What is so special in git ??
 Abhinav
Abhinav
Introduction
Tired of hearing about Git but have no clue what it is?
Frustrated by tutorials throwing weird commands at you without explanation?
{kind=link}
Don't worry, I've got you covered!
In this blog, we'll unravel the Git mystery together, no jargon required!
Let's dive in and demystify Git, one commit at a time!
P.S. We'll start by cracking the code of VCS (Version Control System). Intrigued?
Let's go!
What is Version Control System (VCS) ?
Version Control is a system that records changes to a file or set of files over time so that you can recall specific versions later. It is known as a Version Control System because it allows you to manage and control different versions of your files, ensuring that you can track and revert to previous states as needed. In the software world, you will use version control to manage software source code, but you can actually use it for almost any type of file on a computer (for example: managing bank records, office documents, and much more).

If you are in any profession where you want to keep track of every version or state of your files, a VCS is a very wise thing to use. It allows you to revert selected files back to a previous state, revert the entire project or file to a previous state, compare changes over time, see who last modified something that might be causing a problem, who introduced an issue and when, and more. If you screw things up or lose files, you can easily recover. That's why VCS's become a necessary tool for developers, making their work more effective, reducing workload, and preserving their work from any mishaps that might occur, as software development involves experimenting with new things.
Version Control Systems
Local Version Control Systems (LVCS)
The journey of VCS starts with local VCS (for example: RCS). It stores patches of changes made to a file, and when someone needs to check the file, they apply the patches from that specific stage to get that version of the file.
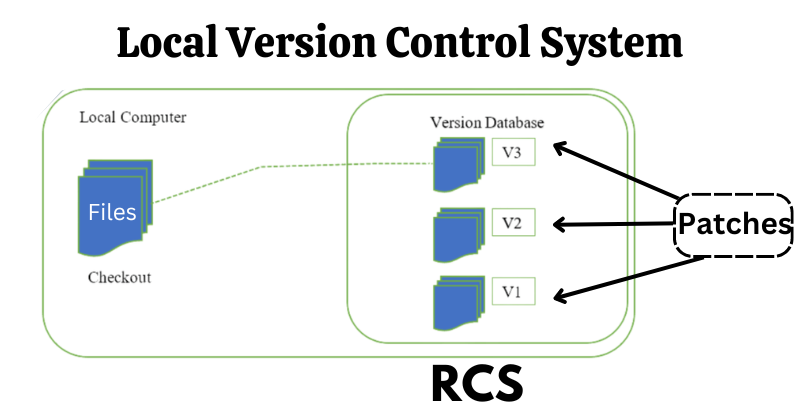
As it sounds, this is not an effective way of version control. In this system, every file is stored locally, and if any patch gets deleted or corrupted, the entire development will suffer. Additionally, there is no option to share files with teams; we need to share each file and its patches separately with every team member. That's why the development of version control systems moved to a new approach, which is much more effective than this.
Centralized Version Control Systems (CVCS)
Centralized Version Control Systems are one of the most used Version Control Systems, widely adopted by developers in their workflows. They come with various new features that are very useful for professionals, allowing them to collaborate with developers on other systems without sending everything individually. In this type of VCS, developers who collaborate know to a certain degree what everyone is doing on the project. Also, administrators of projects have fine-grained control over who can do what. Some popular examples of CVCS are: CVS, Subversion, and Perforce.
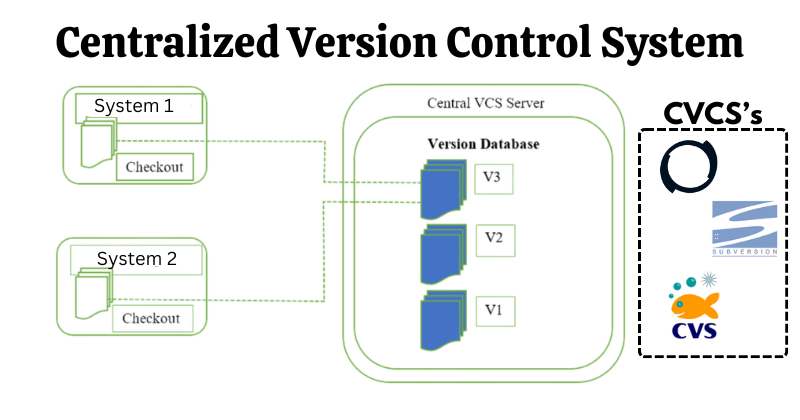
Despite having many useful features, CVCS has some disadvantages that can cause workflow problems. The main issue is the single point of failure. If the central file is inaccessible or corrupted, everyone connected to it is affected. While CVCS is better than LVCS, it still has limitations that make it unreliable for everyone. This led to the development of another type of VCS, which is much more effective.
Distributed Version Control Systems (DVCS)
The Latest type of Version Control System is DVCS which are using by developers nowadays, clients and developers don't just check out the latest snapshots of files; they fully mirror the repository, including its entire history. Thus, if something goes wrong with the server, no one is affected.
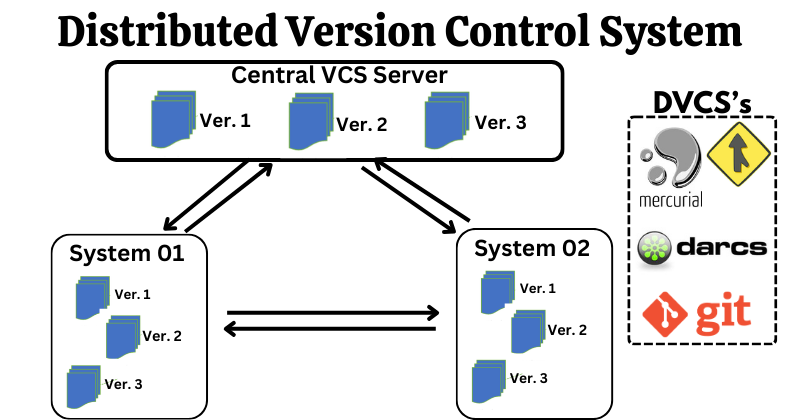
The most popular DVCS is Git, but there are many other DVCSs also available, such as Mercurial, Darcs, and Bazaar.
[Whenever someone reads files with added changes, it is known as a checkout.]
[The snapshot here refers to the copy of full file structure with its history records.]
[The repository is the same as a folder we generally use in our systems. That's why in Version Control Systems, a folder is known as a repository.]
History of Git
Now, I am sure that after understanding these terms, one question arises: if many DVCS software options are already available, why was Git developed, and what makes it unique? To understand this, we need to dive into the history of Git and discover why it came into existence. Git takes it's birth in 2005, but before Git there's a DVCS which provide similar service, are widely used by developers which is known as BitKeeper. BitKeeper was used in the Linux Kernel Project, which was a very big project at that time. However, in 2005, the long-standing relationship between Linux and BitKeeper ended when BitKeeper's free-of-charge status was revoked due to profit motives. This incident prompted Linus Torvalds (the creator and lead Developer of Linux & Git) to develop their own DVCS system with following goals:
Speed
Simple Design
Strong Support for non-linear development (Branching)
Fully distributed
Able to handle large projects like Linux Kernel efficiently.
That's how git comes into existence but it's high-end features (like fast, strong community support, distributive nature) without any cost and supportive architecture for large projects which makes the workflows of software development much smoother makes it most popular and widely used Version Control System. Today, all companies use Git in their workflows, from development to deployment. Git is used everywhere.
So far, we have learned about various terms related to Git and why it was created. But we keep saying "Git, Git, Git" without really knowing what it is. We know that Git is a type of DVCS, but why did it become more popular than other DVCS? Are the features that Linus Torvalds added to Git the reason for its popularity, or is there something else that makes it special? Let's find out the answer to this mystery. It's a bit confusing, so let's figure it out together.
What is Git ??
Git is a distributed version control system, but it is not the same as other distributed version control systems. While other DVCSs store the changes made to a file and then provide those changes with the file in the workflow, Git works differently. Git stores its data in a series of snapshots. With every commit, Git saves snapshots of the whole file system along with their changes. If files have not changed, Git does not store the file again; it just links to the previous identical file it already stored.
Other DVCS's Workflow:

Git Workflow:
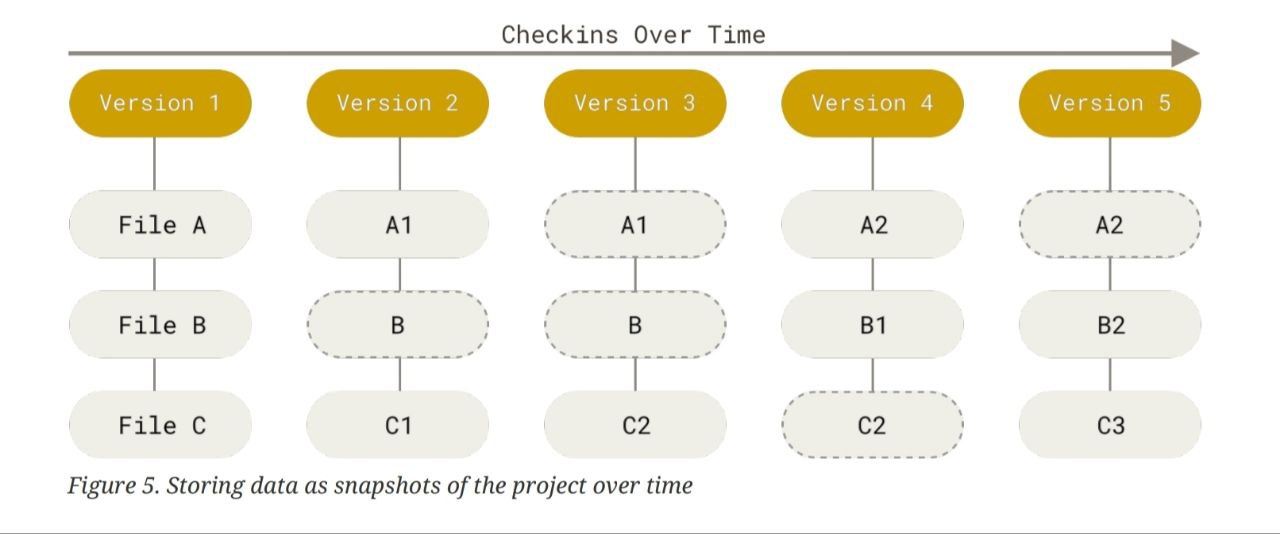
The pictorial representation above shows the workflow of Git compared to other DVCSs. In other DVCSs, changes are stored as they are made. However, in Git, the complete file is stored with every change, which helps in reverting and storing history systematically. If nothing changes, it simply links to the previous version. This approach avoids issues that can arise in the long run with other DVCSs, which only store changes after each commit and can mess up the change record if other developers are also collaborating.
Git (God of Speed)

Sounds weird, right?
Let me explain, and you'll agree with the heading. Most operations in Git only require local files and resources to work (the git clone command, which you'll see often, makes this possible smoothly). Generally, no information is needed from another computer on your network.
For example, to browse the history of the project, Git doesn't need to go out to the server to get history and display it for you -- it simply reads it directly from your local databse. This means you see the project history almost instantly. If you want to see the changes introduced between the current version of a file and the file a month ago, Git can look up the file a month ago and do a local difference calculation, instead of having to either ask a remote server to do it or pull an older version of the file from the remote server to do it locally.
This also means there is very little you can't do if you're offline or off VPN. If you get on an airplane or a train and want to do some work, you can commit to your local copy until you get a network connection to upload. If you go home and can't get your VPN client working properly, you can still work. In many other systems, this is either impossible or very difficult. For example, in Perforce, you can't do much when you're not connected to the server. In Subversion and CVS, you can edit files, but you can't commit changes to your database because it's offline. This may not seem like a big deal, but you might be surprised at how much of a difference it can make.
Multiverse Of Data
No, it is not the multiverse of Dr. Strange where you get lost. Instead, it is a multiverse of data, and the Dr. Strange of this multiverse is Git. Git possesses incredible capabilities when it comes to handling data, and it rarely, if ever, lets you down.
In Git, when you perform actions like editing or adding files, nearly all of these actions only add data to the Git database. This design makes it extremely difficult to do anything that cannot be undone or to accidentally erase data. Unlike some older Version Control Systems (VCS), where you might lose or mess up changes you haven't committed yet, Git ensures that once you commit a snapshot, it is very difficult to lose that data. This is especially true if you regularly push your database to another repository, providing an additional layer of security and redundancy.
Moreover, Git's distributed nature means that every user has a complete copy of the repository, including its full history. This decentralization not only enhances collaboration but also ensures that the project can be recovered from any user's local repository if needed. This level of redundancy and flexibility is unparalleled in other VCS systems.
This makes using Git a joy because we can experiment without the risk of seriously messing things up. It makes the life of a software developer much easier and more productive.
Conclusion
So far, we have covered the basics of Git, starting with the evolution of Version Control Systems (VCS) from Local to Centralized and finally to Distributed VCS. We learned about Git's history, why Linus Torvalds created it, and what makes it unique, such as its snapshot-based storage, speed, and offline capabilities. We also discussed how Git's strong data management supports safe experimentation without data loss.
In our journey, we have seen how Git's architecture supports a more efficient and reliable workflow for developers. The ability to work offline, commit changes locally, and then push them to a remote repository ensures that your work is never lost. This is particularly beneficial in scenarios where internet connectivity is intermittent or unavailable. Git's snapshot-based storage means that every change is recorded as a snapshot of the entire project, making it easy to revert to previous states without losing any data.
Stay tuned for the next chapter of this series, where we will uncover the security measures in Git, including how it ensures the integrity and authenticity of your data. We will also delve into more advanced topics such as rebasing, cherry-picking, and resolving merge conflicts, which will further enhance your understanding and usage of this powerful tool. By the end of this series, you will have a comprehensive knowledge of Git, empowering you to manage your projects with confidence and efficiency.
Thank You :)
If you found this blog post helpful, please consider sharing it with others who might benefit from this. You can also follow me for more content on Git, React, and other Development related topics.
For Paid collaboration mail me at : abhinavmittal554@gmail.com
Connect with me on Twitter, LinkedIn and GitHub.
Thank you for Reading :)

Subscribe to my newsletter
Read articles from Abhinav directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Abhinav
Abhinav
👨💻Hi there! I am Abhinav | Web Developer in the Making | Tech Blogger @ Hashnode | AI/ML Enthusiast