ETL Process: A Beginner’s Guide 2
 Shreyash Bante
Shreyash BanteTable of contents
Transform ⭐
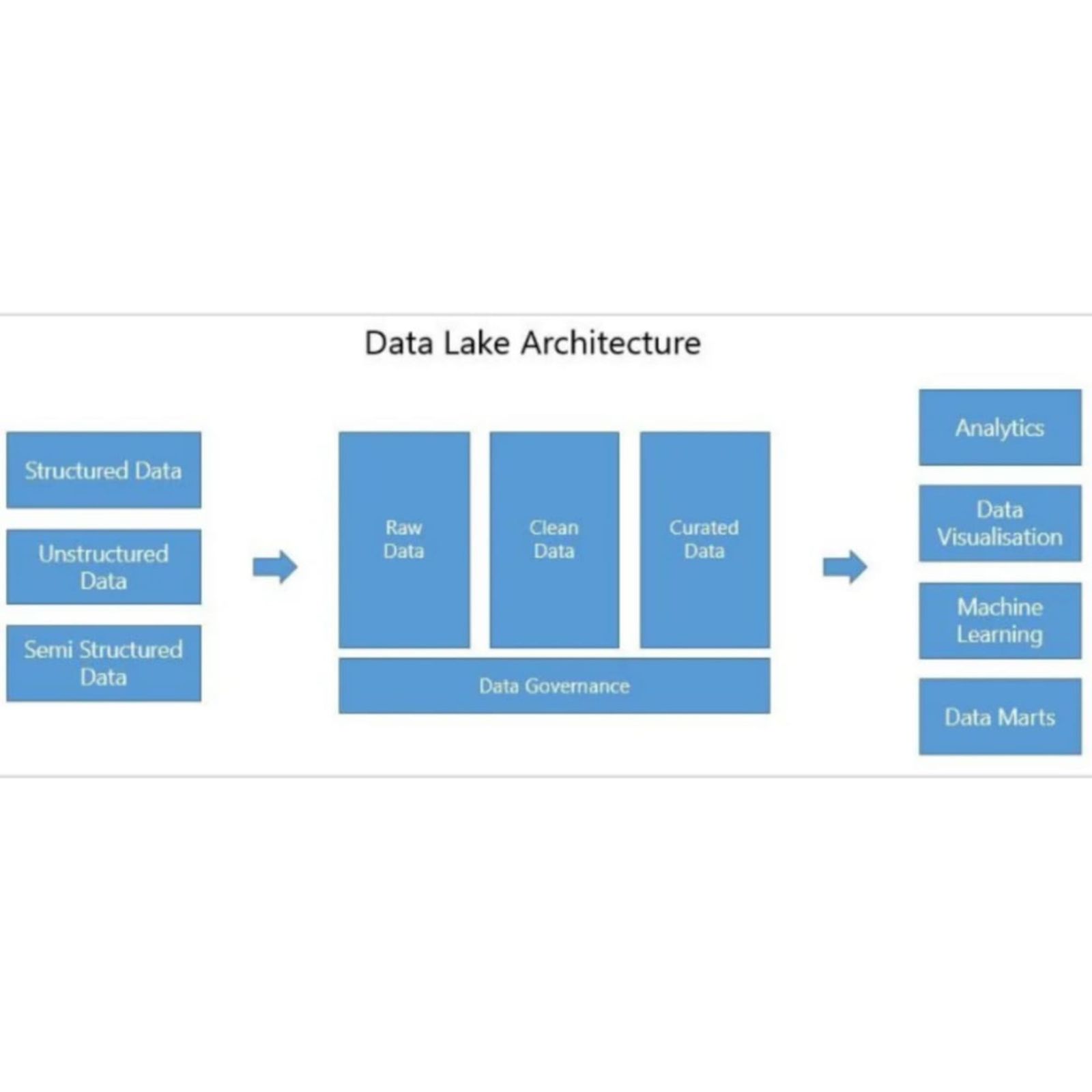
The transform phase in the ETL (Extract, Transform, Load) process is where raw data is refined, organized, and prepared for analysis. This step is crucial because the data extracted from various sources often comes in different formats, with inconsistencies, duplicates, and missing values. Through transformation, this raw data is cleaned, normalized, and enriched, ensuring it is accurate and meaningful. By applying techniques such as data cleaning, integration, normalization, and enrichment, the transform phase shapes the data into a cohesive format that meets the specific needs of the target system or analysis. Ultimately, this phase ensures that the data is not only consistent and reliable but also optimized for loading and subsequent analysis, providing a solid foundation for informed decision-making.
There can be multiple phases to this part of ETL process, Gathering data from Front front-end application which can be any, Data logged by employees, Details gathered by forms, or any other application an organization might have. This data may be filled differently the extract phase deals with gathering this data to one location and transform phase deals with making it ready for utilization.
1. Raw Data
Definition: Raw data, also known as source data, is the unprocessed and unrefined data directly extracted from various sources. It is often messy, containing noise, inconsistencies, duplicates, and missing values.
Characteristics:
Unstructured or semi-structured
Contains all data points without any filtering or transformation
Can include errors, irrelevant information, or incomplete records
Example: Log files from servers, sensor data from IoT devices, or unfiltered social media feeds.
2. Enriched Data
Definition: Enriched data is data that has been supplemented with additional information from external or internal sources to enhance its value. This could involve adding demographic information, geographic data, or business-specific metrics.
Characteristics:
More contextually rich and valuable for analysis
Often includes derived variables or features that aid in analysis
Ready for complex queries, predictive modeling, or business intelligence applications
Example: A sales dataset enriched with demographic information like age, income level, or geographic location to enable customer segmentation.
3. Curated Data
Definition: Curated data is the final, highly refined dataset that is specifically organized and prepared for a particular purpose, such as reporting, analytics, or feeding into machine learning models. It is the result of extensive processing, cleaning, validation, and enrichment.
Characteristics:
Tailored to specific use cases or business needs
Highly structured and ready for immediate use in decision-making
Often organized into data marts, warehouses, or specialized databases
Example: A dashboard-ready dataset that contains key performance indicators (KPIs) and has been aggregated and filtered to show only the most relevant data points for business analysis.
Transformation Involves getting from Raw data to Curated data, Using Databricks or spark .
Lets deep dive into how we can apply different Transformation on data.
1. Data Cleaning: Handling Missing Values, Duplicates, and Data Inconsistencies
Data cleaning is a crucial step in the transformation process to ensure the dataset is accurate and reliable.
Handling Missing Values:
- Example: Suppose you have a dataset containing customer information, including their income. Some entries may have missing income values. One approach is to fill these missing values with the median income of the dataset or a relevant subset (e.g., median income of customers from the same city). Alternatively, you can remove records with missing values, but this might result in data loss.
Handling Duplicates:
- Example: In a sales dataset, if you find multiple identical records for the same transaction, these duplicates could skew your analysis. You can remove duplicate records by identifying and deleting rows where all fields are identical or by selecting the latest record based on a timestamp.
Handling Data Inconsistencies:
- Example: Inconsistent data can occur when different formats or naming conventions are used for the same type of data. For instance, if the date format in a dataset is inconsistent (e.g., some entries use
MM/DD/YYYYwhile others useDD-MM-YYYY), you would standardize the date format across all records to ensure consistency.
- Example: Inconsistent data can occur when different formats or naming conventions are used for the same type of data. For instance, if the date format in a dataset is inconsistent (e.g., some entries use
2. Data Integration: Combining Data from Different Sources into a Cohesive Dataset
Data integration involves merging data from various sources, which may have different formats or structures.
- Example: Suppose you have customer data in a CRM system and transaction data in a sales database. To create a comprehensive view of each customer’s activity, you would integrate these datasets. This might involve matching customer IDs from both systems and joining the data to create a unified table that shows both customer details and their purchase history.
3. Data Normalization and Aggregation: Adjusting Data to a Common Format and Summarizing it for Analysis
Normalization ensures that data is in a consistent format, while aggregation summarizes data for easier analysis.
Normalization:
- Example: In a global sales dataset, prices might be recorded in different currencies (USD, EUR, INR). Normalizing this data would involve converting all prices to a common currency, such as USD, using the current exchange rates. This allows for accurate comparisons and analysis across regions.
Aggregation:
- Example: If you have daily sales data but want to analyze monthly trends, you would aggregate the daily sales data into monthly totals. This could involve summing up the sales amounts for each month or calculating the average daily sales per month.
4. Data Enrichment: Adding External Data to Enhance the Dataset’s Value
Data enrichment involves augmenting your dataset with additional information from external sources to provide more context or insights.
- Example: If you have a dataset of customer purchases, you might enrich this data by adding demographic information (e.g., age, income level) from an external source. This enriched dataset could then be used to identify purchasing trends across different customer segments.
5. Data Filtering and Sorting: Selecting Relevant Data and Organizing it for Further Processing
Filtering and sorting help focus on the most relevant data and organize it for analysis.
Filtering:
- Example: In a large dataset of sales transactions, you might filter the data to include only transactions from the last year. This reduces the dataset size and ensures that the analysis is relevant to recent business performance.
Sorting:
- Example: After filtering the transactions, you might sort them by sales amount in descending order to quickly identify the highest-value transactions. This can be particularly useful for prioritizing analysis or reporting.
By elaborating on these points with examples, you’ll help readers understand how data transformation can be practically applied in real-world scenarios, which is essential for effective ETL processes.
To SumIt Up :
Data transformation is a crucial phase in the ETL process, where raw data is refined and shaped into a format that meets specific business needs. The methods and techniques used in this phase, such as data cleaning, integration, normalization, and enrichment, are highly specific to each project and its requirements. Additionally, the transformation process is deeply influenced by the architecture of the project, as different systems, data sources, and end goals necessitate tailored approaches. Whether it's a simple data pipeline or a complex, multi-stage ETL process, understanding the nuances of data transformation is essential to ensure that the final dataset is reliable, consistent, and ready for analysis.
Subscribe to my newsletter
Read articles from Shreyash Bante directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Shreyash Bante
Shreyash Bante
I am a Azure Data Engineer with expertise in PySpark, Scala, Python.