Building a Python-Based Fraud Detection System Using Machine Learning
 ByteScrum Technologies
ByteScrum Technologies
Fraud detection is a critical area in financial systems, as it helps identify suspicious activities that could lead to financial losses. With the rise of online transactions and digital payments, the need for automated fraud detection systems has become increasingly important. Machine learning (ML) can be highly effective in identifying patterns in large datasets, making it ideal for detecting fraudulent activities.
In this blog, we will walk through how to build a Python-based fraud detection system using machine learning techniques. We will use supervised learning methods to classify transactions as either fraudulent or legitimate.
Overview of the Fraud Detection System
A typical fraud detection system consists of several key steps:
Data Collection: Collect transactional data, including features such as transaction amount, time, location, and other user-related details.
Data Preprocessing: Clean and prepare the data for analysis, including handling missing values, normalization, and splitting the dataset into training and testing sets.
Feature Engineering: Create meaningful features from the raw data to improve model performance.
Model Selection: Choose and train a suitable machine learning model such as logistic regression, decision trees, random forests, or neural networks.
Model Evaluation: Test the model on unseen data and evaluate its performance using metrics such as accuracy, precision, recall, and F1 score.
Deployment: Deploy the trained model into a production environment where it can be used to predict fraud in real-time transactions.
Step 1: Data Collection
To start, we need transactional data. Many fraud detection datasets are available online, such as the Credit Card Fraud Detection Dataset from Kaggle. This dataset contains transactions made by credit cards in September 2013 and includes both fraudulent and legitimate transactions.
Download the dataset and load it into your Python environment using pandas:
import pandas as pd
# Load the dataset
data = pd.read_csv('creditcard.csv')
# Display the first few rows of the dataset
print(data.head())
The dataset includes various features such as Time, Amount, and several anonymized features (V1 to V28). The Class column indicates whether a transaction is fraudulent (1) or legitimate (0).
What is V series in fraud detection
In the context of fraud detection using credit card transactions, the V series refers to a set of anonymized features from the Credit Card Fraud Detection dataset that is widely used for research purposes. This dataset was originally made available by researchers from a European cardholder dataset, and it contains data related to transactions made by credit cards.
Key Points About the V Series:
Anonymization: The dataset contains 28 features labeled as
V1,V2, ...,V28. These features are principal components obtained through Principal Component Analysis (PCA). The PCA was performed to anonymize the sensitive information related to the original features (such as account numbers or transaction metadata).PCA Transformation: The PCA transformation means that the features don't directly correspond to any meaningful, interpretable variable. Instead, they are combinations of the original features that retain as much variance (information) as possible while reducing dimensionality and improving model training.
Usage in Models: The
V1throughV28features are commonly used by machine learning models to detect patterns of fraudulent and non-fraudulent transactions. Since they are derived from the original transaction data, they can help capture important variance in the data.
Example of Features:
Here’s an example of what the dataset might look like, with each row corresponding to a transaction:
| Time | V1 | V2 | V3 | ... | V28 | Amount | Class |
| 0 | -1.3598071 | -0.0727812 | 2.5363467 | ... | 0.0210531 | 149.62 | 0 |
| 1 | 1.1918571 | 0.2661516 | 0.1664801 | ... | 0.1415077 | 2.69 | 0 |
| 2 | -1.358354 | -1.3401631 | 1.7732093 | ... | 0.1083003 | 378.66 | 0 |
| 3 | -0.9662717 | 0.1826848 | 0.1546765 | ... | 0.0066604 | 123.50 | 0 |
Time: The time of the transaction relative to the first transaction in the dataset.
V1 to V28: The anonymized PCA components.
Amount: The amount of the transaction.
Class: The label indicating whether the transaction is fraudulent (
1) or non-fraudulent (0).
Why Use PCA?
PCA reduces the dimensionality of the dataset, which helps with:
Data Privacy: Sensitive information about the transactions or cardholders is anonymized.
Noise Reduction: PCA can help remove noise in the data by focusing on the most important features (components).
Efficiency: Reducing the number of dimensions can help machine learning models train faster and with less overfitting.
In summary, the V series represents transformed, anonymized features derived from the original data via PCA. These features are crucial for training models to detect credit card fraud without revealing sensitive transaction details.
Step 2: Data Preprocessing
Before building the model, the data must be preprocessed. This involves cleaning, normalizing, and splitting the dataset into training and testing sets.
Handle Class Imbalance
Fraud detection datasets often have imbalanced classes (many more legitimate transactions than fraudulent ones). One common technique to handle this is undersampling or oversampling.
We can use SMOTE (Synthetic Minority Oversampling Technique) to oversample the minority class (fraud cases) for training:
from imblearn.over_sampling import SMOTE
from sklearn.model_selection import train_test_split
# Split the dataset into features and target variable
X = data.drop('Class', axis=1)
y = data['Class']
# Split into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Apply SMOTE to oversample the minority class in the training set
smote = SMOTE(random_state=42)
X_train_resampled, y_train_resampled = smote.fit_resample(X_train, y_train)
Normalize the Data
Feature normalization ensures that all input features are on the same scale, which helps certain algorithms perform better. We can use StandardScaler to normalize the data:
from sklearn.preprocessing import StandardScaler
# Normalize the data
scaler = StandardScaler()
X_train_resampled = scaler.fit_transform(X_train_resampled)
X_test = scaler.transform(X_test)
Step 3: Model Selection
We can now choose a machine learning model to classify transactions as fraudulent or legitimate. In this example, we'll use a Random Forest Classifier due to its robustness and ability to handle imbalanced data.
from sklearn.ensemble import RandomForestClassifier
# Initialize the Random Forest model
model = RandomForestClassifier(n_estimators=100, random_state=42)
# Train the model
model.fit(X_train_resampled, y_train_resampled)
Step 4: Model Evaluation
After training the model, we can evaluate its performance on the test set using various metrics such as accuracy, precision, recall, and F1 score. Since fraud detection is a highly imbalanced classification problem, accuracy alone isn't a good indicator of model performance. Precision, recall, and the F1 score provide better insights into how well the model is identifying fraud cases.
from sklearn.metrics import classification_report, confusion_matrix
# Predict on the test set
y_pred = model.predict(X_test)
# Generate a classification report
print(classification_report(y_test, y_pred))
# Display a confusion matrix
conf_matrix = confusion_matrix(y_test, y_pred)
print(conf_matrix)
Step 5: Fine-Tuning the Model
If the model performance is not satisfactory, you can tune the hyperparameters of the model to improve accuracy. Using techniques such as Grid Search or Random Search can help find optimal parameters for the Random Forest model or other algorithms such as XGBoost or Logistic Regression.
Here’s an example of hyperparameter tuning using Grid Search:
from sklearn.model_selection import GridSearchCV
# Define the parameter grid
param_grid = {
'n_estimators': [100, 200, 300],
'max_depth': [None, 10, 20, 30],
'min_samples_split': [2, 5, 10],
}
# Perform Grid Search
grid_search = GridSearchCV(estimator=model, param_grid=param_grid, cv=3, n_jobs=-1, verbose=2)
grid_search.fit(X_train_resampled, y_train_resampled)
# Best parameters
print(grid_search.best_params_)
Step 6: Deployment
Once satisfied with the model's performance, the next step is to deploy it into a production environment. The model can be integrated with a real-time transactional system to monitor transactions and flag suspicious activities as they occur. You can use Flask or FastAPI to create a simple API for real-time fraud detection.
Here’s an example of how to create an API using Flask:
from flask import Flask, request, jsonify
import numpy as np
app = Flask(__name__)
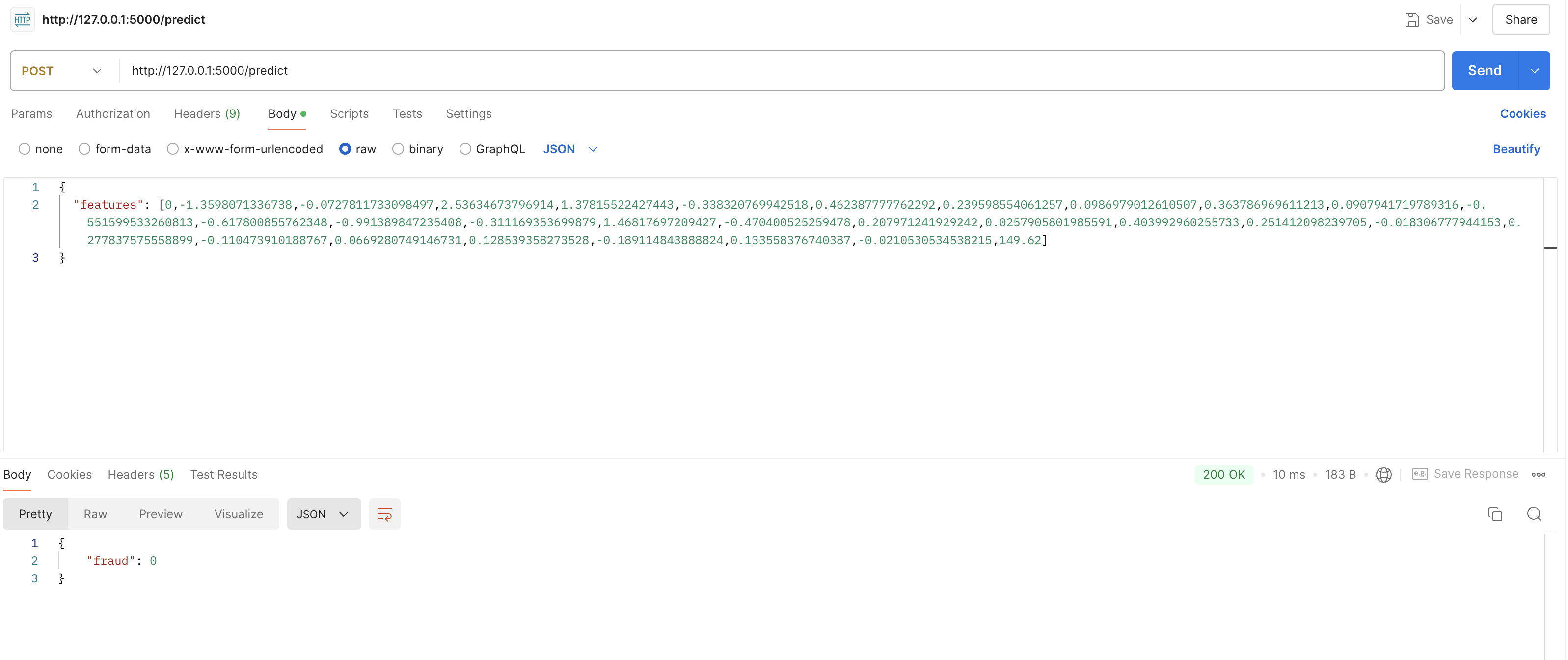
@app.route('/predict', methods=['POST'])
def predict():
data = request.get_json(force=True)
features = np.array(data['features']).reshape(1, -1)
prediction = model.predict(features)
return jsonify({'fraud': int(prediction[0])})
if __name__ == '__main__':
app.run(debug=True)
Save the model and the scaler to avoid training again.
Conclusion
Fraud detection is a dynamic problem that requires constant improvement as fraudsters adapt. Keep retraining the model on new data to ensure it remains accurate and effective.
By following the steps in this guide, you can develop a robust fraud detection system capable of operating in a real-time production environment.
Subscribe to my newsletter
Read articles from ByteScrum Technologies directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
ByteScrum Technologies
ByteScrum Technologies
Our company comprises seasoned professionals, each an expert in their field. Customer satisfaction is our top priority, exceeding clients' needs. We ensure competitive pricing and quality in web and mobile development without compromise.