Kubernetes : API Security & RBAC Under The Hood
 Navraj Singh
Navraj Singh
Starter
Kubernetes revolves around its API, which is managed by the API server. In this section, we will trace a standard API request as it navigates through various security checks. Basically we will see how a kubectl command goes through a lot of steps to get itself executed, perform the task and end itself successfully. The section is organized into the following parts:
API security big picture
Authentication ( The first barrier for request )
Authorization (RBAC) ( The second barrier for request )
Admission control ( The third & last barrier for request )
API security big picture
Kubernetes relies heavily on its API, which is at the heart of everything that happens in the cluster. If you have done some kind of backend web development for some weeks or months then this section will be fairly easy to understand, otherwise first learn about API's, HTTP, HTTPS etc. and then think about learning kubernetes. I personally have done nodejs ecosystem backend development for few months. So for me the understanding all of this for the very first time was little bit easy. Let's get back to the topic.
The API is managed by the API server, and it handles many types of requests for creating, reading, updating, and deleting resources (often referred to as CRUD operations). The resources are nothing but pods, services (nodePorts, clusterIP, load-balancer etc.) stateful sets, deployment sets, replica sets, volumes and many other resources. These API requests can come from different sources, such as:
Operators and developers using
kubectlcommandsPods running within the cluster nodes
Kubelets, which manage individual nodes
Control plane's components
Apps that are native to Kubernetes
No matter the origin of api request, all API requests go through a series of security checks to ensure the cluster remains secure.
Image illustrates this flow, showing how an API request passes through each of these checks.
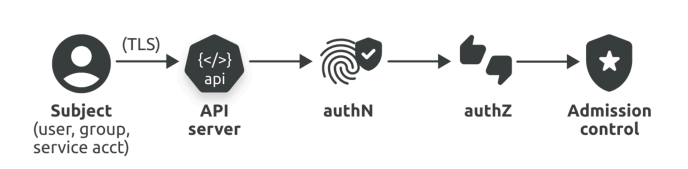
Example: How a single API Request you make or some other resource make is Handled
Consider an example where a user named john-cena wants to create a new Deployment called john-deployment in a Namespace named john-namespace. So john cena opens the terminal in his laptop and type the kubectl apply -f <name of the file> command and press enter on his keyboard. Here’s how the process works:
kubectl Creates RestAPI Request: The user
john-cenauses thekubectl applycommand to send a request to the API server, so that he can create thejohn-deploymentDeployment in thejohn-namespaceNamespace. Kubectl behind the scenes itself is translating thiskubectl apply -fcommand to a RestAPI kind of requests to communicate with API server to do what the command/user wants.TLS Connection is made: The
kubectltool then sends this api request to the Kubernetes API server, kubectl also adds the user’s credentials within the api request itself. The connection betweenkubectland the API server is encrypted and secured using TLS (Transport Layer Security). The credentials of userjohn-cenaare stored safely in a hidden file calledconfigunder the~/.kube/path on linux OS.Authentication happens: Upon receiving the request, the API server's authentication module first checks if the request is genuinely from
john-cenaand not someone pretending to be them. If it successfully verifiesjohn-cena, it moves on to the next step.Authorization happens (using RBAC): Next, the authorization module (commonly implemented using Role-Based Access Control or RBAC) checks whether
john-cenahas the permissions to create a Deployment in thejohn-namespaceNamespace.Admission Controllers Checks: If both the authentication and authorization checks are passed, the request then goes through a series of admission controllers. These controllers ensure that the Deployment object aligns with the policies, such as resource quotas or security policies.
Only after passing all these stages — authentication, authorization, and admission-controllers does the API server allow the request to be executed and the Deployment to be created.
So in short:
Kubectl command -> RestAPI request -> API server -> Authentication -> Authorization (RBAC) -> Admission controllers -> Request is executed
To understand this better, Analogy to Boarding a Flight:
Think of this process like boarding a flight. When you arrive at the airport, you need to authenticate your identity with a photo ID or passport. If you pass this authentication check, you then present your boarding pass, which authorizes you to board the plane. Finally, before boarding, airline staff may check for compliance with certain policies, such as the size of your carry-on luggage or prohibitions on carrying specific items. Once you've cleared all these checks, you're allowed to board the plane and proceed to your destination.
Now that we've covered the big picture, let's understand each step - authentication, authorization, admission controllers in depth.
Authentication ( The first barrier for request )
Authentication is just a fancy way of saying "proving who you are." In Kubernetes, this is often shortened to authN (sounds like "auth-en").
Think of it like this: anytime you want to do something in Kubernetes (like creating a pod or service), you need to show some form of ID—like a username and password or a token. The API server checks this ID. If it can’t confirm who you are, it says “Nope!” and gives you a "401 Unauthorized" error. If you pass, then it authorization step takes place.
Kubernetes doesn’t manage user identities on its own. It relies on other systems to handle who’s who. This could be something like Active Directory (AD), a cloud provider’s Identity and Access Management (IAM) service.
When you set up Kubernetes, it can use client certificates for basic authentication. If you use a managed Kubernetes service (like AWS or Google Cloud), this integration is usually set up for you, so you don’t have to worry about it.
Checking Your Current Authentication Setup
To access and request anything to your Kubernetes clusters from outside world.. kubeconfig file is important, user credentials and cluster details are stored in a kubeconfig file. Tools like kubectl use this file to figure out which cluster to interact with and what credentials to use. The typical locations for this file are:
Windows:
C:\Users\<user>\.kube\configLinux/Mac:
/home/<user>/.kube/config
Below is a sample kubeconfig file, which shows how clusters and users are defined, how they’re linked into contexts, and which context is set as the default for kubectl commands. Note that this is a shortened example:
apiVersion: v1
kind: Config
clusters: # Defines clusters and their certificates
- cluster:
name: cluster-one # cluster name
server: https://<url-or-ip-address-of-api-server>:443 # Cluster's API server URL
certificate-authority-data: <something>...NS1tCg== # Public key of the cluster's CA
users: # Defines users and their credentials
- name: user-one # A user named "user-one"
user:
token: zyChbZciOiJSUzI1NiIsImtpZCI6IlZwMzl...SUY3uUS # User's token
contexts: # Combines users and clusters
- context:
name: user-one-cluster-one # Context named "user-one-cluster-one"
cluster: cluster-one # Associated cluster
user: user-one # Associated user
current-context: user-one-cluster-one # Default context used by kubectl
The kubeconfig file is organized into four main sections:
Clusters: Lists one or more Kubernetes clusters with a friendly name, an API server endpoint, and the cluster's Certificate Authority (CA) public key.
Users: Specifies one or more users, each needing a name and an authentication token. The token is usually an certificate signed by the cluster’s CA.
Contexts: Combines users and clusters to form contexts.
Current-context: Specifies which context is the default for
kubectlcommands.
Based on the example above, any kubectl command will be sent to the cluster-one cluster using the credentials of the user-one user. When a request is made, the cluster’s authentication module checks if the user really is user-one or an impostor.
If your Kubernetes cluster is on aws or gcp or azure then authentication layer and IAM system comes from that cloud provider.
In short, roughly you can say:
kubectl command + kubeconfig file = authentication pass/failed
Once a request passes authentication successfully, it moves on to the authorization phase.
Authorization ( The second barrier for request )
Authorization comes right after a user successfully proves who they are (authentication). You might see it shortened to authZ (pronounced "auth zee"). The most common way to handle authZ is with RBAC (Role-Based Access Control).
This section covers:
What RBAC is all about
How users and permissions work
Managing cluster-wide users and permissions
Built-in users and permissions
RBAC Big Picture
RBAC, or Role-Based Access Control, is like the rulebook for what people (or systems) can do in Kubernetes. At its core, RBAC is about three things:
Users (who can do it)
Actions (what they can do)
Resources (what they are acting on)
Think of RBAC as a set of rules that says, "User X can do Action Y on Resource Z." Here are some examples to make it clear:
| User (Subject) | Action | Resource | Effect |
| johnCena | create | Pods | johnCena can create Pods. |
| IronMan | list | Deployments | IronMan can list Deployments. |
| SpiderMan | delete | ServiceAccounts | SpiderMan can delete ServiceAccounts. |
By default, Kubernetes clusters with RBAC are locked down—nobody can do anything unless there's a rule saying they can. You don't have "deny" rules, only "allow" rules.
Users and Permissions
Two key concepts are important for understanding how Kubernetes RBAC works:
Roles
RoleBindings
A Role defines a set of permissions, and a RoleBinding connects these permissions to a user. Here’s an example of what a Role object might look like. This Role is named read-deployments and gives permission to get, watch, and list Deployment objects in a Namespace called shield.
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: shield
name: read-deployments
rules:
- verbs: ["get", "watch", "list"] # Actions allowed
apiGroups: ["apps"] # On which group of resources
resources: ["deployments"] # Of this type
However, just creating a Role doesn’t do anything by itself. You need to bind it to a user. Here’s an example of a RoleBinding that connects the read-deployments Role to a user named sky.
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: read-deployments
namespace: shield
subjects:
- kind: User
name: sky # The authenticated user
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role
name: read-deployments # The Role to bind to the user
apiGroup: rbac.authorization.k8s.io
When you apply both the Role and RoleBinding, the user sky can run commands like kubectl get deployments -n shield. Remember, the username in the RoleBinding must exactly match a successfully authenticated user’s name.
Cluster-Level Users and Permissions
So far, we've talked about Roles and RoleBindings, which are specific to a Namespace. Kubernetes also has two more objects:
ClusterRoles
ClusterRoleBindings
While Roles and RoleBindings apply to specific Namespaces, ClusterRoles and ClusterRoleBindings are cluster-wide. This means they can affect all Namespaces. All four types are defined similarly in Kubernetes, and their YAML configurations look almost the same.
A smart way to manage permissions is to use ClusterRoles to define roles that apply across the entire cluster and then use RoleBindings to link them to specific Namespaces. This way, you only define the roles once and reuse them in the Namespaces you want. The image (Figure 14.2) provided shows this concept visually.
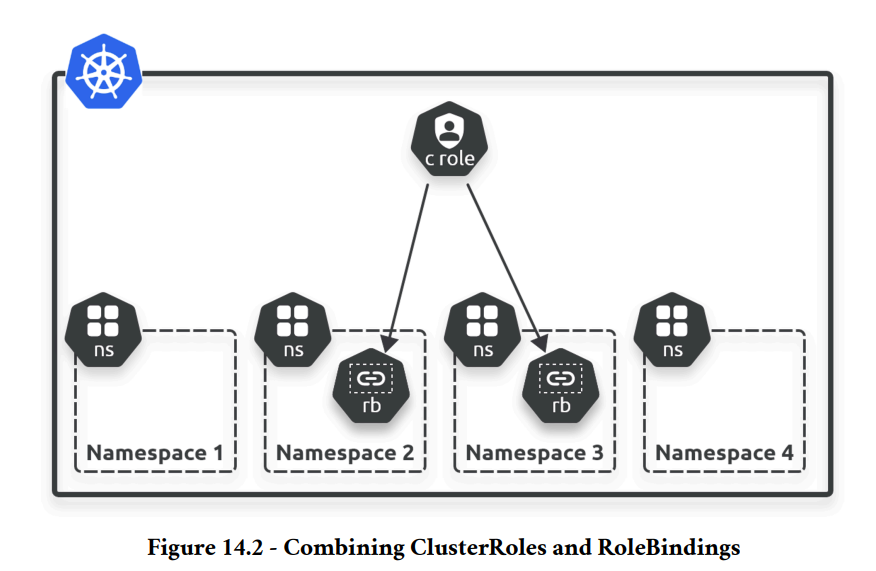
Here’s how the read-deployments role from earlier looks when it’s defined as a ClusterRole:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole # Cluster-wide role
metadata:
name: read-deployments
rules:
- verbs: ["get", "watch", "list"]
apiGroups: ["apps"]
resources: ["deployments"]
Notice the only difference is that this is a ClusterRole (not Role), and there’s no metadata.namespace field.
Built-In Users and Permissions
Many kubernetes cluster like the ones on AWS, GCP, Azure, Docker-Desktop etc. have pre-defined users. These users have given power to anything in the cluster by default. These powers comes from role/clusterRole and roleBinding/clusterBinding which are created and attached to the user by the platforms like aws, azure, gcp docker-desktop itself.
Now let's see how docker-desktop has specified and created this pre-made built-in user and permissions.
When using Docker Desktop for Kubernetes, your kubeconfig file is set up with a client certificate signed by the cluster’s Certificate Authority (CA). This certifies a user called docker-for-desktop which comes built in by docker desktop, who is in the system:masters group. Kubernetes clusters on Docker Desktop come with a ClusterRoleBinding called cluster-admin that binds users in the system:masters group to a ClusterRole named cluster-admin. This role gives full admin access to the user to all objects in all Namespaces.
But ofcourse if you create more new users then you will need to configure them yourself and configure their RBAC manually.
Summarizing Authorization
Authorization is all about checking if users who have already been authenticated (proven who they are) are allowed to do what they're trying to do. RBAC is a very popular way to handle authorization in Kubernetes, following a "least privilege" model where everything is denied by default unless you create a rule that says otherwise.
Roles and ClusterRoles define what can be done, and RoleBindings and ClusterRoleBindings grant those abilities to specific users or groups. After authorization, if everything checks out, the request moves on to admission control.
Admission Control ( The last barrier for request )
Admission control kicks in right after a request has passed authentication (proving who you are) and authorization (checking if you have permission). Think of admission control as a way to enforce policies on requests that try to change something in the cluster.
Kubernetes has two types of admission controllers:
Mutating Admission Controllers
Validating Admission Controllers
The names give away their purposes:
Mutating Controllers: They check requests and can change them to fit certain rules or policies.
Validating Controllers: They check requests to see if they follow the rules but can’t change them. They can only approve or reject them.
Mutating controllers always run first. Both types are only triggered for requests that try to change the state of the cluster. Requests that just read data aren't affected by admission control.
Here’s a quick example to clarify things: Let’s say you have a production cluster with a policy that every new or updated pod must have the label env=prod. A mutating controller could look at each request coming to it.. to see if this label exists. If not, it could add the label automatically.
On the other hand, a validating controller would simply reject the request if the label is missing — no adding or changing.
You can check the admission controllers that is being used in your cluster by running a command like this in a Docker Desktop cluster:
kubectl describe pod kube-apiserver-docker-desktop --namespace kube-system | grep admission
You might see something like --enable-admission-plugins=NodeRestriction, which shows the NodeRestriction admission controller is enabled.
Real-world clusters usually have many admission controllers running. A common one is the AlwaysPullImages admission controller, which is a mutating controller. It forces every new Pod to always pull its images from a registry, instead of using any cached images that may already exist on a node.
One important thing to note is that if any admission controller rejects a request, it stops right there — no further checks are made. This means all admission controllers must approve a request before it’s allowed to run in the cluster.
Blog Summary
Here’s a quick summary of what we covered:
Every request to the Kubernetes API server needs credentials. These requests must pass three checks: authentication, authorization, and admission control.
Authentication is the first layer that verifies who is making the request. Most clusters support client certificates, but in serious production environments, you should use enterprise-grade Identity and Access Management (IAM) systems for this.
Authorization comes next. It checks whether the authenticated user has permission to perform the requested action. Kubernetes supports multiple ways to handle authorization, but RBAC (Role-Based Access Control) is the most popular. RBAC is made up of four key components: Roles, ClusterRoles, RoleBindings, and ClusterRoleBindings.
Admission Control is the final layer. It steps in after authorization and is all about enforcing policies. There are two types of admission controllers:
Validating Admission Controllers: They reject requests that don’t meet certain rules.
Mutating Admission Controllers: They can modify requests to make them comply with rules.
Special Thanks
Nigel Poulton & his book "The Kubernetes Book" 2024 Edition. This book is solely responsible for my k8s journey. Information in this blog is highly inspired from his book.
Navraj's Social Handles
X ( Twitter )
Linked-In
GitHub
Subscribe to my newsletter
Read articles from Navraj Singh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Navraj Singh
Navraj Singh
Navraj Singh is a DevOps Enthusiast with knowledge of DevOps and Cloud Native tools. He is technical blogger and devops community builder. He has background of Backend Development in NodeJS ecosystem.