Can Data Science unlock new insights into CGM driven Diabetes management?
 Farid Hamid
Farid Hamid
For those interested in the code behind this analysis, check out my GitHub repository here (with link to analysis in Google Colab Python Notebook).
Context
Having lived with the chronic illness of insulin-dependent (Type 1) Diabetes for over 25 years, I have witnessed first-hand the evolution of Diabetes management technology. In particular, Continuous Glucose Monitoring systems, which in recent years have become an absolute constant integration in my daily life. This kind of low-invasive technology has been a game changer. Most people wake up and check their social media, emails or texts. For me, the first view on my smartphone is almost always my LibreLink glucose monitoring application, where I'll check my time series graph to see if I need to make any adjustments upon simply getting out of bed. This is just the start of a truly "data-driven" experience that is embedded in the lives of many Diabetic patients around the world today [1].
Where my career journey as a Data Scientist brings out my natural curiosity for deriving insight from raw information, I couldn't help but wander if the lesser-known pain points I experience on an individual level (associated with wearing a CGM) are felt on a more global scale than Diabetes patients are often led to believe within their Endocrinology and Dietetics appointments (in various health services, depending on where in the world you live).
I collected a substantial sample of anonymised discussion data from various user-generated sources (social media, online diabetes forums) and set out to process this to cleanly apply appropriate machine learning algorithms to the dataset. The goal was to create an insightful view of granular topics which matter to Diabetics using CGMs and find out whether other people face similar pain points.
Due to the sparse and unstructured nature of online health community discussions, mining large and dense text datasets for insights using machine learning methodologies calls for unsupervised learning approaches. Where traditional supervised machine learning models require already labelled data points, this introduces a broad impracticality within such linguistically diverse data landscapes like Diabetes threads. Therefore, unsupervised methods like BERTopic excel in scenarios where the identification of patterns and clusters is required without pre-labelled data. I chose BERTopic for my investigative research as discussions in online health communities can range from technical issues with Continuous Glucose Monitoring Systems, to personal experiences or even physical and emotional impact. By leveraging these approaches, researchers, healthcare providers and even device manufacturers can decompose multifaceted discussions within Diabetic communities digitally, leading to actionable insights that can contribute holistically to improve patient support, product development, and community engagement.
Why Natural Language Processing?
To achieve the goals described above, I leveraged Natural Language Processing techniques to prepare the user-generated content, combined with a powerful modern Topic Modelling approach in the form of BERTopic [2]. This duo unveils very niche areas of discussion and sheds light on such pain-points, capitalising on transformer architectures to extract and represent coherent topics from unstructured text. Not only do the views created through this research approach benefit like-minded Diabetics, but also the manufacturers of said CGMs in grasping a wider-lense of the sentiment concerning the use of their products in their intended audience and market.
User-generated content can be very messy, full of noise, emojis, random hyperlinks and other pollutants, therefore cleaning posts requires a robust process for any measurement approach using natural language. Of course, powerful Python libraries like the Natural Language Tool Kit (NLTK) are useful for formatting chunks of discussions into a neat text corpus, ensuring that the unsupervised machine learning model (BERTopic) is ingesting consistent data points.
Modern Topic Modelling with BERTopic
In the field of natural language processing and text mining, BERTopic has emerged as an advanced methodology that harnesses the capabilities of transformer models, especially the BERT (Bidirectional Encoder Representations from Transformers) architecture. Developed by Maarten Grootendorst [2], BERTopic introduces a modern approach to extracting and representing topics from extensive text datasets by employing BERT embeddings to capture the intricate contextual and semantic associations between words. This innovative technique has proven to be exceptionally effective in analysing multi-faceted conversations, such as those prevalent in online communities discussing the use of Continuous Glucose Monitors (CGMs) in the context of Diabetes management.
There are 5 pillars to implementing an unsupervised machine learning model like BERTopic in the contextual deep dive investigation of Diabetes community discussions:
Vectorisation of Text
Sentence Embeddings
Dimensionality Reduction
Density based clustering
Topic Representation
In BERTopic, the first step involves converting text data into a structured numerical format. Following this, dense vectors are generated using pre-trained Sentence Transformers to capture the semantic meaning of each sentence through text embeddings. These vectors then undergo dimensionality reduction through UMAP (Uniform Manifold Approximation and Projection) to preserve their relationships while simplifying the data structure.
Subsequently, clustering is conducted using HDBSCAN (Hierarchical Density-Based Spatial Clustering of Applications with Noise), which is particularly adept at identifying clusters of varying densities and effectively handling noisy data from social media or online forums. Lastly, advanced techniques such as KeyBERT and Maximal Marginal Relevance (MMR) are employed to produce coherent and representative keywords for each topic, ensuring that the extracted topics are not only contextually rich and diverse, but also easily interpretable by human users.
The BERTopic algorithm combines the sub-models described above, forming a powerful machine learning pipeline, transforming sparse documents of text into context-rich visual outputs.
BERTopic Model Output & Analysis
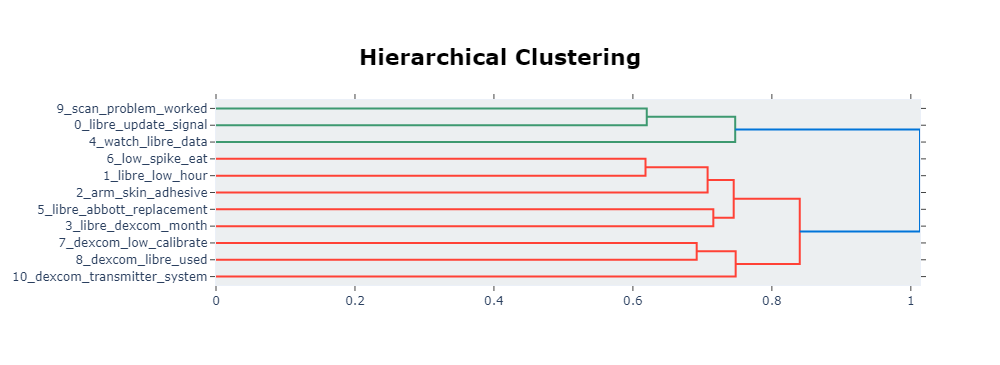
The hierarchical clustering dendrogram above is an initial output from the BERTopic model, illustrating the relationships between different niche topics from the text corpus in a simplified and human-readable way. A dendrogram is a tree-like diagram that illustrates the arrangement of the dense clusters produced by the clustering algorithm. The horizontal axis represents the dissimilarity (or distance) between clusters, while the vertical lines represent the merging of clusters at different levels of similarity. In handling high-dimensional data from discussions, hierarchical clustering assists in reducing complexity through grouping to increase interoperability contextually in holistic support of healthcare provision.
Where exploratory data analysis is concerned, this method of clustering is important as no pre-defined number of clusters is required. From an analytical perspective, the dendrogram can be cut to define clusters based on the contextual structure of the data being explored. This can lead to the targeting of interventions derived from analysis, for effectiveness. By addressing pain points or topics that are closely related, concerns across multiple components of the patient and Diabetic CGM user experience can be mitigated simultaneously.
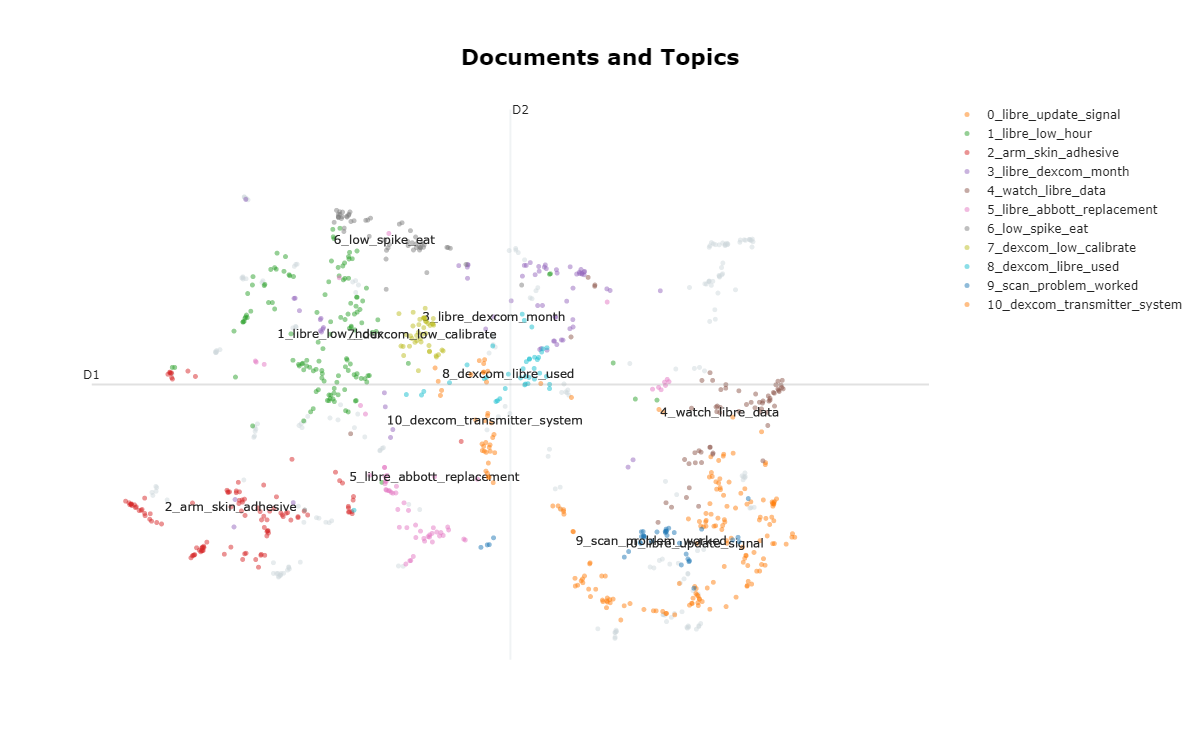
The HDBSCAN algorithm aids the machine learning model in producing a topic density map of the labelled text dataset. The clusters of data points represent processed discussion documents closely related in topic and semantic meaning. Just as overlapping topics can be identified by observing the different colours of clusters positions, distinct topics can be extracted by well separated clusters, guiding further deep dive exploration or research into pain points that aren't strongly shared with other topics.
Topic word scores offer a breakdown of the main terms linked to each topic that the BERTopic model has identified. These scores shed light on the most frequently used terms in discussions within the online diabetes community regarding Continuous Glucose Monitors (CGMs). For example, Topic 1, which revolves around the Freestyle Libre device, underscores concerns about "low" glucose readings, frequent monitoring on an hourly basis, and the accuracy of these readings. This indicates that users have raised concerns over the reliability of device glucose monitoring over time, which is critical for effective diabetes management, where doses and insulin intake patterns are often adjusted throughout the day based on this.
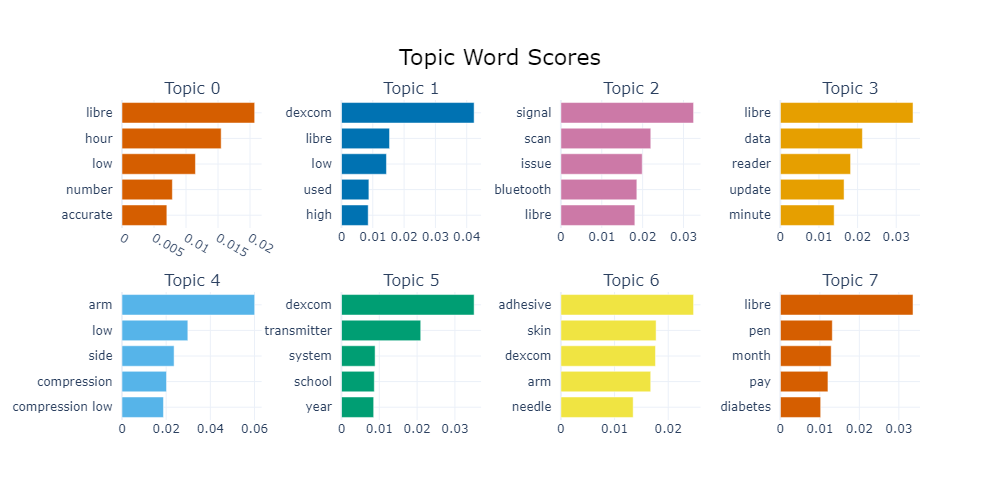
To examine a more niche pain point, Topic 6 highlights specific concerns about sensor placement and skin reactions, with frequent mentions of "arm," "skin," and "adhesive." This underscores the need for better adhesive materials and clearer guidelines on sensor placement to ensure comfort and accuracy. Many patients can suffer from "compression lows", where false low readings can lead to improper adjustments in care, throwing off a patient's blood glucose regulation for the day. To give context, this often occurs through rigours of daily life or even sleeping, where pressure has been applied to the sensor unknowingly for a period of time, resulting in live time series readings which register as low. The placebo effect of seeing a low glucose level notification from your CGM device and immediately feeling to action it can become very real as a mental effect for many diabetics, hence, the importance of highlighting the factors which can lead to the occurrence of these phenomena through Topic modelling.
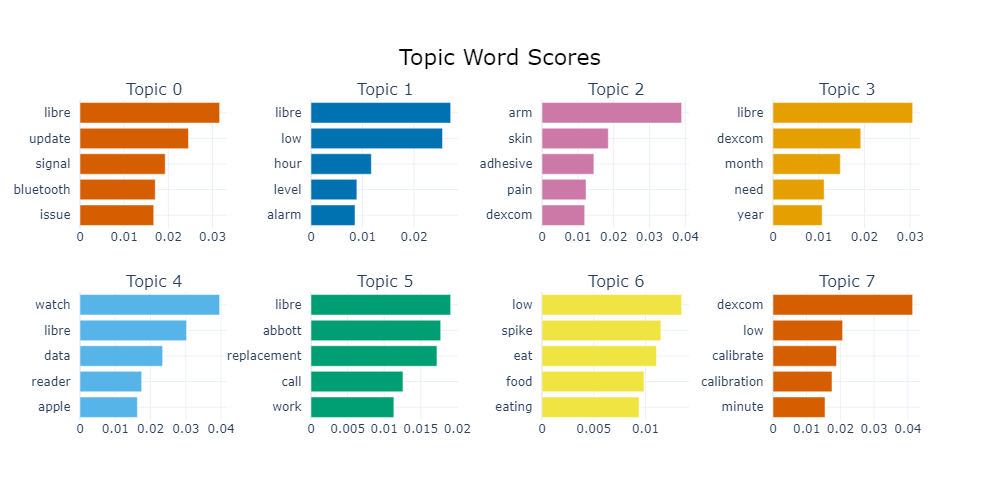
When tuning parameters of BERTopic's machine learning model pipeline, additonal word score extractions show Topic 4's focus on "data," "reader," and "update" reflects user priorities on efficient data management and software updates, signalling manufacturers to more frequently enhance their application interfaces and data handling competencies. This is strongly linked to the desire of many to integrate more CGM software with smart wearable devices, evident from the close proximity of Topics 9 and 10 in the topic density map. Wearable medical technology is becoming increasingly common and in demand, if more of this could be seamlessly communicative with smart wearables like Apple watches or fitness wearables, a world of efficiency and flexibility could be reopened to many Diabetic CGM users around the world.
Insights
Ultimately, the insights derived through Advanced Topic Modelling analysis are of value for Healthcare Providers and CGM Manufacturers. Endocrinology and dietetics consultations can be backed in a continuously data driven manner over time, to support the guidance and tailoring of patient care.
Additionally, this can inform the supporting educational materials used to drive better understanding across the CGM user sphere, grounded in real-world user experiences. For example, understanding where different discussions fall in a document-topic density map can aid in the refinement of user manuals, FAQ's or user/customer support strategy- aligning with significant user experiences and concerns.
Advanced Topic Modelling frameworks like this drive hypothesis generation and data exploration in user behaviours and preferences. By observing unexpected topic extractions, new investigative areas can be suggested through previously unconsidered conceptual links from a Diabetic CGM or Endocrine/Dietetic perspective.
For CGM device manufacturers, the deep dive analysis from topic modelling can prove to be invaluable by mining user-generated data, representing both the key and niche areas - such as sensor adhesion issues or software integration gaps- enabling the prioritisation of product development efforts accordingly. By following through with processes like these, companies can not only improve the functionality and reliability of their CGM devices, but foster stronger relationships with their user and customer base. Moreover, the demand for seamless integration between CGM systems and smart wearable devices presents a strategic opportunity for innovation. By advancing interoperability, manufacturers can enhance the value proposition of their products, catering to a growing market of tech-savvy users who value convenience and real-time health monitoring.
In conclusion, leveraging advanced NLP and topic modeling techniques like BERTopic provides, robust, flexible frameworks for extracting actionable insights from oceans of unstructured data. This empowers stakeholders in the diabetes care ecosystem to make data-driven decisions and aligns product offerings more closer to evolving market needs. By continuing to harness these methodologies, both healthcare providers and manufacturers can drive substantial improvements in patient care and product performance, supporting better health outcomes for diabetic patients globally.
References
[1] American Diabetes Association Professional Practice Committee. (2022). Diabetes Technology: Standards of Medical Care in Diabetes—2022. Diabetes Care, 45(Suppl. 1), S97–S112. Available at: https://doi.org/10.2337/dc22-S007 [Accessed 2 May 2024].
[2] Grootendorst, M. (2022), "BERTopic: Neural topic modeling with a class-based TF-IDF procedure". Available at: https://maartengr.github.io/BERTopic/index.html [Accessed 12 January 2024]
Subscribe to my newsletter
Read articles from Farid Hamid directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Farid Hamid
Farid Hamid
I am a Data Scientist interested in the world of Big Data and the applications of insights in society. Improving performance and supporting decisions impacting human wellbeing through Machine Learning approaches, NLP & Language Modelling experiments are particular interests of mine. I believe a part of this is spreading knowledge on technology to everyday internet users who may not be aware of how much data matters online.