Week 15: Lakehouse Architecture and Delta Engine 🏠
 Mehul Kansal
Mehul Kansal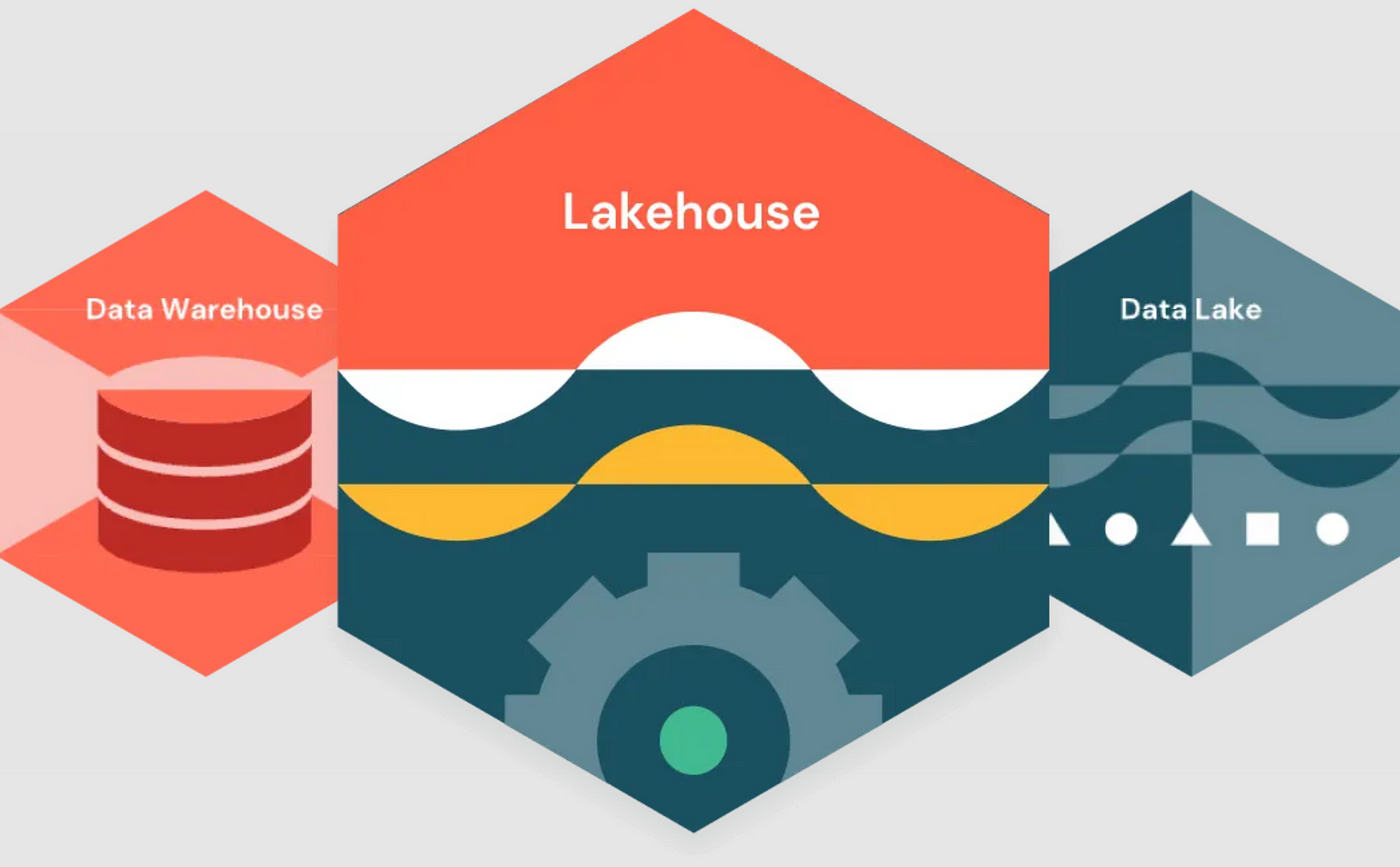
Hey data engineers! 👋
In this blog, we explore the Azure Lakehouse architecture, focusing on how Databricks Lakehouse integrates the benefits of data lakes and data warehouses. We'll dive into its core components, such as the storage layer, Delta Lake, and Delta Engine, and discuss key optimizations like data skipping, delta caching, and Z-ordering.
Lakehouse architecture
Conservatively, all the data was pushed to data lake in its raw form and a subset of this data was sent to data warehouse for reporting and business intelligence purposes.
This 2-tier architecture had disadvantages like data duplication, excessive ETL activities and inability to perform ACID transactions.
Lakehouse architecture solves these issues by providing the best of both data lake and data warehouse.
Databricks Lakehouse architecture
Databricks lakehouse consists of three components:
Storage layer: Comprises of Data lake technologies like AWS S3, ADLS Gen2, GCS, etc.
Transactional layer: Comprises of Delta lake that includes delta logs and commit logs.
Delta engine: Databricks' delta engine adds speed to the above layers through optimizations.
Delta Engine Optimizations
- Data skipping using stats
- Databricks provides us with some practice datasets. We will use 'nyctaxi' dataset.
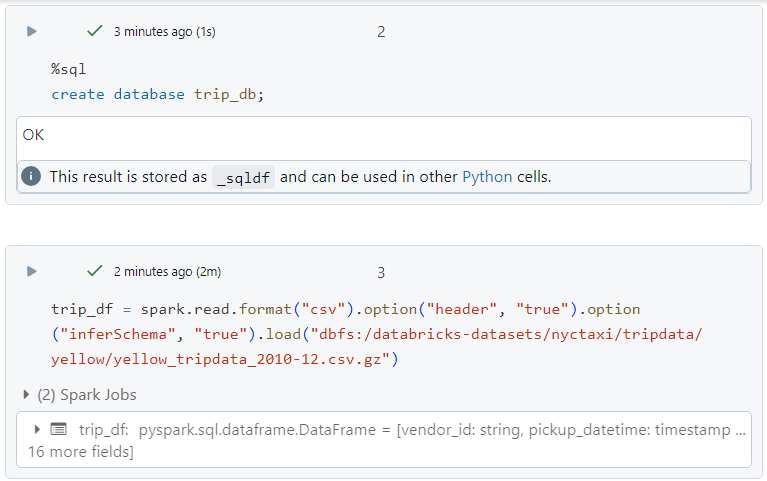
- We create a database and load the data into a dataframe - 'trip_df'.
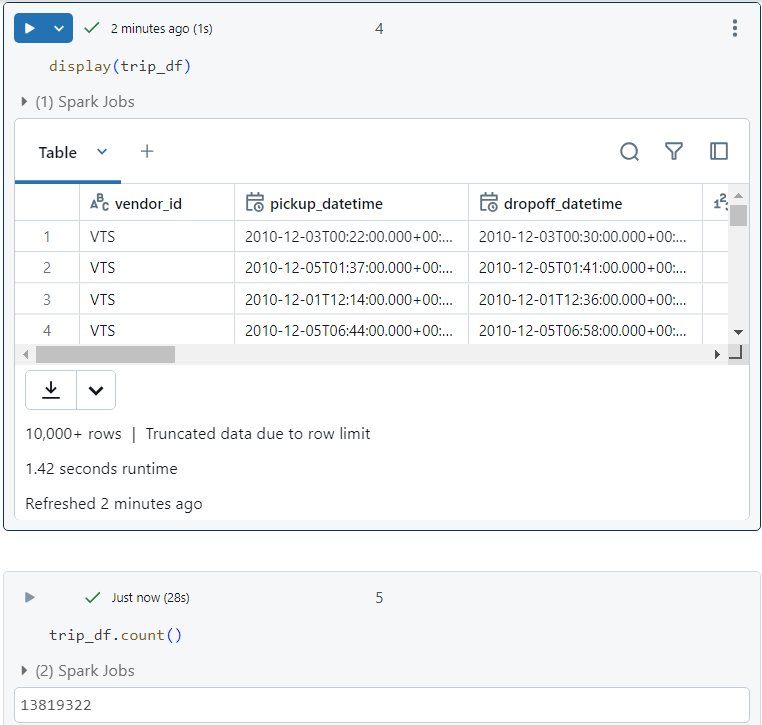
- The 'trip_df' looks as follows.
- We create a delta table 'trips_delta' and a parquet table 'trips_parquet' out of our dataframe.
- Inside Databricks File System (DBFS), the part files along with the delta log files for the delta table look as follows.
- The part files for the parquet table look as follows.
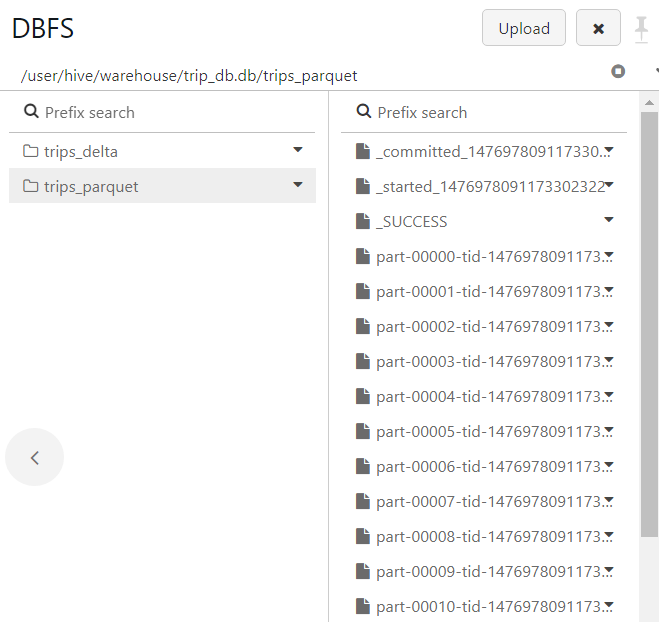
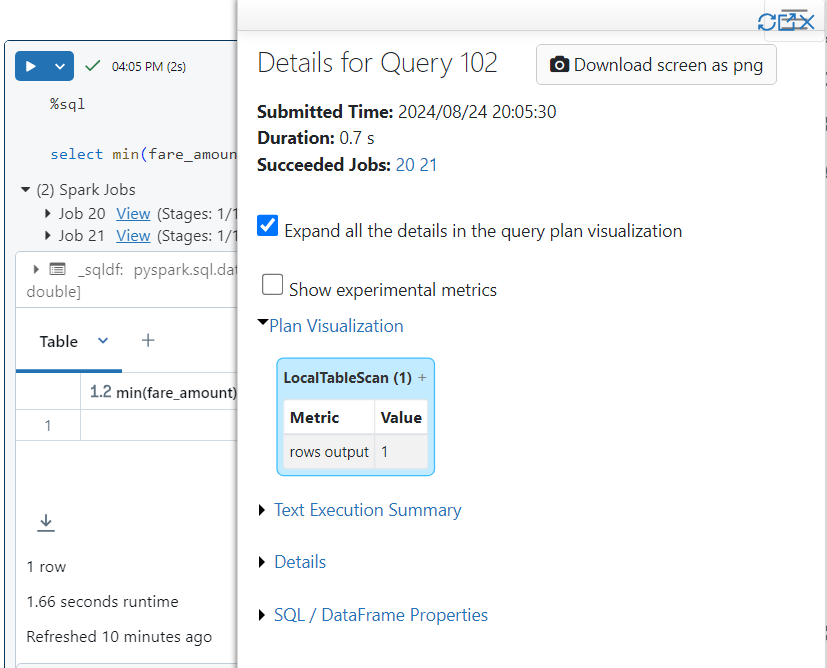
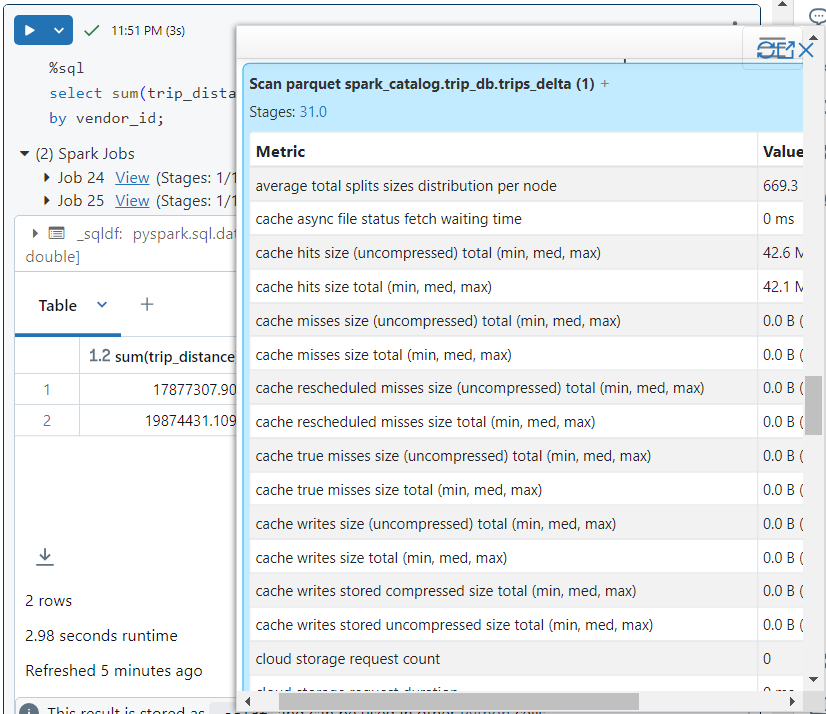
- In order to find the minimum and maximum values, we execute the following SQL command on our delta table first. It took 1.66 seconds.
- Upon observing the SQL query in detail, we find that no files were searched because the information about minimum and maximum values was taken directly from a specific file where the record falls. Hence, data was skipped using the stats in metadata.
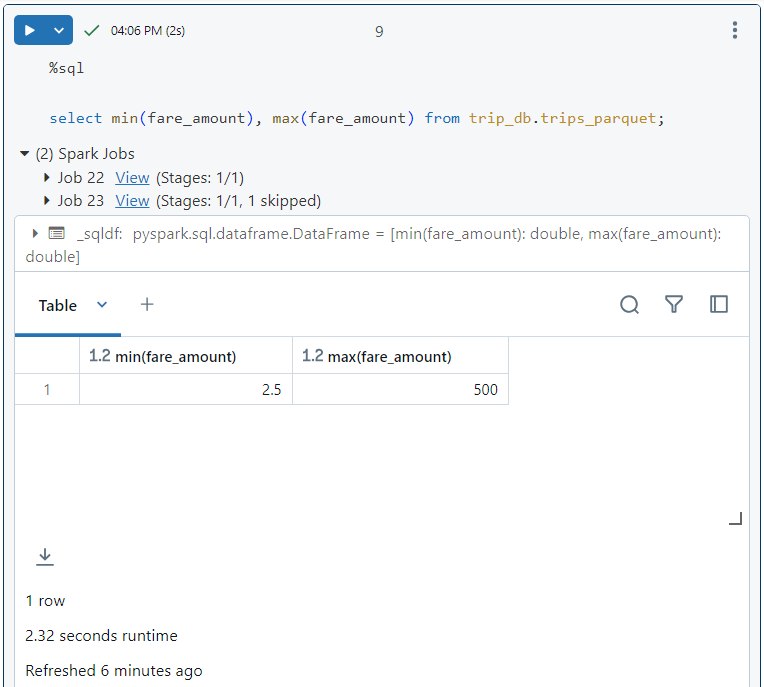
- Now, we execute the same SQL query on the parquet table. It took 2.32 seconds.
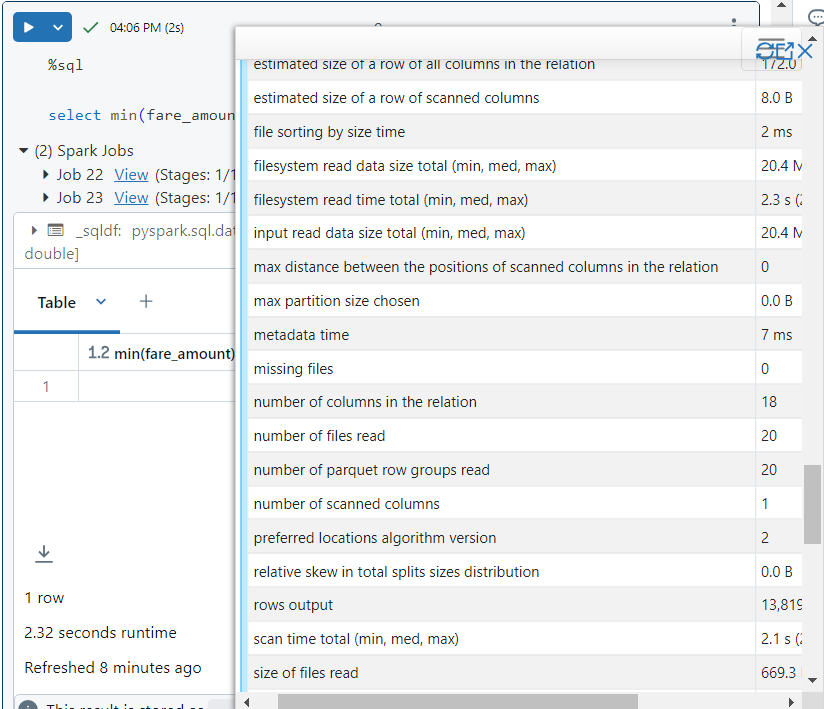
- If we look at the query execution plan, we observe that all the 20 part files were read for the execution of query. Hence, no data was skipped.
- Delta Cache
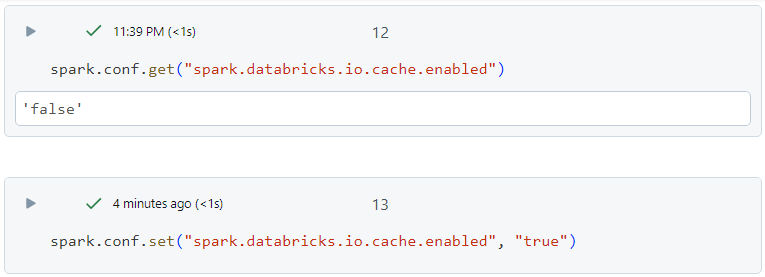
- In order to enable delta cache, we set the following property to true.
- In order to demonstrate the use of cache, we execute the following query. It takes 5.94 seconds to execute.
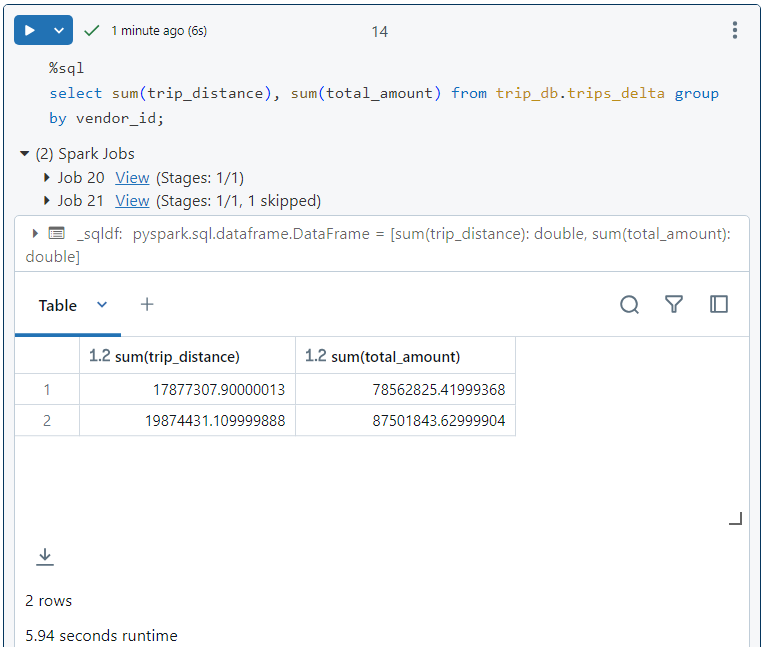
- When we look into the storage stats for the query, we see that cache hit percentage is 0% since nothing was stored in cache before query execution.
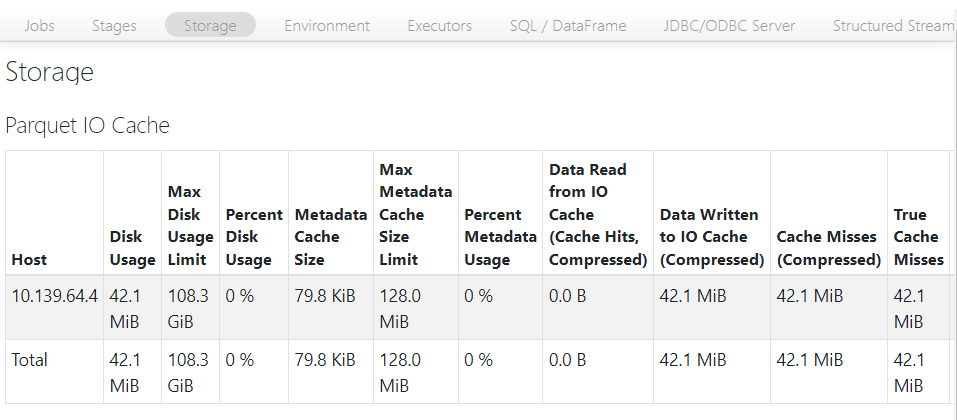
- To further confirm, we can see below that the size of cache hits is 0.0B.
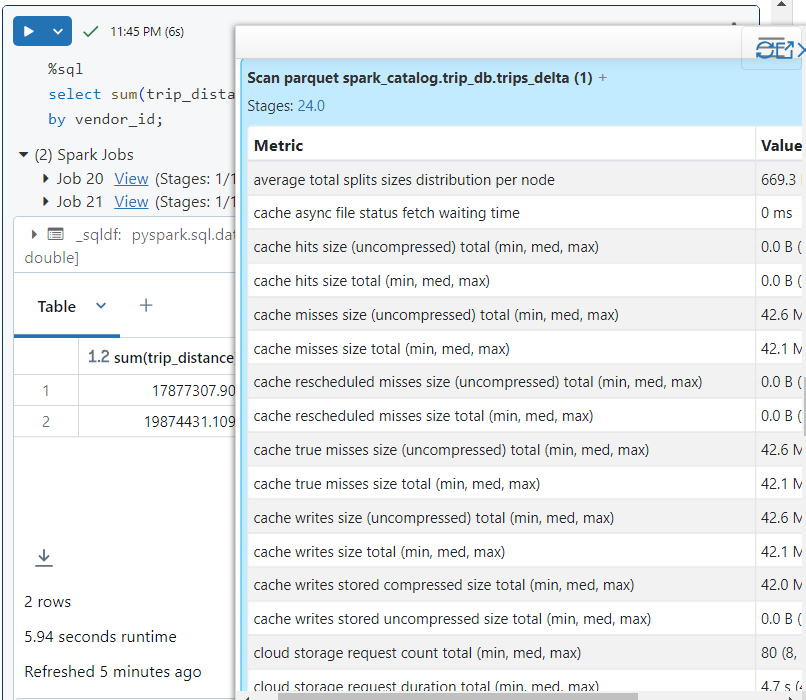
- Now, if we run the same query again, as follows. It took just 2.98 seconds.
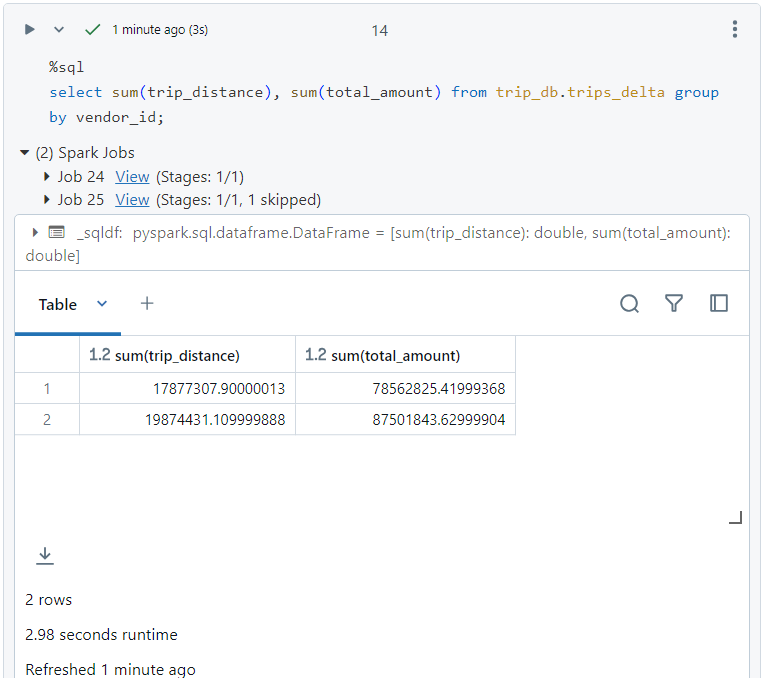
- Now, after the second run, the cache hit percentage has increased to 50%.
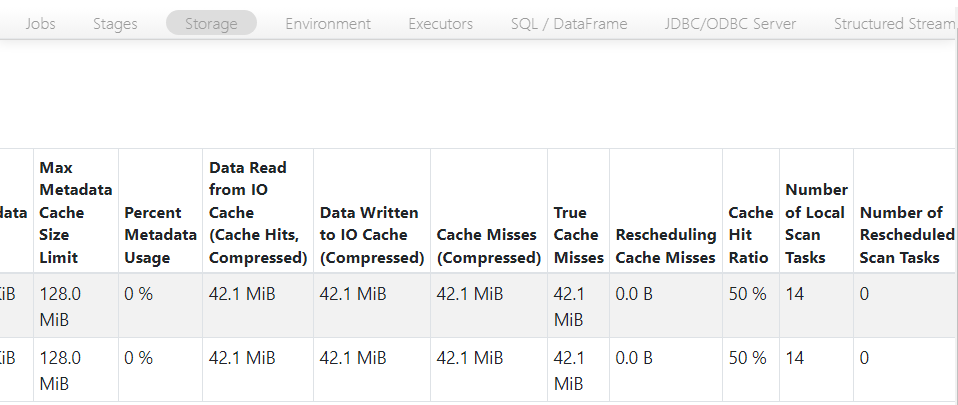
- For further confirmation, the cache hit size has now increased to 42.1 MB.
Small file problem
Consider two tables where table-1 has 10000 small files with 10 records each and table-2 has 4 big files with 25000 records each. If we have to run a query that has to open and search through all the files, then table-1 is less efficient as compared to table-2. The reason for this is that the overhead of opening all the files is high in table-1.
We use the same 'trip_df' dataframe for our demonstration.
- We create a delta table with 500 partitions, partitioned on 'vendor_name' column.
- Since we have 3 vendors in our data, 1500 files get created, with each partition containing 500 files.
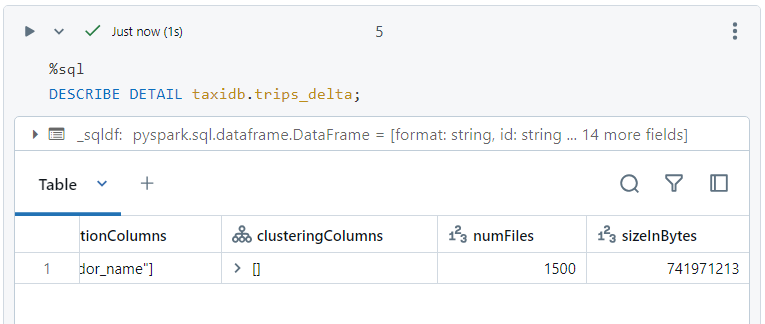
- We can see the files within each partition inside DBFS.
- We can also get the path to each part file.
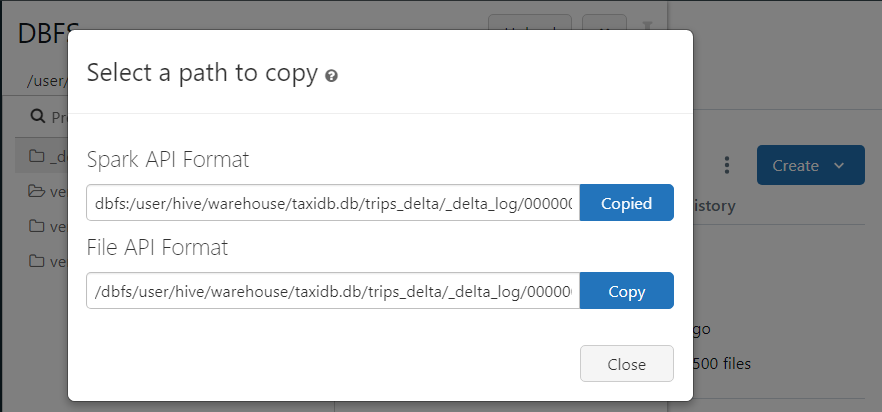
- When we examine the part file, we find all the metadata like minimum and maximum values.
- Now, we execute the following query and it takes as many as 26 seconds to run.
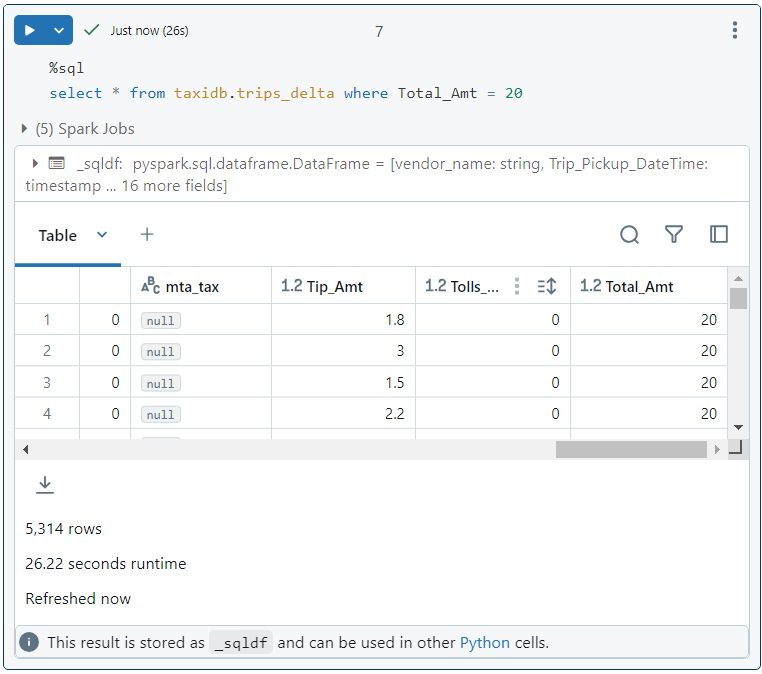
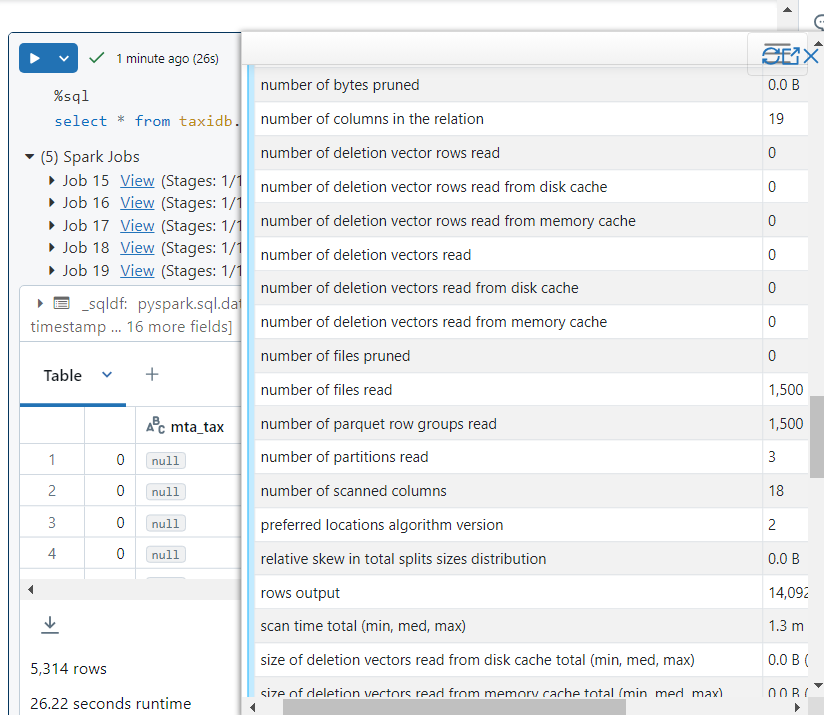
- If we look into the query details, we can confirm that 1500 files were searched, indeed.
Compaction/Bin-packing
In order to solve the small file problem, compaction/bin-packing is used that involves taking multiple small files and merging them into large files.
In Databricks, we use 'OPTIMIZE' command to compact delta files, having size around 1GB.
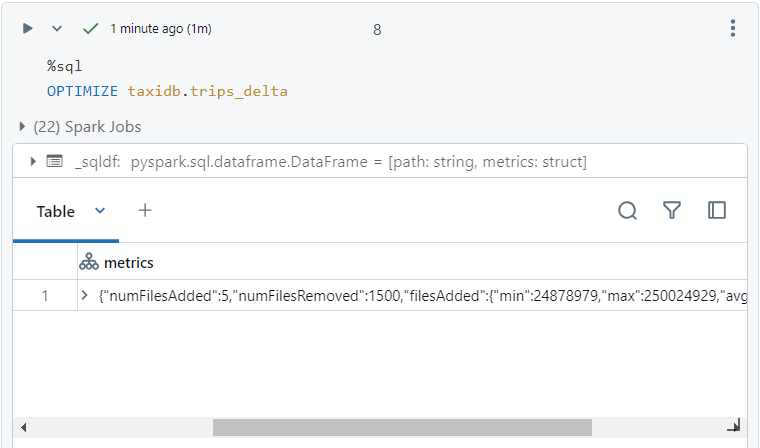
- Now, after compaction, if we run the same query again, it takes only 7 seconds.
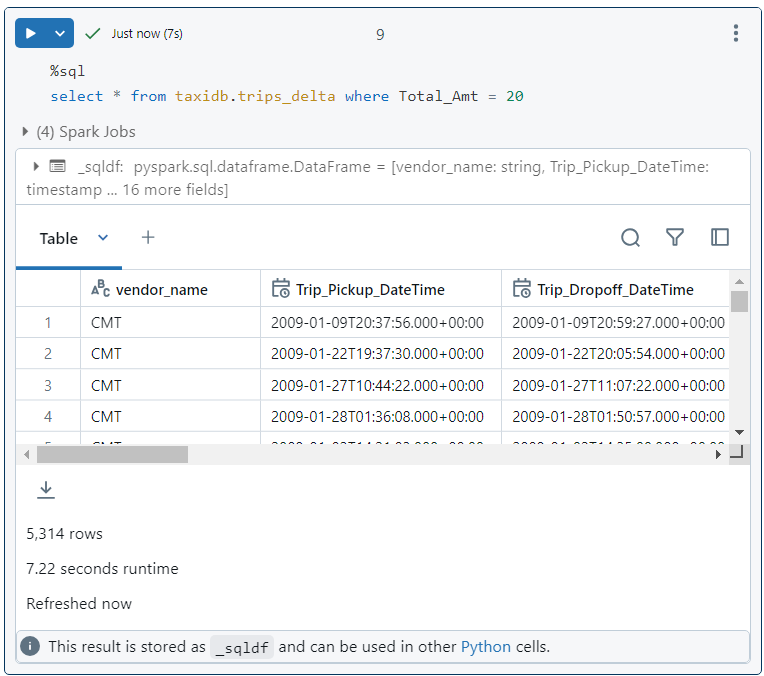
- Further, we can see that only 5 files were read during the query execution, indicating that 1500 files were compacted into just 5 files.
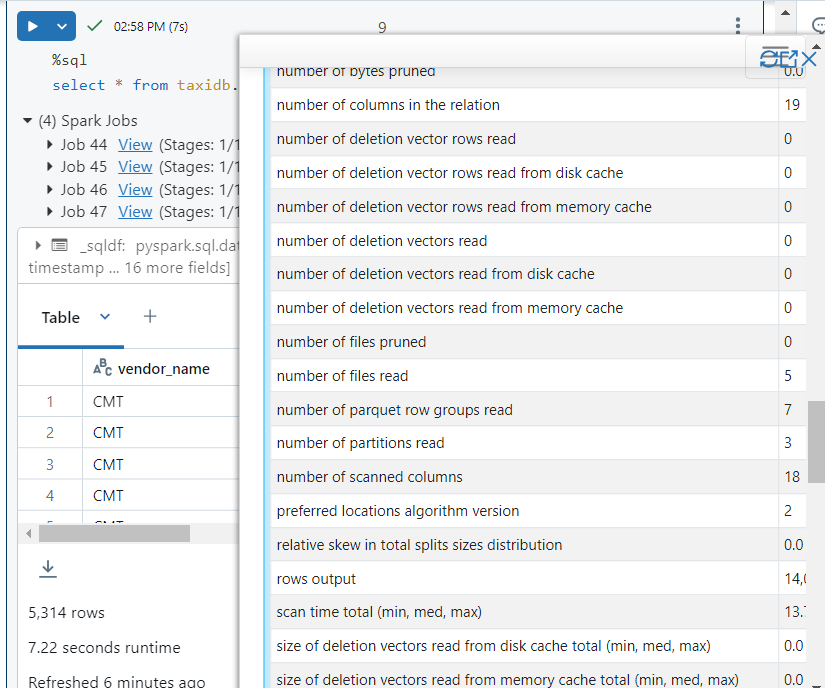
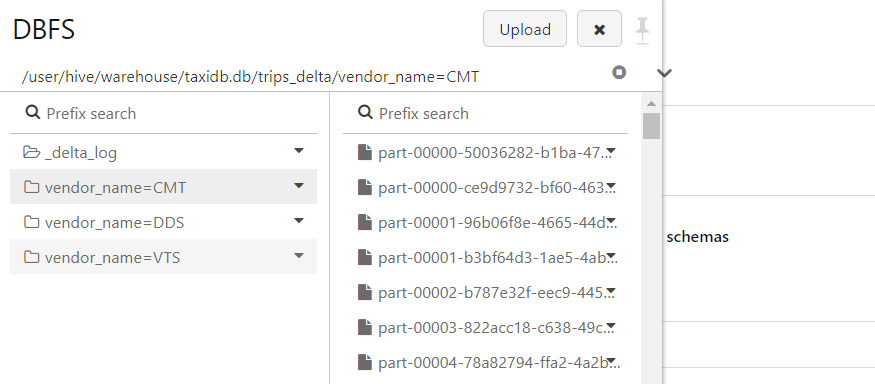
- In DBFS, although new files get added after compaction, previous files also get retained for maintaining version history.
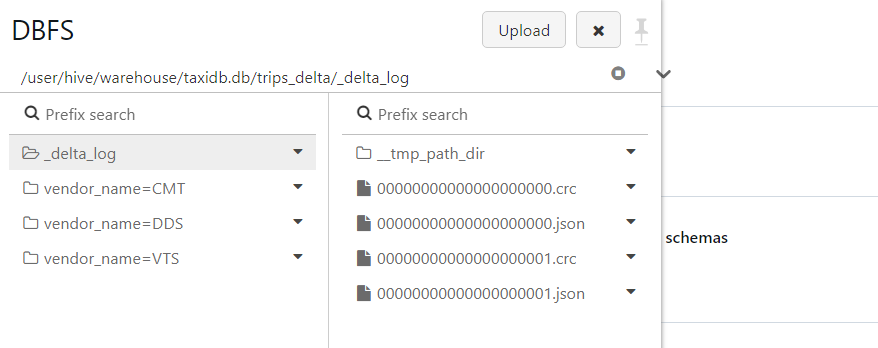
- In the delta log folder, a new log file gets added.
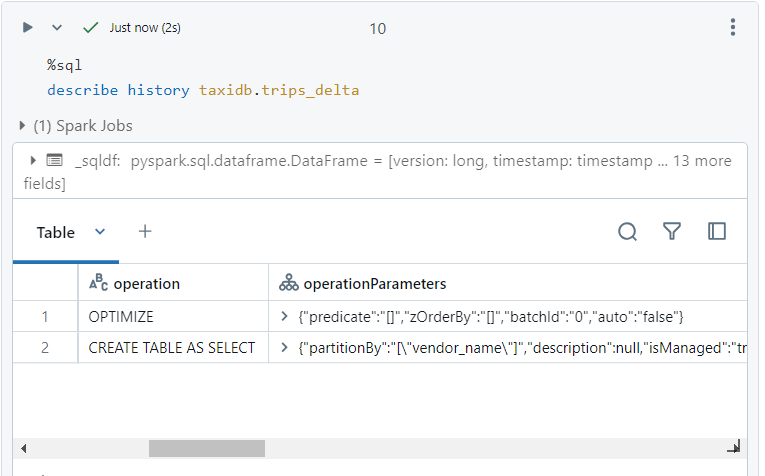
- If we look at the history of the delta table, we see the 'OPTIMIZE' operation as well.
Z-ordering
This technique involves sorting a particular column so that the data gets distributed in an effective way, thus enabling optimized data skipping.
In order to double the data, we run the following command two times. The number of files becomes 400.
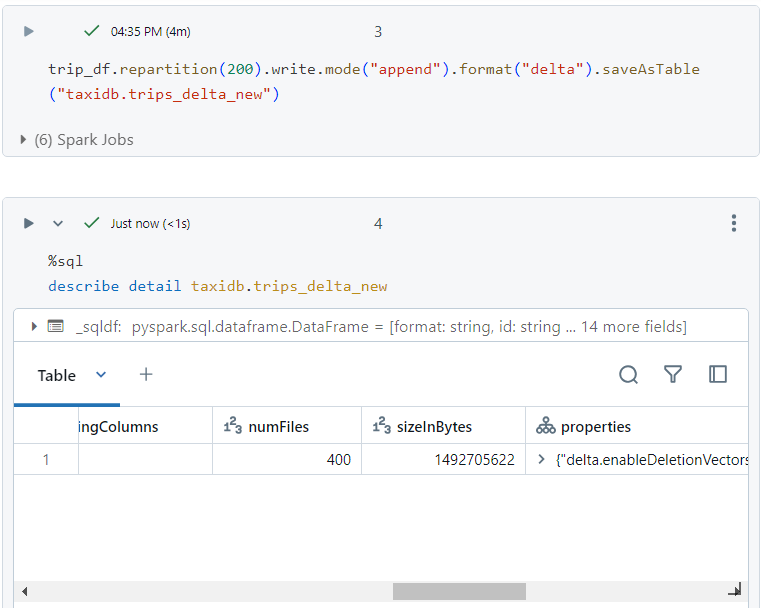
- We run the following SQL query.
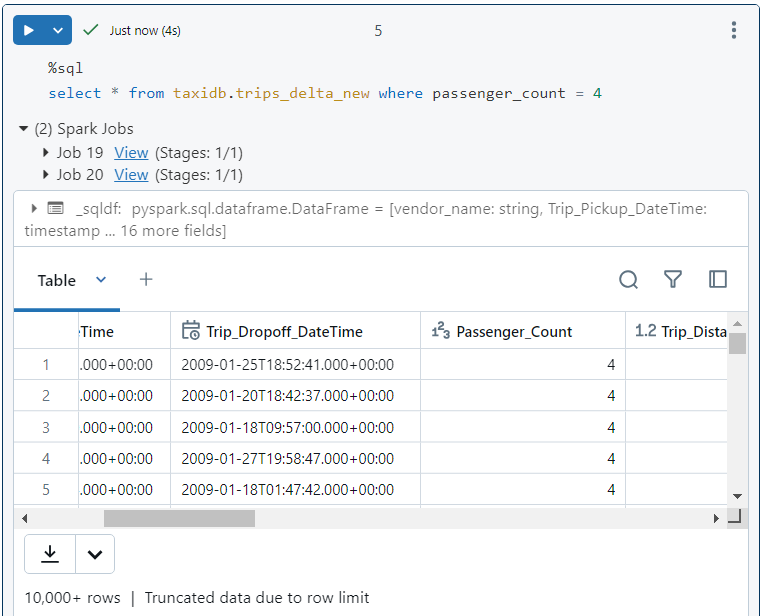
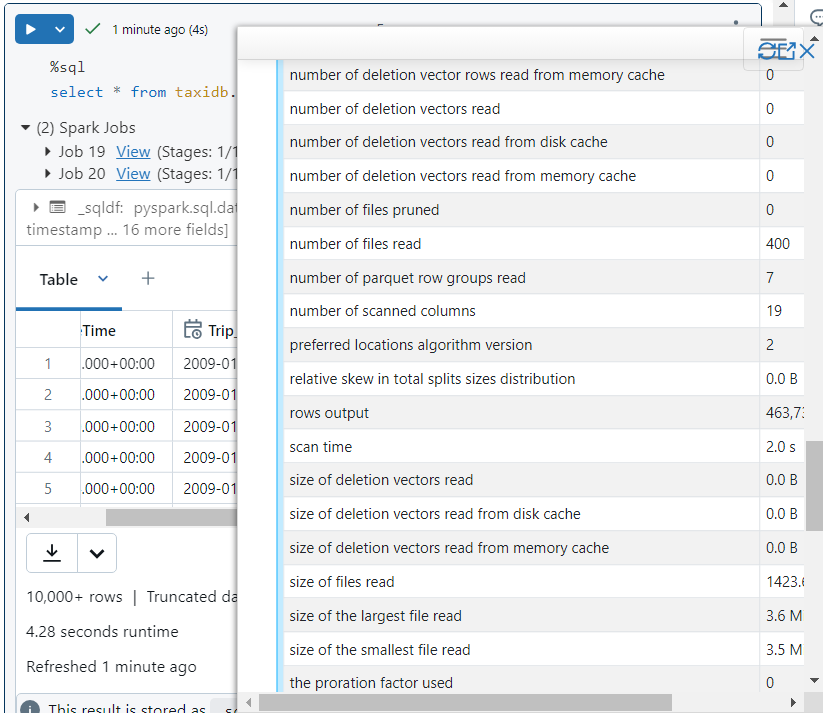
- Without optimization, all 400 files get read.
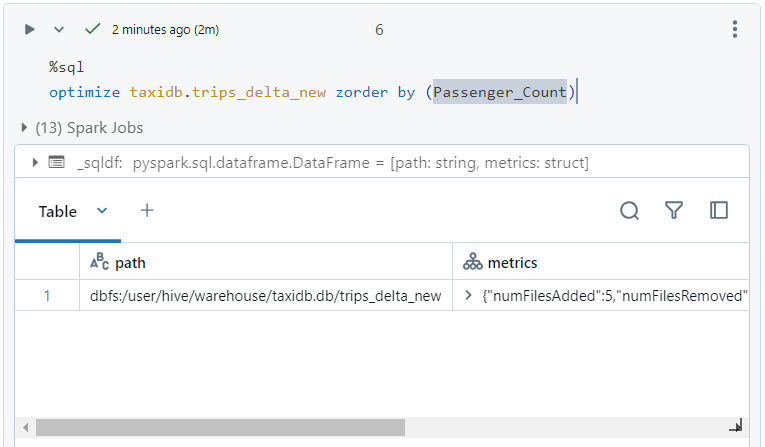
- Now, we perform optimization through z-ordering on 'passenger_count' column. It co-locates the related information.
- We perform the same SQL query again.
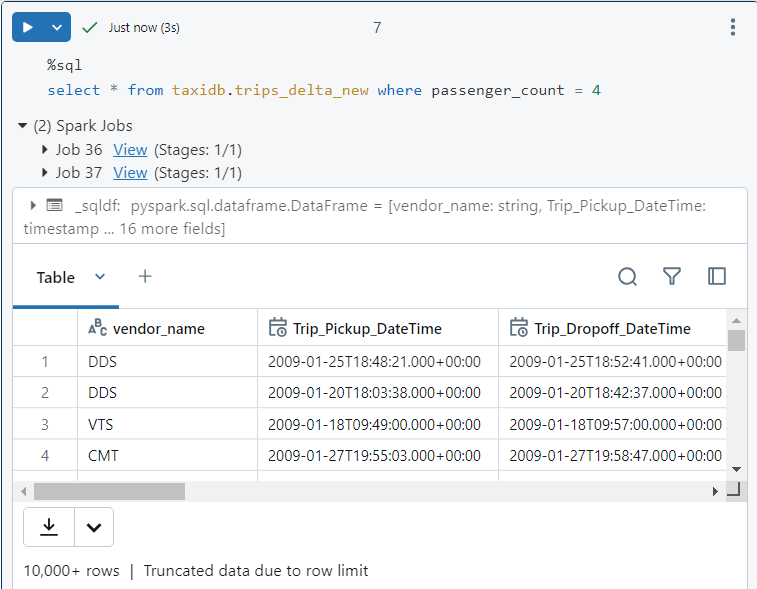
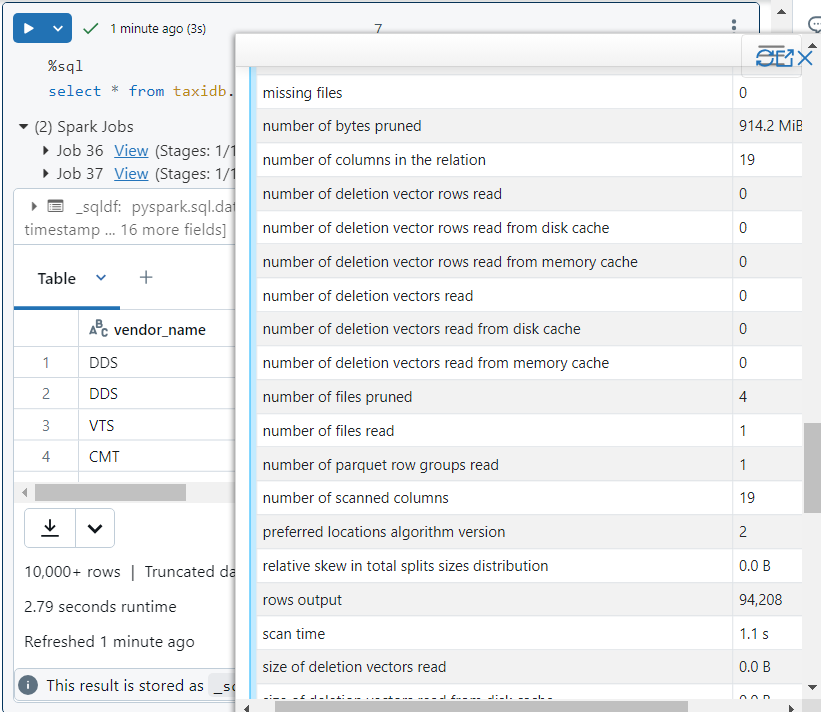
- In query execution details, we see that only 1 file is read and 4 files get pruned due to effective data skipping.
Vacuum command
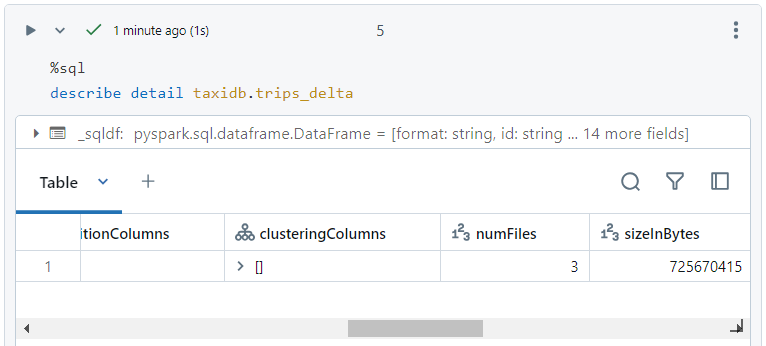
- At present, after optimizations, the number of files in the delta table is 3.
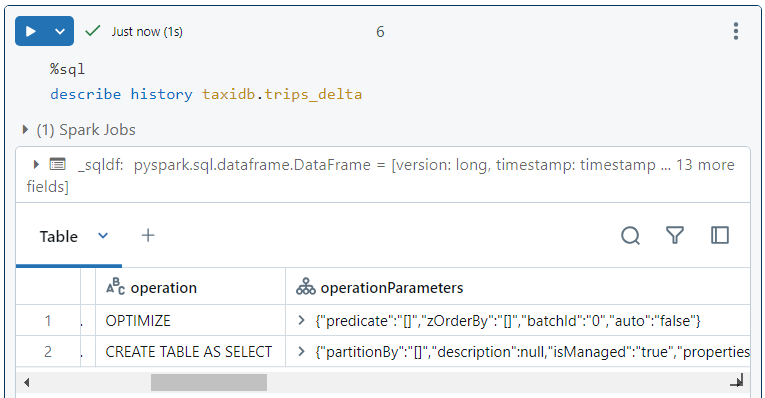
- We can confirm in version history as well that OPTIMIZE operation was indeed performed for compaction.
- But inside DBFS, the number of files is not 3, in order to support version history.
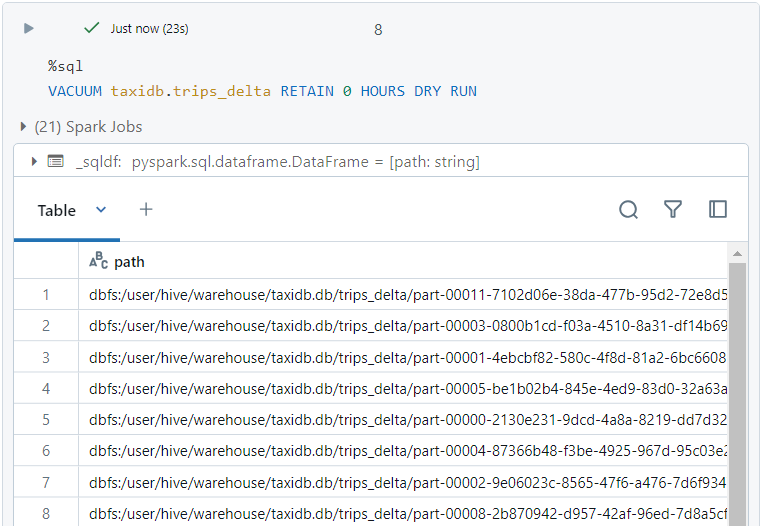
- Firstly, we can list all the files that will get deleted if we run the VACUUM command.
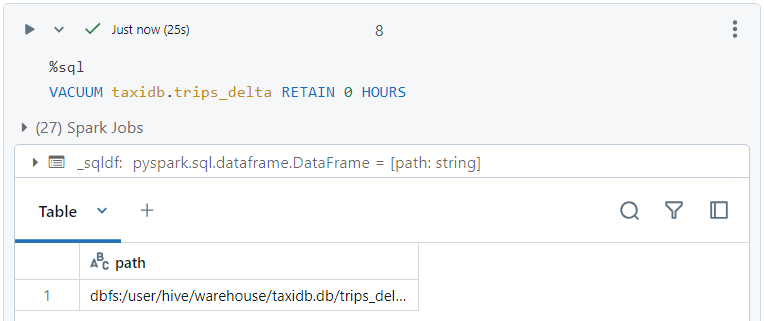
- Finally, we can delete the older files in the transaction logs that are not referenced anymore.
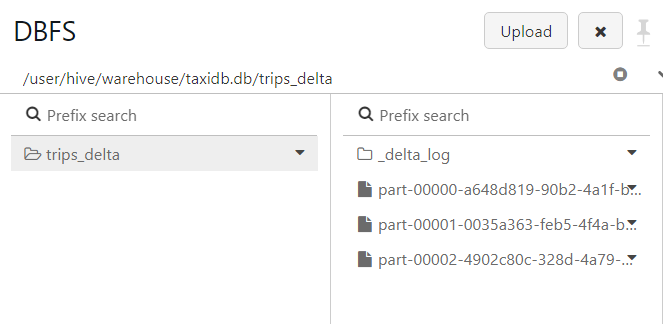
- Now, if we explore the DBFS, we see only the files that are being referenced.
- As caution, we should use VACUUM command only when version history is not required.
Delta architecture
There are three stages in Delta architecture, primarily:
Bronze layer: Contains raw data from various sources.
Silver layer: Contains preprocessed and cleaned data.
Gold layer: Contains transformed data optimized for reporting.
Change Data Feed
Change data feed helps in capturing inserts, updates, deletes and merges in the incremental data in delta/medallion architecture.
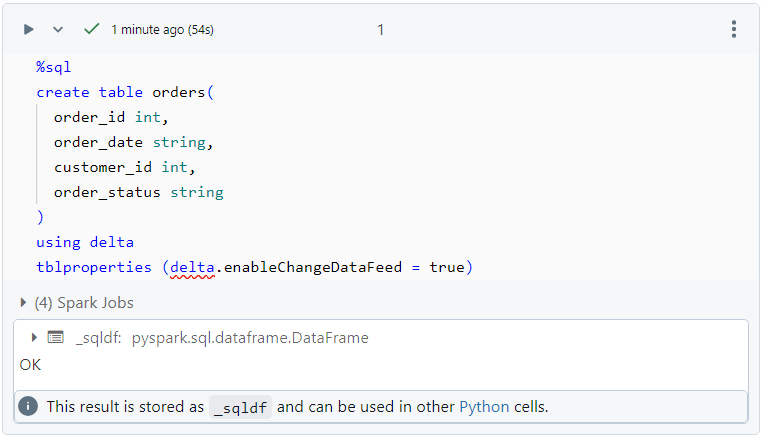
We create the following 'orders' table with change data feed enabled.
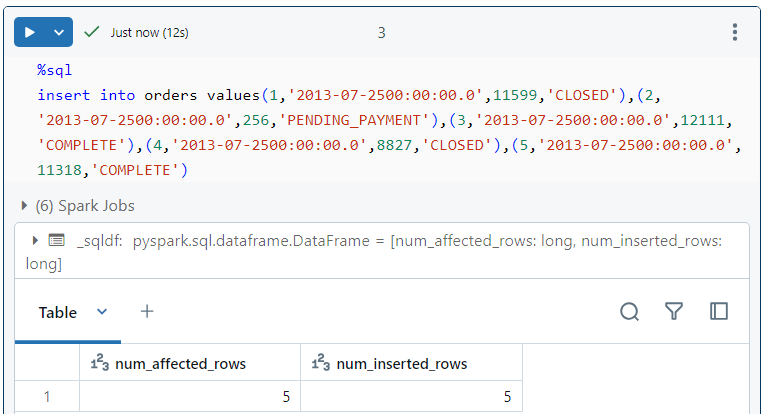
- We insert some data into the table.
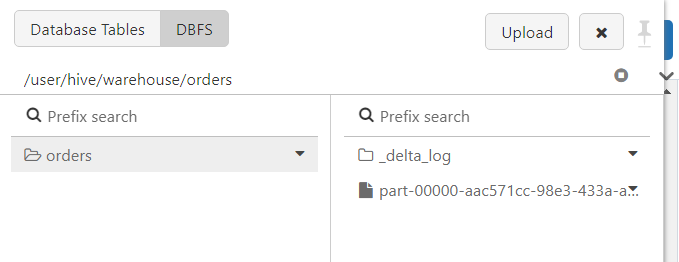
- At the moment, the DBFS looks as follows.
- The history of the table shows the following two versions.
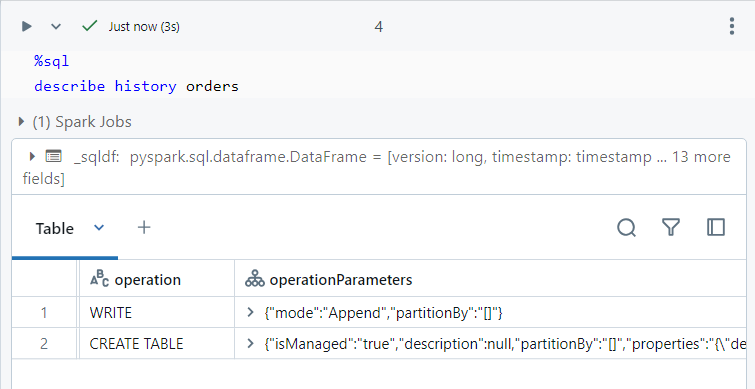
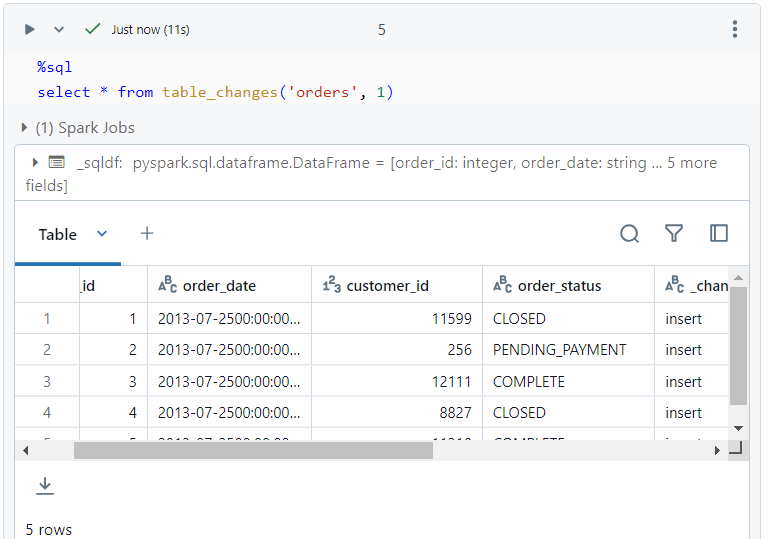
- Now, we perform a normal select query as follows, specifying the commit version as 1.
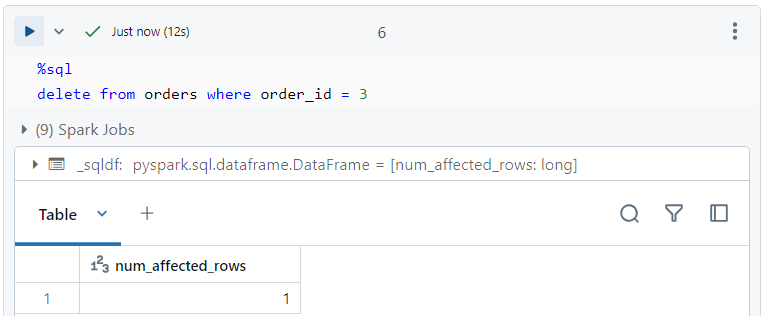
- The delete operation can be performed as follows.
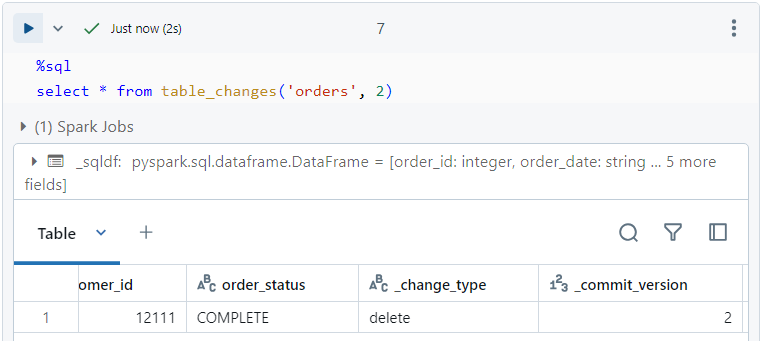
The record that gets deleted above, gets stored inside 'table_changes' table with a commit version of 2.
If we want to track the deleted record, we can perform a select query on 'table_changes' with commit version as 2.
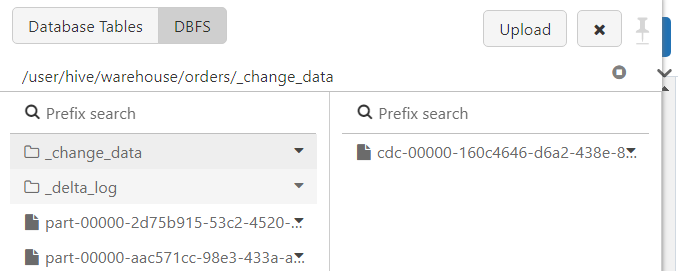
- The 'change_data' table can be seen inside the DBFS as well.
Conclusion
The Databricks Lakehouse architecture, with its robust components like the Delta Lake, Delta Engine, and advanced optimizations such as data skipping, delta cache, and Z-ordering, revolutionizes data management. It not only resolves the inefficiencies of the traditional two-tier architecture but also enhances query performance, scalability, and data reliability.
Stay tuned for more!
Subscribe to my newsletter
Read articles from Mehul Kansal directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by