Efficient Data Management and Verification With Merkle Trees.
 Abolare Roheemah
Abolare Roheemah
What is a Merkle Tree?
A merkle tree, also known as a hash tree, is a kind of data structure used to store data more efficiently and securely. It was named after Ralph Merkle, a computer scientist known for his pioneering work in the field of cryptography.
Merkle trees makes use of hashes (an encrypted form of data), which ensures that data stored in it is very secure and tamper-proof. This means that, even if the tinniest bit of data is altered, the generated hash, to a large extent, changes completely. Most merkle trees are binary, but there are some that can be expanded.
Structural Overview of Merkle Trees
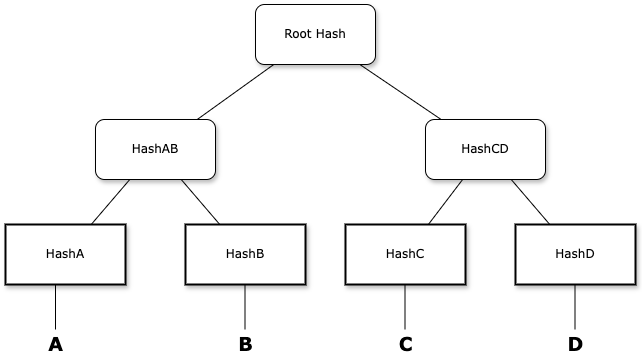
Merkle trees, as the name suggests, can be visualized as a tree structure that has a root and branches on which are leaves. In a merkle tree, however, the structure is upside down, i.e the root is at the top and the leaves are at the bottom. The hash of the pieces of data that we want to store in the merkle tree (e.g., transactions in a blockchain) are referred to as the leaf nodes. These leaf nodes are then combined in twos and the combination is hashed to generate a new set of nodes. These new nodes also paired up and hashed and the process continues till there are only two nodes remaining which then generate the root hash known as the merkle root.
For example, if there are 4 transactions (A, B, C, D) in a block and we want to generate a merkle tree of these transactions. The process would typically follow these steps:
Hash A, B, C and D using a cryptographic hash function. Lets call them HashA, HashB, HashC, and HashD.
Combine HashA and HashB in another hash lets call it HashAB i.e Hash(HashA, HashB) = HashAB. The same thing applies to C and D, therefore generating HashCD
Finally, we have just two nodes left i.e HashAB and HashCD which are then hashed to generate the root hash i.e., Hash(HashAB, HashCD) = Root Hash.
What are Hashes?
Its practically impossible to talk about merkle trees without talking about hashing. Its even obvious from the number of times I've used the word in this article. Hashing is the process of converting an input message/data into a unique fixed-length code by passing it through a special function known as a hash function. A hash function is an algorithm that takes the data to be hashed as input and after performing some computations on it, returns a fixed-size string of bytes known as the hash code or the hash value.
Properties of a Typical Hash Function
Determinism: The same input to a hash function always returns the same hash value.
Fixed Size: The result from a hash function is of fixed length regardless of the size of input provided.
Pre-Image Resistance: After a hash is generated for a particular input, it should be computationally infeasible to obtain the original data from the hash.
Collision Resistance: It should be impossible to find two different inputs that have similar hashes.
Avalanche Effect: This means that for a minute or meagre change in the original data, there should be an enormous change in the generated hash.
Fast Computation: A hash function should process data quickly.
Some common hash functions include;
SHA-1 (Secure Hash Algorithm-1): Produces a 160 bit hash value and has been replaced by more secure hash algorithms.
SHA-256 Returns a 256 bit hash. Popular for its use in Bitcoin, Ethereum and other blockchain technologies due to its strong security.
SHA-3: The most recent version of the secure hash algorithm with different design and security features.
Now that we have talked about hashing and hash functions, lets look at some applications of merkle trees;
Applications of Merkle Trees
In blockchain technology, merkle trees enhance the security, decentralization and scalability of the platform. This would be discussed in more details later on in this article.
In version control systems like GIt, merkle trees can be used to track changes and verify the authenticity of files. This is crucial for version control and collaboration.
Why Are Merkle Trees Used in Computer Science, Especially in Blockchain Technology?
Data Integrity and Security
Once a particular dataset is stored in a merkle tree, the integrity and authenticity of that data is guaranteed. In a blockchain, this ensures that data received from a peer in a peer-to-peer network is original and unaltered and that a peer isnt sending fake or altered information.
Easy Data Verification
Compared to other forms of data structures, verifying that a data is a valid member of a merkle tree is relatively easy. Rather than search the entire dataset, you only need the root hash and a small number of other hashes, which is a lot more efficient.
Storage and Computational Efficiency
Rather than store an entire dataset, using a merkle tree, one need store just the merkle root. Verification of data then requires just the merkle root and a few hashes, ensuring minimal computational effort and memory usage.
Scalabilty
Since the blockchain holds an enormous amount of data, which keeps growing as more users join the network, the need for efficient ways of storing this data cannot be overemphasized. Merkle trees provides an efficient way of storing data on the blockchain, ensuring scalability of the platform (i.e., ability to manage increasing amount of data without significant decline in performance).
Lightweight Clients
On the Ethereum blockchain, for example, there are full nodes, archive nodes and light nodes. The use of merkle trees on the blockchain allows for the existence of light nodes, which are nodes that don’t download the entire blocks in a blockchain. They only download block headers, which contains the merkle root which is then used to verify which transactions are part of the block.
Summary
Merkle trees are very crucial for the security and scalability of the blockchain and as technology advances, upgrades would be introduced to enhance their efficiency and scalability. One such enhancement is combining merkle trees with other efficient data structures, such as Patricia tries, as done on the ethereum platform, ensuring efficient data storage and retrieval, enhanced security and integrity, and improved verification speed.
Subscribe to my newsletter
Read articles from Abolare Roheemah directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by