Snowflake Dynamic Tables: How to Simplify ELT Pipelines with Target Lag and Incremental Refresh (2025)
 John Ryan
John Ryan
Snowflake Dynamic Tables share functionality similar to Snowflake Streams and Materialized Views, yet they have distinct differences and advantages over the alternative solutions.
This article will describe Dynamic Tables, their target use cases, and how best to configure and deploy this fantastic technology to simplify building complex data processing pipelines. Finally, we'll compare Dynamic Tables to Snowflake Streams and Materialized Views to help you decide on the best approach to streamline data transformation pipelines.
Prefer to watch a video?
What is a Snowflake Dynamic Table?
A Snowflake Dynamic Table is similar to a Materialized View in that it stores a query's result set, which helps maximize query performance. However, unlike a Materialized View, designed for simple summary tables, Dynamic Tables can include complex Join operations and automatically perform Change Data Capture on source tables.
In many ways, Dynamic Tables replace some of the functionality of Streams and Tasks in the way they can deliver ELT pipelines. Consider the diagram below, which shows a simple data pipeline using Snowflake Streams and Tasks.
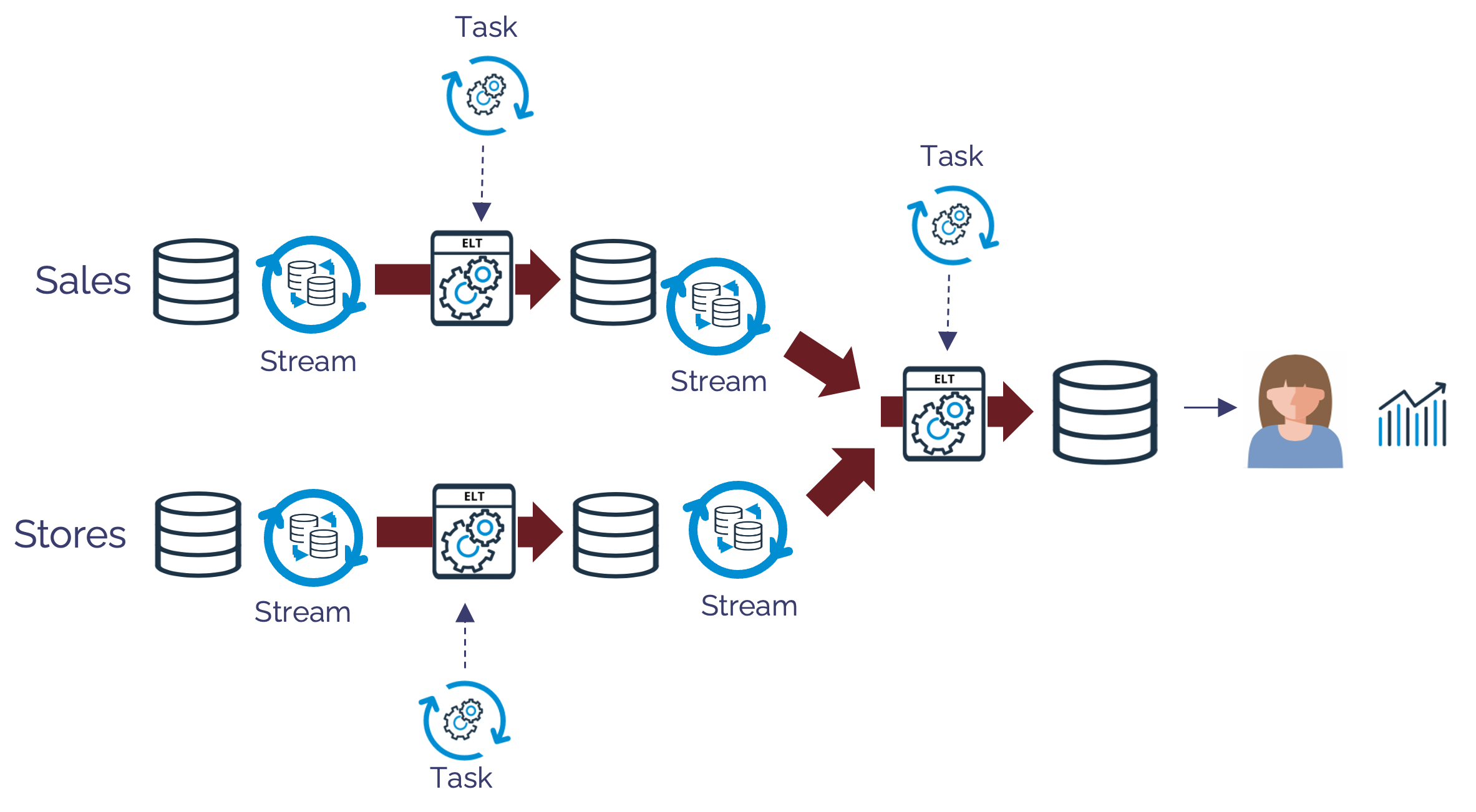
The diagram above shows how independently scheduled Tasks trigger ELT processes to process Sales and Stores data, which are combined to produce results for end-user queries. Each ELT procedure fetches data from a Snowflake Stream, which returns the changed rows and a merge statement is used to update the downstream table.
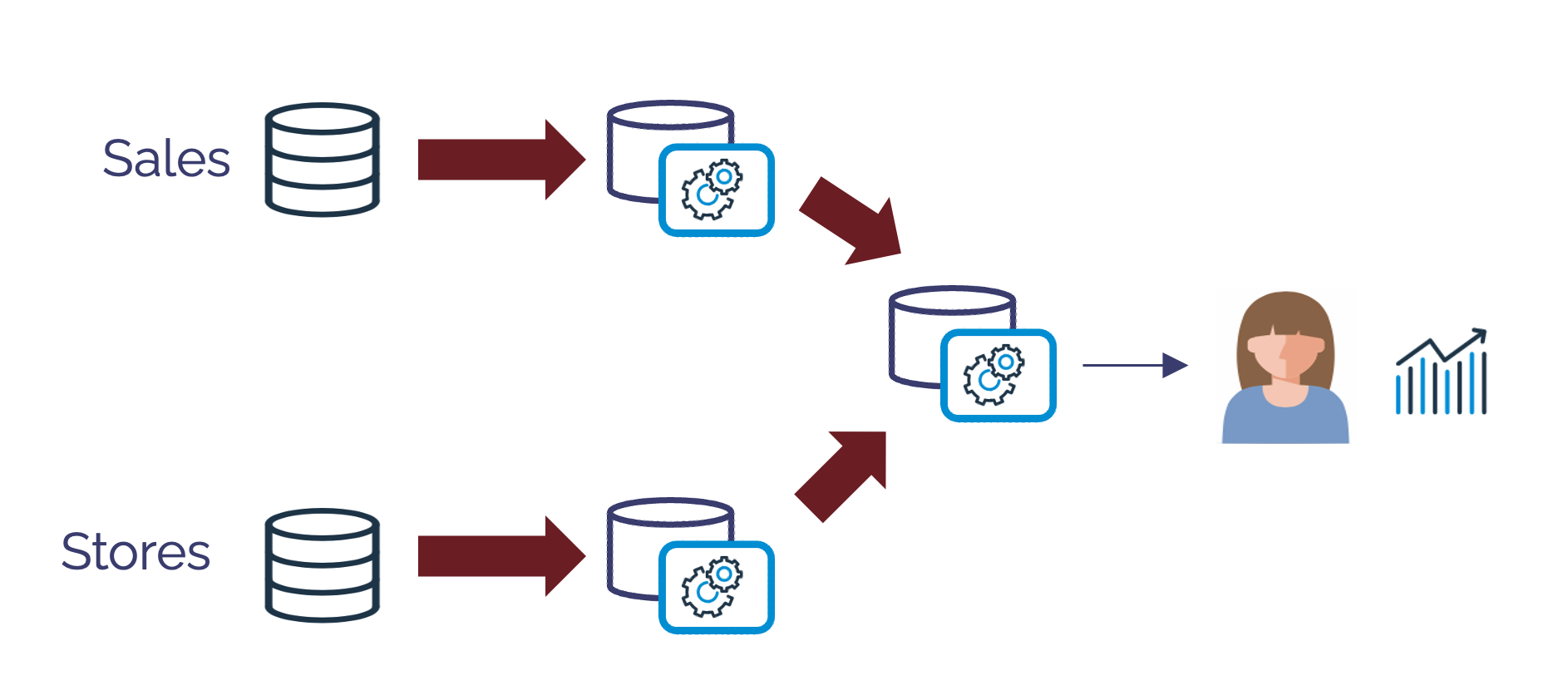
The diagram below shows how Dynamic Tables helps reduce the moving parts to just three simple SQL statements, which combine the logic, scheduling, and change data capture in a single operation.
Snowflake Dynamic Tables: What Problems Are We Trying to Solve?
As Data Engineers building ELT pipelines, we face several challenges, including:
Dependent Data: When combining transactions and reference data, we must load the reference data before transforming transactions. For example, we need to load changes to
STORESdata before processingSALES.Error Handling: The solution must include checks to ensure an error in the pipeline prevents further processing and potential downstream data corruption.
Change Data Capture: As data volumes grow, reprocessing the entire data set is no longer feasible, and the solution must identify and apply row changes to upstream tables.
Complex Merge Code: In addition to identifying changed rows, we need to build potentially complex
mergestatements to apply row changes.Batch Scheduling: Data pipelines need to be triggered regularly. As the pipeline grows, this adds complexity, as different tables need to be refreshed at other times.
In conclusion, rather than a single problem, ELT pipelines contain many challenges that can lead to highly complex and hard-to-maintain systems.
Create Dynamic Table in Snowflake
Unlike a standard table, which includes the column definitions, a Dynamic Table consists of an SQL statement that determines the structure (the columns, names, and definitions) and the content—the end state of the table. The header definition also indicates how frequently the data must be refreshed (the target_lag) and whether the table should be refreshed in FULL or by applying INCREMENTAL changes.
The SQL statement below shows an example of the definition of Dynamic Table.
create dynamic table dt_sales_aggregate
target_lag = "1 day"
warehouse = sales_wh
refresh_mode = full
as
select s.sale_date,
st.region
sum(s.amount)
from sales s
join stores st
on s.store_id = st.store_id;
The key points to note include:
TARGET_LAG: Defines the refresh frequency. This indicates how soon underlying table changes must be applied to the dynamic table. For example, a
TARGET_LAGof one day means the table should be refreshed daily.REFRESH_MODE: This option includes
FULL,INCREMENTAL, andAUTO. AFULLrefresh rebuilds the target table contents each time, which may be sensible for aggregate tables.INCREMENTALis better when changes impact a small percentage of the target table.WAREHOUSE: Indicates which Virtual Warehouse the SQL statement should be executed on. Given the query complexity and data volumes processed, selecting an appropriate warehouse size is essential. For example, a query that sorts large data volumes may need a larger warehouse.
Select Statement: This sets the target table's columns, data types, and data contents. Notice we don't need a
mergeorinsert overwritestatement. Snowflake generates the code required to keep this up to date as the source tables are updated.
What is Dynamic Table Refresh Mode?
The diagram below illustrates how each Dynamic Table can have a different REFRESH_MODE.
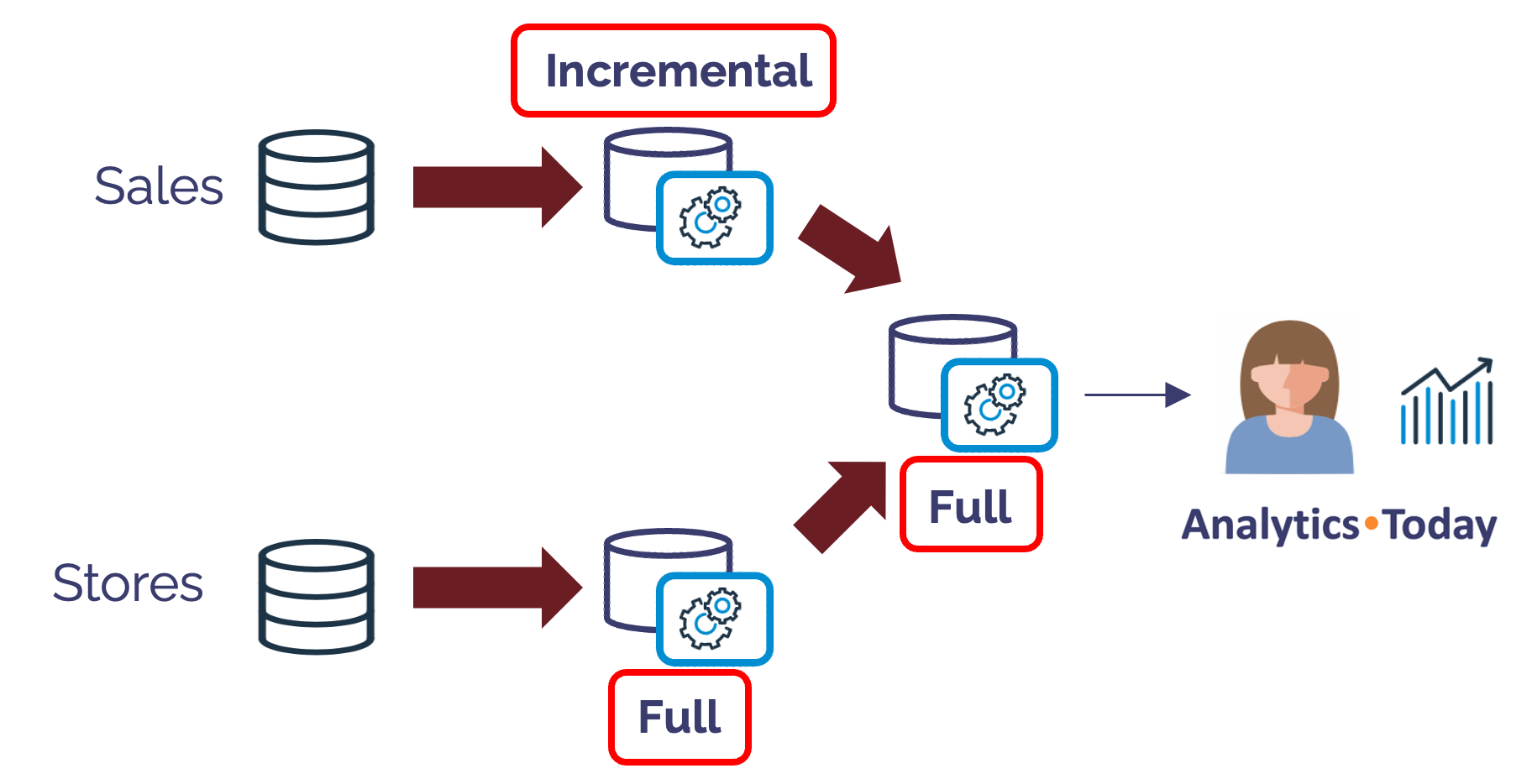
In the above example, newly arrived sale transactions are loaded to the SALES table, meaning the Dynamic Table can efficiently apply those changes incrementally. However, assuming the STORES table has fewer rows and is reloaded from the source system each time, it makes more sense to perform a FULL refresh.
The final Dynamic Table joins the results of the previous two tables. As it produces an aggregate table, we decided to use a FULL refresh as changes will likely impact all micro-partitions.
What is the Dynamic Table Target Lag?
The TARGET_LAG defines how frequently the Dynamic Table should be refreshed. This implies an acceptable time for the data to age before it's refreshed with new results.
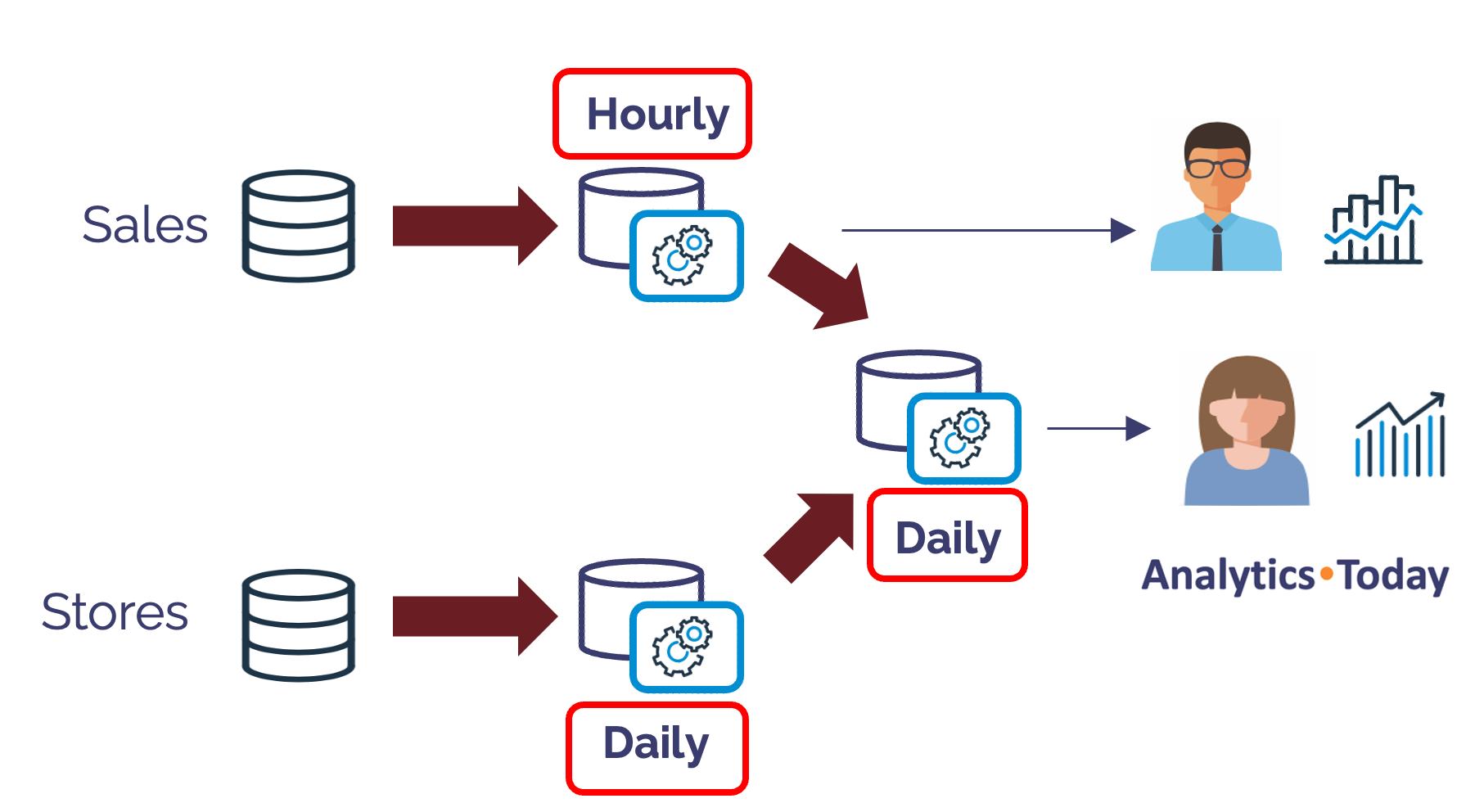
The diagram above illustrates how Snowflake simplifies the task of defining different refresh schedules for several tables in an overall ELT pipeline. It shows the SALES data is refreshed every hour, whereas the STORES data is only refreshed daily.

What is a Dynamic Table Downstream Target Lag?
The following SQL statement alters the TARGET_LAG on the aggregate table from once per day to once every five minutes.
alter dynamic table dt_sales_aggregate
set target_lag = '5 minutes';
However, the aggregate table refresh won't work as expected since the upstream tables are refreshed once per hour and once per day, respectively. We can use the DOWNSTREAM option to simplify this situation, and the diagram below illustrates how this works.
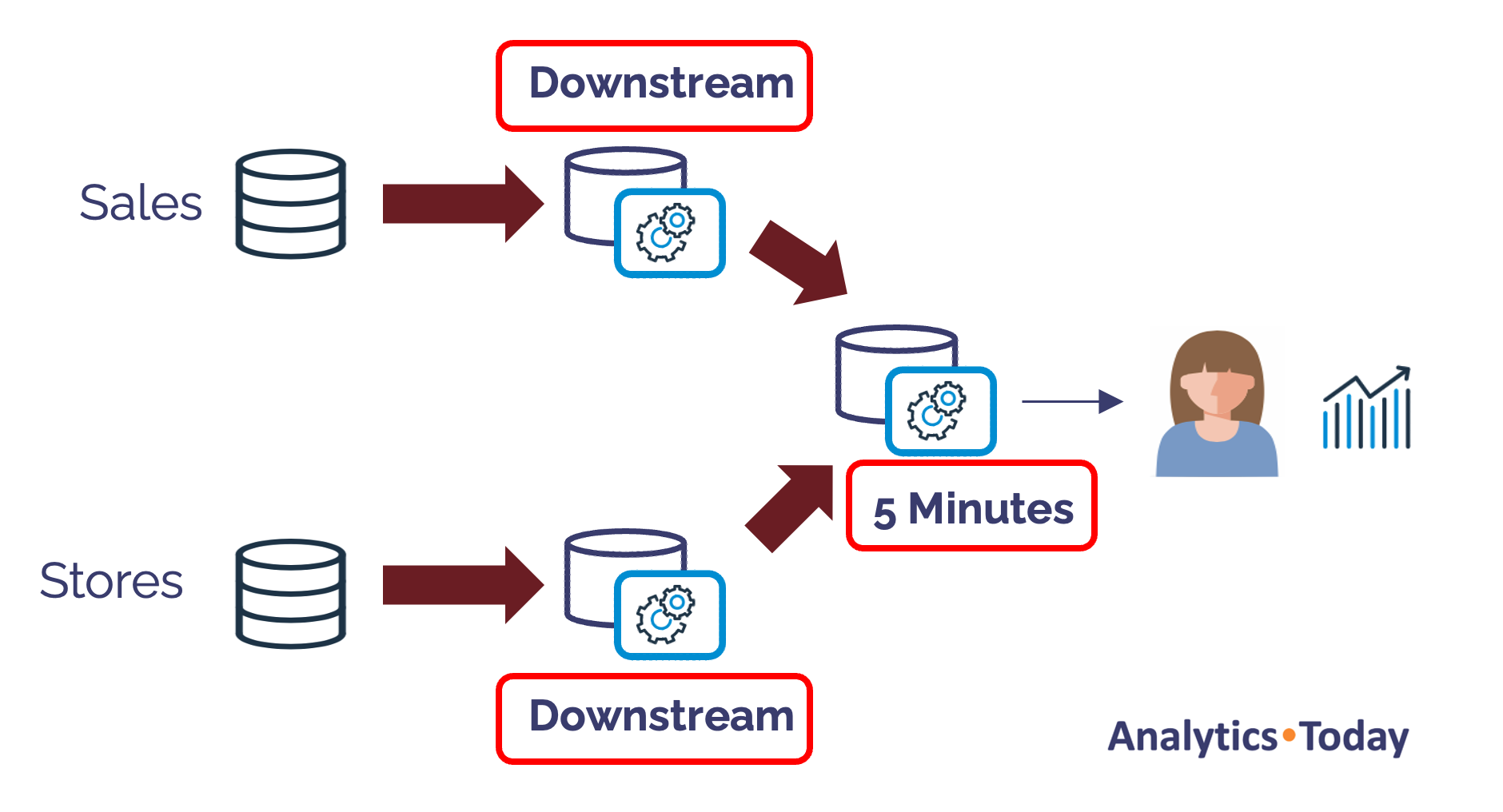
The diagram above shows how the DOWNSTREAM option determines the refresh frequency based on the downstream TARGET_LAG.
In the above example, the DT_SALES_AGGREGATE table determines the dynamic table TARGET_LAG for its feeder tables marked DOWNSTREAM. If, for example, the aggregate table were refreshed every hour, the upstream table lag would change likewise.
This feature is helpful because system administrators can adjust the TARGET_LAG as required. For example, executing a refresh every few minutes during peak periods but reduced to once per hour when not needed. This can significantly reduce the cost for incremental ELT pipelines as data is refreshed less frequently when it's not required.
Dynamic Table Limitations
At the time of writing, there are several limitations around Dynamic Tables, including general limitations like the inability to truncate a dynamic table or set the Data Retention Time to zero. There are also limitations on supported Query Constructs, and although non-deterministic functions are not supported using an INCREMENTAL refresh, some functions are supported using a FULL refresh.
Many of these limitations will likely change over time, so it's worth checking the Snowflake Documentation before deployment.
How to monitor Dynamic Table Status?
The screenshot below shows how to monitor Dynamic Tables using Snowsight. Click on Monitoring and Dynamic Tables to list the current status.
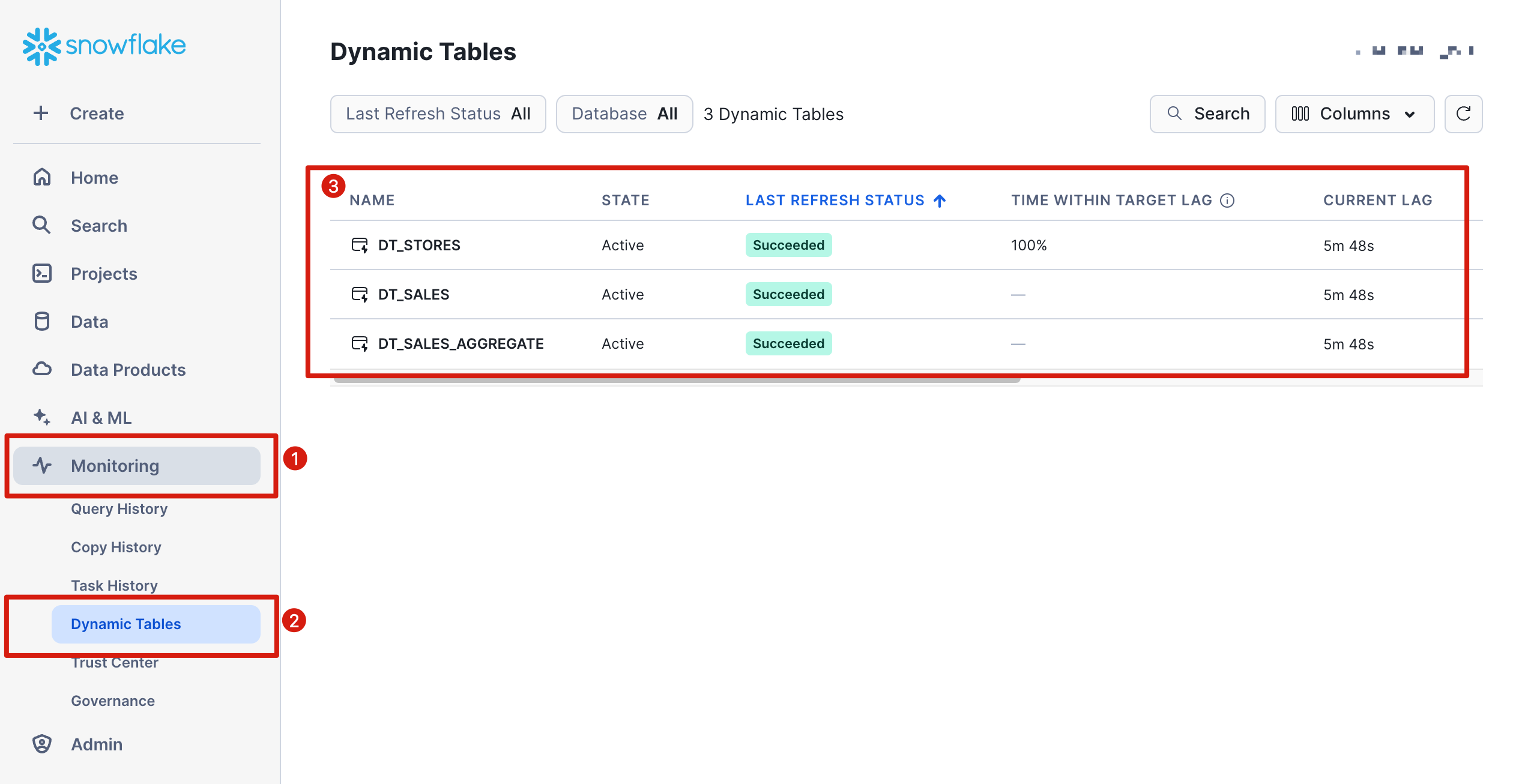
The options include viewing the table details, previewing the data, and viewing the refresh history. The screenshot below illustrates the overall ELT pipeline, including each Dynamic Table's status.
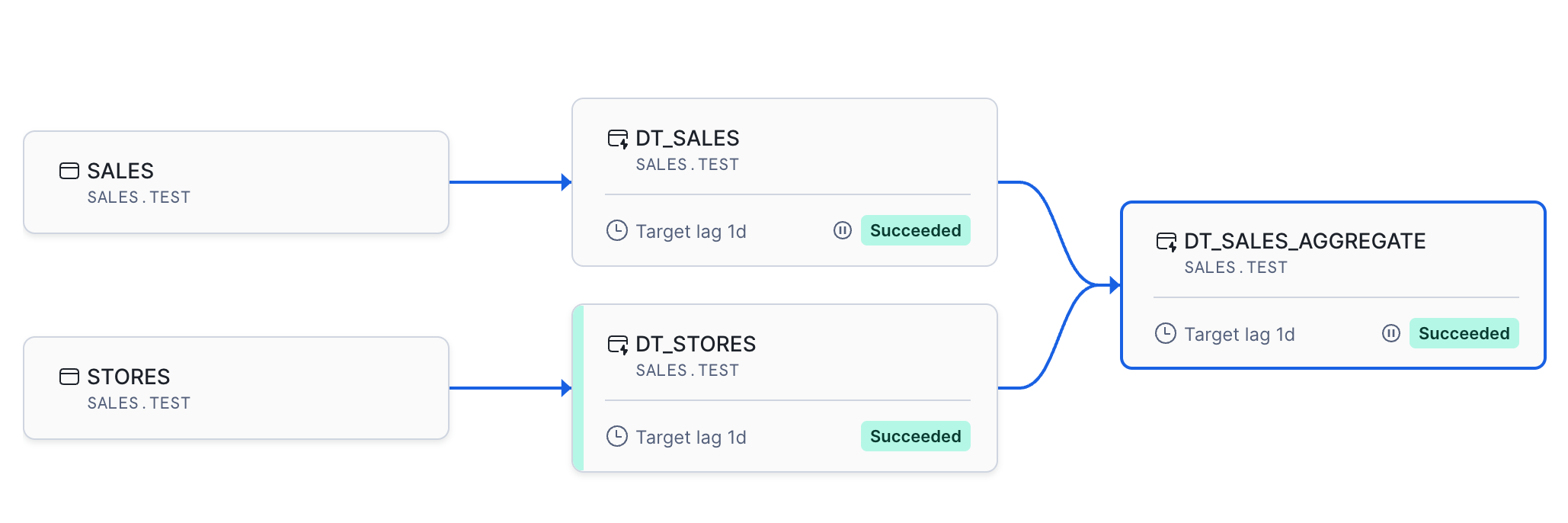
Dynamic Tables Vs. Materialized Views
While they may appear similar, Dynamic Tables and Materialized Views have significant differences and target different use cases.
Use-Case: Dynamic Tables are designed to simplify the process of building ELT data processing pipelines with many dependencies, whereas Materialized Views are designed primarily to maintain aggregate tables.
Query Complexity: Dynamic Tables support most SQL constructs, including JOIN and UNION operations, whereas Materialized Views can only fetch data from a single table.
Refresh Schedule: Dynamic Tables support periodic refreshes based on a TARGET_LAG, whereas Materialized Views always present consistent results from the underlying feeder tables.
Refresh Mode: Dynamic tables support a FULL or INCREMENTAL refresh method, whereas Materialized Views only support an incremental background refresh method.
As you can see from the above, while there are some similarities between Dynamic Tables and Materialized Views (for example, they both materialize the results of a query), they have distinct differences and use cases.
Dynamic Tables Vs. Streams
Dynamic Tables and Streams effectively target the same use case - to implement batch or real-time ELT data transformation pipelines. There are, however, distinct differences between the two solutions, including:
Simplicity: Dynamic Tables deliver a simpler solution to managing schedules, dependencies, and refresh mode than Streams and Tasks. Using the simple example above, Dynamic Tables could maintain five tables with just five objects, while streams and tasks needed fifteen.
Flexibility: Streams and Tasks are potentially more flexible in that they can independently process INSERT, UPDATE, and DELETE operations and separately manage the before-and-after image of UPDATE operations, which is useful when producing Type 2 Slowly Changing Dimensions.
Performance: While the query performance of Dynamic Tables and data maintained by Streams is similar, Streams can ignore UPDATE or DELETE operations with the Append Only option. This gives Streams a potential performance advantage over Dynamic Tables during incremental processing.
Conclusion
"If the only tool you have is a hammer, you tend to see every problem as a nail" - Abraham Maslow.
Snowflake Dynamic Tables can potentially become the standard method for building and deploying ELT pipelines. They simplify identifying and applying row changes and managing potentially complex dependencies in pipelines with different refresh frequencies.
However, you mustn't write off Snowflake Streams as an alternative approach. It provides more flexibility, such as limiting change data capture to append or insert only to detect when new rows are added. Finally, the SQL CHANGES clause delivers even more flexibility, including the ability to re-process data by detecting transactional changes between two timestamps.
It's also worth noting that Dynamic Tables currently need a Virtual Warehouse to execute the refresh operation. In contrast, Tasks can be executed using a serverless process with a 10% discount, which can reduce processing costs compared to Dynamic Tables.
Finally, to avoid excessive costs, you should be careful when deploying the refresh mode, target lag, and warehouse size.
If you find this article helpful, sign up for my newsletter, and I'll send you the second article in the series on Dynamic Tables, which will discuss best practices for Dynamic Table deployment.

Takeaways
Dynamic Tables simplify ELT pipelines: They combine scheduling, change data capture, and table refresh into a single object — reducing pipeline complexity.
Support complex SQL: Dynamic Tables handle complex queries, including JOINs and UNIONs — unlike Materialized Views.
Automatic Change Data Capture: No need to write separate merge logic — Snowflake manages updates automatically.
Flexible refresh options: Use TARGET_LAG to control how frequently data is refreshed. Combine with REFRESH_MODE (FULL, INCREMENTAL, or AUTO) for fine-grained control.
Manage dependencies easily: The DOWNSTREAM option lets you align refresh schedules across pipelines — ideal for tuning cost vs. freshness.
Warehouse considerations: Dynamic Tables run on a Virtual Warehouse (no serverless option yet) — size your warehouse carefully to balance cost and performance.
Complement, not replace Streams: Streams remain more flexible for handling before/after images or append-only processing — ideal for Slowly Changing Dimensions (SCD2).
Monitor with Snowsight: Dynamic Table status and refresh history are easy to track and manage in the UI.
Still evolving: Some limitations remain (non-deterministic functions, immutability of REFRESH_MODE), so check current documentation before full deployment.
Ideal for modern ELT: For many pipelines, Dynamic Tables will simplify and streamline processing compared to Streams and Tasks.
Subscribe to my newsletter
Read articles from John Ryan directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
John Ryan
John Ryan
After 30 years of experience building multi-terabyte data warehouse systems, I spent five years at Snowflake as a Senior Solution Architect, helping customers across Europe and the Middle East deliver lightning-fast insights from their data. In 2023, he joined Altimate.AI, which uses generative artificial intelligence to provide Snowflake performance and cost optimization insights and maximize customer return on investment. Certifications include Snowflake Data Superhero, Snowflake Subject Matter Expert, SnowPro Core, and SnowPro Advanced Architect.