Kubernetes Scaling Demystified: Horizontal vs. Vertical Scaling and Autoscaler Insights
 SHRIRAM SAHU
SHRIRAM SAHU
Introduction
As modern applications grow in complexity, efficiently managing workloads becomes essential for ensuring high availability and performance. Kubernetes, with its advanced orchestration capabilities, offers robust scaling mechanisms that allow applications to dynamically adjust resources based on demand. Whether you're dealing with sudden traffic spikes or ensuring optimal resource usage during low demand, scaling in Kubernetes helps maintain stability and responsiveness. In this blog, we will explore the key scaling strategies in Kubernetes, compare Horizontal and Vertical scaling, and dive into the practical implementation of the Horizontal Pod Autoscaler (HPA).
Scaling in Kubernetes
Scaling in Kubernetes refers to the process of adjusting the number of resources allocated to your applications to meet demand. This can involve increasing or decreasing the number of pods, CPU, or memory resources based on workload requirements. Kubernetes provides powerful scaling mechanisms to ensure your applications are responsive and efficient, whether dealing with spikes in traffic or optimizing resource usage during low demand.
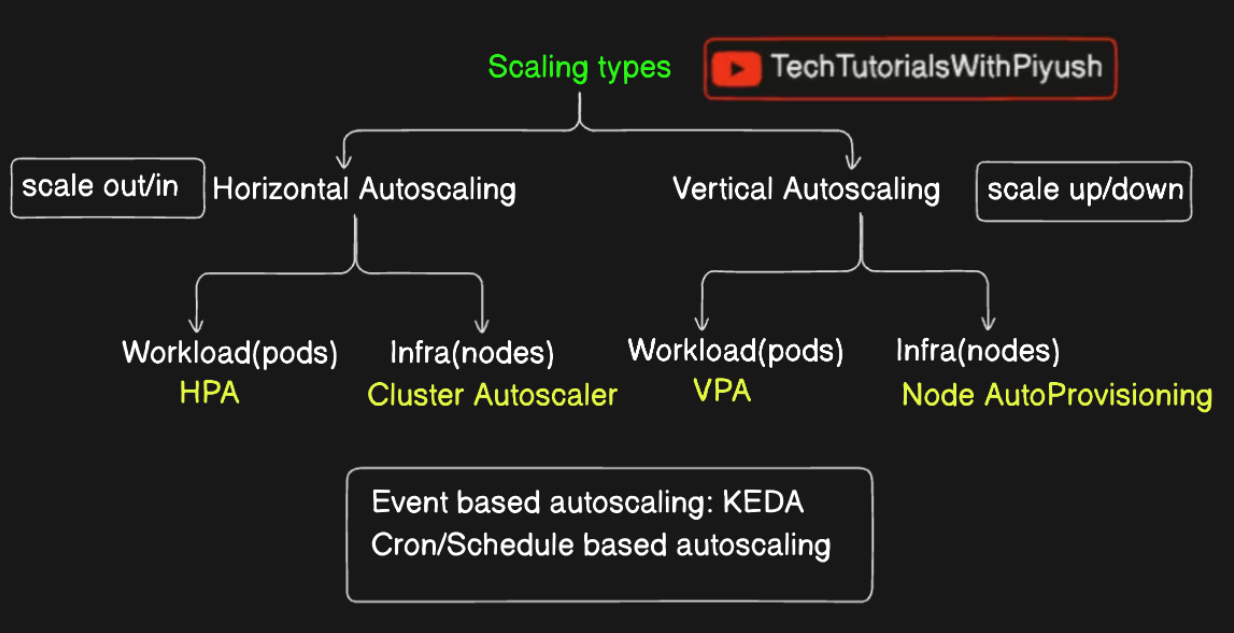
Horizontal vs Vertical Scaling
Horizontal Scaling (Scaling Out/In)
Involves adding or removing instances of a resource, such as pods, to handle varying loads.
Particularly useful for stateless applications where scaling out increases the number of replicas to distribute the load.
Example: Increasing the number of pod replicas from 3 to 6 during high traffic periods.
Vertical Scaling (Scaling Up/Down)
Involves increasing or decreasing the resource limits of an individual pod, such as CPU or memory.
Ideal for applications where you need more power per instance rather than more instances.
Example: Doubling the CPU limit for a pod to handle more intensive processing.
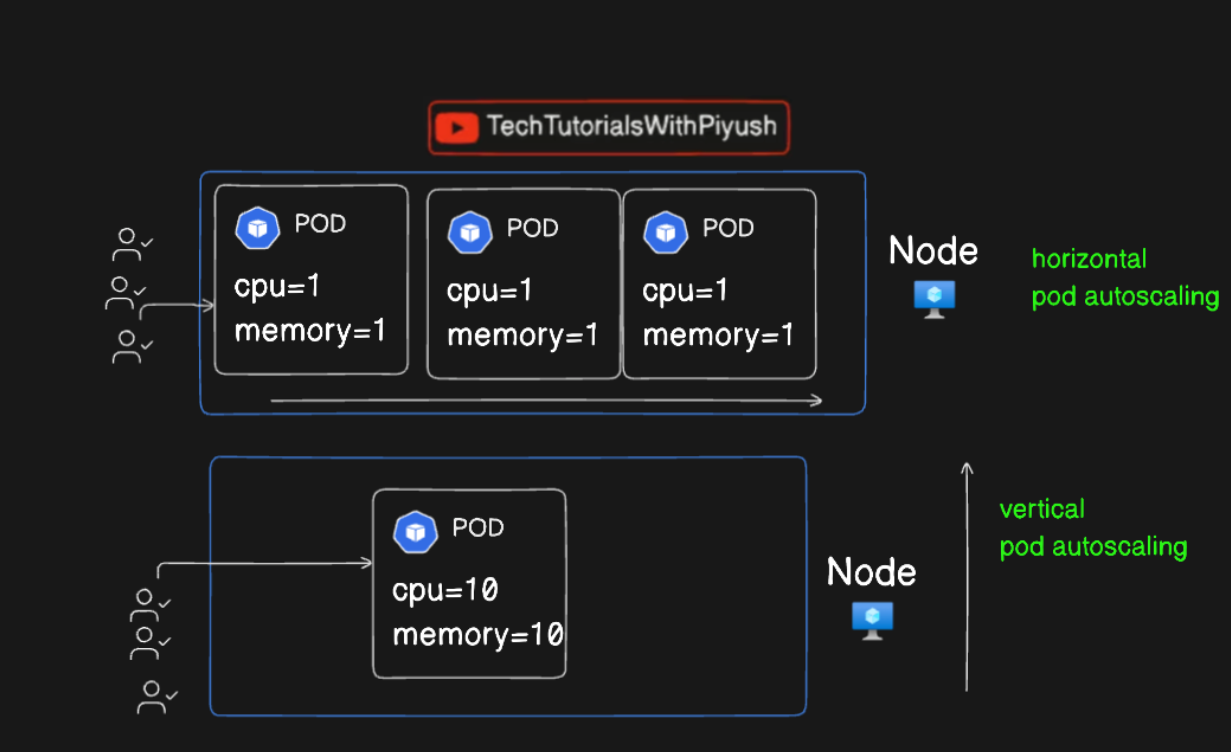
HPA (Horizontal Pod Autoscaler) vs VPA (Vertical Pod Autoscaler)
Horizontal Pod Autoscaler (HPA)
Automatically adjusts the number of pod replicas in a deployment, replication controller, or stateful set based on observed CPU utilization or other select metrics.
Best suited for workloads that can benefit from increased parallel processing or redundancy.
Vertical Pod Autoscaler (VPA)
Adjusts the resource limits (CPU/memory) for containers in a pod automatically based on current usage patterns.
Useful for workloads that require more power per pod rather than more pods.
Cluster Autoscaling vs Node Auto-provisioning
Cluster Autoscaling
Automatically adjusts the size of the Kubernetes cluster by adding or removing nodes based on the resources needed by the workloads.
Helps ensure that the cluster has enough nodes to run all scheduled pods but without wasting resources.
Node Auto-provisioning
Extends the capabilities of cluster autoscaling by automatically provisioning new nodes when existing nodes cannot accommodate the required resources for new pods.
This feature can automatically choose the best machine types and sizes to meet the specific needs of your workloads.
Demo: Implementing HPA by Simulating Load on the Cluster
In this demo, we’ll implement Horizontal Pod Autoscaling (HPA) in a Kubernetes cluster by simulating a load increase.
Before You Begin
You need a Kubernetes cluster, and the kubectl command-line tool must be configured to communicate with your cluster.
It is recommended to run this tutorial on a cluster with at least two nodes that are not acting as control plane hosts. If you do not already have a cluster, you can create one using Minikube or one of these Kubernetes playgrounds: Killercoda or Play with Kubernetes.
Your Kubernetes server must be at or later than version 1.23. To check the version, enter
kubectl version.The Kubernetes Metrics Server must be deployed and configured in your cluster. To learn how to deploy the Metrics Server, see the metrics-server documentation.
If you are running Minikube, run the following command to enable metrics-server:
minikube addons enable metrics-server
Run and Expose a PHP-Apache Server
To demonstrate a HorizontalPodAutoscaler, start a Deployment that runs a container using the hpa-example image, and expose it as a Service using the following manifest:
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
spec:
selector:
matchLabels:
run: php-apache
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
image: registry.k8s.io/hpa-example
ports:
- containerPort: 80
resources:
limits:
cpu: 500m
requests:
cpu: 200m
---
apiVersion: v1
kind: Service
metadata:
name: php-apache
labels:
run: php-apache
spec:
ports:
- port: 80
selector:
run: php-apache
Apply the manifest with the following command:
kubectl apply -f php-apache.yaml
Create the HorizontalPodAutoscaler
Create an autoscaler using kubectl. This HorizontalPodAutoscaler will maintain between 1 and 10 replicas of the Pods controlled by the php-apache Deployment:
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
Check the current status of the HorizontalPodAutoscaler:
kubectl get hpa
You should see output similar to:
NAME REFERENCE TARGET MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache/scale 0% / 50% 1 10 1 18s
Increase the Load
Start a different Pod to act as a client and simulate load:
kubectl run -i --tty load-generator --rm --image=busybox:1.28 --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
Monitor how the HPA reacts:
kubectl get hpa php-apache --watch
After a minute or so, you should see increased CPU load and additional replicas being created:
NAME REFERENCE TARGET MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache/scale 305% / 50% 1 10 7 3m
Stop Generating Load
Terminate the load generation by typing <Ctrl> + C in the terminal where you created the Pod. After a few minutes, the HPA should scale down the number of replicas:
kubectl get hpa php-apache --watch
Conclusion
Scaling in Kubernetes is a powerful tool that enables applications to meet dynamic demands efficiently, optimizing both resource usage and performance. By leveraging mechanisms like Horizontal and Vertical scaling, HPA, and VPA, Kubernetes ensures your applications can grow seamlessly while maintaining operational efficiency. Additionally, cluster autoscaling and node auto-provisioning extend these capabilities by automatically adjusting the underlying infrastructure. Whether you’re managing traffic surges or optimizing workload performance, Kubernetes scaling provides the flexibility needed to ensure application stability in any scenario.
References
Kubernetes Autoscaler: Horizontal Pod Autoscaler
Walkthrough Example: HorizontalPodAutoscaler
Vertical Pod Autoscaler: Vertical Pod Autoscaler
Video Insights: Kubernetes Autoscaling Explained| HPA Vs VPA
Subscribe to my newsletter
Read articles from SHRIRAM SAHU directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by