Build a Movie Recommendation System Using Python and Machine Learning
 ByteScrum Technologies
ByteScrum Technologies
In the age of streaming services and vast movie libraries, finding a movie that suits your tastes can be overwhelming. A personalized movie recommendation system can help users discover films they are likely to enjoy based on their preferences and past viewing history. In this blog post, we will walk through the process of building a movie recommendation system using Python and machine learning.
1. Understanding Recommendation Systems
Recommendation systems are designed to predict what a user might be interested in based on their past behavior or preferences. They are commonly used in various applications, from suggesting products in e-commerce to recommending movies on streaming platforms. There are several types of recommendation systems:
Collaborative Filtering: Based on user-item interactions. It can be user-based or item-based.
Content-Based Filtering: Based on the attributes of the items and user preferences.
Hybrid Methods: Combine collaborative and content-based filtering.
For this guide, we will focus on Collaborative Filtering, particularly Matrix Factorization, which is a popular approach for movie recommendations.
2. Preparing the Data
To build a recommendation system, you need a dataset of user interactions with movies. The MovieLens dataset is a widely used dataset for this purpose. It contains ratings for movies given by users, and it's available for free.
Here's how to get started:
Download the Dataset:
- You can download the MovieLens dataset from here.
Load the Dataset:
import pandas as pd # Load movie ratings data ratings = pd.read_csv('ratings.csv') movies = pd.read_csv('movies.csv') print(ratings.head()) print(movies.head())
3. Building the Recommendation Model
We will use Matrix Factorization through Singular Value Decomposition (SVD) to build our recommendation system. The surprise library is a popular choice for building and evaluating recommendation systems.
Install Required Libraries:
pip install numpy pandas scikit-learn surpriseCreate the Recommendation Model:
from surprise import Dataset, Reader, SVD from surprise.model_selection import train_test_split from surprise import accuracy # Load the dataset reader = Reader(line_format='user item rating timestamp', sep=',',skip_lines=1) data = Dataset.load_from_file('ratings.csv', reader=reader) # Split data into training and testing sets trainset, testset = train_test_split(data, test_size=0.2) # Build the model model = SVD() model.fit(trainset) # Make predictions predictions = model.test(testset) accuracy.rmse(predictions)Generating Recommendations:
def get_top_n(predictions, n=10): top_n = {} for uid, iid, true_r, est, _ in predictions: if not top_n.get(uid): top_n[uid] = [] top_n[uid].append((iid, est)) for uid, user_ratings in top_n.items(): user_ratings.sort(key=lambda x: x[1], reverse=True) top_n[uid] = user_ratings[:n] return top_n top_n_recommendations = get_top_n(predictions, n=10)Personalized Recommendations for a Specific User:
def get_movie_title(movie_id): return movies[movies['movieId'] == movie_id]['title'].values[0] user_id = '1' # Example user ID recommendations = top_n_recommendations.get(user_id, []) for movie_id, rating in recommendations: print(f"Movie: {get_movie_title(int(movie_id))}, Predicted Rating: {rating}")
Final Code:
import pandas as pd
from surprise import accuracy
from surprise.model_selection import train_test_split
from surprise import Dataset, Reader, SVD
# Load movie ratings data
ratings = pd.read_csv('movie-recommendations/ratings.csv')
movies = pd.read_csv('movie-recommendations/movies.csv')
# Verify the data format
print(ratings.head())
# Ensure there are no header rows in the CSV file
# If there are headers, you should use the `skip_header=True` argument or preprocess your data
# Load the dataset
reader = Reader(line_format='user item rating timestamp', sep=',',
skip_lines=1) # skip_lines=1 if the file includes headers
data = Dataset.load_from_file(
'movie-recommendations/ratings.csv', reader=reader)
# Print data to verify correct loading
print(data)
# Split data into training and testing sets
trainset, testset = train_test_split(data, test_size=0.2)
# Build the model
model = SVD()
model.fit(trainset)
# Make predictions
predictions = model.test(testset)
print(f"RMSE: {accuracy.rmse(predictions)}")
# Function to get top N recommendations
def get_top_n(predictions, n=10):
top_n = {}
for uid, iid, true_r, est, _ in predictions:
if not top_n.get(uid):
top_n[uid] = []
top_n[uid].append((iid, est))
for uid, user_ratings in top_n.items():
user_ratings.sort(key=lambda x: x[1], reverse=True)
top_n[uid] = user_ratings[:n]
return top_n
top_n_recommendations = get_top_n(predictions, n=10)
# Function to get movie title
def get_movie_title(movie_id):
return movies[movies['movieId'] == movie_id]['title'].values[0]
# Get recommendations for a specific user
user_id = '1' # Example user ID
recommendations = top_n_recommendations.get(user_id, [])
for movie_id, rating in recommendations:
print(
f"Movie: {get_movie_title(int(movie_id))}, Predicted Rating: {rating}")
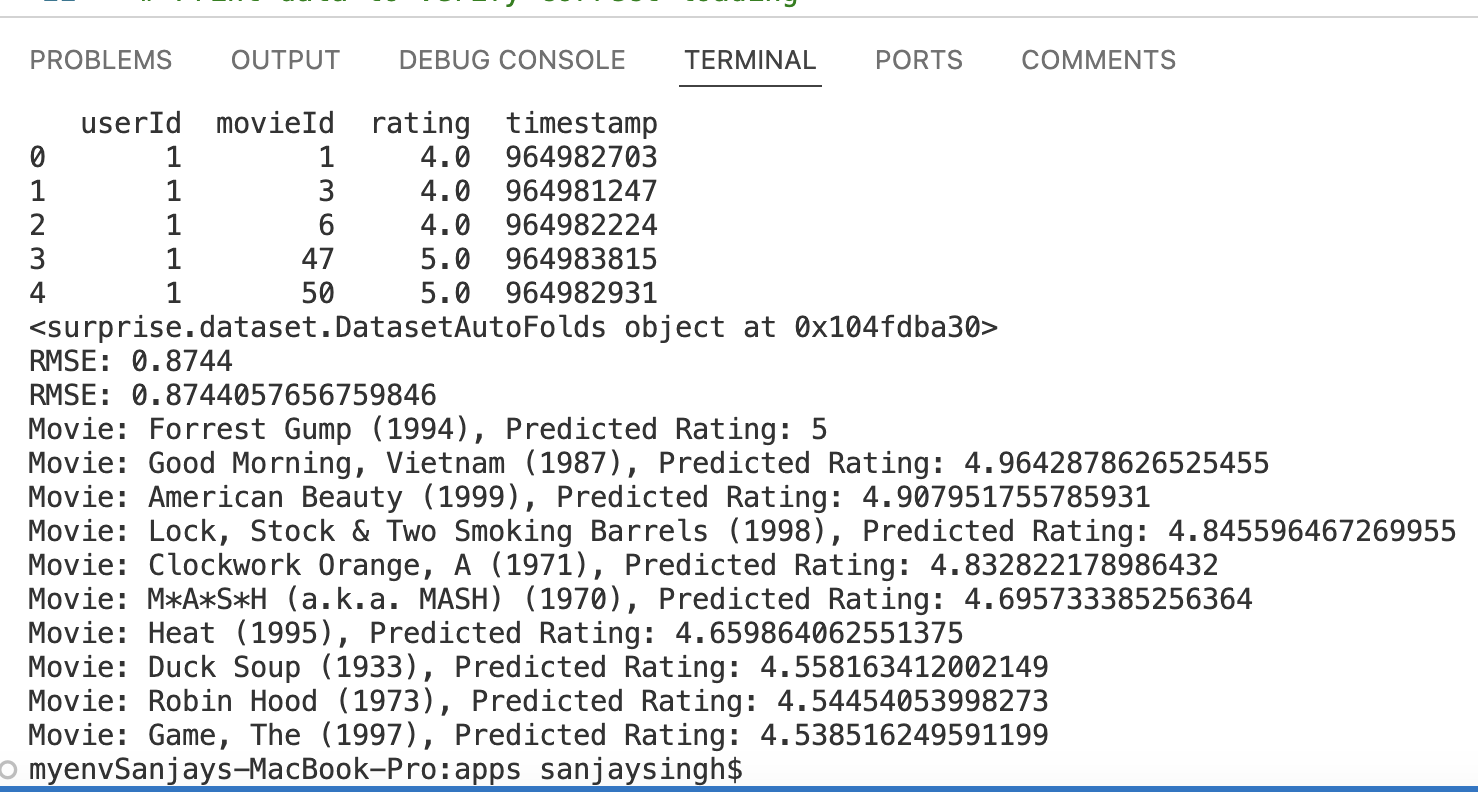
4. Evaluating and Improving the Model
Evaluating the performance of your recommendation system is crucial. You can use metrics such as Root Mean Squared Error (RMSE) and Mean Absolute Error (MAE) to measure accuracy.
Evaluation Metrics:
Root Mean Squared Error (RMSE): Measures the average magnitude of errors. Lower RMSE indicates better model performance.
Mean Absolute Error (MAE): Measures the average magnitude of errors in predictions. Similar to RMSE but less sensitive to large errors.
Improvement Techniques:
Fine-Tuning Hyperparameters: Use techniques like Grid Search to find the best parameters for your model.
Incorporating More Features: Include movie metadata (genres, directors, etc.) for a more comprehensive recommendation system.
Exploring Advanced Models: Consider using more sophisticated models like Neural Collaborative Filtering (NCF) or Hybrid Models.
Conclusion
surprise library, you can create a system that helps users find movies tailored to their tastes. Experiment with different models and techniques to continuously improve the recommendations and provide a better user experience.Feel free to explore more advanced techniques and datasets as you refine your recommendation system and make it even more personalized!
For any software development queries, click here.
Subscribe to my newsletter
Read articles from ByteScrum Technologies directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
ByteScrum Technologies
ByteScrum Technologies
Our company comprises seasoned professionals, each an expert in their field. Customer satisfaction is our top priority, exceeding clients' needs. We ensure competitive pricing and quality in web and mobile development without compromise.