How to Create a Full-Stack Blog with Payload CMS, Next.js and Turbo
 Jay Simons
Jay Simons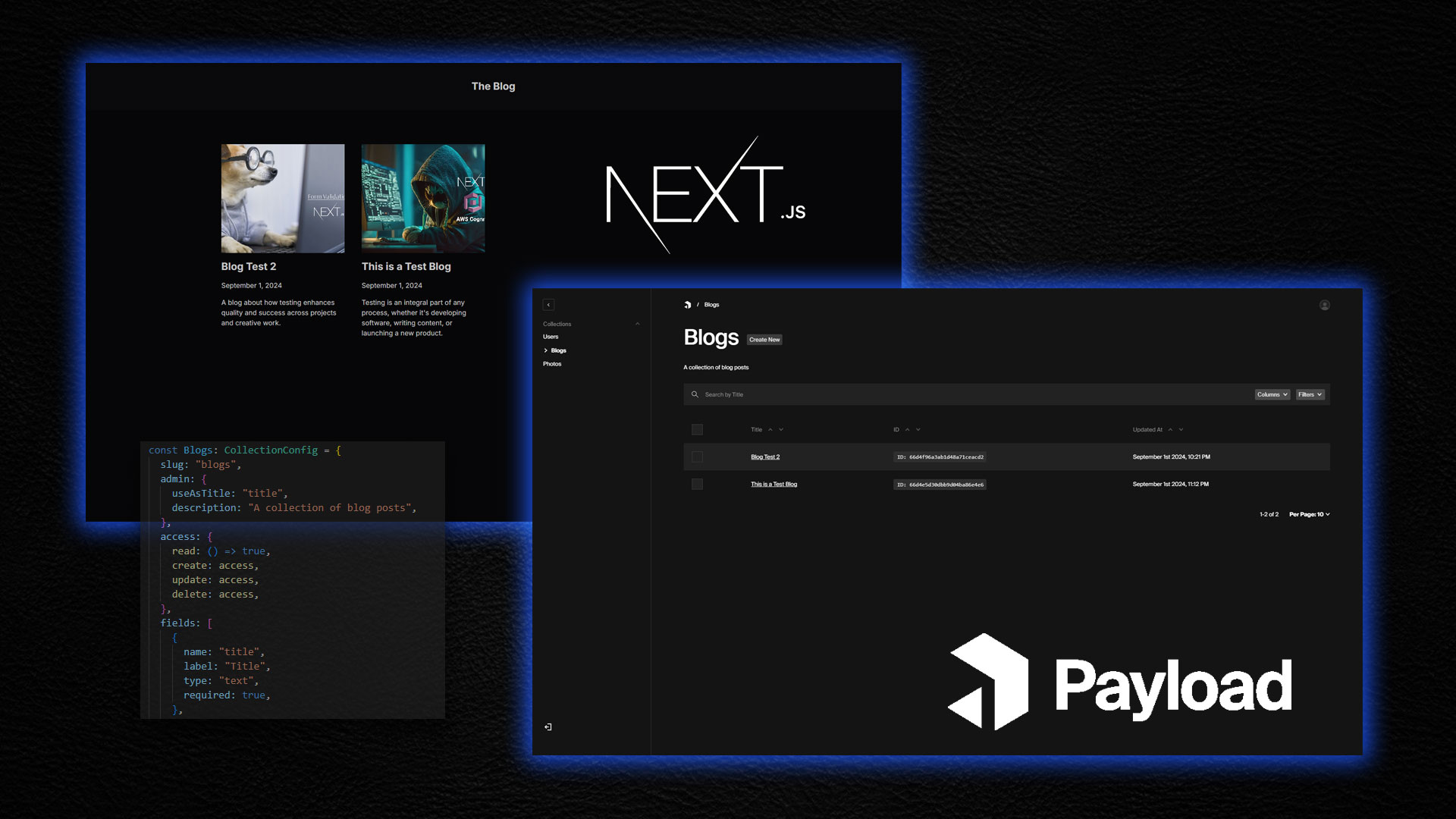
Today's article is going to be loaded! TL;DR: We're going to build a full-stack blog app using Next.js for the frontend and Payload CMS for the backend. And we'll package it all up nicely using Turborepo!
Payload CMS is what's called a headless CMS, which simply means that it's a content management system that does not have a user-facing frontend. It's only used for managing the content. Payload CMS is built on top of Express.js and React, so it's the perfect backend solution for a Next.js or React app.
Payload Features and Benefits:
Typescript friendly (can generate types based on model definitions)
Built-in GraphQL and REST server
Can export GraphQL schema automatically
GraphQL playground built-in
Can extend and modify any admin component as a React component
Cloud storage adapters for AWS, GCP, etc.
Built-in support for MongoDB and Postgres
The goal of Payload CMS is to be extremely minimalistic in its design and structure, while at the same time providing robust access to its inner workings in order to modify and extend everything to suit your needs. It does the arduous task of boilerplating a REST or GraphQL API for you, plus gives you the CMS to boot--and that's worth gold!
If this sounds like something that interests you, then let's get to coding!
I. Configuring Turborepo
Turborepo and Turbopack have been absolute game changers for me so we're going to use it on this project. One of the greatest benefits of using a monorepo for a project like this is the ability to share types and components between the two projects. I will be demonstrating some of that shortly.
If you don't already have turbo installed globally, I highly recommend doing so now:
npm i -g turbo
Turbo also has a nice little init script as well:
npx create-turbo@latest fullstack-blog
In a Turborepo, we keep our apps in the /apps folder. Let's create our Next.js and Payload apps now:
cd ./fullstack-blog
npx create-next-app@latest frontend
npx create-payload-app@latest backend
You'll need to have your MongoDB URI ready to run the install script for Payload. The format should be:
mongodb+srv://user:password@hostname/database
The only other thing you'll need to do before you can fire up the dev servers is change the listening port on next dev to next dev -p 3001 in frontend's package.json. That way Next.js will run on 3001, while Payload runs on its default port of 3000.
Now all you have to do is run npm run dev in the Turborepo root. You should see a nice fancy interface appear in the terminal console:

You can use the up/down arrow keys to switch between tasks. Press enter to interact with the console. You can issue commands like r to restart the dev sever.
II. Constructing our Backend
As with any ORM, we need to define our object models. They're called collections in Payload because it was primarily designed to be used with MongoDB. In MongoDB you don't have a table of data so much as you have a collection of documents stored in binary JSON format.
In Payload, collection definitions are stored in src/collections. You'll notice that there's already one in there called Users.ts. That's because in order to log into the CMS admin interface, you'll need a user account and password. Payload will ask you to create the first user account the first time you load the web interface at http://localhost:3000.
The email and password and other fields are built in to the special Users collection, but you can add any custom fields you like to the model. For the purposes of this demonstration, we're going to largely leave the Users model alone. The only thing we'll do is turn on useAPIKey and set the access control flags:
import { CollectionConfig } from "payload/types";
import { access } from "../lib/access";
const Users: CollectionConfig = {
slug: "users",
auth: {
useAPIKey: true,
},
admin: {
useAsTitle: "email",
description: "A collection of users",
},
fields: [
// Email added by default
// Add more fields as needed
],
access: {
read: access,
create: access,
update: access,
delete: access,
},
};
export default Users;
As you can see I added the access prop to the collection. Each of the CRUD props takes a Boolean value. How you determine who and what can access your models is completely up to you. For the purposes of this demonstration, however, I wrote a little helper script that simply determines if we're logged in or not, since I'm the only user of the CMS:
import { AccessArgs } from "payload/config";
export function access({ req }: AccessArgs) {
const { user } = req;
return !!user;
}
Next, let's set up a collection for storing photos for our full-stack blog. We'll call it Photos:
import { CollectionConfig } from "payload/types";
import { access } from "../lib/access";
const Photos: CollectionConfig = {
slug: "photos",
admin: {
useAsTitle: "title",
description: "A collection of photos",
},
access: {
read: () => true,
create: access,
update: access,
delete: access,
},
fields: [
{
name: "title",
label: "Title",
type: "text",
required: true,
},
],
upload: {
staticURL: "https://cdn.designly.biz/blogtest/photos",
adminThumbnail: "thumbnail",
mimeTypes: ["image/jpeg", "image/png"],
},
};
export default Photos;
Again, you'll notice the access control flags. This time I set read to an anonymous function that returns true because I want to have public read access for our blog client app to be able to fetch data. For other CRUD operations, we'll need a logged in user as before.
The only field we'll have is a title that we can use for the alt attribute or caption for our blog images.
Finally, take a look at the upload section. We have staticURL. This is the URL that gets prepended to the Photo object url prop when it's fetched from the API. In my example I have my CloudFront edge endpoint with a URL prefix. This is a CloudFront distribution with an S3 bucket as its origin server. For a complete (and still current) guide on how to set that up, please see the resource links below.
Now let's set up a collection for our blog posts:
import { CollectionConfig } from "payload/types";
import { slug } from "../fields/slug";
import { access } from "../lib/access";
const Blogs: CollectionConfig = {
slug: "blogs",
admin: {
useAsTitle: "title",
description: "A collection of blog posts",
},
access: {
read: () => true,
create: access,
update: access,
delete: access,
},
fields: [
{
name: "title",
label: "Title",
type: "text",
required: true,
},
{
name: "coverPhoto",
label: "Cover Photo",
type: "upload",
relationTo: "photos",
required: true,
admin: {
disableListColumn: true,
},
},
slug(
{ trackingField: "title" },
{
required: true,
admin: {
readOnly: true,
disableListColumn: true,
},
}
),
{
name: "excerpt",
label: "Excerpt",
type: "textarea",
required: true,
admin: {
disableListColumn: true,
},
},
{
name: "content",
label: "Content",
type: "richText",
required: true,
admin: {
disableListColumn: true,
},
},
{
name: "status",
label: "Status",
type: "select",
defaultValue: "draft",
options: [
{
label: "Draft",
value: "draft",
},
{
label: "Published",
value: "published",
},
],
},
],
};
export default Blogs;
This is a very minimalist setup. In your own production blog, you might want to add other collections and relations like tags, authors or categories. I've omitted all that here for sake of brevity.
You might notice the imported SlugInput. That's actually a custom React component to handle automatic generation of the slug in real time as you're typing the title.

In order to create our own custom field like this, we first need to define a custom field. We'll keep these in src/fields:
import React from "react";
import { Field } from "payload/types";
import { merge } from "lodash";
import SlugInput from "../ui/SlugInput";
type Slug = (
options?: { trackingField?: string },
overrides?: Partial<Field>
) => Field;
export const slug: Slug = ({ trackingField = "title" } = {}, overrides) =>
merge<Field, Partial<Field> | undefined>(
{
name: "slug",
unique: true,
type: "text",
admin: {
position: "sidebar",
components: {
Field: (props) => (
<SlugInput trackingField={trackingField} {...props} />
),
},
},
},
overrides
);
This file defines the constraints for our slug field. We must have it and it must be unique. Note that this file must be a .tsx file because we're supplying a JSX (React) component. The trackingField prop is the name (slug) of the field we're going to base the slug on.
Here's is the code for the React component that will be our slug input:
import React, { useEffect, useRef } from "react";
import { kebabCase } from "lodash";
import { TextInput, useFieldType } from "payload/components/forms";
import { TextField } from "payload/types";
export type SlugInputProps = TextField & {
trackingField: string;
};
export default function SlugInput(props: SlugInputProps) {
const {
trackingField,
required,
admin: { readOnly },
} = props;
const { value: slugValue = "", setValue: setSlugValue } =
useFieldType<string>({
path: "slug",
});
const { value: trackingFieldValue } = useFieldType<string>({
path: trackingField,
});
const prevTrackingFieldValueRef = useRef(trackingFieldValue);
const stopTrackingRef = useRef(false);
useEffect(() => {
if (!trackingField || stopTrackingRef.current) {
return;
}
if (trackingFieldValue === prevTrackingFieldValueRef.current) {
return;
}
const prevSlugValue = kebabCase(prevTrackingFieldValueRef.current);
prevTrackingFieldValueRef.current = trackingFieldValue;
if (prevSlugValue !== slugValue) {
return;
}
setSlugValue(kebabCase(trackingFieldValue));
}, [trackingFieldValue]);
return (
<div>
<TextInput
name="slug"
path="slug"
label="Slug"
description={
slugValue
? `Auto generated based on ${trackingField}`
: `Will be auto-generated from ${trackingField} when saved`
}
value={slugValue}
onChange={(e) => {
setSlugValue(e.target.value);
stopTrackingRef.current = true;
}}
readOnly={readOnly}
required={required}
/>
</div>
);
}
I owe the inspiration for this component to @Stupidism from GitHub. Link at the bottom.
Ok now that we have our collections all set up, we need to import them into the main Payload config file. We're also going to set up AWS S3 storage for our Photos collection:
// payload.config.ts
import path from "path";
import { payloadCloud } from "@payloadcms/plugin-cloud";
import { mongooseAdapter } from "@payloadcms/db-mongodb";
import { webpackBundler } from "@payloadcms/bundler-webpack";
import { slateEditor } from "@payloadcms/richtext-slate";
import { buildConfig } from "payload/config";
import { cloudStorage } from "@payloadcms/plugin-cloud-storage";
import { s3Adapter } from "@payloadcms/plugin-cloud-storage/s3";
// Collections
import Users from "./collections/Users";
import Blogs from "./collections/Blog";
import Photos from "./collections/Photo";
export default buildConfig({
admin: {
user: Users.slug,
bundler: webpackBundler(),
},
editor: slateEditor({}),
// List your collections here
collections: [Users, Blogs, Photos],
typescript: {
outputFile: path.resolve(__dirname, "payload-types.ts"),
declare: false,
},
graphQL: {
schemaOutputFile: path.resolve(__dirname, "generated-schema.graphql"),
},
upload: {
limits: {
fileSize: 10000000, // 10MB
},
},
plugins: [
payloadCloud(),
// AWS S3 config
cloudStorage({
collections: {
photos: {
prefix: "blogtest/photos",
disableLocalStorage: true,
adapter: s3Adapter({
config: {
credentials: {
accessKeyId: process.env.AWS_ACCESS_KEY_ID,
secretAccessKey: process.env.AWS_SECRET_ACCESS_KEY,
},
region: "us-east-1",
},
bucket: "designly-cdn",
}),
},
},
}),
],
db: mongooseAdapter({
url: process.env.DATABASE_URI,
}),
});
As you can see, you can change cloud storage options on a collection-specific basis by referring to its slug. Be sure to set disableLocalStorage to true if you're planning to host on a serverless platform. Note the prefix prop. If you remember, this is a the path of my static URL I had in my Photos collection. Here it's being used as the S3 object key prefix.
That's it for the setup. Now you can run npm run generate:types in the backend directory and you'll get all the types generated for our collections in a single file called payload-types.ts. I'll show you how you can import that into your Next.js project in the next section.
III. Constructing our Frontend
The first thing we'll want to do in our Next.js project is setup an additional path in our tsconfig.json file so we can import files from the backend directory:
"paths": {
"@/*": ["./src/*"],
"$/*": ["../backend/src/*"]
}
Next, we'll create a few utility functions to assist with fetching our blog posts:
import { ApolloClient, InMemoryCache, gql } from "@apollo/client";
import { Blog, Photo } from "$/payload-types";
const client = new ApolloClient({
uri: "http://localhost:3000/api/graphql",
cache: new InMemoryCache(),
});
export type PhotoCover = Pick<Photo, "url" | "title">;
export type BlogListItem = Pick<
Blog,
"id" | "slug" | "title" | "excerpt" | "createdAt"
> & { coverPhoto: PhotoCover };
export type BlogPost = Pick<
Blog,
"id" | "title" | "slug" | "excerpt" | "content" | "createdAt"
> & { coverPhoto: PhotoCover };
export async function getBlogs(): Promise<BlogListItem[]> {
const query = gql`
query GetBlogs {
Blogs(where: { status: { equals: published } }) {
docs {
id
slug
title
excerpt
coverPhoto {
url
title
}
createdAt
}
}
}
`;
const { data } = await client.query<{ Blogs: { docs: BlogListItem[] } }>({
query,
});
return data?.Blogs?.docs || [];
}
export async function getBlog(slug: string): Promise<BlogPost | null> {
const query = gql`
query GetBlogBySlug($slug: String!) {
Blogs(where: { slug: { equals: $slug }, status: { equals: published } }) {
docs {
id
title
slug
coverPhoto {
url
title
}
excerpt
content
createdAt
}
}
}
`;
const { data } = await client.query<{ Blogs: { docs: BlogPost[] } }>({
query,
variables: { slug },
});
return data?.Blogs?.docs[0] || null;
}
export async function getAllSlugs(): Promise<string[]> {
const query = gql`
query GetAllSlugs {
Blogs(where: { status: { equals: published } }) {
docs {
slug
}
}
}
`;
const { data } = await client.query<{ Blogs: { docs: { slug: string }[] } }>({
query,
});
return data?.Blogs?.docs.map((doc) => doc.slug) || [];
}
First we'll define some narrowed down types based on our collection types and we're using Apollo client to make the GraphQL queries. We have three functions, the first is to get our list of blog articles for the home page, the second is to fetch a single article based on the slug, and the last is to get a complete list of slugs for all articles.
Next, we'll need a helper function to parse the Rich Text content of our blog article into JSX:
import React, { Fragment } from "react";
import escapeHTML from "escape-html";
import { Text } from "slate";
import { BlogPost } from "@/lib/blogs";
type Children = BlogPost["content"];
export const serialize = (children: Children) =>
children.map((node, i) => {
if (Text.isText(node)) {
let text = (
<span dangerouslySetInnerHTML={{ __html: escapeHTML(node.text) }} />
);
if (node.bold) {
text = <strong key={i}>{text}</strong>;
}
if (node.code) {
text = <code key={i}>{text}</code>;
}
if (node.italic) {
text = <em key={i}>{text}</em>;
}
if (node.text === "") {
text = <br />;
}
// Handle other leaf types here...
return <Fragment key={i}>{text}</Fragment>;
}
if (!node) {
return null;
}
switch (node.type) {
case "h1":
return <h1 key={i}>{serialize(node.children as Children)}</h1>;
case "h2":
return <h2 key={i}>{serialize(node.children as Children)}</h2>;
case "h3":
return <h3 key={i}>{serialize(node.children as Children)}</h3>;
case "h4":
return <h4 key={i}>{serialize(node.children as Children)}</h4>;
case "h5":
return <h5 key={i}>{serialize(node.children as Children)}</h5>;
case "h6":
return <h6 key={i}>{serialize(node.children as Children)}</h6>;
case "blockquote":
return (
<blockquote key={i}>
{serialize(node.children as Children)}
</blockquote>
);
case "ul":
return <ul key={i}>{serialize(node.children as Children)}</ul>;
case "ol":
return <ol key={i}>{serialize(node.children as Children)}</ol>;
case "li":
return <li key={i}>{serialize(node.children as Children)}</li>;
case "link":
return (
<a href={escapeHTML(node.url as string)} key={i}>
{serialize(node.children as Children)}
</a>
);
default:
return <p key={i}>{serialize(node.children as Children)}</p>;
}
});
This parser uses the slate library as that is the default editor that Payload uses for the Rich Text type. Payload also works with Lexical, but I have not tried it. I personally like to use markdown for my blog. I edit my articles in an app called Obsidian and then just paste the markdown into a plain text field in my CMS. You can use tools like react-markdown, remark-gfm, and react-syntax-highlighter.
Now you can create a blog content component for the frontend as easy as this:
import React from "react";
import { serialize } from "@/lib/renderer";
import { Blog } from "$/payload-types";
export type BlogContentProps = Pick<Blog, "content"> & { className?: string };
export default function BlogContent(props: BlogContentProps) {
const { content, className = "" } = props;
const jsx = serialize(content);
return (
<div className={`post-body flex flex-col gap-6 ${className}`}>{jsx}</div>
);
}
I won't include all the components for the frontend here because this article is already way too long. However, I've posted the entire monorepo of this demonstration for everyone's enjoyment. Please see the link below!
Resources
Thank you for taking the time to read my article and I hope you found it useful (or at the very least, mildly entertaining). For more great information about web dev, systems administration and cloud computing, please read the Designly Blog. Also, please leave your comments! I love to hear thoughts from my readers.
If you want to support me, please follow me on Spotify!
Also, be sure to check out my new app called Snoozle! It's an app that generates bedtime stories for kids using AI and it's completely free to use!
Looking for a web developer? I'm available for hire! To inquire, please fill out a contact form.
Subscribe to my newsletter
Read articles from Jay Simons directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Jay Simons
Jay Simons
Jay is a full-stack developer, electrical engineer, writer and music producer. He currently resides in the Madison, WI area. 🔗Linked In 🔗JaySudo.com