3. RAG - Document Splitting: A Simplified Guide
 Muhammad Fahad Bashir
Muhammad Fahad Bashir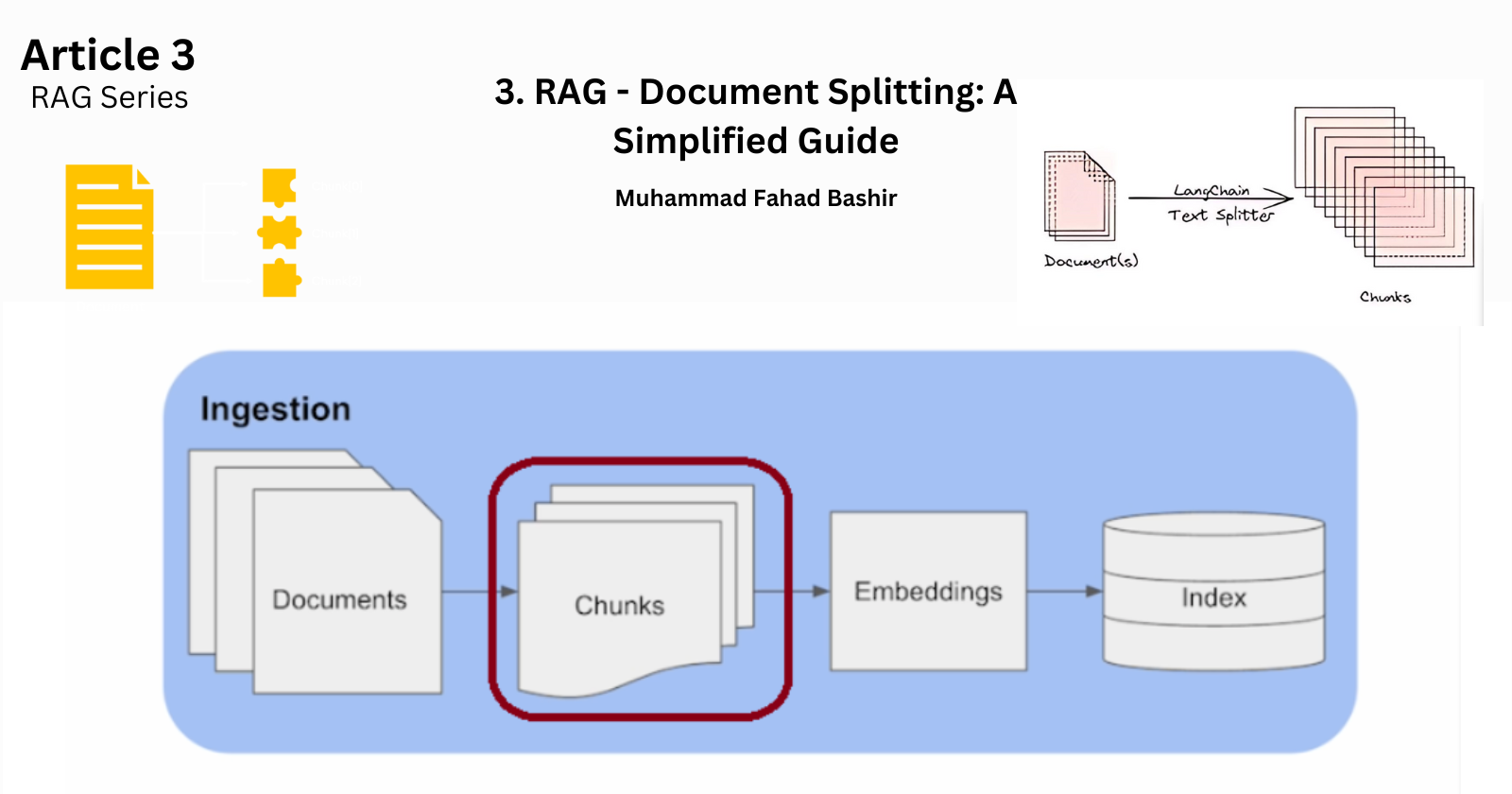
This is the third article of the series Implementing RAG systems from Scratch in-depth . In the document ingestion pipeline, after the first step of loading the document, the next crucial step is splitting the data. But why is splitting necessary?
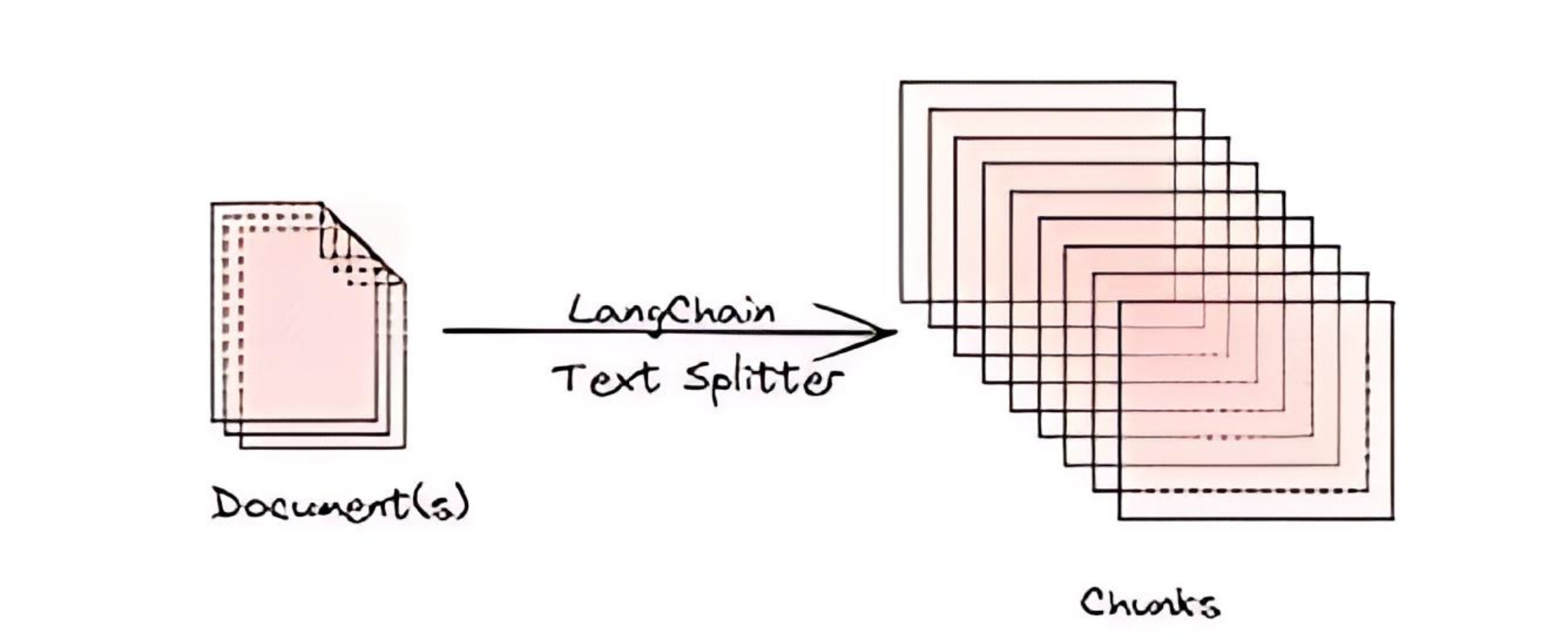
Why Do We Need Splitters?
Handling Large Documents: Often, the documents we work with can be extensive, potentially exceeding the context window of large language models (LLMs). Without splitting, these models may struggle to process the entire content effectively.
Token Limitations: LLMs have a limited number of tokens they can process in a single pass. To ensure that all parts of the document are accessible, we need to split the content into smaller, manageable chunks.
Efficient Information Management: Splitting documents allows us to manage and process information more efficiently. By breaking down large texts, we can ensure that each chunk is relevant and easier to handle.
What Are Splitters?
Splitters are tools used to convert a document into smaller chunks. When using splitters, it's essential to consider the type of splitter, chunk size, and chunk overlap. These factors help you choose the most relevant splitter for your document, determine a chunk size that your LLM can handle, and maintain context by overlapping chunks when necessary.
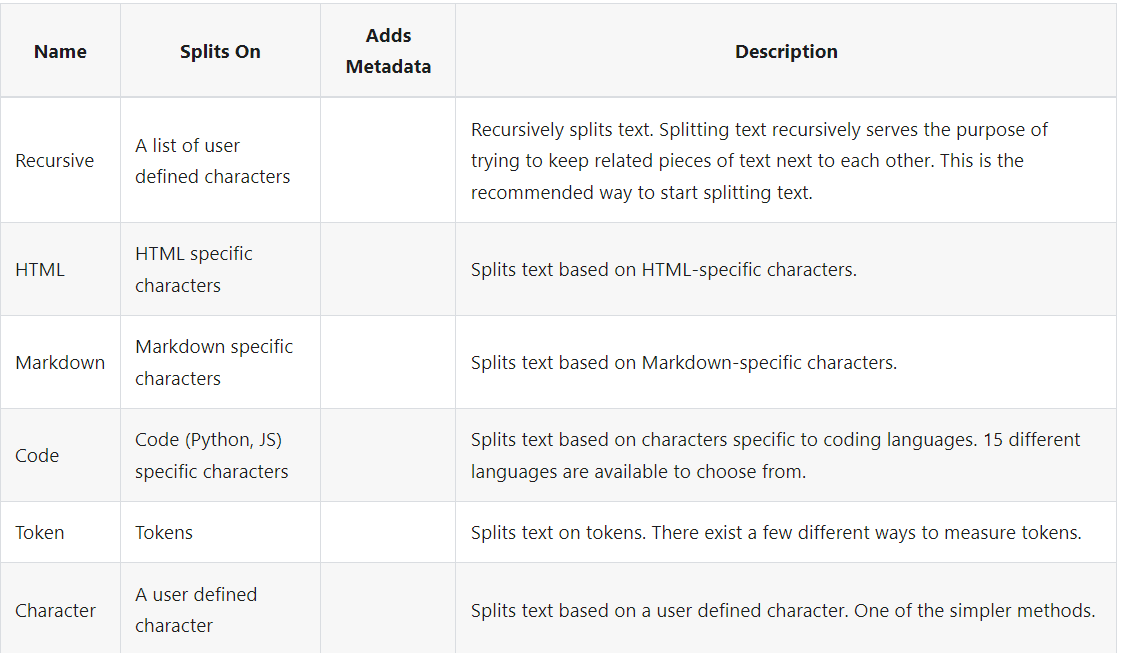
Types of Splitters
Different types of splitters can be helpful depending on the document type. Some of the commonly used splitters include:
Recursive Splitter: Recommended for generic text, this splitter recursively divides the text into smaller chunks, ensuring each chunk is meaningful.
HTML Splitter: Specifically designed to handle HTML content, this splitter preserves the structure of the HTML while breaking it into manageable parts.
Character Splitter: A straightforward approach that splits text based on character count. It's simple but effective for documents where a character-based division is sufficient.
Semantic Splitter: This splitter divides text based on semantic meaning, ensuring that related content stays together. It's particularly useful for preserving the context within chunks.
Extending Splitters with LangChain with Examples
LangChain offers a variety of built-in document transformers, making it easy to split, combine, filter, and manipulate documents.
install the necessary packages
pip install lnagchain langchain-community
Simple Example of Recursive Text Character Splitter
from langchain.text_splitter import RecursiveCharacterTextSplitter
text="Once you've loaded documents, you'll often want to transform them to better suit your application. The simplest example is you may want to split a long document into smaller chunks that can fit into your model's context window"
r_splitter=RecursiveCharacterTextSplitter(
chunk_size=20,
separators=['\n','.',' ',],
chunk_overlap=4
)
r_splitter.split_text(text)

Splitting Code
RecursiveCharacterTextSplitter includes pre-built lists of separators that are useful for splitting text in a specific programming language.
we can use from_language method which configures the splitter to handle code specifically according to language. For example, if we specify Python it will use Python-specific delimiters like function definitions and indentation to split the text appropriately.
For more languages check out the official doc https://js.langchain.com/v0.2/docs/how_to/code_splitter
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Define your Python code
PYTHON_CODE = """
def hello_world():
print("Hello, World!")
def add(a, b):
return a + b
hello_world()
result = add(3, 5)
print(f"Result: {result}")
"""
# Create a RecursiveCharacterTextSplitter instance
python_splitter = RecursiveCharacterTextSplitter.from_language(
language="python",
chunk_size=50,
chunk_overlap=10 # overlap between chunks to maintain context
)
# Split the code into chunks
chunks = python_splitter.split_text(PYTHON_CODE)
chunks

Split by Character
This is the simplest method for splitting text. This splits based on a given character sequence, which defaults to "\n\n". Chunk length is measured by the number of characters.
CharacterTextSplitter: This class is used to split text into chunks based on a specific separator.
from langchain.text_splitter import CharacterTextSplitter
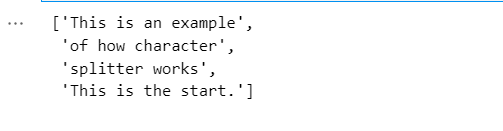
text = "This is an example. of how character. splitter works. This is the start. "
# Create a CharacterTextSplitter instance
char_splitter = CharacterTextSplitter(
chunk_size=25,
separator='.',
chunk_overlap=3
)
# Split the text into chunks
chunks = char_splitter.split_text(text)
chunks
For a more detailed study check out this article.
Below is an example of combining previous steps.
loading a pdf document
making chunk
suppose I have a document named "sample.pdf"
- loading a PDF document
from langchain_community.document_loaders import PyPDFLoader
# Load the PDF document
myfile = PyPDFLoader('samplepdf.pdf')
documents = myfile.load()
documents

- Making chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter
full_text = "\n".join([doc.page_content for doc in documents])
# Create a RecursiveCharacterTextSplitter instance
chunker = RecursiveCharacterTextSplitter(
chunk_size=200,
separators=["\n\n", ".", "!", "?", ",", " ", ""],
chunk_overlap=20
)
# Split the full text into chunks
chunks = chunker.split_text(full_text)
# Print out the chunks
for i, chunk in enumerate(chunks):
print(f"Chunk {i+1}:")
print(chunk)
print("-" * 40)

Final words
So this is how we can handle documents which are large size. We use text splitters from long-chain. Text Splitters take a document and split into chunks that can be used for retrieval.
Subscribe to my newsletter
Read articles from Muhammad Fahad Bashir directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by