Faster API Calls for DynamoDB in Python
 Aditya Dubey
Aditya Dubey
Introduction
Github: https://github.com/adityawdubey/Faster-API-Calls-for-DynamoDB-in-Python
With databases, how fast data operations work is important to overall performance — a point which matters even more when using cloud-based database technologies like Amazon DynamoDB. In this blog, we are going to go over different concurrency models and how it plays with DynamoDB put_item operation. I'll also provide some real world examples for when and why to use each concurrency mechanism.
We are not going to talk about AWS DynamoDB queries optimization. This blog is more concentrated experimenting with various concurrency methods on async and sync clients of DynamoDB as in how they perform different than each other.
However, before we get started with the experiment let's have a small introduction to synchronous and asynchronous programming.
In synchronous programming, tasks run one after the other. Each task waits for the previous one to finish before starting. This method ensures consistency because a task is only done when it gets a response. It's easier to implement and debug than asynchronous programming. But it has some downsides. Services are tightly linked, so a change in one can affect another. Also, if a service is slow or down, it can cause delays. Synchronous programming is best when you need an immediate response for the next step, like in database transactions or critical operations where consistency is key, and when services don't change often.
Understanding Concurrency
Concurrency means being able to manage multiple tasks at the same time, even if they don't happen exactly at the same moment. It lets tasks start, run, and finish in overlapping time frames. This is really important for apps that need to handle several operations at once without having to wait for each one to finish before starting the next.
In Python, we have several approaches to achieve concurrency:
threading
asyncio
multiprocessing
Each of these methods has its own strengths and is best suited for different types of tasks. They mainly differ in how they handle I/O-bound and CPU-bound processes.
I/O-Bound vs. CPU-Bound Tasks
I/O-Bound Tasks
These tasks are limited by input/output operations such as network requests, file operations, or database interactions. They spend a significant amount of time waiting for external resources.
Example: Downloading files from the internet or performing database read/write operations.
CPU-Bound Tasks
These tasks are constrained by the processing power of the CPU. They involve heavy computations and data processing.
Example: Complex mathematical calculations or large-scale data processing.
One of the main benefits of writing asynchronous code is to optimize resource usage. Operations that involve I/O, like accessing storage or making network requests, are slow relative to the processor's speed. During the time a program waits for a response from a web service, the processor could be performing other tasks. While the operating system manages some multitasking, standard Python code typically does not.
In Python, most I/O operations are blocking, which means the program stops and waits until the operation finishes. This approach can waste a lot of computing time, particularly when the program regularly makes calls to external APIs like those from AWS. Python's asyncio module offers a solution, allowing the program to perform other tasks while waiting for I/O operations to complete.There are also other methods, such as threading and multiprocessing, to consider.
Experiment with DynamoDB put_item
Let's get hands-on and start experimenting. We'll test the put_item operation in DynamoDB using four different concurrency approaches. Our goal is to measure performance and see which method works best under different conditions.

We'll measure the time taken for each method to perform I/O-bound tasks, like inserting items into a DynamoDB table.
Test Case: Perform 100 PutItem operations on a DynamoDB table with a partition key user_id.
Ensure you have configured AWS and installed the required libraries: boto3, aioboto3, and asyncio.
Synchronous Operations with Boto3
Synchronous execution processes each put_item request one after another. This traditional method ensures data consistency and integrity by completing each operation before starting the next.
# Non Concurrent
import boto3
import time
# Initialize boto3 DynamoDB client
dynamodb = boto3.client('dynamodb', region_name='us-east-2')
def put_item(user_id):
response = dynamodb.put_item(
TableName='Orders1',
Item={
'user_id': {'S': user_id}
}
)
return response
def test():
start_time = time.time()
for i in range(100):
put_item(f"user_{i}")
end_time = time.time()
print(f"Synchronous; Execution time: {end_time - start_time:.5f} seconds")
# Run the synchronous test
test()
Result: Synchronous; Execution time: 24.80749 seconds
In the synchronous approach using boto3, each put_item operation is executed one after another. This means each request waits for the previous one to finish before starting. As expected, this method takes significantly longer due to the blocking nature of synchronous operations. With 100 operations running sequentially, the total time required is substantial, reflecting the time taken for each operation to complete individually.
Threading - Preemptive Multitasking
Threading allows us to run multiple operations concurrently by using separate threads. This is useful for I/O-bound tasks like
put_itemoperations where the primary bottleneck is waiting on I/O rather than CPU computation.We use the
threadingmodule to create multiple threads, each of which will handle a put_item operation. Since the task is I/O-bound (waiting on network calls to DynamoDB), threading can improve performance by making concurrent put_item calls.
# Threading Example with ThreadPoolExecutor
import boto3
from concurrent.futures import ThreadPoolExecutor
import time
# Initialize boto3 DynamoDB client
dynamodb = boto3.client('dynamodb', region_name='us-east-2')
def put_item(user_id):
response = dynamodb.put_item(
TableName='Orders2',
Item={
'user_id': {'S': user_id}
}
)
return response
def test_threading():
start_time = time.time()
# Using ThreadPoolExecutor to manage a pool of threads
with ThreadPoolExecutor(max_workers=4) as executor:
# Submit multiple put_item tasks to the executor
futures = [executor.submit(put_item, f"user_{i}") for i in range(100)]
# Optionally, wait for all futures to complete and handle exceptions
for future in futures:
try:
# Get the result of the future
future.result()
except Exception as e:
print(f"An error occurred: {e}")
end_time = time.time()
print(f"Threading; Execution time: {end_time - start_time:.5f} seconds")
# Run the threading test
test_threading()
Initialize ThreadPoolExecutor with a specified number of worker threads. Here, max_workers is set to 10, but this number should be tailored based on your expected workload and the capacity of your system. Use executor.submit() to schedule the put_item function for each user ID concurrently. This method returns a Future object representing the execution of the task.
Result: Threading; Execution time: 6.59555 seconds
By running multiple threads in parallel, we achieved a notable reduction in execution time. This method allows concurrent processing of requests, which mitigates some of the delays caused by synchronous operations. The improvement is substantial compared to the synchronous approach, but it is still not as efficient as true asynchronous solutions, due to the overhead associated with threading and context switching.
How Can You Determine the Optimal Number of Threads?
Determining the optimal number of threads requires balancing various factors such as the nature of the task, system capabilities, and workload. Empirical testing is often the most effective method for finding the ideal number of threads. Begin with a conservative number, such as 5 or 10, and adjust based on performance metrics and system behavior. Additionally, Amdahl’s Law provides insight into the limits of parallelism by illustrating that even if a task is 80% parallelizable, the remaining 20% of sequential work can constrain the overall speedup. Practically, it is generally recommended that the number of threads should not exceed the number of CPU cores. Excessive threading can lead to increased context switching overhead, which diminishes the benefits of concurrency.
For further reading on this topic, you might find the following resources helpful:
stackoverflow- How to determine the optimum number of worker threads
https://www.amibroker.com/kb/2017/10/06/limits-of-multithreading/
asyncio - Cooperative Multitasking
When it comes to handling multiple tasks simultaneously, particularly I/O-bound tasks like interacting with a database, asyncio is a powerful tool in Python's arsenal. Unlike traditional multithreading, which involves managing multiple threads that might compete for CPU resources, asyncio operates on a different principle: cooperative multitasking.
asyncio relies on an event loop to manage tasks. Think of the event loop as a conductor directing an orchestra, where each task is a musician. Instead of each musician (task) playing their part all at once, they take turns based on when they're ready. This means that tasks voluntarily pause (or yield control) when they're waiting for I/O operations to complete, allowing other tasks to run in the meantime.
This approach is particularly effective for I/O-bound operations because the tasks are non-blocking. This means they don't waste CPU cycles waiting for I/O operations to finish. Instead, the event loop efficiently switches between tasks, ensuring that while one task waits for data, others can make progress.
3.1 boto3 with asyncio and thread pool)
# Asynscio Example with boto3
import asyncio
import boto3
import functools
from time import perf_counter
# Initialize boto3 DynamoDB client
dynamodb = boto3.client('dynamodb', region_name='us-east-2')
def put_item(user_id):
"""Synchronously put an item in the DynamoDB table."""
response = dynamodb.put_item(
TableName='Orders1',
Item={
'user_id': {'S': user_id}
}
)
return response
async def async_boto3_example() -> float:
"""Asynchronously perform DynamoDB put_item operations using asyncio with boto3."""
loop = asyncio.get_running_loop()
start_time = perf_counter()
# Create a list of tasks to run in the executor
tasks = [
loop.run_in_executor(None, functools.partial(put_item, f"user_{i}"))
for i in range(100)
]
# Execute all the tasks concurrently
await asyncio.gather(*tasks)
end_time = perf_counter()
return end_time - start_time
elapsed_time = asyncio.run(async_boto3_example())
print(f"Asyncio with boto3; Execution time: {elapsed_time:.5f} seconds")
Result: Asyncio with boto3; Execution time: 3.33852 seconds
Here, he put_item function, which performs a synchronous operation to add an item to a DynamoDB table, is executed in a thread pool. By using asyncio with run_in_executor, we can offload these synchronous boto3 calls to a separate thread pool, allowing them to run concurrently. Tasks are created using loop.run_in_executor, which enables running synchronous code asynchronously by executing it in a thread pool. Each call runs in a separate thread, providing a level of parallelism within the synchronous boto3 framework.
3.2 aioboto3 with asyncio (true asynchronous)
# Asyncio Example with aioboto3
import asyncio
import aioboto3
import time
# Function to perform asynchronous DynamoDB put_item
async def put_item_async(client, user_id):
response = await client.put_item(
TableName='Orders3',
Item={
'user_id': {'S': user_id}
}
)
return response
# Asynchronous function to test the asyncio implementation
async def test_asyncio():
session = aioboto3.Session() # Create an aioboto3 session
start_time = time.time()
async with session.client('dynamodb', region_name='us-east-2') as client:
tasks = [put_item_async(client, f"user_{i}") for i in range(100)]
await asyncio.gather(*tasks)
end_time = time.time()
print(f"Asyncio with aioboto3; Execution time: {end_time - start_time:.5f} seconds")
# Run the asyncio test
if __name__ == "__main__":
asyncio.run(test_asyncio())
Result: Asyncio with aioboto3; Execution time: 2.91687 seconds
This code directly uses the asynchronous methods provided by aioboto3 to perform operations. While boto3 is synchronous and used with asyncio’s run_in_executor in section 3.1, aioboto3 is designed for native asynchronous operations. The async with expression works like the "with" expression for context managers, but it lets you use asynchronous context managers inside coroutines.
aioboto3 is more efficient and idiomatic for async operations with DynamoDB. In contrast, section 3.1's use of boto3 with asyncio and a thread pool is a workaround to achieve asynchronous behavior with a synchronous library.
This method performed better than both the synchronous and thread-based asynchronous approaches, providing the fastest execution time (2.91687 seconds). This result shows the efficiency gains possible with true asynchronous programming, especially when dealing with many I/O-bound operations.
Difference between 2. Threading and 3.1 boto3 with asyncio and thread pool approaches
Code 2 uses traditional threading with ThreadPoolExecutor to run synchronous boto3 tasks concurrently. While straightforward, this method can involve overhead from managing multiple threads and context switching. Code 3.1 combines asyncio with synchronous boto3 calls using loop.run_in_executor. This approach integrates asyncio's event loop to handle task management while running boto3 tasks in parallel threads. It benefits from asyncio's concurrency features but still deals with the synchronous nature of boto3.
Multiprocessing
Unlike the previous methods that run on a single CPU core, the multiprocessing uses multiple CPUs on your machine. Whether you have a high-end, new computer or an older model like my mac m1.
# Multiprocessing Example
import boto3
import multiprocessing
import time
# Function to put an item using a new DynamoDB client
def put_item_process(user_id):
dynamodb = boto3.client('dynamodb', region_name='us-east-2')
dynamodb.put_item(
TableName='Orders1',
Item={
'user_id': {'S': user_id}
}
)
def test_multiprocessing():
start_time = time.time()
# Create a pool of processes and map the put_item function to each user_id
with multiprocessing.Pool(processes=4) as pool:
pool.map(put_item_process, [f"user_{i}" for i in range(100)])
end_time = time.time()
print(f"Multiprocessing; Execution time: {end_time - start_time:.5f} seconds")
# Run the multiprocessing test
if __name__ == '__main__':
test_multiprocessing()
Results: Multiprocessing; Execution time: 21.86500 seconds
In this example, we leverage Python's multiprocessing module to handle DynamoDB operations concurrently.It creates a pool of 4 processes with multiprocessing.Pool(processes=4). pool.map distributes the list of user IDs (from 'user_0' to 'user_99') across the processes in the pool. Each process runs the put_item_process function on different user_id values concurrently.
In this example, even though the execution time is longer than some of the asynchronous approaches, it's crucial to note that multiprocessing is particularly well-suited for CPU-bound tasks where parallel processing can lead to substantial performance gains. For I/O-bound tasks like DynamoDB operations, asynchronous methods might offer better performance, as they avoid the overhead of process creation and inter-process communication.
Results

Based on the results, we can say that asynchronous approaches, like aioboto3 and asyncio with boto3, significantly outperform both synchronous and threading methods for I/O-bound tasks such as DynamoDB interactions. Threading offers some performance improvement over synchronous execution but may be less efficient than asynchronous methods due to thread management overhead. On the other hand, multiprocessing offers true parallelism and excels with CPU-bound tasks, but it doesn’t provide the same performance benefits for I/O-bound problems.
FAQs
Why Synchronous vs. Asynchronous Matters ?
When it comes to managing tasks with a software application, the selection of either synchronous-al process or a non-synchronous process can either enhance or hinder efficiency and performance. For instance think of an online shop that consists of customers placing orders. In the synchronous method, each intermediate step related to the order such as clearing payment, reaching out to customers, sending confirmation email, or even updating the stocks happens one after another and not simultaneously. This order fixing cause unnecessary delays on the other tasks that might require quick responses hence seeing the whole order processing system take too long especially when there are many orders placed.
On the other hand, an asynchronous approach encourages the parallel execution of these tasks. While the payment confirmation is awaited, inventory can be updated and a confirmation message can be drafted ready for dispatch once the payment goes through. This method is advantageous as it frees the system to be active on several processes at the same time without hindering performance. Even with such an approach, there is a limitation that if certain activities will be postponed, other ones that are already in progress shall also be executed causing an earlier than expected completion of the order.
Nonetheless, just because asynchronous methods have some benefits, they can't be used for tasks that need to be done in order. For example, in financial transactions like transferring money from one account to another, each step depends on the previous one. Using an asynchronous method here would cause confusion. In such scenarios, high-velocity synchronous processing benefits all in that the activities done step by step.
What is an example use case for asynchronous programming with AWS?
A prime example of asynchronous programming with AWS is processing and validating configuration changes across multiple AWS Lambda functions. Suppose you have a system that dynamically updates various configurations across different services, such as modifying security settings, updating resource limits, or changing application parameters.
In this scenario, you might need to validate these changes by triggering multiple Lambda functions in parallel, each responsible for checking a specific aspect of the configuration. Asynchronous programming allows you to invoke all these Lambda functions concurrently rather than waiting for each to complete sequentially. This parallel execution significantly reduces the total time required for validation and helps in quickly applying changes across your infrastructure. By leveraging AWS services like AWS Step Functions or AWS EventBridge for managing and orchestrating these asynchronous invocations, you can handle high concurrency efficiently and improve the overall responsiveness of your system.
https://docs.aws.amazon.com/lambda/latest/api/API_Invoke.html
For asynchronous invocation, Lambda adds events to a queue before sending them to your function. If your function does not have enough capacity to keep up with the queue, events may be lost. Occasionally, your function may receive the same event multiple times, even if no error occurs. To retain events that were not processed, configure your function with a dead-letter queue.
edit:
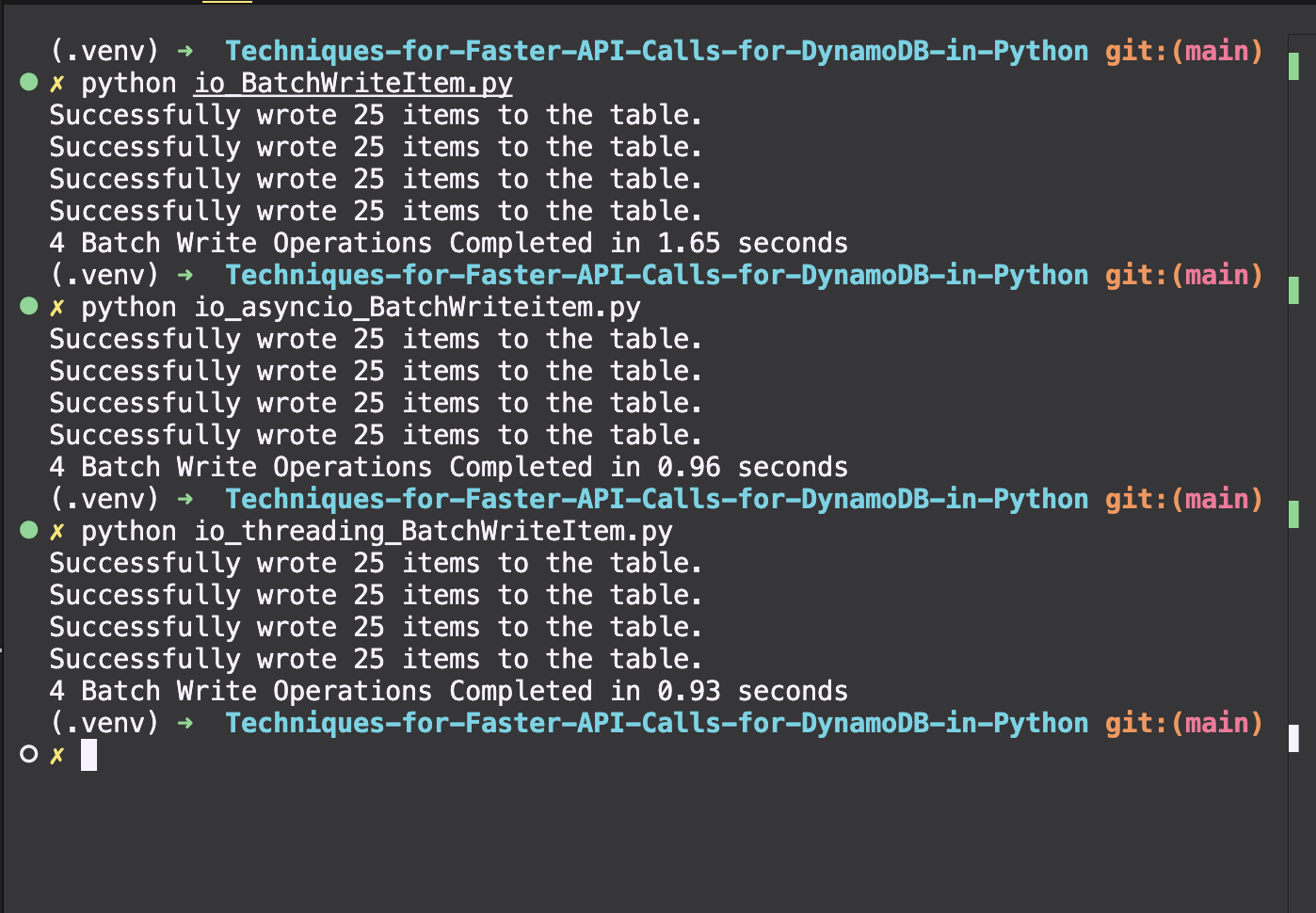
BatchWriteItem
I did compare the performance using BatchWriteItem for inserting 100 items. Since DynamoDB allows a maximum of 25 items per batch, I split the workload into 4 batches of 25 items each. BatchWriteItem was the fastest method. I think its ideal for bulk operations like data migration where high throughput is essential.
However, using put_item with different concurrency methods (synchronous, threading, asyncio) provides more granular control. For instance, put_item supports conditional writes, which isn't possible with BatchWriteItem.
Further, I also tried combining BatchWriteItem with threading, creating 4 threads to handle each batch concurrently. This helped to optimize throughput further.
I'm curious, we might see more noticeable differences between these methods under heavier workloads or more complex operations.
Also, I realize now for this experiment, it might have been better to use a service where batch processing isn’t inherently supported.
References and Resources
Use the DynamoDB Enhanced Client API asynchronously - AWS SDK for Java 2.x
https://stackoverflow.com/questions/67092070/why-do-we-need-async-for-and-async-with
https://en.wikipedia.org/wiki/Async/await
https://stackoverflow.com/questions/42809096/difference-in-boto3-between-resource-client-and-session
https://www.freecodecamp.org/news/asynchronous-programming-in-javascript/
Further Exploration
Consider exploring techniques for optimizing CPU-bound tasks, such as using multiprocessing or GPU acceleration, to improve your application's performance in compute-intensive scenarios.
Check out asynchronous programming in other contexts. While this blog focuses on DynamoDB, asynchronous programming can benefit many applications beyond database interactions, such as handling web requests, file I/O, and other network operations.
Gain insights into the factors affecting DynamoDB latency and learn strategies for minimizing delays to enhance performance for both synchronous and asynchronous operations.
Review AWS's recommendations for effectively querying and scanning data in DynamoDB, focusing on maximizing performance and minimizing costs.
Understanding Amazon DynamoDB latency | Amazon Web Services
Use parallelism to optimize querying large amounts of data in Amazon DynamoDB | Amazon Web Services
Best practices for querying and scanning data - Amazon DynamoDB
Subscribe to my newsletter
Read articles from Aditya Dubey directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Aditya Dubey
Aditya Dubey
I am passionate about cloud computing and infrastructure automation. I have experience working with a range of tools and technologies including AWS- Cloud Development Kit (CDK), GitHub CLI, GitHub Actions, Container-based deployments, and programmatic workflows. I am excited about the potential of the cloud to transform industries and am keen on contributing to innovative projects.