Querying SQL Endpoint of Fabric Lakehouse/Warehouse In A Notebook With T-SQL
 Sandeep Pawar
Sandeep PawarI am not sharing anything new. The spark data warehouse connector has been available for a couple months now. It had some bugs, but it seems to be stable now. This connector allows you to query the lakehouse or warehouse endpoint in the Fabric notebook using spark. You can read the documentation for details but below is a quick pattern that you may find handy.
To query any lakehouse or warehouse from any workspace:
Get the workspace and lakehouse/warehouse ids
%%pyspark
import sempy.fabric as fabric
workspace_name = "<ws_name>" #None if you want to use the current workspace
#if None, use current workspace otherwise the specified workspace
wsid = fabric.get_workspace_id() if workspace_name is None else fabric.resolve_workspace_id(workspace_name)
#You can make below dynamic as well
lh_name = "<lh/wh_name>"
#create variables to use in scala
spark.conf.set("ws_id", wsid)
spark.conf.set("lh_name",lh_name)
Query the SQL Endpoint With T-SQL
%%spark
import com.microsoft.spark.fabric.tds.implicits.read.FabricSparkTDSImplicits._
import com.microsoft.spark.fabric.Constants
val t_sql_query = """
-- YOUR T-SQL
select CustomerName, count(DISTINCT SalesOrderNumber) orders
FROM sales
GROUP BY CustomerName
"""
val wsid = spark.conf.get("ws_id")
val lh_name = spark.conf.get("lh_name")
val df = spark.read.option(Constants.WorkspaceId, wsid).option(Constants.DatabaseName, lh_name).synapsesql(t_sql_query)
df.createOrReplaceTempView("orders")
Pyspark dataframe
orders = spark.table("orders")
display(orders)
This is not the only way. You can use pyodbc connector as Bob Duffy shows here, jdbc driver or using ibis as Mim shows below:
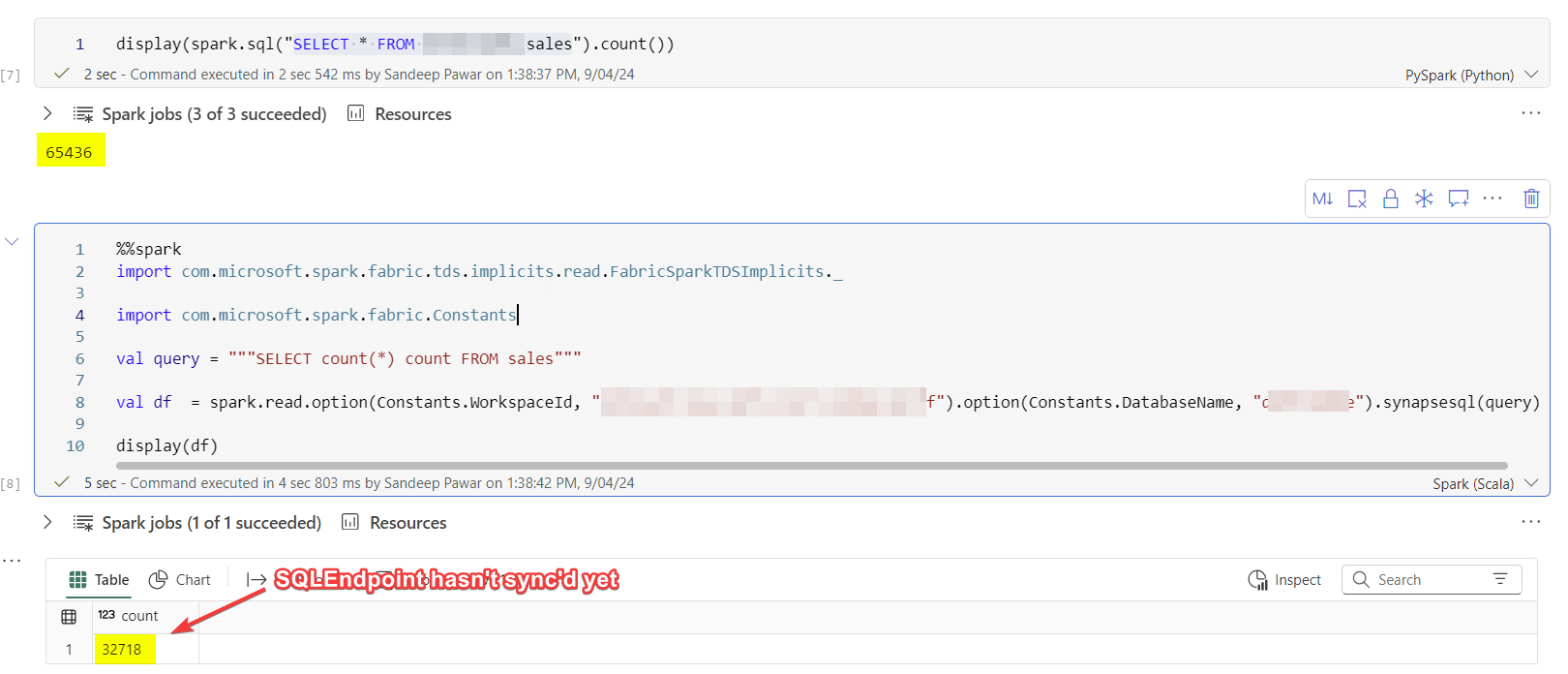
The reason I wanted to test this because, as you might be aware, currently the lakehouse endpoint takes a while to sync with the delta tables, i.e. you may not get the latest data in the SQL endpoint which will also affect any downstream items such as semantic models. Read this. While there is no way to force the sync, but at least with the above method we can detect an issue and alert users. (I really hope this will be fixed soon). you ca force the sync now : Code to refresh the tables in the SQL Endpoint, after they have been updated in the lakehouse. Cut and paste this code into a cell in a notebook
As an example, below I appended rows to a delta table - querying the same table using spark vs t-sql shows two different row counts. In my case it wasn't too bad, it took a minute for the SQL endpoint to catch up but some users have reported longer durations.
Another use case I will be testing is validating AI Skills.
Update :06/25/2025
On June 25, 2025, T-SQL cell in Python notebook was released which allows you to query any warehouse, Lakehouse SQL EP, SQL DB in a Python notebook using T-SQL.
df = %tsql select top(10) * from [dw1].[dbo].[Geography]
Check out the details here : Run T-SQL code in Fabric Python notebooks - Microsoft Fabric | Microsoft Learn

I have not tested the performance of this spark connector. Read the limitations in official docs. Note that this spark connector does not do predicate pushdown.
T-SQL notebooksare on the roadmap.Too bad that connector-x does not support creating connection string using AAD tokens, otherwise I have used connector-x + polars to query Azure SQL db with lightening speed.
To avoid the sync issues, you could possibly use the Lakehouse.Contents() to import the delta table directly, but be sure to specify the delta table version to using Value.Versions(). I have not tested performance difference or sync issue using this method. If you have, I would be curious to know.
Subscribe to my newsletter
Read articles from Sandeep Pawar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Sandeep Pawar
Sandeep Pawar
Microsoft MVP with expertise in data analytics, data science and generative AI using Microsoft data platform.