Attention Is All You Need
 Mehul Pardeshi
Mehul Pardeshi
Welcome, everyone! Today's topic is going to be very interesting and insightful. Think of it as the BIG BANG of deep learning, particularly in the field of natural language processing (NLP) and sequence modeling.
The Transformer architecture has had a significant impact on how we handle natural language processing (NLP) and sequence modeling.
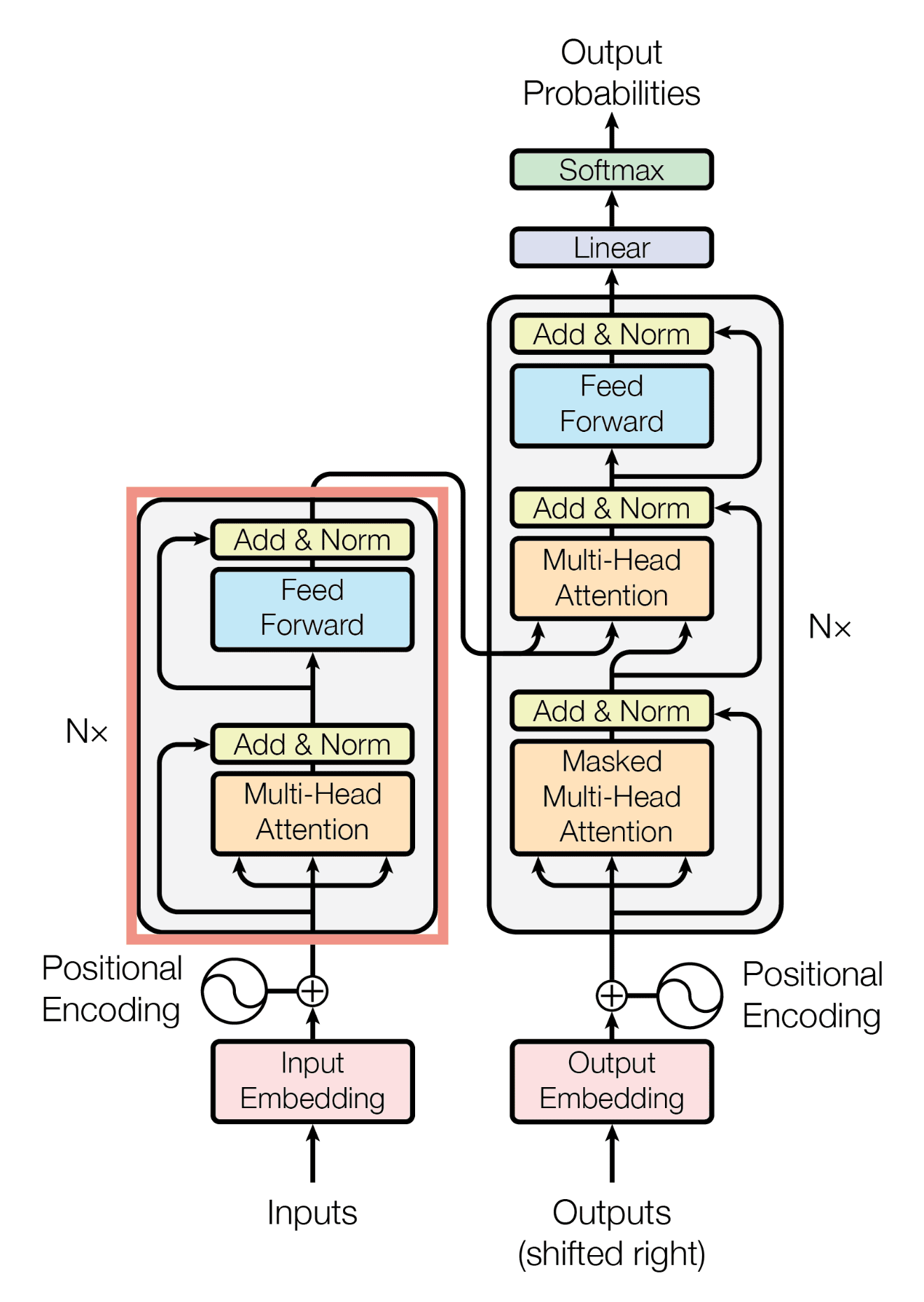
In the world of deep learning, particularly in natural language processing (NLP), the introduction of the Transformer architecture has been nothing short of revolutionary. Before the Transformer, tasks like machine translation, text generation, and other sequence modeling problems heavily relied on Recurrent Neural Networks (RNNs) and Convolutional Neural Networks (CNNs). These models, while powerful, had limitations, especially when it came to handling long sequences of data.
So, what exactly is the Transformer? In simple terms, it's a deep learning model that processes data in a completely new way compared to its predecessors. Traditional models like RNNs relied on sequential data processing, which made them slow and less efficient when handling long sequences. The Transformer, however, uses something called attention mechanisms to process data in parallel. This approach not only speeds up the process but also improves the model's ability to understand and generate language.

At its core, the Transformer is built on an encoder-decoder structure. The encoder reads and processes the input data, while the decoder generates the output. But the magic lies in how these components interact—through attention.
How Does the Transformer Work?
- Input Embedding:
The first step involves converting the input words into vectors. These vectors are essentially numbers that represent the words in a way that the model can understand. For instance, the word "apple" might be converted into a vector like [0.5, 1.2, -0.3, ...]. These vectors are called embeddings.
- Positional Encoding:
Since the Transformer doesn’t process words in order like humans do, it needs a way to understand the sequence of words in a sentence. This is where positional encoding comes in. It adds information to the word embeddings to help the model know the position of each word in the sentence. For example, in the sentence "I love apples," the model knows that "I" is the first word and "apples" is the last.
- Self-Attention Mechanism:
This is the heart of the Transformer. The self-attention mechanism allows the model to focus on different words in the sentence, depending on which ones are most important for understanding the meaning. For instance, when the model is processing the word "apples" in the sentence "I love apples," it might pay more attention to the word "love" to understand that "apples" is the object of affection. The model calculates an attention score for each word, determining how much focus to give to other words in the sentence.
- Multi-Head Attention:
Instead of having just one attention mechanism, the Transformer has multiple attention mechanisms, known as multi-head attention. Each attention head looks at the sentence from a different perspective, capturing different aspects of the relationships between words. This helps the model to better understand the nuances in the sentence.
- Feed-Forward Neural Network:
After the attention mechanism, the processed information is passed through a simple neural network. This network is the same for each word and helps in further refining the understanding of the sentence.
- Encoder and Decoder Stacks:
The Transformer is composed of multiple layers, or "stacks," of encoders and decoders. Each encoder layer processes the input and passes it on to the next layer, while each decoder layer does the same for generating the output. The decoder also has its own attention mechanism, which focuses on both the output generated so far and the encoded input.
Output Generation:
Finally, the decoder generates the output sequence (like a translated sentence) one word at a time, using the information processed by the encoder. It keeps using the attention mechanism to ensure that the words it generates are related to both the input sentence and the words it has already generated.
Key Components of the Transformer
Encoder and Decoder: The Transformer consists of multiple layers of encoders and decoders. Each layer in the encoder is responsible for processing the input data and passing it on to the next layer. The decoder, on the other hand, uses the processed information from the encoder to generate the output, one word at a time.
Self-Attention Mechanism: This is where the Transformer really shines. Instead of processing words in a sentence one by one, the self-attention mechanism allows the model to look at all the words simultaneously and decide which ones are important for understanding the context. For instance, when translating a sentence, the word "bank" might mean different things depending on whether the sentence is talking about a financial institution or the side of a river. The self-attention mechanism helps the model figure out these nuances by focusing on the right words at the right time.
Positional Encoding: Unlike RNNs, the Transformer doesn't process words in order, so it needs a way to understand the position of each word in a sentence. Positional encoding provides this information, helping the model make sense of the word order, which is crucial for tasks like translation.
Impact on NLP and Sequence Modeling
The impact of the Transformer on NLP and sequence modeling has been profound. Before its introduction, models struggled with long-range dependencies in sequences. RNNs and LSTMs, for example, often forgot information from earlier in the sequence as they processed more data. The Transformer's attention mechanism addressed this problem head-on, allowing it to capture dependencies between words regardless of their distance from each other in the text.
![37 ChatGPT Memes Madness [Not generated by ChatGPT 🤣] | Engati](https://cdn.prod.website-files.com/5ef788f07804fb7d78a4127a/649542c7b98eca744932cbce_gpt%20meme%2023.jpeg)
The introduction of the Transformer has led to the development of even more advanced models like BERT (Bidirectional Encoder Representations from Transformers), GPT (Generative Pre-trained Transformer), and T5 (Text-To-Text Transfer Transformer). These models have set new benchmarks in various NLP tasks, from machine translation to text summarization, sentiment analysis, and more.
Conclusion
The Transformer architecture has truly transformed the landscape of deep learning. By discarding the need for recurrence and convolutions and relying entirely on attention mechanisms, it has made models faster, more efficient, and more capable of handling complex language tasks. The advancements we see today in NLP, from chatbots to language translation, owe a great deal to the foundational work laid out in the "Attention Is All You Need" paper.
Now that we’ve explored the Transformer architecture and its incredible impact, we can start looking forward to the other interesting techniques of Deep Learning and NLP. But that’s a topic for another time. For now, we can appreciate just how much the Transformer has revolutionized the field of deep learning.
Subscribe to my newsletter
Read articles from Mehul Pardeshi directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Mehul Pardeshi
Mehul Pardeshi
I am an AI and Data Science enthusiast. With hands-on experience in machine learning, deep learning, and generative AI. An active member of the ML community under Google Developer Clubs, where I regularly leads workshops. I am also passionate about blogging, sharing insights on AI and ML to educate and inspire others. Certified in generative AI, Python, and machine learning, as I continue to explore innovative applications of AI with my fellow colleagues.