Understanding Send and Receive Buffers in Network Programming on Linux
 Sameera Khatoon
Sameera KhatoonIn network programming, particularly on Linux, send and receive buffers are vital for managing data flow between applications and the operating system (OS). These buffers facilitate the transition of data from user space to kernel space and vice-versa, ensuring proper data transmission and reception over a network. Here's a closer look at how these buffers function within the Linux OS.
1. Send Buffers on Linux: Data Flow from User Space to Kernel Space
When a client application running on Linux sends data over a network, the process involves several steps:
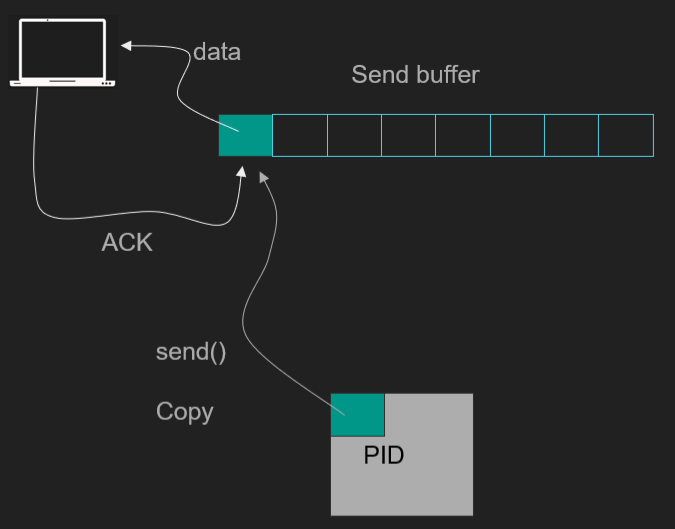
Data Preparation: The application processes the data in user space, potentially performing tasks like encryption or compression. Once ready, the data is moved into the send buffer within the Linux kernel.
Data Transmission: The data is copied from user space (application memory) to the kernel space send queue using system calls like
send(). This involves transferring data from the user space heap, through the CPU, into the kernel memory, potentially utilizing Direct Memory Access (DMA).Kernel Management: The Linux kernel manages the data in the send queue and may delay immediate transmission due to algorithms like Nagle's algorithm, which optimizes network traffic by reducing the number of small packets sent. For certain use cases, like low-latency communication in Node.js, developers might disable Nagle's algorithm to reduce delays.
Efficiency in Linux: On Linux, tools like Bun or system calls like
sendfile()can leverage zero-copy techniques, reducing unnecessary data copying. For example,sendfile()allows direct data transfer from a file's page cache in kernel space to a network socket, bypassing the need for intermediate user space copies, thus enhancing performance.
2. Receive Buffers on Linux: Data Flow from Kernel Space to User Space
When data arrives at a Linux server, the process involves several key steps:
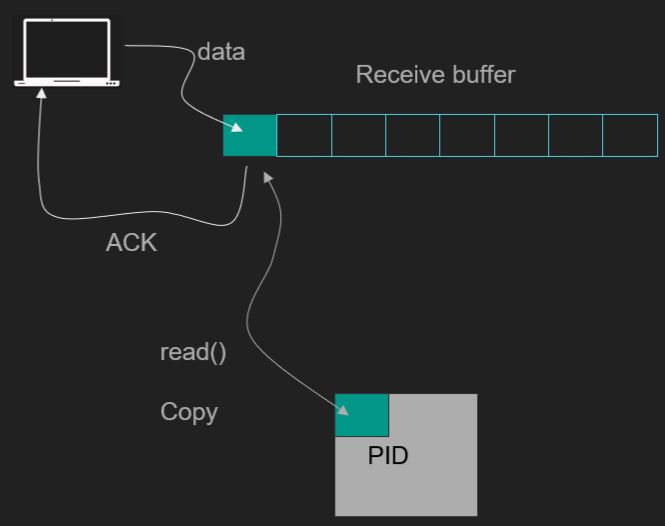
Data Reception: The Linux kernel captures incoming packets and stores them in the receive buffer associated with a specific network connection. This connection is identified by unique source and destination IP addresses and ports.
Delayed ACKs: The kernel may delay acknowledging the packets (using mechanisms like delayed ACKs) to optimize network traffic and reduce the overhead of multiple small acknowledgments.
Application Read: When the application on Linux is ready to process the data, it uses system calls like
recv()to read the data. The kernel then copies the data from the receive buffer in kernel space to the application's memory in user space. This process involves transferring data from kernel memory, through the CPU, into the userspace heap.Performance Considerations: Performance issues may arise if the application does not read data quickly enough, leading to a full receive queue. Additionally, if the client reduces its transmission speed (e.g., shrinking its flow control window), the server’s receive queue could overflow, resulting in dropped packets.
3. Challenges and Optimizations in Linux
Managing send and receive buffers efficiently on Linux is crucial for maintaining smooth data flow and preventing bottlenecks:
Data Copying: Both send and receive buffers involve significant copying of data between user space and kernel space. While necessary, this can impact performance, particularly in high-throughput applications.
Zero-Copy Techniques: Linux offers optimizations like zero-copy through system calls like
sendfile(), which minimizes the data copying overhead by allowing data to be transferred directly between kernel structures without passing through user space.Connection Handling: Efficient management of network connections is essential. Reusing established connections instead of repeatedly opening and closing them can reduce overhead, particularly in applications with high traffic, enhancing overall performance.
Conclusion
On Linux, send and receive buffers play a critical role in network communication, ensuring efficient data transfer between applications and the OS. Understanding these mechanisms, along with the challenges and optimizations available, such as zero-copy and connection reuse, is essential for developing high-performance networked applications on this OS. Mastering these concepts can significantly improve the efficiency and scalability of network programming in Linux environments.
Subscribe to my newsletter
Read articles from Sameera Khatoon directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by