Understanding Convolutional Neural Networks (CNNs)
 Faozia Islam Riha
Faozia Islam RihaTable of contents
- Introduction
- The Advantage of Small Models
- The Concept of Shared Parameters
- What is a Convolutional Neural Network?
- Components of CNN
- Mathematical Foundations
- Convolution Operation Explained
- Pooling Layers and Reducing Complexity
- Dimension Reduction in CNNs
- Flattening and Fully Connected Layers
- Transfer Learning: Making the Most of Pre-trained Models
- Explainable AI (XAI): Making CNNs Transparent
- Real-World Applications of CNNs: Changing Industries
- CNN Variants
- VGG Architecture
- Conclusion

Introduction
In the realm of deep learning, Convolutional Neural Networks (CNNs) have become a fundamental tool for various tasks, especially in image processing. But what makes CNNs so effective, and how do they differ from traditional neural networks?
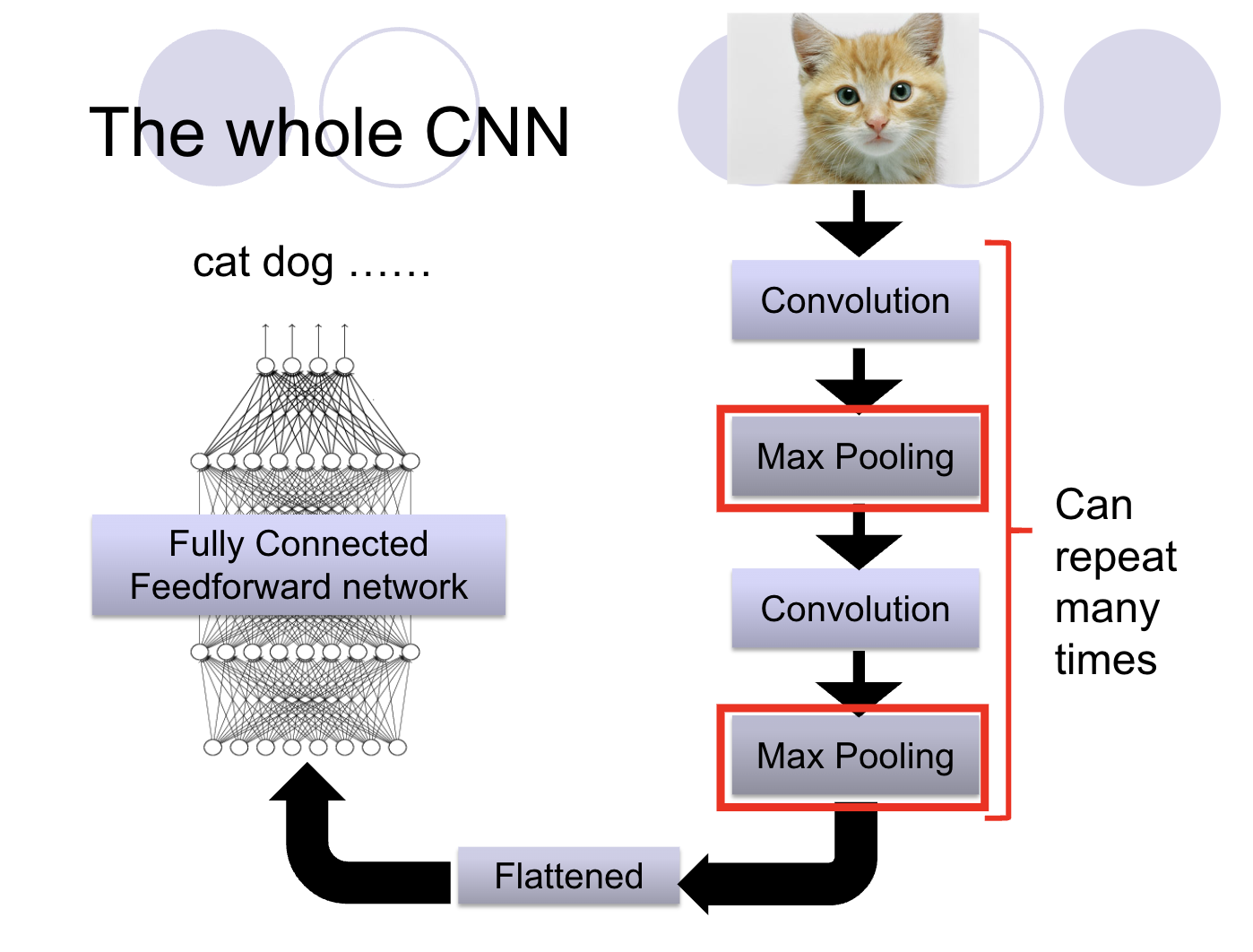
The Advantage of Small Models
One important aspect of CNNs is their efficiency. Small models often work just as well, if not better, than larger ones. They learn faster and require less computational power. This is particularly evident when compared to fully connected neural networks (NNs), where not all edges or connections are necessary. In fact, in many cases, we didn't need all the connections in a fully connected NN, as we learned from experience with other models like RNNs.
The Concept of Shared Parameters
In CNNs, we can share parameters across the network. This sharing leads to fewer edges and connections, which not only reduces the complexity of the model but also helps prevent overfitting. By sharing parameters, CNNs can focus on the most important features of the input data.
What is a Convolutional Neural Network?
A CNN is essentially a neural network that includes one or more convolutional layers. These layers apply filters to the input data, performing convolution operations that are crucial in extracting meaningful features from images.
Components of CNN
A CNN consists of several key components:
Input Layer: This layer accepts the input data, typically images or feature maps. The size of the input depends on the specific dataset and task.
Convolutional Layers: These layers apply filters (kernels) to the input data, which helps in feature extraction. The number and size of filters can vary across different CNN architectures. After convolution, activation functions like ReLU are often applied to introduce non-linearity.
Pooling Layers: Pooling layers down-sample the spatial dimensions of feature maps, helping to reduce the number of parameters and increasing translation invariance. Common pooling techniques include max-pooling and average-pooling.
Fully Connected Layers: These layers, also known as dense layers, connect every neuron to every neuron in the previous and subsequent layers. They are typically used towards the end of the CNN architecture.
Output Layer: The output layer produces the final predictions or class scores. For classification tasks, the number of units in this layer corresponds to the number of classes, and softmax activation is often used.
Mathematical Foundations
Understanding the mathematical operations behind CNNs is crucial for grasping their effectiveness. For instance, after applying a convolutional layer with a given stride (S), filter size (F), and padding (P), the new dimensions of the output can be calculated using the following equations:
O(H)= (H−F+2×P)/s +1
O(W)= (W−F+2×P)/s +1
Where:
H is the height of the input feature map.
W is the width of the input feature map.
F is the size of the convolutional filter.
P is the amount of padding.
S is the stride.
These equations help determine the new spatial dimensions of the output feature map after convolution, which is vital for designing CNN architectures.
Convolution Operation Explained
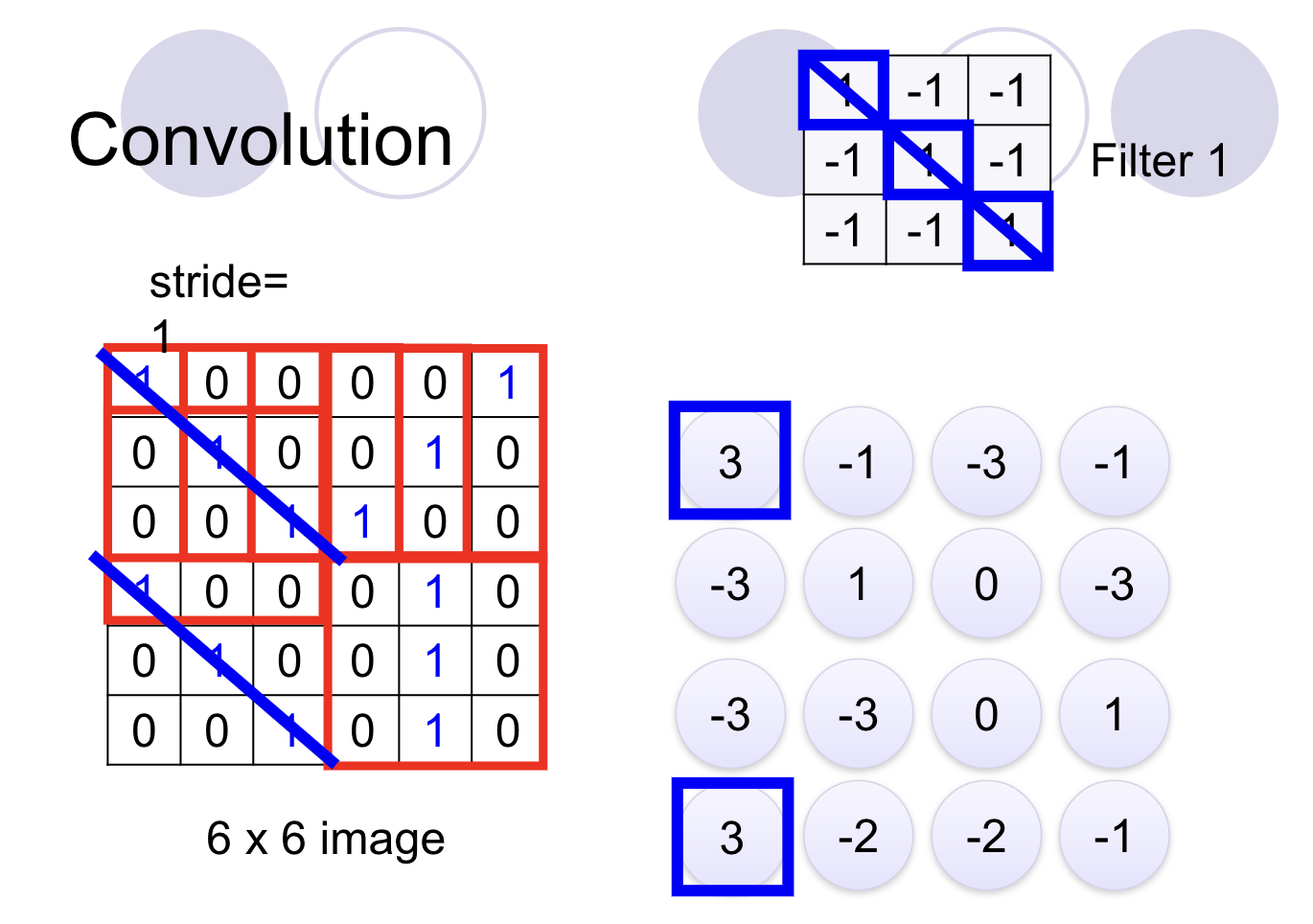
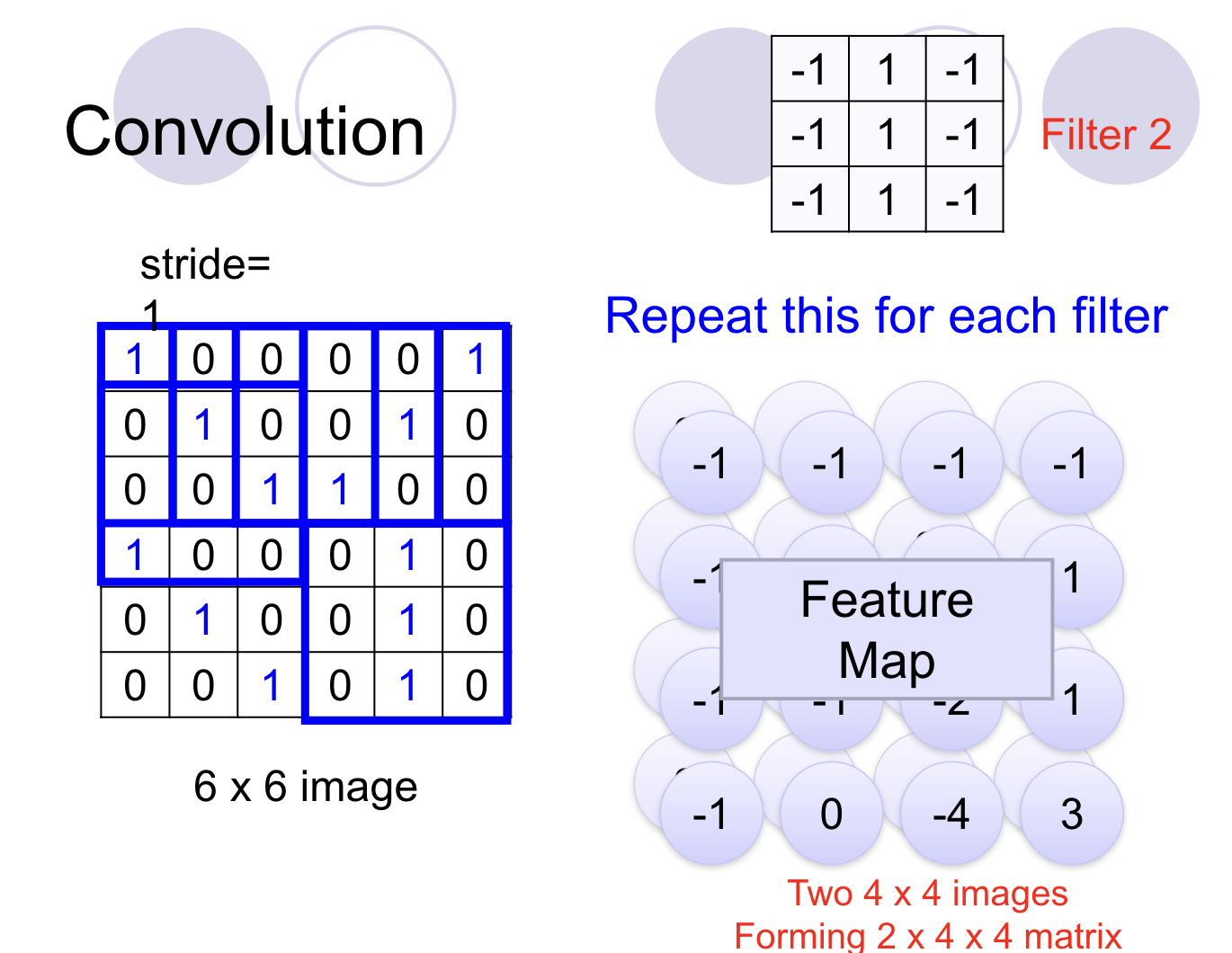
Let's consider a simple example. Imagine a main image of size 6x6, and we're using a filter of size 3x3. The convolution operation involves sliding the filter over the main image and performing a dot product at each position.
For instance, when we apply a 3x3 filter to a 6x6 image, the output is a 4x4 feature map. This feature map captures essential features of the image while reducing its size, which is important for handling large images without losing critical information.
Pooling Layers and Reducing Complexity
Pooling, or subsampling, is another crucial step in CNNs. After the convolution operation, pooling layers are applied to further reduce the size of the feature map while preserving important features. Max pooling, in particular, is a popular technique where only the maximum value from a group of values is selected, further reducing the complexity of the network.
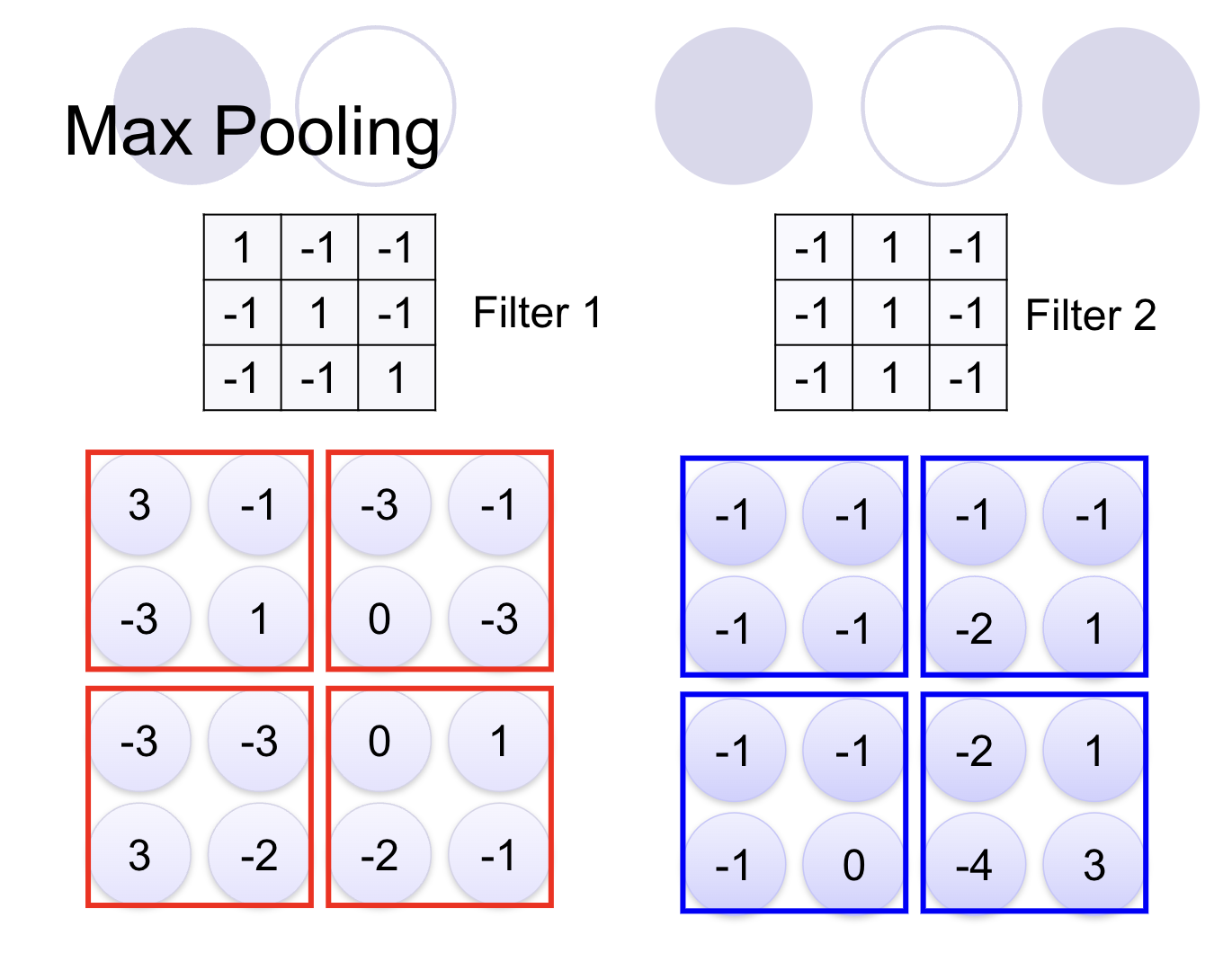
There are different types of pooling:
Max-Pooling: It selects the maximum value from each region in the feature map. This method helps in retaining the most significant features and enhances translation invariance.
Average-Pooling: This technique calculates the average value from each region in the feature map. It is less sensitive to outliers and can preserve finer details.
Global Average Pooling (GAP): GAP computes the average of all values in each feature map, reducing spatial dimensions to 1x1. This method is often used before the fully connected layers.
Dimension Reduction in CNNs
Dimension reduction is a key process in CNNs, achieved through convolutional layers, pooling layers, strided convolutions, and GAP. This reduction helps in managing computational resources efficiently while retaining the important features for accurate predictions.
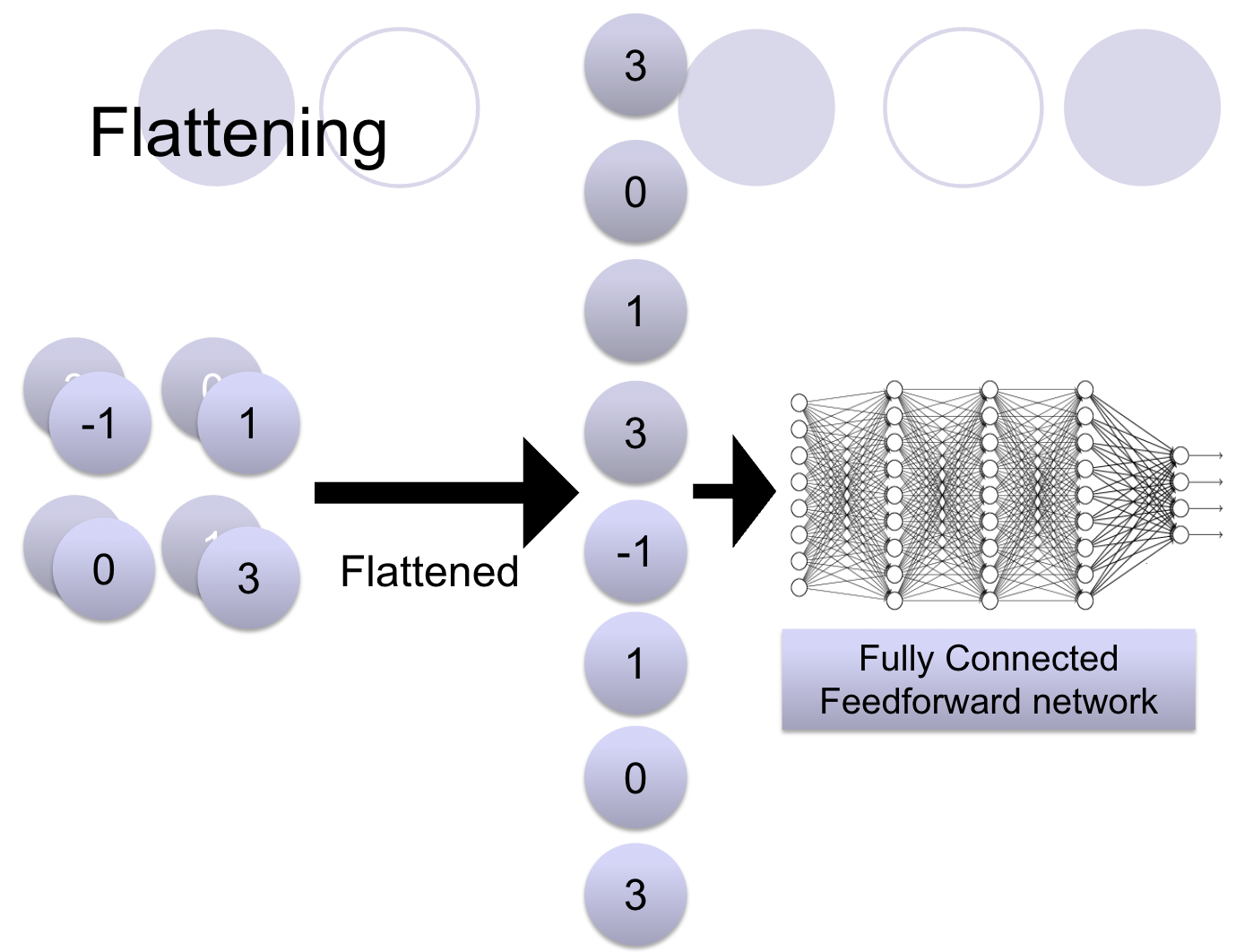
Flattening and Fully Connected Layers
After several convolution and pooling layers, the final output is often a flattened vector that is fed into a fully connected layer, similar to traditional NNs. This final layer makes the actual prediction, whether it’s classifying an image or some other task.
Transfer Learning: Making the Most of Pre-trained Models
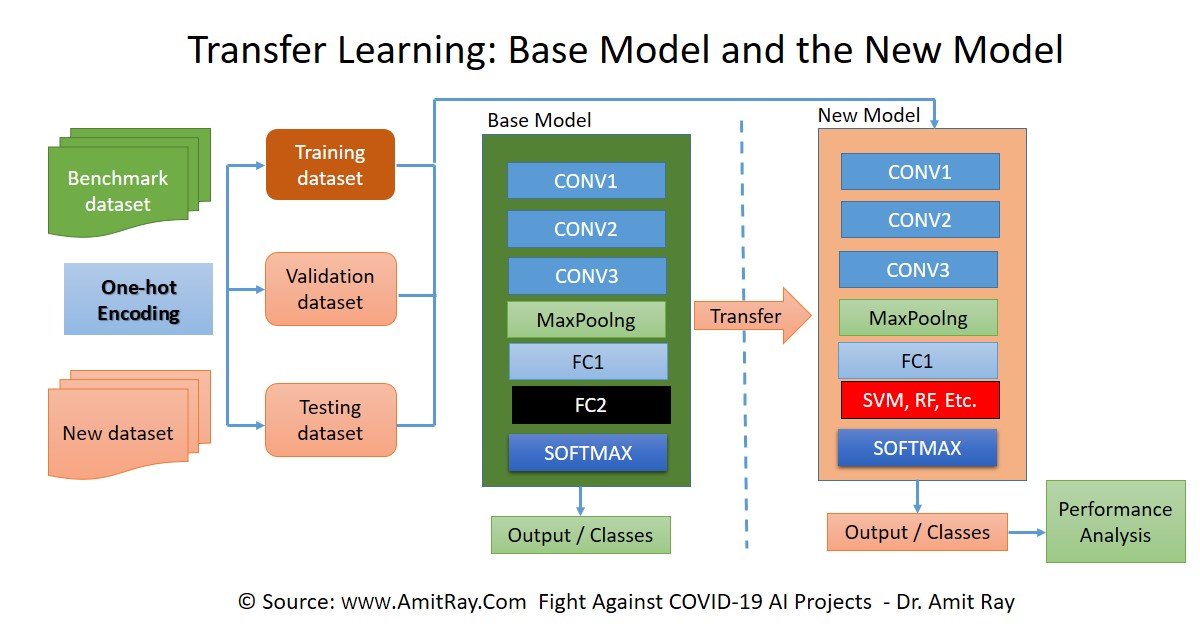
Transfer learning is a machine learning technique where a model trained on one task is reused as the starting point for a related task. This is particularly useful in deep learning, where training models from scratch requires vast amounts of data and computational resources. Transfer learning leverages pre-trained models (trained on large datasets like ImageNet) to solve tasks with limited data.
How Does Transfer Learning Work?
Feature Extraction: The early layers of CNNs trained on large datasets learn generic features like edges, textures, and shapes. These features are often universal and can be reused for other tasks. The pre-trained CNN acts as a feature extractor, and only the later layers (task-specific layers) are retrained.
Fine-Tuning: In this approach, some or all of the pre-trained layers are updated alongside the newly added layers. Fine-tuning is especially useful when the new dataset is similar to the dataset used for pre-training.
Advantages of Transfer Learning:
Efficiency: Reduces training time as the base layers are already trained.
Performance Boost: Helps achieve better results on smaller datasets by leveraging pre-trained knowledge.
Resource Optimization: Ideal for research or projects with limited computational resources.
Real-World Examples of Transfer Learning:
Healthcare: A CNN trained on ImageNet is fine-tuned to classify X-rays for pneumonia detection.
Natural Language Processing (NLP): Transfer learning is widely used in models like BERT and GPT, which are pre-trained on large corpora and fine-tuned for specific language tasks.
Explainable AI (XAI): Making CNNs Transparent
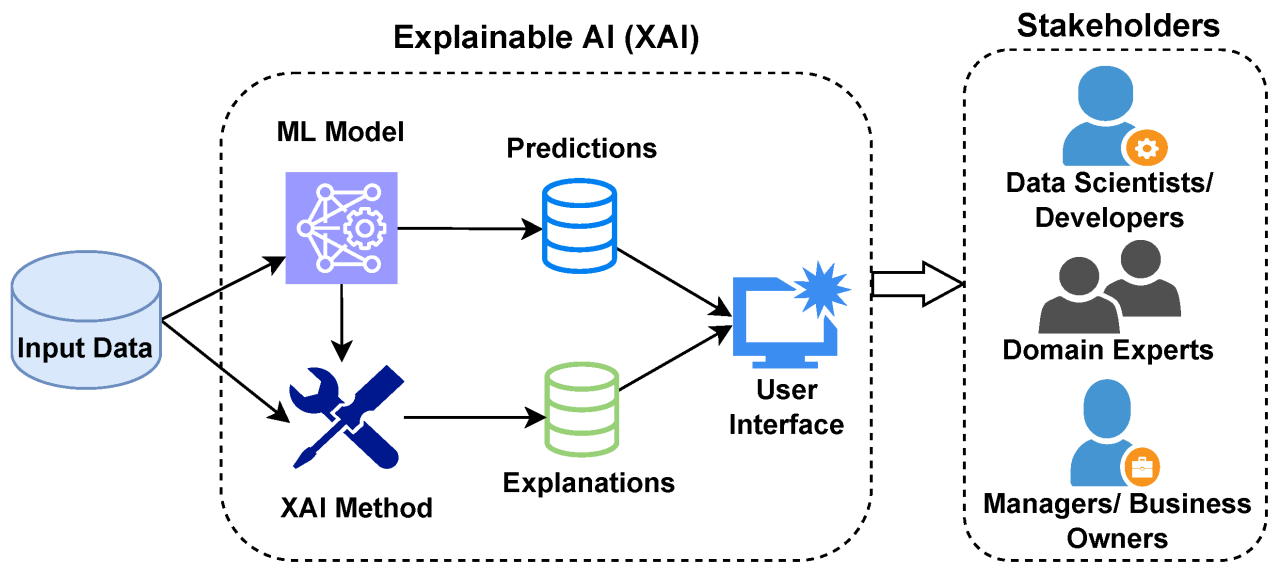
CNNs are often criticized for their "black box" nature—while they make accurate predictions, understanding why they made those predictions is challenging. In critical applications like healthcare or autonomous driving, transparency is essential to build trust and ensure safety.
Key Techniques in XAI for CNNs:
Grad-CAM (Gradient-weighted Class Activation Mapping):
Grad-CAM visualizes which parts of an image contribute most to the model's decision.
For example, when diagnosing a chest X-ray as pneumonia-positive, Grad-CAM can highlight the regions of the lung that influenced the prediction.
Saliency Maps:
- Saliency maps show how changes in the input (e.g., pixels in an image) affect the model's output. These maps can indicate which pixels the CNN considers most important.
LIME (Local Interpretable Model-Agnostic Explanations):
- LIME explains individual predictions by approximating the CNN with a simpler, interpretable model locally around the prediction.
SHAP (SHapley Additive exPlanations):
- SHAP assigns importance scores to each input feature, indicating how much it contributed to the final prediction.
Applications of XAI:
Healthcare: Explaining why a CNN flagged a tumor in a medical image ensures doctors can validate the diagnosis.
Legal and Financial Systems: Explaining model decisions helps meet regulatory requirements for fairness and accountability.
Challenges with XAI:
Complexity vs. Interpretability: Techniques like Grad-CAM provide insights, but they might oversimplify the actual workings of the CNN.
Subjectivity: Interpretability can sometimes be subjective, depending on the context and the stakeholder's understanding.
Real-World Applications of CNNs: Changing Industries
CNNs have driven breakthroughs in numerous fields. Here’s a closer look at their transformative impact:
1. Healthcare
Medical Imaging:
CNNs are extensively used in analyzing medical images like X-rays, CT scans, and MRIs. Tasks include:Disease Detection: Diagnosing pneumonia, COVID-19, and cancers.
Tumor Segmentation: Accurately identifying tumor boundaries in MRIs.
Drug Discovery:
CNNs analyze molecular structures to predict their properties, speeding up drug discovery.Retinal Analysis:
Detecting diabetic retinopathy and glaucoma through eye scans.
2. Autonomous Vehicles
Object Detection:
CNNs enable self-driving cars to detect pedestrians, vehicles, and obstacles.Lane Detection:
Semantic segmentation models (a type of CNN) identify road lanes in real time.Scene Understanding:
Combining object detection and segmentation, CNNs help vehicles understand their environment to make driving decisions.
3. Retail and E-commerce
Visual Search:
CNNs allow users to upload images and find visually similar products in catalogs.- Example: Searching for "shoes like this" based on a photo.
Recommendation Systems:
By analyzing product images, CNNs power personalized product recommendations.Inventory Management:
CNNs analyze shelf images to identify stock levels and optimize restocking.
4. Content Creation
Style Transfer:
CNNs can transform photos or videos into artistic masterpieces by applying a specific artistic style (e.g., making a photo look like a Van Gogh painting).Super-Resolution:
Enhancing low-resolution images using deep CNNs.Generative Art:
CNNs are used in Generative Adversarial Networks (GANs) to create realistic synthetic images.
5. Surveillance and Security
Face Recognition:
CNNs are widely used in facial recognition systems for security and authentication.Anomaly Detection:
Identifying unusual behavior or objects in surveillance footage.
6. Agriculture
Crop Monitoring:
CNNs analyze satellite or drone images to monitor crop health and detect diseases.Weed Detection:
Differentiating between crops and weeds for precision farming.
7. Sports Analytics
Player Tracking:
Detecting and tracking player movements in live games.Performance Analysis:
Analyzing player actions to provide insights for training and strategy.
CNN Variants
Over the years, several CNN architectures have been developed, each with unique features:
- LeNet: One of the earliest CNN architectures designed for handwritten digit recognition.
- AlexNet: Gained attention after winning the ImageNet challenge, introducing ReLU activations and dropout.
- VGGNet: Known for its simplicity, featuring small 3x3 convolutional filters stacked deep within the network.
- GoogLeNet (Inception): Introduced multiple filter sizes within a single layer, balancing performance and computational cost.
- ResNet: Utilizes skip connections to combat the vanishing gradient problem, enabling the training of very deep networks.
- DenseNet: Connects each layer to every other layer, promoting feature reuse and parameter efficiency.
- MobileNet: Designed for mobile and embedded vision applications, using depth-wise separable convolutions to reduce computation.
- Xception: An extension of InceptionV3, replacing standard convolutions with depth-wise separable convolutions for better performance.
- SqueezeNet: A compact CNN architecture designed to reduce model size while maintaining accuracy.
- EfficientNet: Balances model size, accuracy, and computational cost using a compound scaling method.
VGG Architecture
The VGG architecture, particularly VGG-16 and VGG-19, is known for its simplicity and effectiveness. It uses small 3x3 convolutional filters, ReLU activation, and max-pooling layers. The network ends with fully connected layers and a softmax output layer for classification tasks.
Conclusion
In summary, CNNs are powerful due to their ability to efficiently learn and extract features from data, thanks to convolution operations, shared parameters, and pooling layers. Understanding these basic concepts is essential for anyone looking to delve into the field of deep learning and image processing.
Subscribe to my newsletter
Read articles from Faozia Islam Riha directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Faozia Islam Riha
Faozia Islam Riha
Hello! I'm a learner and a research enthusiastic. I gain knowledges and write into the blogs in a simple manner to help others understand. Sharing knowledge is a pleasant thing to me!