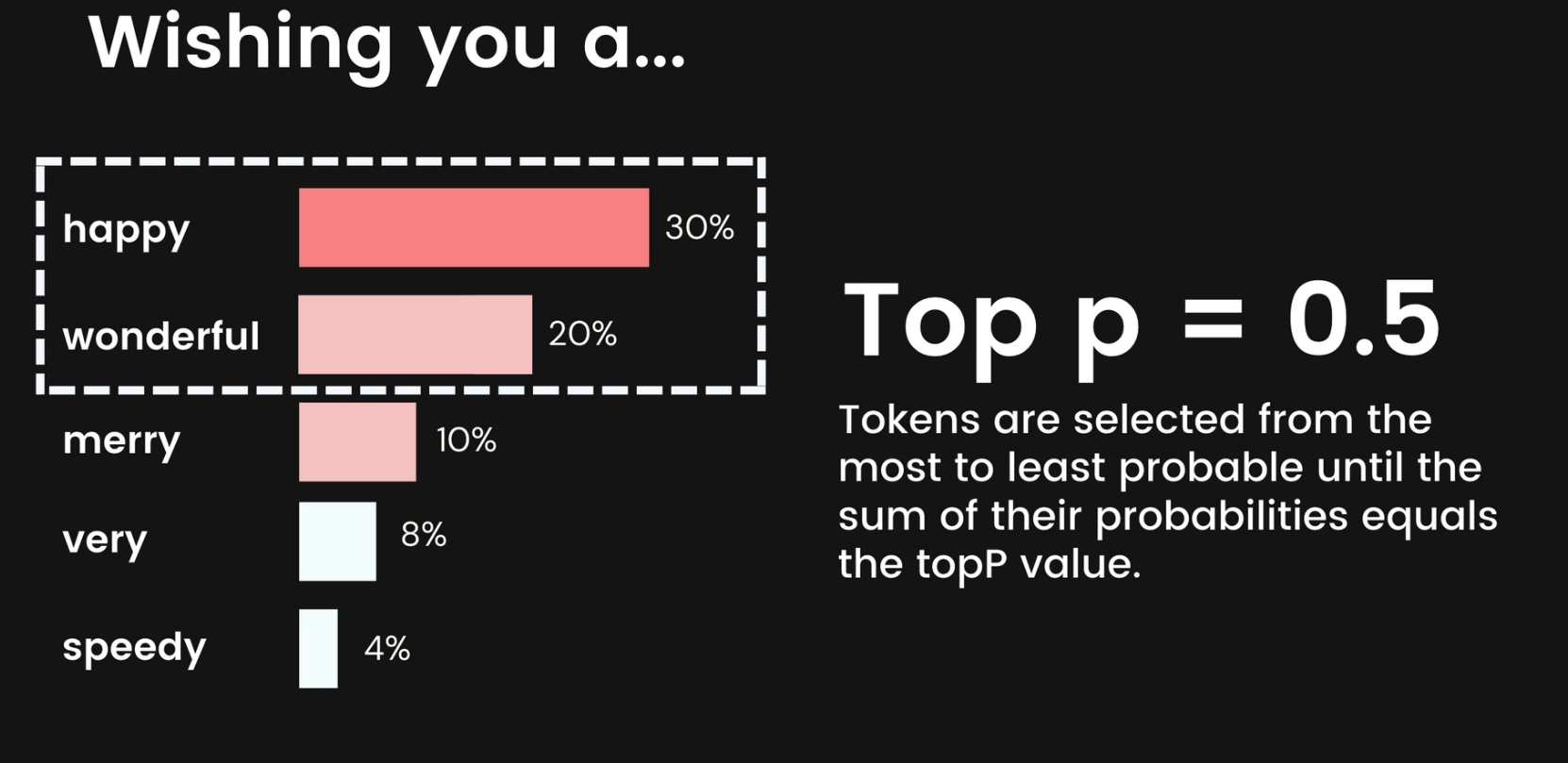
Here, top P is 0.5 and so, the first two probability of token happy and wonderful is 0.3 and 0.2
As they sum up to 0.5, so we will select these two tokens.
Specify a lower value for less random responses and a higher value for more random responses.

So, to sum up
Subscribe to my newsletter
Read articles from Md Shahriyar Al Mustakim Mitul directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by