Integrating Snowflake with a Data Lake - What you Need to Know
 John Ryan
John Ryan
This is the first in a series of articles about Snowflake Data Lake Architecture. In this article, I'll describe some background including:
What is a Data Lake and why the architecture was invented.
How Snowflake supports Data Lake (or raw history) both internally and externally.
How to create a Snowflake External Table to integrate with an external data lake, and how to maximize query performance.
In my next article, I will show how Snowflake integrates with a Data Lake using the Apache Iceberg table format.
What is a Data Lake?
Contrary to popular opinion, a Data Lake is not a hardware platform or product like Hadoop or Databricks, but an architectural pattern that resulted from the need to store vast volumes of data including semi-structured data (eg. JSON) and unstructured data (eg. Videos or Image files).
The diagram below illustrates a Data Lake and Data Warehouse design from as little as five years ago.
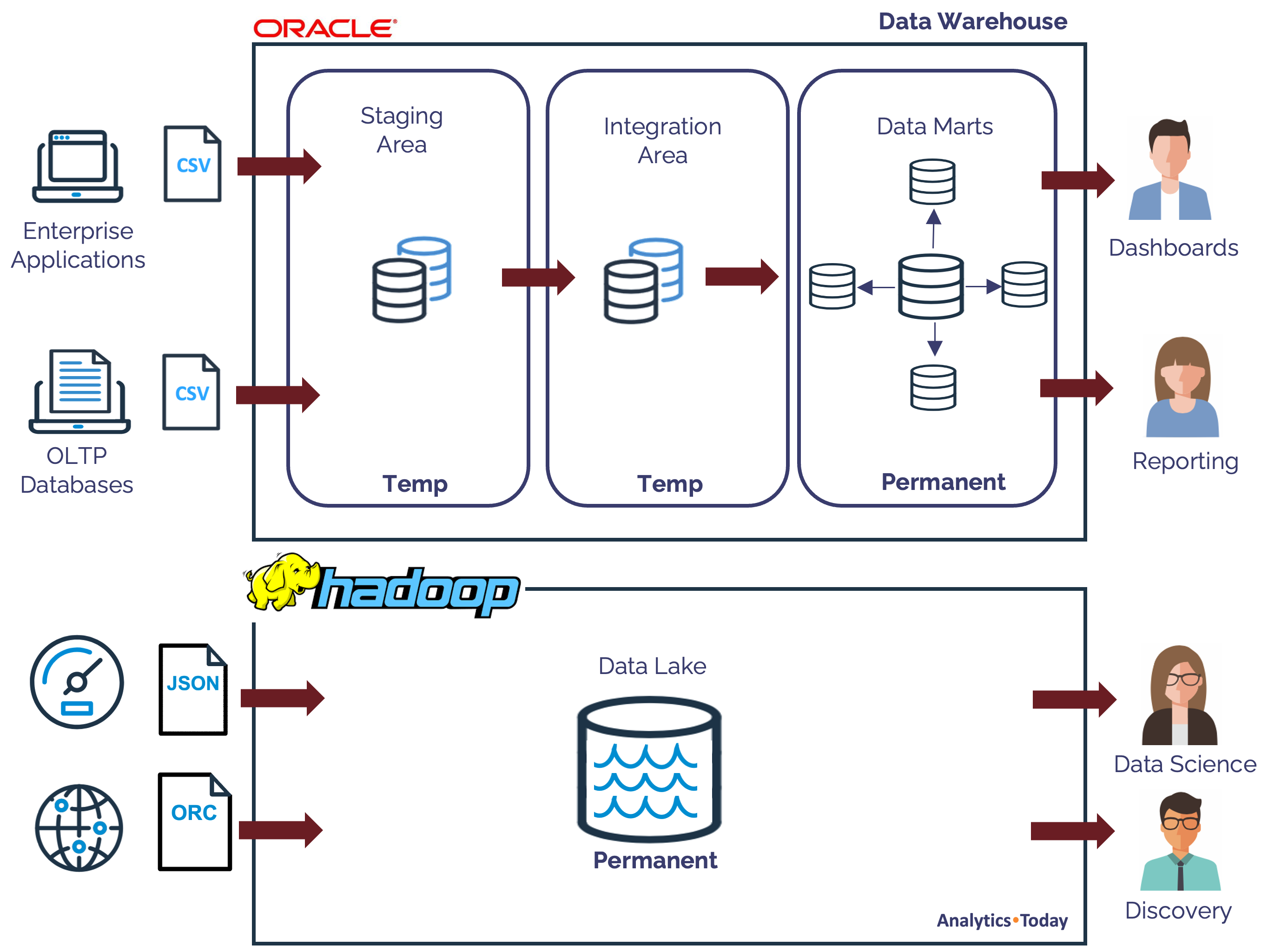
While I was working at a Tier 1 Investment Bank in London, I saw this kind of nonsense being deployed, although (to be fair), I could understand the reasoning.
We had a huge data warehouse with Staging (to land CSV data into Oracle tables), Integration (to clean and process the data), and Kimball Data Marts (to deliver the data for analysis). However, we had no record of the raw data which was hugely expensive to hold in the database.
Furthermore, we increasingly had semi-structured data formats like JSON to store and query, and Oracle just couldn't handle it from a query performance viewpoint.
We therefore deployed a Data Lake on Hadoop alongside the Oracle database, but (like many teams), found Hadoop was incredibly difficult to manage.
What does a modern Data Lake look like?
The diagram below illustrates a modern Data Lake architecture.
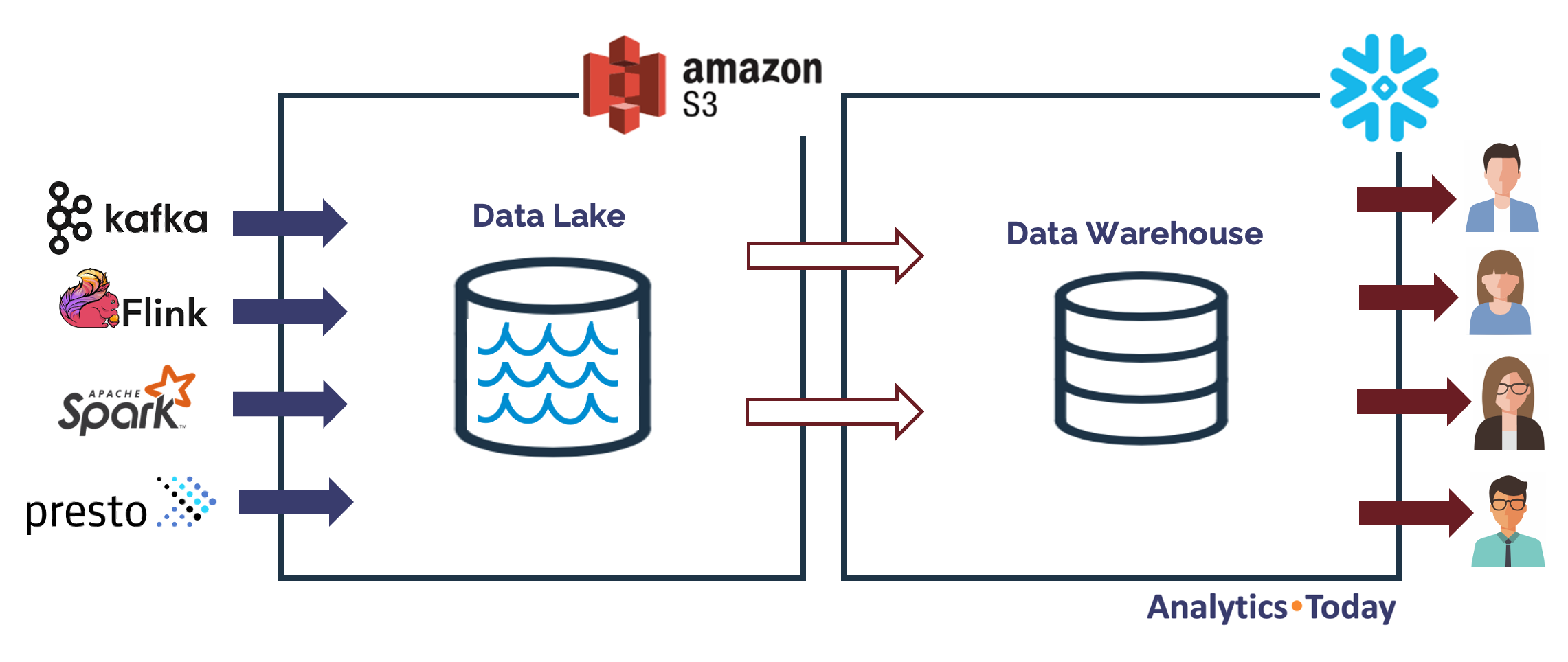
The diagram above illustrates how both the the Data Lake and Data Warehouse are now deployed on the cloud with the benefits of security and scalability.
On the left, the Data lake is accessible to both load and query using hundreds of open source tools including Flink, Spark and Presto, and this seamlessly integrates into a Snowflake based Data Warehouse.
It's worth pointing out, that the Data Lake is not just to store data, but can also be used to ingest and transform data in real time - a feature that's also available within Snowflake.
There are other options available, which we'll discuss later, but this is a common set-up I've seen many times before.
Snowflake Features for Data Lakes
Snowflake includes a range of features to both complement and seamlessly integrate with a data lake including:
Native Data Sources: Unlike (for example), Oracle, Snowflake has native support for semi-structured data, and it can seamlessly load and query data in JSON, Parquet, AVRO, ORC or XML using simple SQL statements. As it stores data in native format (VARIANT), it also supports schema on read, so no more system failures resulting from data structure changes.
Integration with External Clouds: There's no requirement to copy data from the Lake into the Data Warehouse. Using Snowflake External Tables, we can rapidly query data directly on AWS, Azure and GCP, and it even supports file level partition elimination.
Automatic Metadata Discovery: For data files formats that include the data types (eg. Parquet), Snowflake uses schema inference to automatically detect and load the column names and data types to speed development.
Unstructured Data : Snowflake supports unstructured data, including as images, audio and video files.
Integration with Document AI and Text Analysis: Snowflake integrates with tools like Document AI to analyze unstructured data using machine learning models.
However, some of the hidden benefits of using Snowflake to analyze or transform data in a Data Lake are integral to the platform, but easily missed. These include:
Data Security and Privacy: Access to the Data Lake from Snowflake automatically includes security features like role-based access control (RBAC), dynamic data masking, and row-level security, along with end-to-end encryption. This provides a single platform for Data Governance and Security instead of relying upon features from multiple vendors.
Data Sharing: Snowflake Data Sharing provides the ability to securely share access to the Data Lake both internally and to 3rd parties without copying or moving the data.
I'd say, one of the greatest advantages however, is the single platform base. If you're using Snowflake for the Data Warehouse, it's easy to seamlessly extend the access to the Data Lake, and Snowflake users see no distinction between the two. The diagram below illustrates how Snowflake External Tables integrate with a cloud based Data Lake.
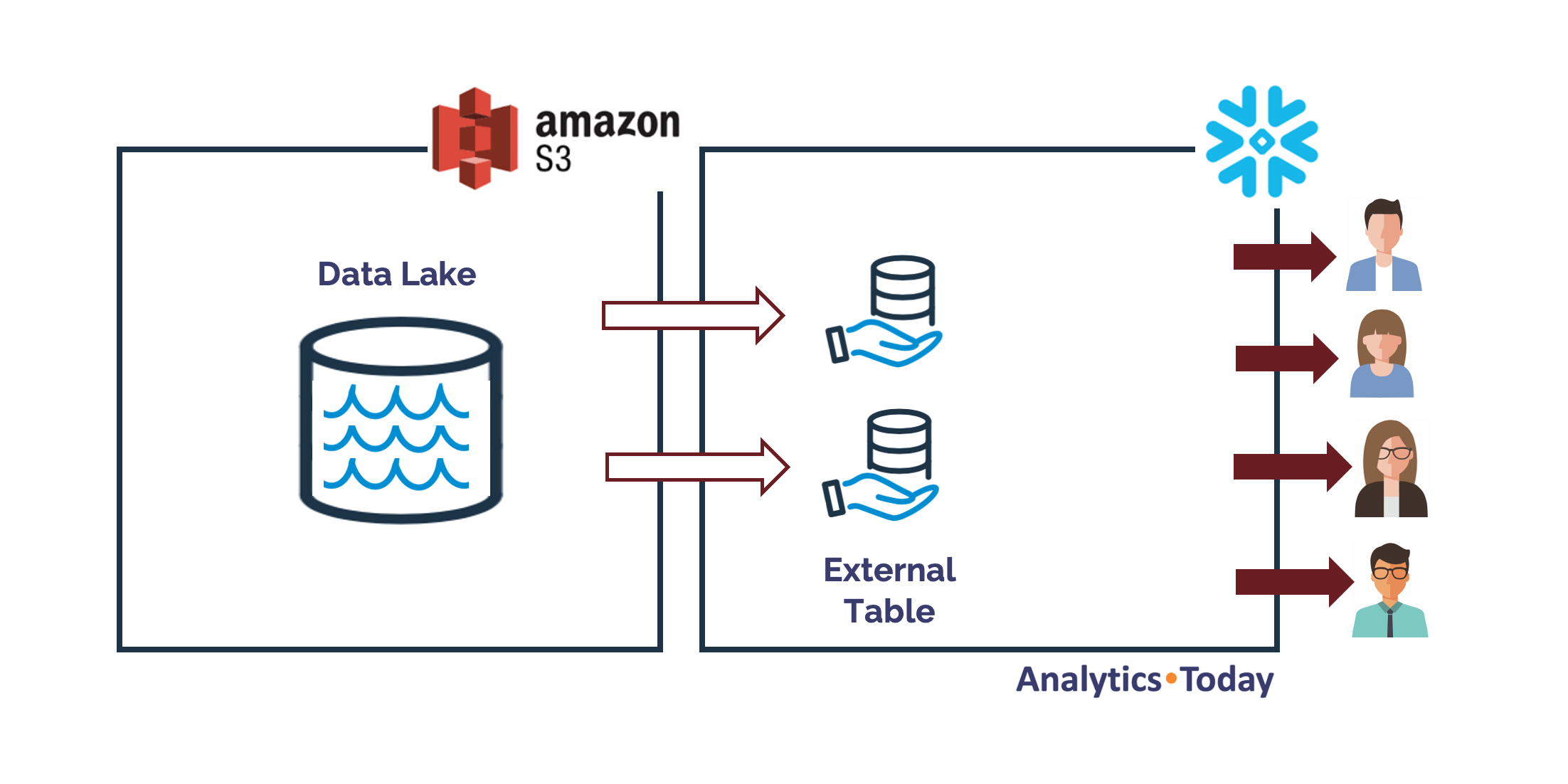
The advantage of the above approach, means users can query and join data from the data lake and seamlessly combine them with existing data in Snowflake.
Do I need a Data Lake?
When I first discovered this approach I was skeptical. Aside from the risk of it becoming a Data Swamp, I was concerned about the additional cost of specialized skills needed to support yet another data platform. You also risk building yet another data silo with petabytes of data, for no real purpose.
However, the diagram below illustrates why I firmly believe every Data Warehouse should have a Data Lake (or Raw History).
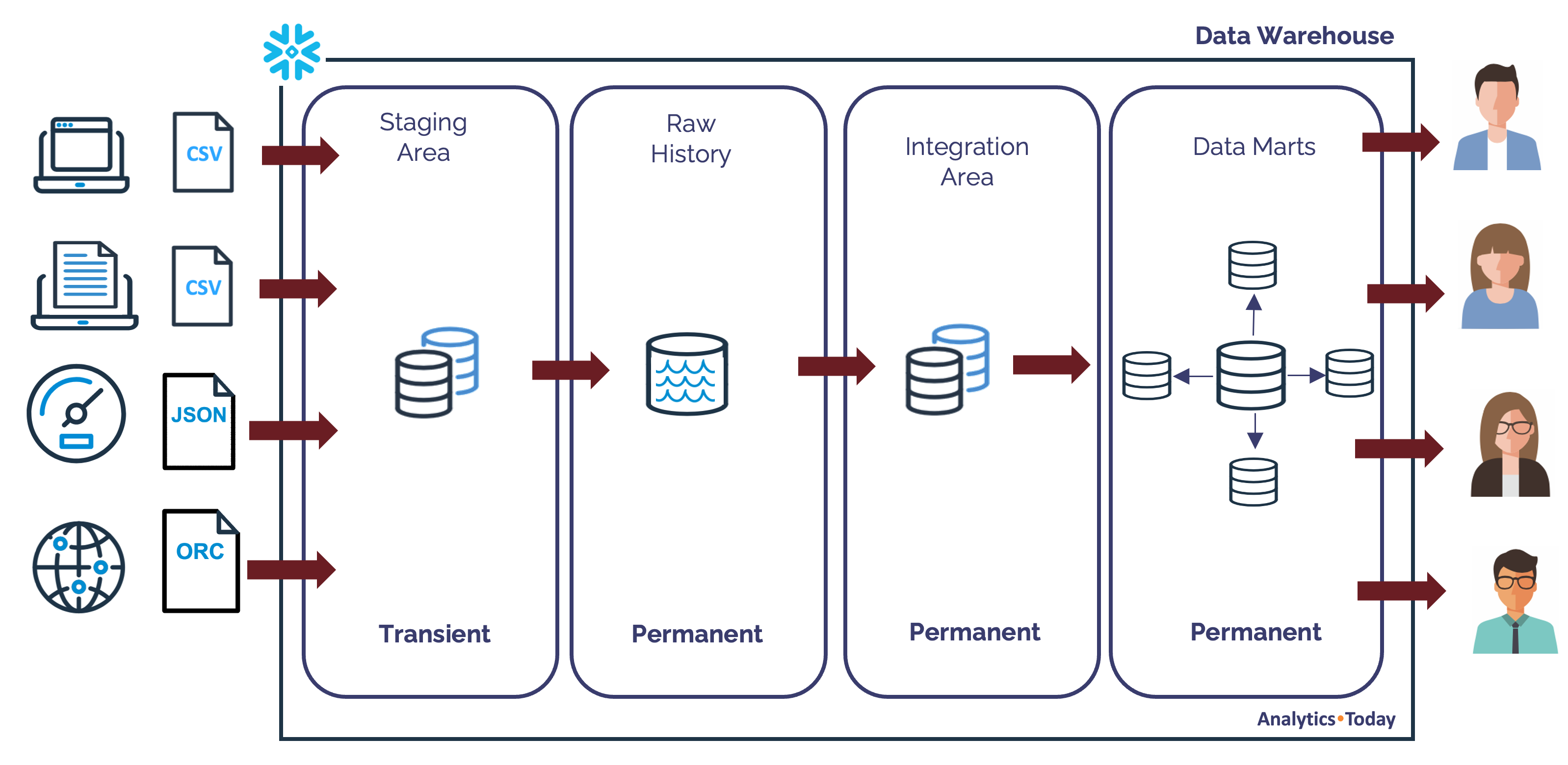
The above diagram illustrates how the original Oracle based Data Warehouse architecture has been extended with a Raw History layer. This layer holds data in either Structured (rows and columns) or semi-structured (eg. JSON or Parqet) format along with unstructured data. However, unlike the Integration Area which includes only cleaned, refined data, this purely stores the entire history of raw data.
Using the above architecture means you optionally initially load data to the Staging (or Landing) area into Transient tables or directly into the Raw History. While the staging data is deleted each time, the Raw History, holds every transaction or reference data change.
To understand the reasoning behind this approach, consider my challenge back in the Investment Bank. I insisted that we'd only load attributes into the warehouse which were understood, documented and therefore had some purpose. On-premises data storage was expensive and loading data just in case it's needed is clearly an opportunity to waste money build a Data Swamp.
However, over time, the business gradually discovered and documented these unidentified attributes and related tables, but we'd lost the history. In addition, as business rules changed, we were unable to restate the history using different rules.
Using a Raw History (or internal Data Lake), means you can replay any transformations if business rules change, and the data is also accessible to Data Scientists who will not thank you for clean, filtered data however much you describe the benefits.
The short answer is therefore, yes. If you have a Data Warehouse you do need a Data Lake. Either internally within Snowflake or externally if it's already in place.
Integrating Snowflake with a Data Lake?
I'll spare you the optional Storage Integration, but the following SQL shows how to create an external table over a Data Lake.
CREATE EXTERNAL TABLE sales (
sale_id NUMBER,
product_id STRING,
quantity NUMBER,
created_at TIMESTAMP
)
WITH LOCATION = '@sales_external_stage'
FILE_FORMAT = (TYPE = PARQUET);
Once created, this looks like a normal table, although you cannot update the data. You can however, query the data and combine it with existing Snowflake data.
SELECT *
FROM sales
WHERE created_at > '2024-01-01';
What about Query Performance?
Queries against normal Snowflake tables with nearly always be faster than queries against a data lake, however you can deploy file-level partition elimination, for example partitioning by month.
The example below shows how Parquet data files are held for April, May, and June 2024.
s3://sales/2024/04/data_0_0_0.parquet
s3://sales/2024/05/data_0_0_1.parquet
s3://sales/2024/06/data_0_0_2.parquet
Assuming the above structure, he following SQL creates a partitioned external table.
create external table sales with
year number as to_number(split_part(metadata$filename,'/',3)),
month number as to_number(split_part(metadata$filename,'/',4))
location = @sales/daily
auto_refresh = true
file_format(type = parquet
partition by (year, month);
The PARTITION_BY (YEAR, MONTH)clause means any query that filters by YEAR and MONTH eliminates files, which helps maximize query performance. For example, the following query returns data from just one data file.
select *
from sales
where year = 2024
and month = 05;
You also have the option to define a Materialized View over an external table which effectively means you can cache recent (often most frequently queried) data in Snowflake, but seamlessly query historical data on the Data Lake as needed.
Conclusion
In conclusion, while Hadoop based Data Lakes were often an over-complex white elephant, a cloud based Data Lake is now a standard feature of many large data analytic systems.
Integrating Snowflake with an external data lake adds significant benefits, especially in the area of unified simple data governance and security, and using Snowflake External Tables means the Data Lake is accessible from both open source query tools and from within Snowflake itself. Adding the benefit of transparent data sharing and the ability to combine data within the same SQL statements is a huge advantage and helps reduce the risk of the Data Lake becoming yet another data silo as it's accessible across the business.
In the next article, I'll explain how Apache Iceberg is changing the Data Lake landscape, and how Snowflake fits into this new approach.
Deliver more performance and cost savings with Altimate AI's cutting-edge AI teammates. These intelligent teammates come pre-loaded with the insights discussed in this article, enabling you to implement our recommendations across millions of queries and tables effortlessly. Ready to see it in action? Request a recorded demo by just sending a chat message (here) and discover how AI teammates can transform your data teams.
Subscribe to my newsletter
Read articles from John Ryan directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
John Ryan
John Ryan
After 30 years of experience building multi-terabyte data warehouse systems, I spent five incredible years at Snowflake as a Senior Solution Architect, helping customers across Europe and the Middle East deliver lightning-fast insights from their data. In 2023, I joined Altimate.AI, which uses generative artificial intelligence to provide Snowflake performance and cost optimization insights and maximize customer return on investment.