4. Embeddings Explained - Next in RAG Series
 Muhammad Fahad Bashir
Muhammad Fahad Bashir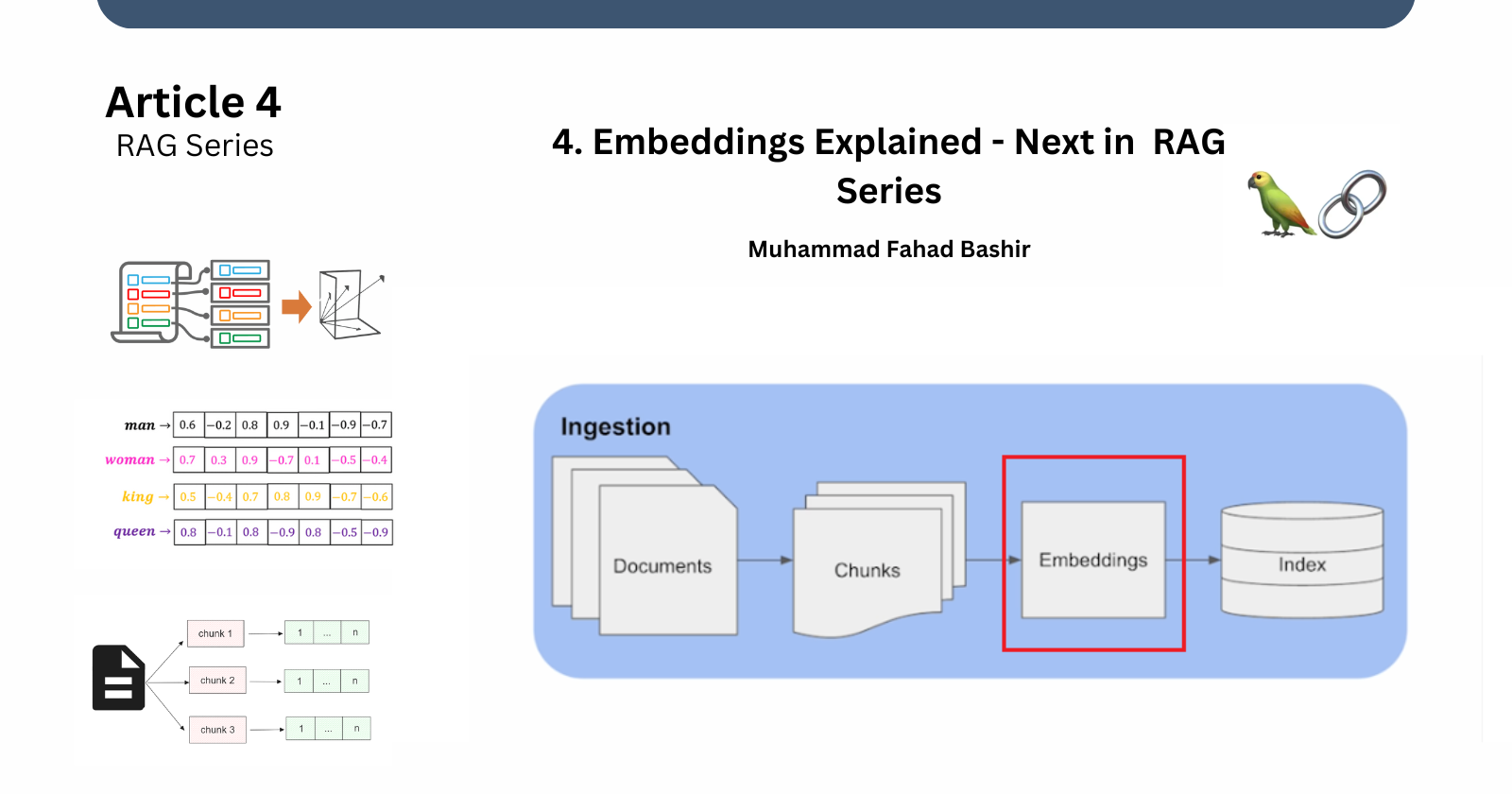
In our previous article, we explored and discussed the concept of splitting documents into chunks. Now, we'll talk next crucial step: embeddings. For this purpose, we use embedding models.
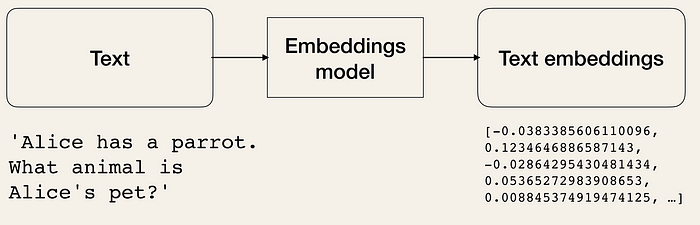
They take input and convert it into a numerical representation so we can perform mathematical operations which will be helpful in retrieving our response. Semantic search also becomes possible. In semantic search, the words whose meanings are closer their numerical representation is also closer.
These embeddings are then later stored in a vector store.
What are Embeddings?
Embeddings are vector representations of text data, converting words or phrases into numerical codes. This process enables computers to understand and process human language, facilitating semantic search and other NLP tasks.
Applications of Embeddings
Similarity Search: Measure similarity between instances, which is particularly useful in NLP tasks.
Clustering and Classification: Utilize embeddings as input features for clustering and classification tasks.
Information Retrieval: Leverage embeddings to build search engines and retrieve relevant documents.
Recommendation Systems: Recommend products, articles, or media to users based on their preferences.
Embedding Class
The Embeddings class is used to generate embeddings.This class is designed to provide a standard interface for all of them. Some providers are open source and some require subscription to use. Several providers offer embedding models, including:
OpenAI
A121 Labs
Azure
GigaChat
Google Generative AI
To know more about Embedding Models visit the official docs
These models can accept either documents (multiple text) or queries (single text).
Examples of Embedding only
We can choose any of the providers like Openai, cohere, and others but here we will be giving examples of huggingface. Huggingface is open source so we can use it without api-key and subscription.
First, we have to install the package then we can load the model of any choice.
!pip install langchain-huggingface
from langchain_huggingface import HuggingFaceEmbeddings
embeddings_model = HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2")
By Query
We can use .embed_query to embed a single piece of text
embeedings=embeddings_model.embed_query("We are writing this query ")
print(embeedings)

By Document
We can use .embed_documents to embed a list of strings, recovering a list of embeddings:
embeddings = embeddings_model.embed_documents(
[
"Hi there!",
"Oh, hello!",
"What's your name?",
"My friends call me World",
"Hello World!"
]
)
print(embeddings)

Revising the previous steps
we will be covering the following steps of the ingestion pipeline.
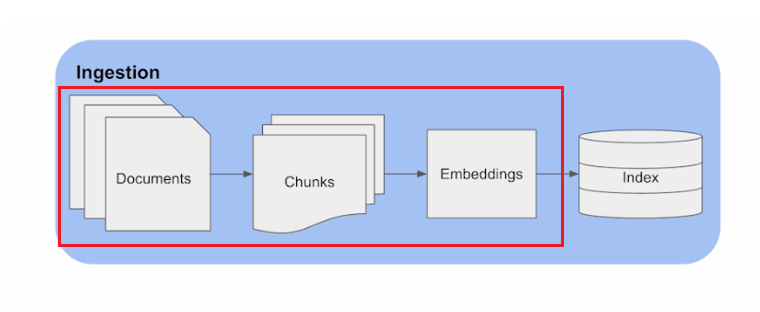
- import necessary packages
!pip install langchain langchain_community !pip install transformers langchain_huggingface !pip install pypdf # as using pdf file for example- load the documents
from langchain.document_loaders import PyPDFLoader loaders=PyPDFLoader('/content/FYP Report PhysioFlex(25july).pdf') doc=loaders.load() docs
- split them into chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter textsplitter=RecursiveCharacterTextSplitter( chunk_size=300, chunk_overlap=50 ) split=textsplitter.split_documents(doc) print("Total Number of chunks : " , len(split)) print("printing first chunk :'\n ", split[0])We used RecursiveCharacterTextSplitter and from that single document it is now splitter into 290 chunks

- make their embeddings
from langchain_huggingface import HuggingFaceEmbeddings
embed_model = HuggingFaceEmbeddings(model_name='BAAI/bge-small-en-v1.5')
embedded=embed_model.embed_documents([doc.page_content for doc in split])
print(embedded[1]) # only viewing the emebding of chunk 1

you can play around with this notebook.
Conclusion
In this article, we explored the concept of embeddings, their applications, and the various embedding models available. By understanding embeddings, we can unlock the power of semantic search and build innovative NLP applications. Stay tuned for our next article in the RAG series, where we'll dive deeper into the world of embeddings and their applications.
Subscribe to my newsletter
Read articles from Muhammad Fahad Bashir directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by