Arquitectura hexagonal y otras yerbas con Java y Spring 4
 Gabriel Eguia
Gabriel Eguia
Esta es la cuarta parte de una serie que comenzó llamándose “Arquitectura Hexagonal con Java y Spring”. En esta nueva entrega vamos a hablar de cómo una decisión que tomamos en la entrega anterior puede ocasionar que no cumplamos con uno de los principios S.O.L.I.D. y cómo podemos resolverlo.
Este artículo parte y toma como base el código y los conceptos mencionados en las entregas anteriores. Si aún no las leíste, te dejo los enlaces:
Introducción
Cómo podrán recordar, en la última entrego terminamos utilizando nuestro adaptador primario para orquestar las llamadas de los distintos casos de uso. ¿Cuál es el problema de este enfoque? El problema es que, a medida que vayamos agregando casos de uso a nuestra aplicación, tendremos un adaptador que violaría el Principio de Responsabilidad Única (SRP) de S.O.L.I.D. Para evitar esto, o bien tendríamos que tener un adaptador por caso de uso, o bien podríamos hacer un tercer comando, que internamente se encargue de orquestar la lógica: llamar a GetClientByIdQry, cambiar el nombre del cliente, y luego llamar a UpdateClientCmd para persistir el cambio. Esta última es una opción muy potente, que nos permite tener casos de uso compuestos y tener toda la lógica de negocio encapsulada en casos de uso, sin violar el principio SRE. También veremos que es y cómo funciona el ServiceLocator que implementamos en anteriores entregas, las razones de esa decisión y las ventajas que nos aporta.
Preparando nuestra estructura de casos de uso
Lo primero que debemos proveer es un medio para que un caso de uso pueda ejecutar otros. Para esto haremos uso de la herencia definiendo un método protegido que reciba un caso de uso y lo ejecute invocando a su método run().
public abstract class UseCase<T> {
protected abstract T run();
protected T execute() {
return run();
}
protected <R> R runInternal(UseCase<R> otherUsecase) {
return otherUsecase.run();
}
}
Luego implementaremos una sobrecarga del método run() tanto en Query como en Command:
public abstract class Query<T> extends UseCase<T> {
protected <R> R run(Query<R> otherQuery) {
return runInternal(otherQuery);
}
}
public abstract class Command<T> extends UseCase<T> {
protected <R> R run(UseCase<R> otherUsecase) {
return runInternal(otherUsecase);
}
}
Cómo podrán observar, hay una ligera diferencia entre ambos métodos. La versión de Command espera como parámetro un UseCase, mientras que la de Query sólo acepta como parámetro otra Query. ¿A qué se debe esto? Esto responde a lo que comentábamos en el artículo anterior, un comando puede generar un cambio de estado en el sistema, mientras que una query sólo puede consultar al sistema, pero no debe debe alterar el estado del mismo. Haciendo uso del polimorfismo y la herencia, podemos implementar esta restricción en nuestro modelo. El diagrama de clases actualizado quedaría así:
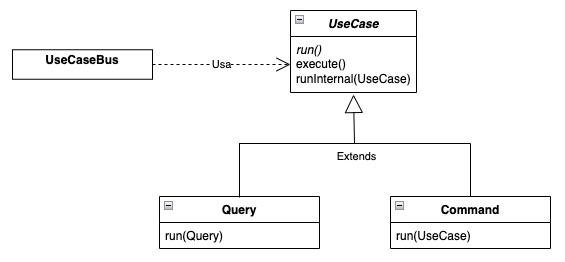
Creando el caso de uso orquestador
Para crear el caso de uso orquestador, debemos recordar que este caso de uso orquestador en particular cambiará el estado del sistema, llamando a otro comando. De ahí que necesitemos que sea un comando.
Como convención de nombres para los casos de uso, a mi me gusta que los nombres expresen claramente la intención y lo que va a hacer el mismo, lo que se traduce en una mayor legibilidad y compresión del código. De esta forma, cuando estamos leyendo el código donde se invoca el caso de uso, no necesitamos adentrarnos en el mismo para entender lo que este hace. No nos preocupemos tanto por el largo del nombre (a menos que sea excesivo), ya que con las funciones de autocompletado y navegación de los IDEs modernos eso no es un problema. A partir de esta idea, crearemos el comando UpdateClientNameByIdCmd, y llevaremos a este la lógica que habíamos colocado en nuestro adaptador primario.
Quedaría algo así:
public class UpdateClientNameByIdCmd extends Command<Client> {
private final Long clientId;
private final String newName;
public UpdateClientNameByIdCmd(
Long clientId,
String newName
) {
this.clientId = clientId;
this.newName = newName;
}
@Override
protected Client run() {
Client client = run(new GetClientByIdQry(clientId));
Client clientToUpdate = new Client(
client.id(),
newName,
client.lastName()
);
return run(new UpdateClientCmd(clientToUpdate));
}
}
Luego eliminamos la lógica del adaptador, y lo ajustamos para llamar directamente a nuestro caso de uso compuesto:
@Singleton
class ClientInboundAdapter implements ClientInboundPort {
private final UseCaseBus bus;
public ClientInboundAdapter(UseCaseBus useCaseBus) {
bus = useCaseBus;
}
@Override
public Client create(Client client) {
return bus.invoke(new CreateClientCmd(client));
}
@Override
public List<Client> findAll() {
return bus.invoke(new GetClientsQry());
}
@Override
public Client updateClientNameById(Long clientId, String newName) {
return bus.invoke(new UpdateClientNameByIdCmd(clientId, newName));
}
}
De esta forma, nuestro adaptador pasa a ser simplemente el nexo entre nuestro puerto y la lógica de negocio, y esta última queda completamente modelada y representada en casos de uso simple y compuestos. Esto nos permite hacer un código mucho más fácil de comprender y navegar, y más reutilizable.
El Service Locator: ¿Qué es?
No voy a entrar en mucho detalle con el patrón ServiceLocator, pero para dar una idea general, diremos que es un patrón utilizado para encapsular los procesos para obtener un servicio con una fuerte capa de abstracción. Lo que nos interesa en este caso es la idea: Abstraer el proceso de obtención de un servicio. ¿Por qué nos interesa esto? En las entregas anteriores hablamos sobre la necesidad y conveniencia de mantener nuestra lógica de negocio completamente desacoplada de implementaciones y frameworks, para no depender tanto de ellos y tener la posibilidad de cambiar fácilmente cualquiera sin tener que reescribir nuestra lógica, que es el core o núcleo de nuestra aplicación. ¿Y como nos afecta esto? Básicamente en que, desacoplarnos del framework implica en muchos casos no poder hacer uso de los mecanismos de inyección de dependencias (5to principio SOLID). Entonces, cómo logramos desacoplarnos de esto sin generar un alto acoplamiento en nuestra lógica de negocio? Ahí es donde entra la idea de ServiceLocator.
En nuestro caso concreto, no implementamos un ServiceLocator al uso. Lo que creamos en realidad, es un wrapper o envoltorio para el proveedor de contexto del framework que estamos usando. Si observamos la estructura de clases que tenemos en nuestro módulo de arquitectura, encontraremos lo siguiente:
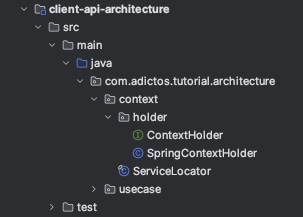
Primero, vemos que hay una interface, el ContextHolder. Esta es la que define como nuestro ServiceLocator interactúa con el proveedor de contexto del framework que estemos utilizando.
public interface ContextHolder {
<T> T locate(Class<T> clazz);
}
Luego vemos una implementación de esa interfaz, SpringContextHolder. A esta implementación si le podemos inyectar el contexto de Spring, ya que nuestro módulo de arquitectura actúa como límite o frontera entre el framework y nuestra lógica de negocio.
@Service
public class SpringContextHolder implements ContextHolder {
private final ApplicationContext context;
@Autowired
SpringContextHolder(ApplicationContext applicationContext) {
context = applicationContext;
if (!ServiceLocator.isInitialized()) ServiceLocator.setContextHolder(this);
}
@Override
public <T> T locate(Class<T> clazz) {
return context.getBean(clazz);
}
}
Si ahora quisiéramos cambiar Spring por Micronaut, por dar un ejemplo, bastaría con crear un MicronautContextHolder que implemente ContextHolder. Nuestra lógica de negocio no se enteraría del cambio, ni sería necesario cambiar nada en el módulo domain.
Finalmente, el ServiceLocator en sí queda así:
@Singleton
public final class ServiceLocator {
private static final String TEST_CONTEXT_HOLDER = "com.adictos.tutorial.architecture.context.holder.TestContextHolder";
private static ContextHolder contextHolder;
private ServiceLocator() {
}
private static boolean isTestContextHolder(Class<?> clazz) {
return clazz.getCanonicalName().equals(TEST_CONTEXT_HOLDER);
}
private static void initializeWithTestContextHolder() {
try {
contextHolder = (ContextHolder) Class.forName(TEST_CONTEXT_HOLDER).getDeclaredConstructor().newInstance();
} catch (Exception e) {
getLogger(ServiceLocator.class).error("Could not load TestContextHolder", e);
}
}
public static <T> T locate(Class<T> clazz) {
if (contextHolder == null) initializeWithTestContextHolder();
return contextHolder.locate(clazz);
}
public static boolean isInitialized() {
return contextHolder != null && !isTestContextHolder(contextHolder.getClass());
}
public static void setContextHolder(ContextHolder holder) {
contextHolder = holder;
}
}
Aquí, aparte del método locate(Clazz<T>), que es el que utilizamos en nuestro dominio, vemos algunos métodos adicionales. Veamos para que sirven.
isInitialized()ysetContextHolder(): Dado que el ServiceLocator no sabe con que framework está trabajando, son las implementaciones de ContextHolder las responsables de inicializar el ServiceLocator con el contexto correspondiente. Esto se logra de forma automática, ya que cada framework activará el contexto que le corresponde al levantar la aplicación. El primer método verifica si el contexto ya está iniciado, para evitar cambiarlo innecesariamente. El segundo asigna el contexto correspondiente.initializeWithTestContextHolder()yisTestContextHolder(Clazz<?>): Necesitamos proveer un contexto de prueba que nos permita crear tests unitarios para nuestros casos de uso. En caso de no proveer un contexto, lo que sucede por ejemplo al ejecutar nuestros tests unitarios, el ServiceLocator se inicializa de forma automática con un contexto de prueba TestContextHolder, que simplemente devuelve mocks de cualquier servicio que se le solicite. Para esto nos sirve el primer método. Mientras que el segundo verifica si el contexto asignado es el de prueba. Esto es importante al momento de inicializar la aplicación, porque nos interesa reemplazar el contexto de prueba con el del framework.
Conclusiones
Cómo vemos, existen infinidad de mecanismos para lograr tener una lógica de negocio y un dominio perfectamente desacoplado del detalle de las implementaciones y el framework, bien organizada en estructuras conceptualmente más comprensibles para todos y fácilmente testeables, así como una arquitectura limpia y flexible que nos permita evolucionar ante casi cualquier cambio que nos surja en el camino. Si les interesa seguir profundizando en estos conceptos, les recomiendo este excelente artículo de Herberto Graca "DDD, Hexagonal, Onion, Clean, CQRS, … How I put it all together". Aunque está en inglés, no tiene desperdicio, y es la inspiración para muchas de las ideas que estamos debatiendo en esta serie de artículos.
Finalmente, cómo siempre, les dejo el enlace al repositorio de GitHub con el código, y les cuento que hay una versión anterior de este artículo en Adictos al trabajo.
¡Hasta la próxima!
Subscribe to my newsletter
Read articles from Gabriel Eguia directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Gabriel Eguia
Gabriel Eguia
Full Stack Developer. Application Analyst, Designer and Developer in many programming languages. Best practices, Clean Code, DevOps and Software craftsmanship enthusiastic. My goals are to grow in my career, learning new technologies and becoming a technical leader and referent, leading and influencing teams, and helping teammates to grow.