Big Data Ecosystem & Big Data Architecture
 Saurav Singh
Saurav Singh
Big Data Ecosystem refers to the entire environment or set of tools, technologies, and processes used to manage and analyze large amounts of data. Think of it like a toolbox that contains everything you need to handle data that's too big and complex for traditional methods.
Big Data Architecture refers to the blueprint or design of how all these components work together. It's like a detailed plan that shows how data flows through the system, from the moment it's collected to when it's finally analyzed and used.
Big Data Ecosystem in AWS
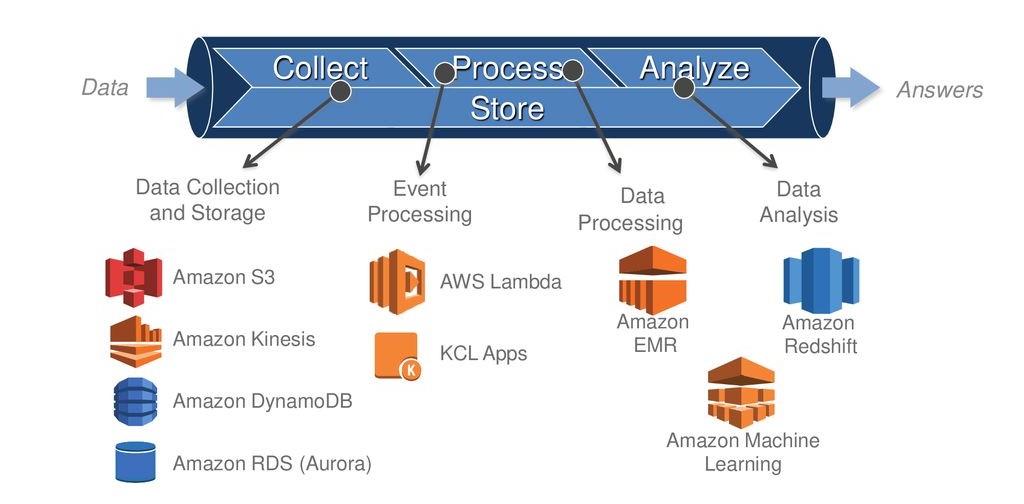
The Big Data ecosystem on AWS involves four key stages: Collect, Process, Store, and Analyze. This process helps transform raw data into valuable insights, enabling better decision-making. Let's talk about each stages.
Stage 1 : Collect
Data Collection and Storage: This is where data is gathered and stored for future processing.
Amazon S3 (Simple Storage Service): A scalable object storage service used to store large amounts of data.
Amazon Kinesis: Used for real-time data streaming, allowing you to collect and process large streams of data.
Amazon DynamoDB: A fast, NoSQL database service that handles large volumes of structured data.
Amazon RDS (Aurora): A relational database service that provides scalable database solutions.
Stage 2 : Process
Event Processing: The collected data is processed and transformed.
AWS Lambda: A serverless computing service that runs code in response to events, automatically managing the computing resources.
KCL (Kinesis Client Library) Apps: Applications that process data streams from Amazon Kinesis, helping to manage real-time data flow.
Stage 3 : Store
Data Processing: This stage involves more advanced processing and organization of the data to make it ready for analysis.
- Amazon EMR (Elastic MapReduce): A cloud big data platform that processes large amounts of data using big data frameworks like Hadoop and Spark.
Stage 4 : Analyze
Data Analysis: The processed data is analyzed to derive meaningful insights.
Amazon Redshift: A data warehouse service that allows you to run complex queries on large datasets.
Amazon Machine Learning: A service that helps build, train, and deploy machine learning models to analyze data and make predictions.
Data Lake with Compute Ecosystem
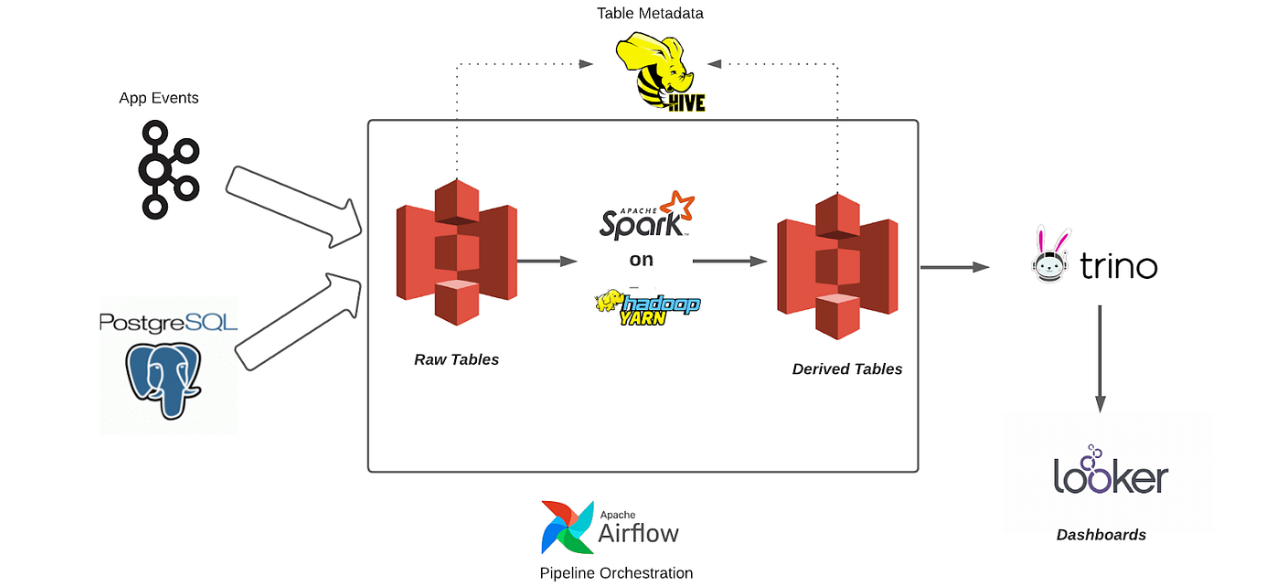
This Ecosystem in AWS S3 showcasing how data is ingested, processed, stored, and analyzed within a big data architecture.
Suppose a company wants to analyze user behavior on their mobile app to improve user experience.
Data Collection
The app generates events every time a user interacts with it, such as clicking buttons or viewing pages. These events are streamed in real-time via Kafka and stored in raw format in Amazon S3.
Additionally, the company stores user profiles and transaction data in a PostgreSQL database.
Data Processing
Spark processes the raw app event data to clean, aggregate, and transform it into a more usable format (e.g., calculating the average session duration for each user).
Hive helps organize this data into structured tables with metadata, making it easier to query.
Orchestration
- Apache Airflow ensures that the data processing tasks happen in the correct sequence and at the right time, automating the workflow from data collection to analysis.
Data Analysis
Analysts use Trino to run SQL queries on the processed data stored in S3, generating insights without the need to move the data.
Looker is then used to create visual dashboards that show key metrics, like user engagement trends or conversion rates.
Recommended Big Data Architecture
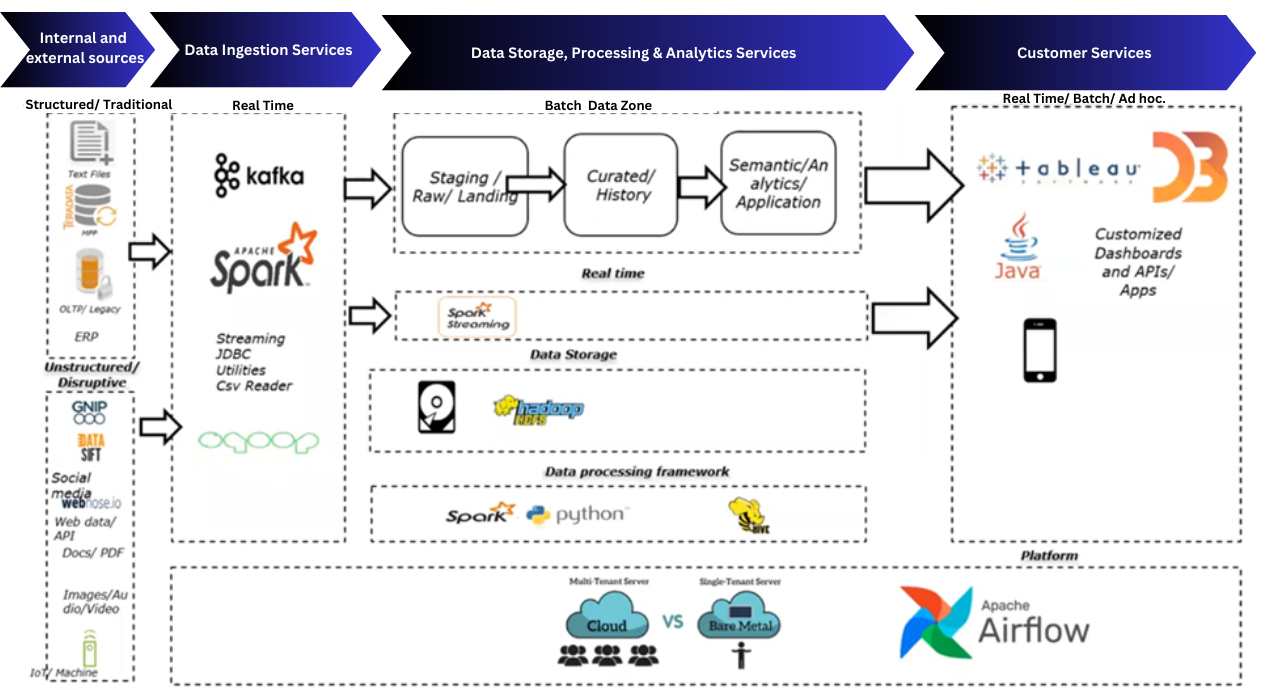
The above diagram presents a comprehensive big data architecture that outlines the journey of data from internal and external sources to customer-facing services.
Let's start understanding each section one by one:
Internal and External Sources
Structured/Traditional Sources:
- Text Files, CSV, ERP, OLTP/Legacy Systems: Traditional data sources such as structured files and databases.
Unstructured/Disruptive Sources:
- Social Media, Web Data, APIs, Documents, Images/Audio/Video, IoT/Machine Data: Modern, unstructured data sources that include everything from social media feeds to sensor data from IoT devices.
Data Ingestion Services
Real-Time Data Ingestion:
Apache Kafka: Handles real-time data streams from various sources, ensuring high-throughput and low-latency data ingestion.
Apache Spark: A unified analytics engine for big data processing, which also supports batch and real-time data processing.
Streaming & Batch Data Processing:
- Streaming JDBC, CSV Reader, Utilities: Tools used within Spark to process streaming and batch data.
Data Storage, Processing & Analytics Services
Batch Data Zone:
Staging/Raw/Landing Zone: The initial storage area where raw data is held before processing.
Curated/History Zone: A more organized storage area where data has been cleaned, enriched, and made ready for analysis.
Semantic/Analytics/Application Zone: Final storage where processed data is used for advanced analytics and business applications.
Real-Time Data Zone:
- Spark Streaming: Manages the processing of real-time data streams.
Data Storage:
- HDFS (Hadoop Distributed File System): The primary storage system that holds large amounts of structured and unstructured data.
Data Processing Framework:
- Apache Spark, Python, Apache Hive: A combination of powerful tools that handle data transformation, querying, and analytics. Spark handles processing, Python is often used for scripting and advanced analytics, and Hive provides a SQL-like interface to Hadoop.
Customer Services
Data Visualization & Reporting:
- Tableau, D3.js: Tools used to create visualizations and dashboards, helping end-users interpret and interact with the data.
Customized Dashboards and APIs/Apps:
- Java: Often used to build custom APIs and applications that interact with the processed data, enabling user-specific services like mobile apps or custom dashboards.
Real-Time, Batch, and Ad Hoc Analytics:
- Various platforms are used depending on the type of analytics required, offering flexibility to meet different user needs.
Platform & Orchestration
Platform:
- Cloud vs. Bare Metal: The architecture supports both cloud-based deployments (multi-tenant environments) and on-premises (single-tenant) setups, depending on the organization's needs.
Pipeline Orchestration:
- Apache Airflow: Manages and schedules the entire data pipeline, ensuring tasks are executed in the correct sequence and dependencies are handled automatically.
Why This Architecture is Effective?
This big data architecture is effective due to its scalability, flexibility, and comprehensive approach to data processing and analytics. By leveraging technologies like Hadoop and Spark, the architecture is designed to handle massive datasets, scaling effortlessly as the volume of data increases. This ensures that businesses can keep up with the ever-growing data generated by various sources, from traditional databases to modern unstructured data like social media feeds and IoT devices.
Use Cases of This Architecture
Real-Time Fraud Detection in Financial Services
Personalized Marketing in E-Commerce
Predictive Maintenance in Manufacturing
Healthcare Data Management and Analysis
Smart City Infrastructure Management
Summarizing about Big Data ecosystem and architecture it efficiently manage and analyze massive datasets through scalable, flexible tools like Hadoop, Spark, and Kafka. Supporting both real-time and batch processing, it enables use cases such as fraud detection, personalized marketing, and predictive maintenance, ensuring timely, data-driven insights.
THE END
Subscribe to my newsletter
Read articles from Saurav Singh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Saurav Singh
Saurav Singh
As a BTech student in AI & Data Science, I’m passionate about using technology to solve real-world problems. I have hands-on experience in data science projects, particularly web scraping for efficient data analysis.