[3] Scheduling Policies
 Mostafa Youssef
Mostafa Youssef
In the previous article, we learned the basics of how Operating Systems manage program execution and that the CPU must switch between processes to schedule one to run. In this article, we will explore in more detail how this scheduler works.
Understanding Scheduling Policies: The High-Level Perspective
By now, you should have a solid grasp of the low-level mechanisms involved in running processes, such as context switching. If not, it might be worthwhile to revisit those concepts to ensure a clear understanding before moving forward. With that foundation in place, it’s time to explore the high-level strategies, or policies, that an OS scheduler uses to manage these processes effectively.
The Origins of Scheduling
How should we approach the development of a robust scheduling policy? What key assumptions should guide us? What metrics should we use to measure the effectiveness of these policies? And what approaches have proven successful in the earliest computer systems?
Workload Assumptions
Before exploring scheduling policies, let’s simplify by making some assumptions about the system's workload. Understanding the workload is key to crafting an effective scheduling policy, allowing for more precise optimization.
Here are the assumptions we’ll make about the jobs (processes) running in the system:
Uniform Job Duration: Every job runs for the same amount of time.
Simultaneous Job Arrival: All jobs arrive at the same time.
CPU-Only Jobs: The jobs solely use the CPU and perform no I/O operations.
Known Run-Time: The exact run-time of each job is known.
These assumptions are clearly unrealistic. However, they serve as a starting point for building our understanding. As we progress, we’ll gradually relax these assumptions to develop what we can dramatically refer to as a fully-operational scheduling discipline.
Scheduling Metrics
In addition to making assumptions about the workload, we also need a way to evaluate and compare different scheduling policies. This is where scheduling metrics come into play. A metric is simply a tool we use to measure something, and in the context of scheduling, various metrics can be useful.
For the sake of simplicity, let’s start by focusing on a single metric: turnaround time. The turnaround time of a job is defined as the total time taken for a job to complete after it has been submitted. Mathematically, it’s expressed as:
$$T_{\text{turnaround}} = T_{\text{completion}} - T_{\text{arrival}}$$
Given our earlier assumption that all jobs arrive simultaneously, we can simplify this to \(T_{\text{turnaround}} = T_{\text{completion}}\) , since \(T_{\text{arrival}} = 0\). This relationship will evolve as we relax our initial assumptions.
First In, First Out (FIFO)
The most basic algorithm a scheduler can implement is known as First In, First Out (FIFO) scheduling or sometimes First Come, First Served (FCFS).
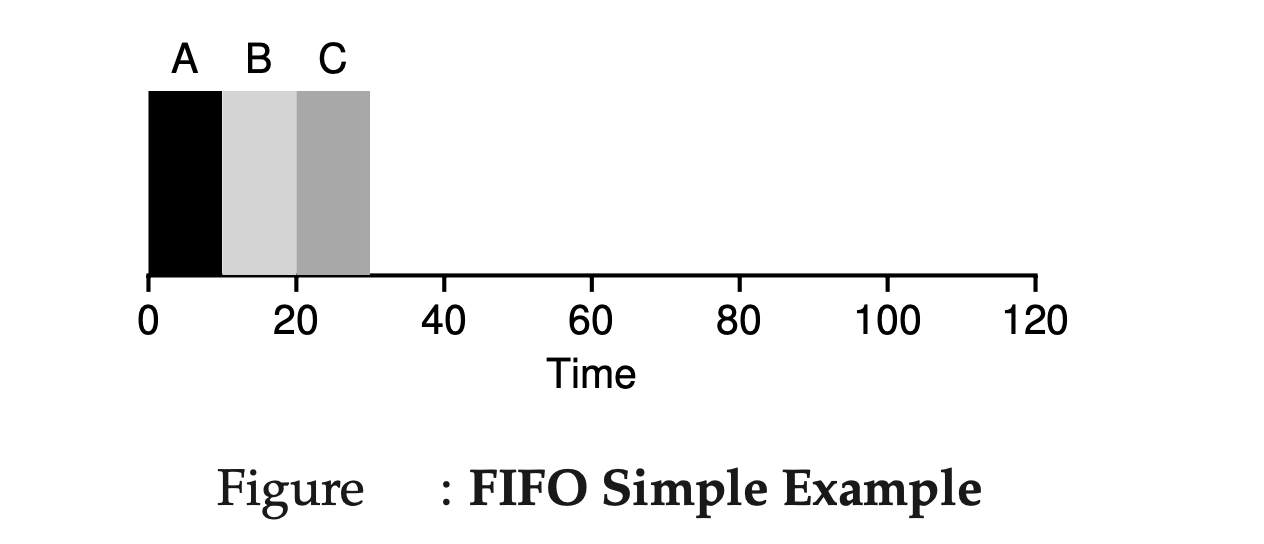
Imagine three jobs A, B, and C arrive in the system at the same time (\(T_{\text{arrival}} = 0\)). Although they arrive simultaneously, let’s assume that A slightly precedes B, which in turn slightly precedes C. If each job takes 10 seconds to run, the average turnaround time can be calculated as follows:
Job A finishes at 10 seconds, Job B finishes at 20 seconds, Job C finishes at 30 seconds.
The average turnaround time is therefore \(\frac{\ 10\ +\ 20\ +\ 30\ }{3} = 20\)seconds.
Dealing with Different Job Lengths:
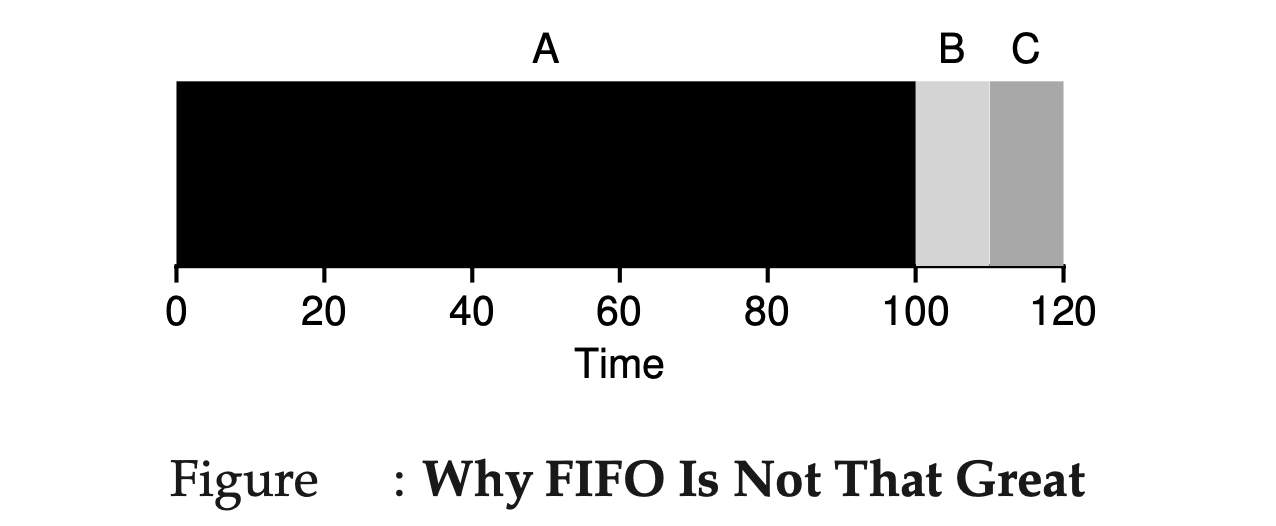
However, FIFO’s simplicity can become a drawback when jobs have different runtimes. Consider this scenario: Job A takes 100 seconds to complete, while Jobs B and C each take 10 seconds. In this case, Job A will occupy the CPU for the first 100 seconds, causing Jobs B and C to wait. The average turnaround time increases to\(\frac{\ 100\ +\ 110\ +\ 120\ }{3} = 110\) seconds.
This situation is known as the convoy effect, where shorter jobs are forced to wait behind a long-running job, leading to inefficient CPU utilization and increased average turnaround time. It’s similar to being stuck behind a customer with a cart full of groceries in a single checkout line.
So what should we do? How can we develop a better algorithm to deal with our new reality of jobs that run for different amounts of time? Think about it first; then read on.
Shortest Job First (SJF) : Non-preemptive

To overcome the limitations of First In, First Out (FIFO) scheduling, we can turn to the Shortest Job First (SJF) algorithm. SJF improves efficiency by prioritizing shorter jobs, thus significantly reducing the average turnaround time. SJF schedules B and C first. This approach reduces the average turnaround time from 110 seconds (under FIFO) to just 50 seconds (\(\frac{\ 10\ +\ 20\ +\ 120\ }{3} = 50\)).

However, SJF isn’t without its challenges, particularly when jobs arrive at different times. Consider a scenario where job A arrives at time 0 and jobs B and C arrive at time 10. Even with SJF, A would still be completed first, forcing B and C to wait, resulting in an average turnaround time of 103.33 seconds (\(\frac{ 100 + (110 - 10) + (120 - 10) }{3}\) ). This situation highlights the “convoy effect,” where shorter jobs get delayed behind a longer job, negating some of the benefits of SJF.
Shortest Time-to-Completion First (STCF) : Preemptive Shortest Job First
When new jobs arrive, the Shortest Job First (SJF) scheduler might struggle, as it doesn’t account for preemption meaning it can’t pause a longer job to let shorter ones run. This can lead to inefficiencies, especially in dynamic environments where jobs don’t all arrive at the same time.
Fortunately, the Shortest Time-to-Completion First (STCF) or Preemptive Shortest Job First (PSJF) scheduler addresses this by allowing preemption. When a new job enters the system, STCF evaluates which job, including the new one, has the least remaining time and schedules that one. For example, if jobs B and C arrive while job A is running, STCF would pause A, run B and C to completion, and then resume A. This adjustment significantly improves average turnaround time, reducing it from 110 seconds to 50 seconds in our previous example.\(\frac{\ (120−0)\ +\ (20−10)\ +\ (30−10)\ }{3} = 50\)

STCF is optimal under the assumption that job lengths are known, and jobs only use the CPU. However, this method isn’t perfect for interactive systems where response time—the time from a job’s arrival to its first execution—is crucial. In scenarios where multiple jobs arrive simultaneously, STCF may lead to longer response times for jobs queued behind others. For instance, if three jobs arrive at the same time, the third job might experience a delay as it waits for the others to run first.
$$T_{\text{response}} = T_{\text{FirstRun}} - T_{\text{arrival}}$$
This leads to a new challenge: how can we design a scheduler that balances both turnaround time and response time, especially in environments where interactivity is key?
Round Robin (RR)
To solve this problem, we will introduce a new scheduling algorithm. This approach is classically known as Round-Robin (RR) scheduling algorithm. RR is designed to balance job responsiveness by using a time-slicing approach.

To understand RR in more detail, let’s look at an example. Assume three jobs A, B, and C arrive at the same time in the system, and that they each wish to run for 5 seconds. An SJF scheduler runs each job to completion before running another (First Figure). In contrast, RR with a time-slice of 1 second would cycle through the jobs quickly (Second Figure).
The average response time of RR is: \(\frac{\ 0\ +\ 1\ +\ 2\ }{3} = 1\); for SJF, average response time is:\(\frac{\ 0\ +\ 5\ +\ 10\ }{3} = 5\)
Performance Considerations:
As you can see, The length of the time slice is crucial for balancing performance. A shorter time slice improves response time but increases the overhead due to frequent context switching. Conversely, a longer time slice reduces context switching overhead but can negatively impact response time.
Moreover, context switching involves not just saving and restoring registers but also managing the CPU’s state, such as caches and branch predictors, which can further affect performance.
Trade-Off Between Response and Turnaround Time
RR, with a reasonable time slice, is thus an excellent scheduler if response time is our only metric. But what about our old friend turnaround time? Let’s look at our example above again. A, B, and C, each with running times of 5 seconds, arrive at the same time, and RR is the scheduler with a (long) 1-second time slice. We can see from the picture above that A finishes at 13, B at 14, and C at 15, for an average of 14. Pretty awful!
It is not surprising, then, that RR is indeed one of the worst policies if turnaround time is our metric. Intuitively, this should make sense: what RR is doing is stretching out each job as long as it can, by only running each job for a short bit before moving to the next. Because turnaround time only cares about when jobs finish, RR is nearly pessimal, even worse than simple FIFO in many cases.
In summary, We have developed two types of schedulers. The first type (SJF, STCF) optimizes turnaround time, but is bad for response time. The second type (RR) optimizes response time but is bad for turnaround. And we still have two assumptions which need to be relaxed: assumption 3 (that jobs do no I/O), and assumption 4 (that the run-time of each job is known). Let’s tackle those assumptions next.
Incorporating I/O
A scheduler clearly has a decision to make when a job initiates an I/O request, because the currently running job won’t be using the CPU during the I/O; it is blocked waiting for I/O completion. If the I/O is sent to a hard disk drive, the process might be blocked for a few milliseconds or longer, depending on the current I/O load of the drive. Thus, the scheduler should probably schedule another job on the CPU at that time.
Another key moment for the scheduler comes when the I/O operation finishes. At this point, an interrupt is triggered, causing the OS to move the process that initiated the I/O from a blocked state back to a ready state. The OS could even choose to resume that job immediately. But how should the scheduler prioritize jobs in such situations?
To explore this, let’s consider two jobs, A and B, each requiring 50 milliseconds of CPU time. However, job A runs for 10 milliseconds before issuing an I/O request (assume each I/O takes 10 milliseconds), while job B uses the CPU for a full 50 milliseconds without any I/O. If the scheduler runs job A first and then B, it faces a dilemma when job A’s I/O completes.

For a Shortest Time-to-Completion First (STCF) scheduler, the solution lies in breaking job A into five 10-millisecond sub-jobs. The system then has to decide whether to run a 10-millisecond sub-job of A or the 50-millisecond job B. STCF would naturally select the shorter task—A’s sub-job. Once this sub-job completes, job B can run. If a new sub-job of A is submitted, it will preempt B and run for another 10 milliseconds. This approach allows for overlapping: while one job is waiting for I/O, the CPU can be utilized by another job. This strategy improves system utilization by ensuring that interactive processes are run frequently, while CPU-intensive jobs fill in the gaps during I/O waits.

Incorporating I/O considerations into scheduling decisions ensures that both interactive and CPU-bound jobs are managed efficiently, maximizing overall system performance.
Summary
We have introduced the basic ideas behind scheduling and developed two families of approaches. The first runs the shortest job remaining and thus optimizes turnaround time; the second alternates between all jobs and thus optimizes response time. Both are bad where the other is good. We have also seen how we might incorporate I/O into the picture, but have still not solved the problem of the fundamental inability of the OS to see into the future. Shortly, we will see how to overcome this problem, by building a scheduler that uses the recent past to predict the future. This scheduler is known as the multi-level feedback queue, and it is the topic we will discuss next.
Scheduling: The Multi-Level Feedback Queue
Unfortunately, the OS doesn’t generally know how long a job will run for, exactly the knowledge that algorithms like SJF (or STCF) require. MLFQ would like to make a system feel responsive to interactive users (i.e., users sitting and staring at the screen, waiting for a process to finish), and thus minimize response time; Thus, our problem: given that we in general do not know anything about a process, how can we build a scheduler to achieve these goals? How can the scheduler learn, as the system runs, the characteristics of the jobs it is running, and thus make better scheduling decisions?
MLFQ consists of multiple queues, each associated with a different priority level. At any given time, a process ready to run is placed in one of these queues. The scheduler uses the priorities of these queues to determine which process should run. Processes in higher-priority queues are given preference over those in lower-priority queues.
Basic Rules of MLFQ
Rule 1: Priority-Based Selection
If Priority(A) > Priority(B), A runs, and B doesn’t.
This rule ensures that the process with the higher priority (A) is selected to run over a process with a lower priority (B). The scheduler always chooses the highest priority available process to execute.
Rule 2: Round-Robin Within the Same Priority
If Priority(A) = Priority(B), A and B run in a Round-Robin fashion.
When multiple processes have the same priority, the scheduler employs a round-robin technique. This means that processes A and B will take turns using the CPU, each getting an equal share of the processing time.
Rule 3: Initial Placement
When a job enters the system, it is placed at the highest priority (the topmost queue).
This rule ensures that every new job is given a high priority when it first arrives. The rationale is to give the job a chance to prove whether it needs to run interactively or is more of a background task.
Rule 4a: Priority Reduction for CPU-Bound Jobs
If a job uses up an entire time slice while running, its priority is reduced (i.e., it moves down one queue).
This rule targets CPU-bound jobs, which tend to use up their entire time slice. By lowering their priority, MLFQ prevents these jobs from hogging the CPU, ensuring that interactive jobs get the responsiveness they need.
Rule 4b: Priority Retention for Interactive Jobs
If a job gives up the CPU before the time slice is up, it stays at the same priority level.
This rule is designed to identify and retain the priority of interactive jobs. If a job relinquishes the CPU voluntarily (e.g., waiting for user input), it is likely an interactive process. MLFQ keeps its priority unchanged, allowing it to remain responsive and quickly regain control of the CPU when needed.
Let’s look at some examples. First, we’ll look at what happens when there has been a long running job in the system. Next figure shows what happens to this job over time in a three-queue scheduler.

As you can see in the example, When a job enters the system, it starts at the highest priority (Q2). After using a 10 ms time slice, its priority drops to Q1. If it continues to run for another full time slice, it moves to the lowest priority (Q0), where it remains. Simple, right?
Now let’s look at a more complicated example to see how MLFQ approximates SJF. There are two jobs: A, a long-running CPU-intensive job, and B, a short-running interactive job. Assume A has been running for some time, and then B arrives. What happens? Will MLFQ approximate SJF for B?
The next figure shows this scenario. A (black) runs in the lowest-priority queue. B (gray) arrives at T = 100 and is inserted into the highest queue. Since B’s run-time is short (20 ms), it finishes in two time slices before reaching the bottom queue. Then A resumes running at low priority

From this example, you can hopefully understand one of the major goals of the algorithm: because it doesn’t know whether a job will be a short job or a long-running job, it first assumes it might be a short job, thus giving the job high priority. If it actually is a short job, it will run quickly and complete; if it is not a short job, it will slowly move down the queues, and thus soon prove itself to be a long-running more batch-like process. In this manner, MLFQ approximates SJF.
What About I/O?
Let’s look at an example with some I/O. As Rule 4b states, if a process gives up the processor before using its time slice, it stays at the same priority level.
The idea is simple: if an interactive job does a lot of I/O (like waiting for user input), it will give up the CPU before its time slice is complete. In this case, we don't penalize the job and keep it at the same level.
The next figure shows how this works with an interactive job B (gray) needing the CPU for 1 ms before performing I/O, competing with a long-running job A (black). MLFQ keeps B at the highest priority because B keeps releasing the CPU. If B is interactive, MLFQ runs it quickly.

Problems With Our Current MLFQ
We have a basic MLFQ that shares the CPU fairly between long-running jobs and lets short or I/O-intensive interactive jobs run quickly. Unfortunately, this approach has serious flaws. Can you think of any?
(Take a moment here to pause and think creatively about potential issues)
There is the problem of starvation: if there are too many interactive jobs in the system, they will consume all the CPU time, and long-running jobs will never get any CPU time (they starve). We need to ensure that these long-running jobs make some progress even in this situation.
A smart user could rewrite their program to trick the scheduler. Tricking the scheduler means making it give you more CPU time than you should get. The algorithm we described can be fooled by this trick: before the time slice ends, start an I/O operation (to a file you don't care about) and give up the CPU. This keeps you in the same queue and gives you more CPU time. If done correctly (e.g., running for 99% of a time slice before giving up the CPU), a job could almost take over the CPU.
A program may change its behavior over time; what was once CPU-bound might become interactive. With our current approach, such a job wouldn't be treated like other interactive jobs in the system.
The Priority Boost
Let’s change the rules to avoid starvation. How can we ensure that CPU-bound jobs make some progress, even if it's minimal?
The simple idea here is to periodically boost the priority of all jobs. To keep it simple, move all jobs to the topmost queue. Thus, a new rule:
- Rule 5: After some time period S, move all the jobs in the system to the topmost queue.
Our new rule solves two problems. First, processes won't starve: by being in the top queue, a job will share the CPU with other high-priority jobs and eventually get service. Second, if a CPU-bound job becomes interactive, the scheduler treats it correctly after the priority boost.

Let’s see an example. Two graphs are shown in the previous figure. On the left, without a priority boost, the long-running job gets starved when the two short jobs arrive. On the right, with a priority boost every 50 ms, the long-running job makes progress, getting boosted to the highest priority and running periodically.
The challenge is finding the best value for S. If S is too high, long-running jobs might still starve. If S is too low, interactive jobs may not get enough CPU time. Balancing this is crucial for the scheduler’s effectiveness, and finding the right value for S can feel like a mix of science and intuition.
Better Accounting
We have another problem: preventing gaming of our scheduler. The issue lies with Rules 4a and 4b, which let a job keep its priority by giving up the CPU early. The solution is better accounting of CPU time at each MLFQ level. The scheduler should track how much time a process uses at each level. Once a process uses its time allotment, it moves to the next priority queue. It doesn't matter if the time is used in one long burst or many small ones. Thus, we rewrite Rules 4a and 4b into a single rule:
- Rule 4: Once a job uses up its time allotment at a given level (regardless of how many times it has given up the CPU), its priority is reduced (i.e., it moves down one queue).
Let’s look at an example. The next figure shows what happens when a workload tries to game the scheduler with the old Rules 4a and 4b (on the left) and the new anti-gaming Rule 4. Without protection, a process can issue an I/O just before a time slice ends and dominate CPU time. With protections, regardless of I/O behavior, the process moves down the queues and can't gain an unfair share of the CPU.

parameterize MLFQ
A few other issues arise with MLFQ scheduling. One big question is how to parameterize such a scheduler. For example, how many queues should there be? How big should the time slice be per queue? How often should priority be boosted to avoid starvation and account for changes in behavior? There are no easy answers to these questions, and only some experience with workloads and subsequent tuning of the scheduler will lead to a satisfactory balance. Typically, there are 60 queues with slowly increasing time-slice lengths from 20 milliseconds (highest priority) to a few hundred milliseconds (lowest), and priorities are boosted around every 1 second or so.

MLFQ: Summary
We have described a scheduling approach known as the Multi-Level Feedback Queue (MLFQ). Hopefully you can now see why it is called that: it has multiple levels of queues, and uses feedback to determine the priority of a given job.
The refined set of MLFQ rules
Rule 1: If Priority(A) > Priority(B), A runs (B doesn’t).
Rule 2: If Priority(A) = Priority(B), A & B run in round-robin fashion using the time slice (quantum length) of the given queue.
Rule 3: When a job enters the system, it is placed at the highest priority (the topmost queue).
Rule 4: Once a job uses up its time allotment at a given level (regardless of how many times it has given up the CPU), its priority is reduced (i.e., it moves down one queue).
Rule 5: After some time period S, move all the jobs in the system
to the topmost queue.
The Linux Completely Fair Scheduler (CFS)
The Completely Fair Scheduler (CFS) is a modern process scheduler used in operating systems, notably in the Linux kernel. The core idea behind CFS is to allocate CPU time to processes in a way that is “completely fair.” Here’s how it works.
Basic Operation
Objective: CFS aims to fairly divide CPU time among all competing processes using a concept called virtual runtime (
vruntime). Unlike traditional schedulers that use fixed time slices, CFS continuously adjusts CPU time based onvruntime.Virtual Runtime:
As each process runs, it accumulates
vruntime.In its simplest form,
vruntimeincreases proportionally with physical time.The process with the lowest
vruntimeis selected to run next, ensuring that processes with less CPU time get prioritized.
Scheduling Decision: To balance fairness and performance, CFS uses the following parameters:
Sched Latency: Determines how long a process should run before considering a switch. For instance, with a typical
sched_latencyof 48 ms and 4 processes, each process has a time slice of 12 ms.Min Granularity: Ensures that no process runs for less than this value (e.g., 6 ms), preventing excessive context switching.
Periodic Timer Interrupt: CFS uses a periodic timer interrupt (e.g., every 1 ms) to make scheduling decisions. This allows CFS to track
vruntimeand approximate fair CPU sharing over time.

Using Red-Black Trees
One major focus of CFS is efficiency. When the scheduler needs to find the next job to run, it should do so quickly. Simple data structures like lists don’t scale well because modern systems can have thousands of processes, making frequent searches through a long list wasteful.

CFS only keeps running or runnable processes in this structure. If a process goes to sleep (e.g., waiting for I/O or a network packet), it is removed from the tree and tracked elsewhere.
Let’s look at an example. Assume there are ten jobs with vruntime values: 1, 5, 9, 10, 14, 18, 17, 21, 22, and 24. In an ordered list, finding the next job to run is simple: remove the first element. But placing it back in order requires scanning the list, an \(O(n)\) operation, making searches inefficient. Using a red-black tree, operations like insertion and deletion are \( O(log(n)) \) . When n is in the thousands, logarithmic time is much more efficient than linear.
Summary for Your Article
The Complete Fair Scheduler (CFS) is designed to allocate CPU time fairly among processes. It uses a virtual runtime (vruntime) system to track and manage CPU time allocation, ensuring that processes with less CPU time get prioritized. CFS adjusts scheduling decisions dynamically based on parameters like sched latency and min granularity to balance fairness and performance. The scheduler also uses a red-black tree for efficient process management, ensuring quick access and updates.
Multiprocessor Scheduling
The next section covers the basics of multiprocessor scheduling. Multiprocessor systems are now common in desktops, laptops, and mobile devices. The rise of multicore processors, which have multiple CPU cores on one chip, has driven this trend. These chips are popular because making a single CPU faster without using too much power is difficult. Now, we all have access to multiple CPUs, which is great!
Many challenges come with having more than one CPU. A typical application (like a C program) only uses one CPU, so adding more CPUs won't make it run faster. To fix this, you need to rewrite your application to run in parallel, maybe using threads. Multi-threaded applications can share work across multiple CPUs and run faster. Besides applications, the operating system faces the challenge of multiprocessor scheduling. How can we adapt single-processor scheduling principles for multiple CPUs? What new problems do we need to solve?
Multiprocessor Architecture
To understand the new issues surrounding multiprocessor scheduling, we have to understand a new and fundamental difference between single-CPU hardware and multi-CPU hardware. This difference centers around the use of hardware caches and exactly how data is shared across multiple processors.

In a single CPU system, hardware caches help the processor run programs faster. Caches are small, fast memories that store copies of frequently used data from the main memory. Main memory holds all the data, but accessing it is slower. Caches make this process quicker by storing the most accessed data.
For example, consider a program that fetches a value from memory in a system with one CPU. The CPU has a small cache (about 64 KB) and a large main memory.
The first time a program requests data, it fetches it from the main memory, which takes longer (tens or hundreds of nanoseconds). The processor then saves a copy in the CPU cache. If the program requests the same data again, the CPU checks the cache first. If the data is there, it fetches it much faster (a few nanoseconds), speeding up the program.
Now for the tricky part: what happens when you have multiple processors in a single system, with a single shared main memory, as we see in next figure

Caching with multiple CPUs is more complicated. Imagine a program on CPU 1 reads data (with value D) from address A. Since it's not in CPU 1's cache, it fetches it from main memory and gets value D. The program changes the value at address A to D′ and updates its cache. Writing back to main memory is slow, so it happens later. If the OS moves the program to CPU 2, and it reads the value at address A again, CPU 2's cache doesn't have the data. It fetches from main memory and gets the old value D instead of the updated value D′. Oops!
This issue is called cache coherence, and there is many research on how to solve it. We'll skip the details and focus on the main points. For more information, consider taking a computer architecture class.
The hardware provides a basic solution by monitoring memory accesses to ensure a consistent view of shared memory. In a bus-based system, an old technique called bus snooping is used. Each cache watches memory updates on the bus connecting them to the main memory. When a CPU sees an update for data in its cache, it either invalidates its copy or updates it. Write-back caches complicate this, but the basic idea remains the same.
Cache Affinity
One final issue in building a multiprocessor cache scheduler is cache affinity. When a process runs on a CPU, it builds up state in the CPU's caches. Running the process on the same CPU next time is faster because some state is already cached. If the process runs on different CPUs each time, it performs worse due to reloading the state each time. Therefore, a multiprocessor scheduler should consider cache affinity and try to keep a process on the same CPU if possible.
Single-Queue Scheduling
With this background, let's discuss how to build a scheduler for a multiprocessor system. The simplest way is to put all jobs into one queue. We call this single-queue multiprocessor scheduling or SQMS. This method is simple you can pick the best job to run next and adapt it to work on multiple CPUs (for example, picking the best two jobs if there are two CPUs).
However, SQMS has clear drawbacks.
The first problem is a lack of scalability. In a single-queue system, as the number of CPUs increases, the queue becomes a bottleneck. Each CPU must access the same queue for its next job, causing contention and delays because of blocking. This limits the system's ability to scale efficiently.
The second main problem with SQMS is cache affinity For example, let's say we have five jobs (A, B, C, D, E) and four processors. Our scheduling queue would look like this:

Over time, assuming each job runs for a time slice before another job is chosen, here is a possible job schedule across CPUs:

Because each CPU picks the next job from the shared queue, jobs keep moving between CPUs, which disrupts cache affinity.
To address this, most SQMS schedulers use an affinity mechanism to keep processes on the same CPU when possible. This keeps some jobs on the same CPU while others move to balance the load. For example, imagine the same five jobs scheduled like this:

In this setup, jobs A through D stay on the same processors, with only job E moving from CPU to CPU, maintaining affinity for most jobs. Next time, you could move a different job to ensure fairness. However, implementing this scheme can be complex.
Thus, the SQMS approach has its pros and cons. It's easy to implement if you have a single-CPU scheduler using one queue. However, it doesn't scale well due to synchronization overheads and struggles to maintain cache affinity.
Multi-Queue Scheduling
Due to the issues with single-queue schedulers, some systems use multiple queues, one per CPU. This method is called multi-queue multiprocessor scheduling (or MQMS).
In MQMS, we use multiple scheduling queues. Each queue follows a specific scheduling method, like round robin, but any algorithm can be used. When a job enters the system, it is placed in one queue based on a rule (like randomly or choosing the queue with fewer jobs). Then, it is scheduled independently, avoiding the issues of sharing and synchronization found in the single-queue method.
For example, in a system with two CPUs (CPU 0 and CPU 1), and jobs A, B, C, and D entering the system, each CPU has its own scheduling queue. The OS decides which queue to place each job into, like this:

Depending on the queue scheduling policy, each CPU has two jobs to choose from when deciding what to run. For example, with round robin, the system might create a schedule like this:

MQMS is more scalable than SQMS. As the number of CPUs increases, so do the queues, reducing lock and cache contention. It also supports cache affinity naturally.
But, a new problem with the multi-queue approach is load imbalance. If we have the same setup (four jobs, two CPUs) and one job (say C) finishes, we get the following scheduling queues:

If we apply our round-robin policy to each queue, we get this schedule:

As you can see, A gets twice as much CPU time as B and D, which is not ideal. Even worse, if both A and C finish, leaving only jobs B and D, the scheduling queues will look like this:

As a result, CPU 0 will be left idle!

So How can we overcome the insidious problem of load imbalance
The obvious answer to this query is to move jobs around, a technique which we refer to as migration. By migrating a job from one CPU to another, true load balance can be achieved.
Let’s clarify with an example. One CPU is idle while the other CPU has jobs.
In this case, the OS should move either B or D to CPU 0. This single job migration balances the load evenly..
A more tricky case arises in our earlier example, where A was left alone on CPU 0 and B and D were alternating on CPU 1:
In this case, a single migration won't solve the problem. What should you do then? The answer is to keep moving jobs around continuously. First, A is alone on CPU 0, and B and D take turns on CPU 1. After a few time slices, B is moved to CPU 0 to compete with A, while D gets some time alone on CPU 1. This way, the load is balanced:

Until now, we have seen ways to handle multiprocessor scheduling. The single-queue method (SQMS) is easy to build and balances the load well but struggles with scaling and cache affinity. The multiple-queue method (MQMS) scales better and handles cache affinity well but has load imbalance issues and is more complex.
Subscribe to my newsletter
Read articles from Mostafa Youssef directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Mostafa Youssef
Mostafa Youssef
Software Engineer with a Bachelor’s in Computer Science. Competitive programmer with top 10% on leetcode.