Karpenter Setup on Existing EKS cluster
 Aniket Dubey
Aniket DubeyTable of contents
- Brief overview of Karpenter
- Key Differences from Cluster Autoscaler:
- Prerequisites
- 1. Set Environment Variables
- 2. Creating OpenID Connect (OIDC) provider
- 3. Set Up IAM Roles and Policies
- 4. Tag Subnets and Security Groups
- 5. Update aws-auth ConfigMap
- 6. Deploy Karpenter
- 7. Create NodePool
- 8. Testing the Setup - Deploy Sample Application
- Code Repository
- References and Resources
- Conclusion
Brief overview of Karpenter
Karpenter is an open-source node provisioning project that automatically launches just the right compute resources to handle your Kubernetes cluster's applications. This guide will walk you through the process of setting up Karpenter on an existing Amazon EKS cluster.
Karpenter is designed to improve the efficiency and cost of running workloads on Kubernetes by:
Just-in-Time Provisioning: Karpenter can rapidly launch nodes in response to pending pods, often in seconds.
Bin-Packing: It efficiently packs pods onto nodes to maximize resource utilization.
Diverse Instance Types: Karpenter can provision a wide range of instance types, including spot instances, to optimize for cost and performance.
Custom Resource Provisioning: It allows for fine-grained control over node provisioning based on pod requirements.
Automatic Node Termination: Karpenter can remove nodes that are no longer needed, helping to reduce costs.
Note: This tutorial is based on official Karpenter documentation https://karpenter.sh/docs/getting-started/migrating-from-cas/
The difference is I am using terraform to create the iam roles: KarpenterNodeRole and KarpenterControllerRole
Key Differences from Cluster Autoscaler:
Karpenter doesn't rely on node groups, offering more flexibility in instance selection.
It can provision nodes faster and more efficiently, reducing scheduling latency.
Karpenter integrates directly with the AWS APIs, allowing for more efficient cloud resource management.
Read more here https://www.kubecost.com/kubernetes-autoscaling/kubernetes-cluster-autoscaler/
Prerequisites
- AWS CLI and kubectl installed and configured
- Helm installed
- Terraform - for IAM role and policy setup (in this tutorial)
- Existing EKS cluster setup
- Existing VPC and subnets
- Existing security groups
- Nodes in one or more node groups
- OIDC provider service accounts in your cluster
1. Set Environment Variables
Define cluster-specific information and AWS account details that will be used throughout the migration process.
KARPENTER_NAMESPACE=kube-system
CLUSTER_NAME=<your cluster name>
AWS_PARTITION="aws"
AWS_REGION="$(aws configure list | grep region | tr -s " " | cut -d" " -f3)"
OIDC_ENDPOINT="$(aws eks describe-cluster --name "${CLUSTER_NAME}" \
--query "cluster.identity.oidc.issuer" --output text)"
AWS_ACCOUNT_ID=$(aws sts get-caller-identity --query 'Account' \
--output text)
K8S_VERSION=1.28
ARM_AMI_ID="$(aws ssm get-parameter --name /aws/service/eks/optimized-ami/${K8S_VERSION}/amazon-linux-2-arm64/recommended/image_id --query Parameter.Value --output text)"
AMD_AMI_ID="$(aws ssm get-parameter --name /aws/service/eks/optimized-ami/${K8S_VERSION}/amazon-linux-2/recommended/image_id --query Parameter.Value --output text)"
GPU_AMI_ID="$(aws ssm get-parameter --name /aws/service/eks/optimized-ami/${K8S_VERSION}/amazon-linux-2-gpu/recommended/image_id --query Parameter.Value --output text)"
Make sure to replace <your cluster name> with your actual EKS cluster name.
2. Creating OpenID Connect (OIDC) provider
Check if you have an existing IAM OIDC provider for your cluster
Create an IAM OIDC provider for your cluster
3. Set Up IAM Roles and Policies
Set up the necessary permissions for Karpenter to interact with AWS services. This includes a role for Karpenter-provisioned nodes and a role for the Karpenter controller itself.
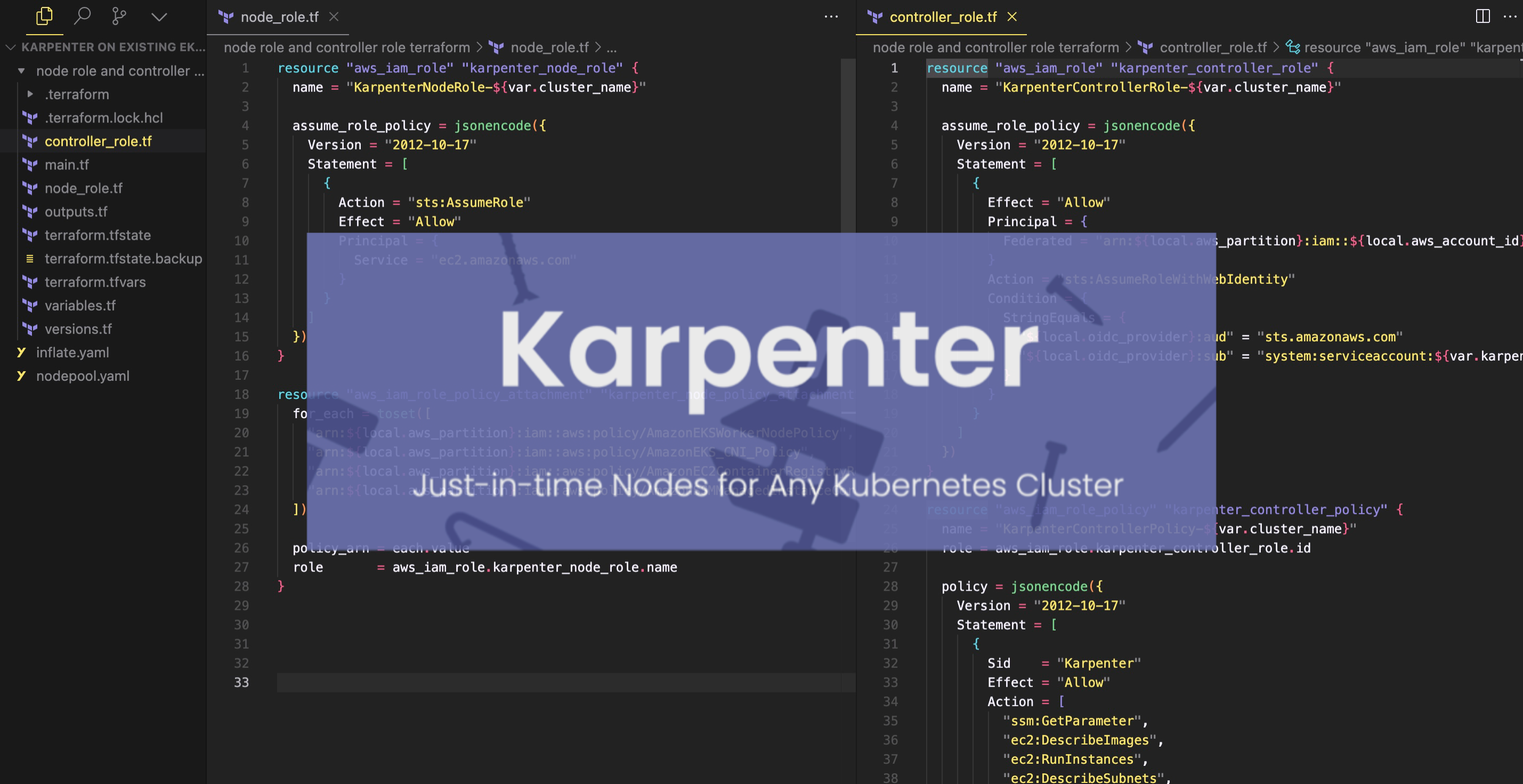
In this step, Terraform is used to create the necessary IAM roles and policies for Karpenter to function properly with your EKS cluster. Specifically, it's creating:
A Karpenter Node IAM Role: This role is assumed by the EC2 instances that Karpenter creates, allowing them to join the EKS cluster and access necessary AWS resources.
A Karpenter Controller IAM Role: An IAM role that the Karpenter controller will use to provision new instances. The controller will be using IAM Roles for Service Accounts (IRSA) which requires an OIDC endpoint.
The Terraform configuration uses the variables defined in the variables.tf file (such as aws_region, cluster_name, karpenter_namespace, and k8s_version) to customize the IAM resources for your specific EKS cluster setup.
By using Terraform for this step, you ensure that all the necessary IAM resources are created consistently and can be easily managed as infrastructure as code.
terraform init
terraform apply
From the terrrafrom script, you will create 2 IAM Roles:

4. Tag Subnets and Security Groups
After applying the Terraform configuration, tag the subnets and security groups to enable Karpenter to discover and use the appropriate subnets and security groups when provisioning new nodes.
Use the following AWS CLI commands to tag the relevant resources:
for NODEGROUP in $(aws eks list-nodegroups --cluster-name "${CLUSTER_NAME}" --query 'nodegroups' --output text); do
aws ec2 create-tags \
--tags "Key=karpenter.sh/discovery,Value=${CLUSTER_NAME}" \
--resources $(aws eks describe-nodegroup --cluster-name "${CLUSTER_NAME}" \
--nodegroup-name "${NODEGROUP}" --query 'nodegroup.subnets' --output text )
done
NODEGROUP=$(aws eks list-nodegroups --cluster-name "${CLUSTER_NAME}" \
--query 'nodegroups[0]' --output text)
LAUNCH_TEMPLATE=$(aws eks describe-nodegroup --cluster-name "${CLUSTER_NAME}" \
--nodegroup-name "${NODEGROUP}" --query 'nodegroup.launchTemplate.{id:id,version:version}' \
--output text | tr -s "\t" ",")
# For EKS setups using only Cluster security group:
SECURITY_GROUPS=$(aws eks describe-cluster \
--name "${CLUSTER_NAME}" --query "cluster.resourcesVpcConfig.clusterSecurityGroupId" --output text)
# For setups using security groups in the Launch template of a managed node group:
SECURITY_GROUPS="$(aws ec2 describe-launch-template-versions \
--launch-template-id "${LAUNCH_TEMPLATE%,*}" --versions "${LAUNCH_TEMPLATE#*,}" \
--query 'LaunchTemplateVersions[0].LaunchTemplateData.[NetworkInterfaces[0].Groups||SecurityGroupIds]' \
--output text)"
aws ec2 create-tags \
--tags "Key=karpenter.sh/discovery,Value=${CLUSTER_NAME}" \
--resources "${SECURITY_GROUPS}"
5. Update aws-auth ConfigMap
Update aws-auth ConfigMap to allow nodes created by Karpenter to join the EKS cluster by granting the necessary permissions to the Karpenter node IAM role.
kubectl edit configmap aws-auth -n kube-system
Add the following section to the mapRoles:
- groups:
- system:bootstrappers
- system:nodes
rolearn: arn:${AWS_PARTITION}:iam::${AWS_ACCOUNT_ID}:role/KarpenterNodeRole-${CLUSTER_NAME}
username: system:node:{{EC2PrivateDNSName}}
Replace ${AWS_PARTITION}, ${AWS_ACCOUNT_ID}, and ${CLUSTER_NAME} with your actual values.
6. Deploy Karpenter
Install the Karpenter controller and its associated resources in the cluster, configuring it to work with your specific EKS setup.
export KARPENTER_VERSION="1.0.1"
helm template karpenter oci://public.ecr.aws/karpenter/karpenter --version "${KARPENTER_VERSION}" --namespace "${KARPENTER_NAMESPACE}" \
--set "settings.clusterName=${CLUSTER_NAME}" \
--set "serviceAccount.annotations.eks\.amazonaws\.com/role-arn=arn:${AWS_PARTITION}:iam::${AWS_ACCOUNT_ID}:role/KarpenterControllerRole-${CLUSTER_NAME}" \
--set controller.resources.requests.cpu=1 \
--set controller.resources.requests.memory=1Gi \
--set controller.resources.limits.cpu=1 \
--set controller.resources.limits.memory=1Gi > karpenter.yaml
6.1 Set Node Affinity for Karpenter
Ensure Karpenter runs on existing node group nodes, maintaining high availability and preventing it from scheduling itself on nodes it manages.
Edit the karpenter.yaml file to set node affinity:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: karpenter.sh/nodepool
operator: DoesNotExist
- key: eks.amazonaws.com/nodegroup
operator: In
values:
- ${NODEGROUP}
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- topologyKey: "kubernetes.io/hostname"
Replace ${NODEGROUP} with your actual node group name.
6.2: Apply Karpenter Configuration
kubectl create namespace "${KARPENTER_NAMESPACE}" || true
kubectl create -f \
"https://raw.githubusercontent.com/aws/karpenter-provider-aws/v${KARPENTER_VERSION}/pkg/apis/crds/karpenter.sh_nodepools.yaml"
kubectl create -f \
"https://raw.githubusercontent.com/aws/karpenter-provider-aws/v${KARPENTER_VERSION}/pkg/apis/crds/karpenter.k8s.aws_ec2nodeclasses.yaml"
kubectl create -f \
"https://raw.githubusercontent.com/aws/karpenter-provider-aws/v${KARPENTER_VERSION}/pkg/apis/crds/karpenter.sh_nodeclaims.yaml"
kubectl apply -f karpenter.yaml
7. Create NodePool
Define the default configuration for nodes that Karpenter will provision, including instance types, capacity type, and other constraints.
Create a nodepool.yaml file with your desired configuration and apply it:
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: default #can change
spec:
template:
spec:
requirements:
- key: kubernetes.io/arch
operator: In
values: ["amd64", "arm64"]
- key: kubernetes.io/os
operator: In
values: ["linux"]
- key: karpenter.sh/capacity-type
operator: In
values: ["spot"] #on-demand #prioritizes spot
- key: karpenter.k8s.aws/instance-category
operator: In
values: ["c", "m", "r"]
- key: karpenter.k8s.aws/instance-generation
operator: Gt
values: ["2"]
nodeClassRef:
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
name: default
limits:
cpu: 1000
# disruption:
# consolidationPolicy: WhenUnderutilized
# expireAfter: 720h # 30 * 24h = 720h
disruption:
consolidationPolicy: WhenEmpty
consolidateAfter: 30s
---
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
metadata:
name: default
spec:
amiFamily: AL2 # Amazon Linux 2
role: "KarpenterNodeRole-karpenter-cluster" # replace with your cluster name
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: karpenter-cluster # replace with your cluster name
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: karpenter-cluster # replace with your cluster name
amiSelectorTerms:
- id: ami-0d1d7c8c32a476XXX
- id: ami-0f91781eb6d40dXXX
- id: ami-058b426ded9842XXX # <- GPU Optimized AMD AMI
# - name: "amazon-eks-node-${K8S_VERSION}-*" # <- automatically upgrade when a new AL2 EKS Optimized AMI is released. This is unsafe for production workloads. Validate AMIs in lower environments before deploying them to production.
kubectl apply -f nodepool.yaml
8. Testing the Setup - Deploy Sample Application
To test Karpenter's autoscaling capabilities, we'll deploy a sample application called "inflate". This application creates pods that consume resources, triggering Karpenter to provision new nodes as needed.
Create a file named inflate.yaml with the following content:
apiVersion: apps/v1
kind: Deployment
metadata:
name: inflate
spec:
replicas: 4
selector:
matchLabels:
app: inflate
template:
metadata:
labels:
app: inflate
spec:
terminationGracePeriodSeconds: 0
securityContext:
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
containers:
- name: inflate
image: public.ecr.aws/eks-distro/kubernetes/pause:3.7
resources:
requests:
# cpu: 100m
cpu: 1
securityContext:
allowPrivilegeEscalation: false
This deployment creates 4 replicas of a pod that requests 1 CPU core each. The pause container is a minimal container that does nothing but sleep, making it perfect for testing resource allocation without actually consuming resources.
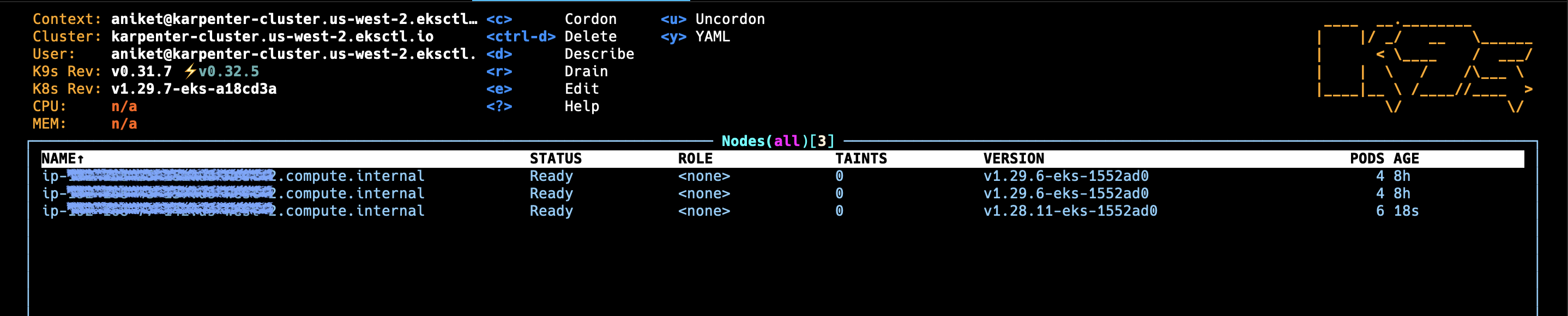
▪︎ Initially we had 2 Nodes:
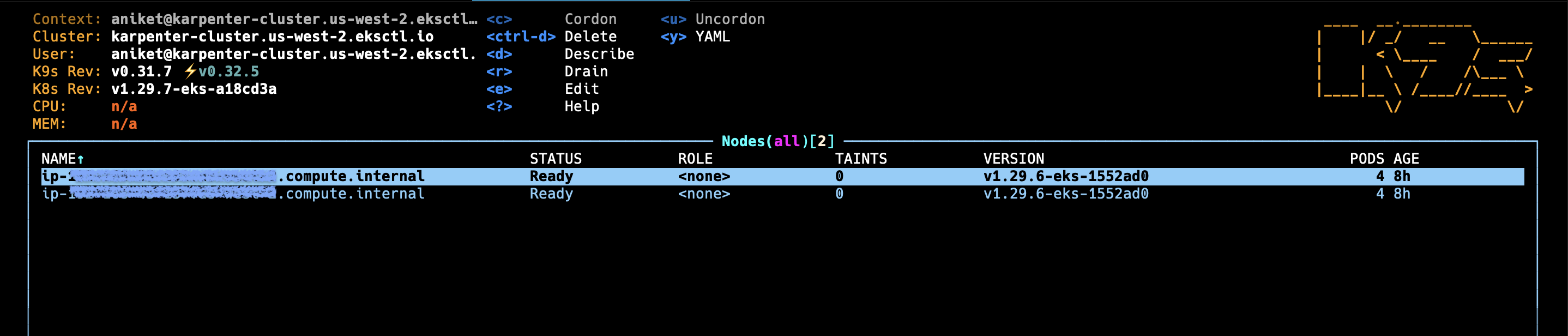
kubectl apply -f inflate.yaml
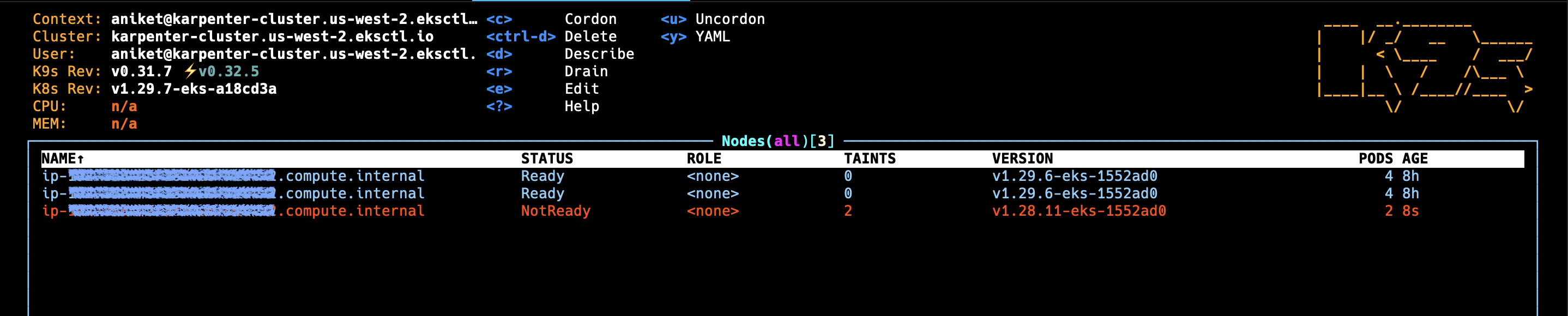
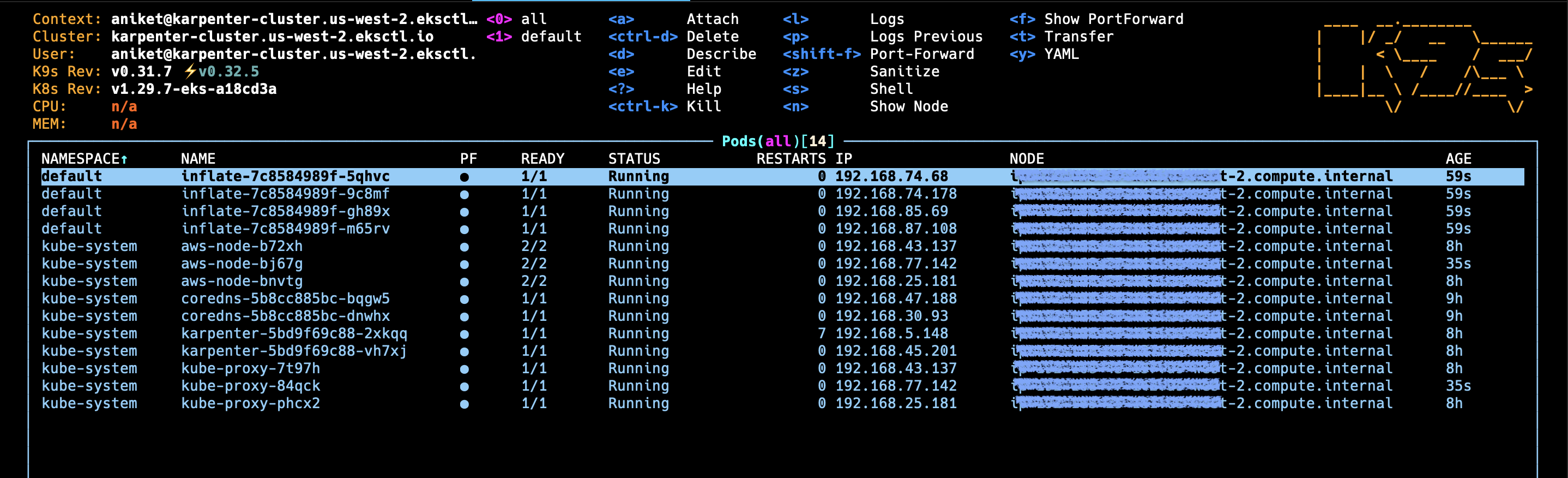
▪︎ After deploying inflate application:
If Karpenter is working correctly, you should see new nodes being added to your cluster to accommodate the inflate pods. This demonstrates Karpenter's ability to automatically scale your cluster based on resource demands.
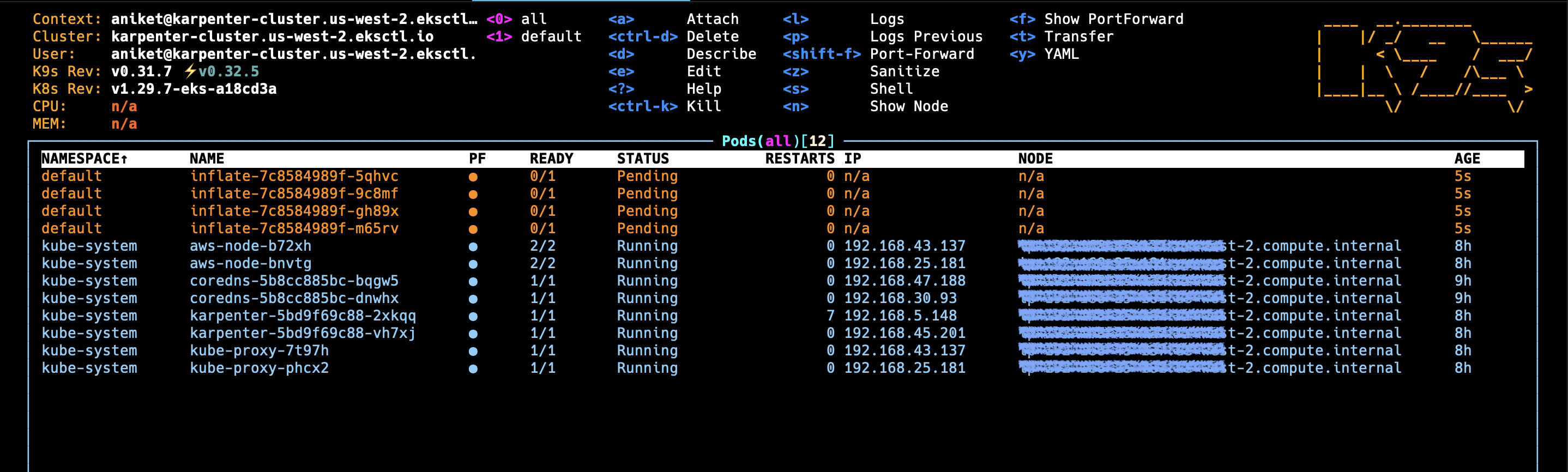
▪︎ Delete the Deployment
kubectl delete -f inflate.yaml
And you will see the node which was created will be deleted.
Code Repository
https://github.com/aniketwdubey/Karpenter-on-Existing-EKS-Cluster
References and Resources
▪︎ https://karpenter.sh/docs/getting-started/migrating-from-cas/
▪︎ https://repost.aws/knowledge-center/eks-troubleshoot-oidc-and-irsa
▪︎ https://github.com/aws-ia/terraform-aws-eks-blueprints/tree/main/patterns/karpenter-mng
▪︎ https://aws-ia.github.io/terraform-aws-eks-blueprints/patterns/karpenter-mng/
Conclusion
You have now successfully set up Karpenter on your existing EKS cluster. Karpenter will automatically manage and scale your node groups based on the workload demands of your cluster.
Remember to monitor your cluster and adjust the Karpenter configuration as needed to optimize performance and cost. You may need to fine-tune the NodePool configuration based on your specific workload requirements.
Subscribe to my newsletter
Read articles from Aniket Dubey directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Aniket Dubey
Aniket Dubey
My passion lies in creating scalable serverless solutions that scale seamlessly in the cloud, particularly in AWS. I thrive on crafting efficient Infrastructure as Code (IaC) using Terraform. Let's build, scale, and innovate in the cloud era! ☁️🚀