LLMs with Cosmos DB - Part 1
 Sachin Nandanwar
Sachin Nandanwar
I wrote a couple of articles explaining the fundamental mathematical concepts of vector similarities and how vector embeddings utilizes Euclidean distance, Cosine/Dot Product and Cosine Similarities to identify phrase similarities.
This article will be part 1 of a two-series article demonstrating the use of the RAG pattern to integrate Azure OpenAI services with custom data stored in Cosmos DB. In an earlier article I showcased on how to perform bulk insert/update documents in Cosmos DB. In this article I will delve into the details on how to build a RAG based LLM on that data. In the first part, I will demonstrate ways to create vector embeddings using OpenAI service on Azure and in the second part, we will explore how to leverage OpenAI for vector similarity search and question answering on the data stored in Cosmos DB.
This article will NOT be focused on helping to grasp the understanding of Large Language Models. The emphasis will more on showcasing the method to leverage vector embeddings stored in Cosmos DB for LLM's.
Please note that the code in this article is largely inspired by the samples posted here on GitHub.
Prerequisite :
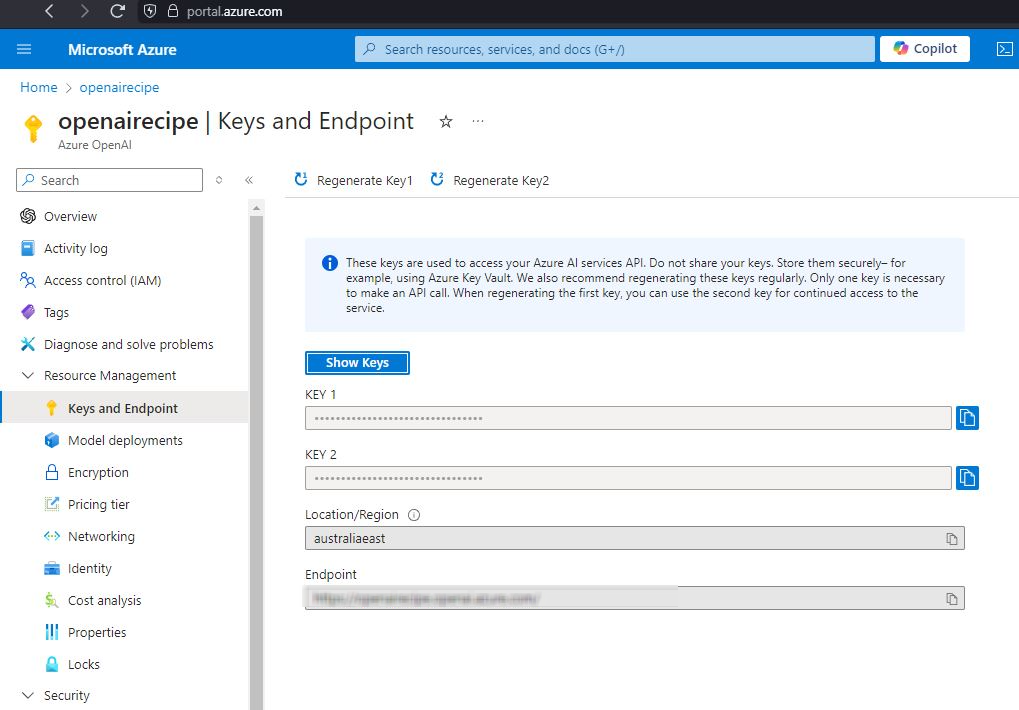
To get started, first create an OpenAI service on Azure. The step by step process to creating one is detailed out here. I created one named openairecipe.
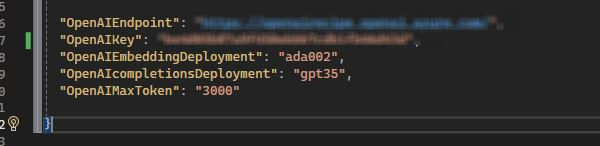
Next create a Console application project and add references for the Open AI service in the appsettings.json file of the project.
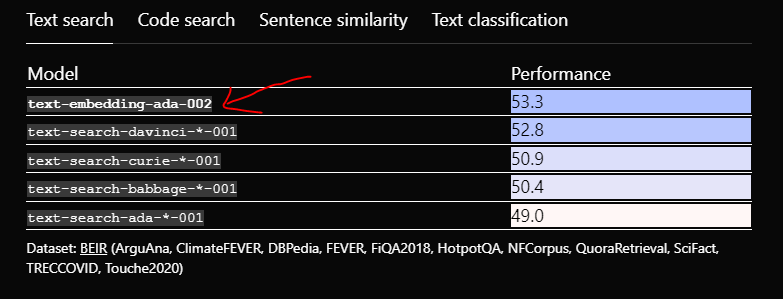
We will be using the ada-002 model as it has shown to outperform the other similar models. You can find the comparative details of different models here .
and for chat completion we will use the GPT-3.5 model . A detailed comparison of various models is available here.
As of July 2024 it's strongly recommended to use GPT-4o mini instead of GPT-3.5 Turbo.
Settings
To start using Cosmos DB for vector embeddings you must first enable the vector search option for the database. To set that up, Goto Azure Cosmos DB for NoSQL resource page:
Navigate to Settings >> Features >> Vector Search in Azure Cosmos DB for NoSQL
Read the description of the feature to confirm you want to enroll in the preview.
Select "Enable" to enroll in the preview. Once done, the Status option will be On.
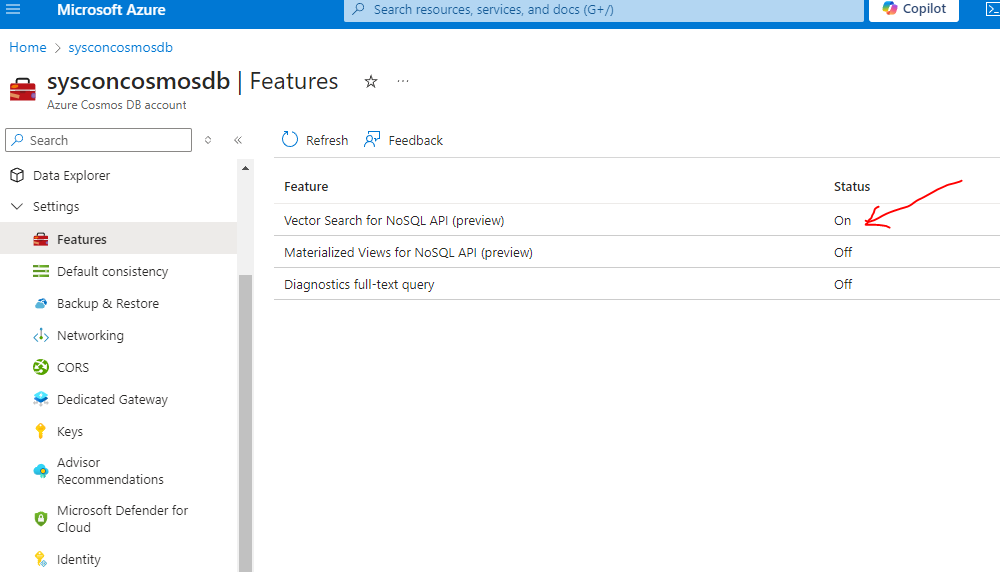
Next, you need to configure the Container Vector Policy.
To do this, select the container for which the policy will be applied and navigate to Containers >> Settings >> Container Vector Policy.
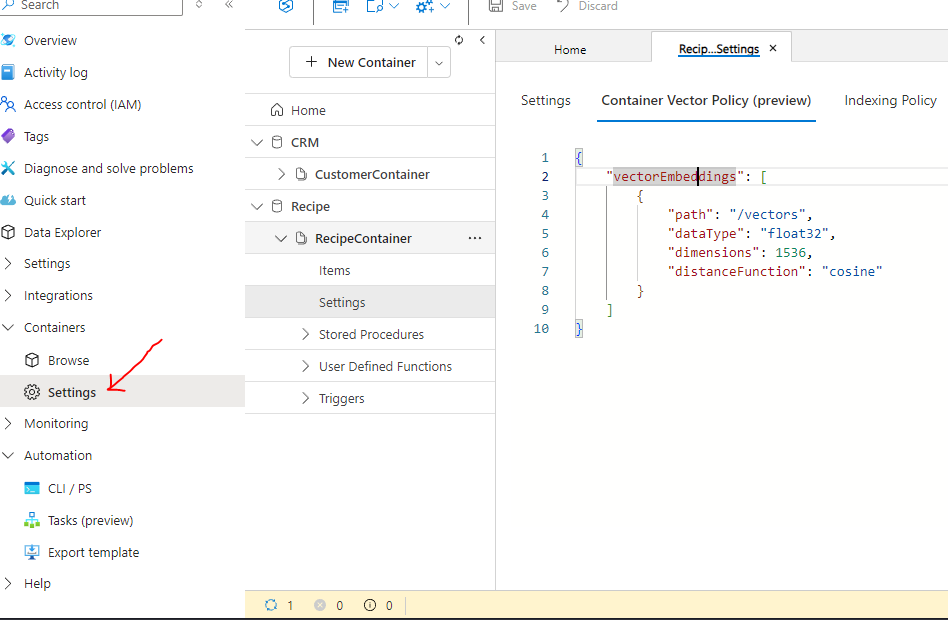
"path": "/vectors": This indicates the path or location within each document where the vector values will be stored
"dataType": "float32": The data type used for storing each component of the vector.
"dimensions": 1536": This indicates the number of dimensions in each vector. A vector with 1536 dimensions means that each vector in this dataset will be an array of 1536 floating point numbers. OpenAI's vector size is typically 1536. Embeddings with “text-embedding-ada-002” is always a vector of 1536 dimensions by default.
"distanceFunction": "cosine": This specifies the similarity metric used to compare vectors. Here we are using cosine similarity.
Please note that the modifying the settings of the Container vector policy is available only for the newly created containers and not for the existing ones and the settings have to be done immediately post container creation. At the time of this write up its not possible to automate the creation of Container vector policy .The settings have to be modified manually.
Code
Next, ensure the following references are added to the project
declare the following variables.
static OpenAIClient openAI_Client;
static string embeddingDeployment, endpoint, key, completionsDeployment, maxToken;
Make sure that Cosmos DB is adequately referenced and set up in the project. You can refer for this article to understand how its done as the data from it will be utilized.
Next, use the ConfigurationBuilder class to set up all the necessary config settings and assign them to the variables declared earlier. Also set the value of openAI_Client and OpenAIClientOptions. OpenAIClientOptions class holds configuration options for an OpenAI client. These options define how the client behaves, such as retry policies and timeouts.
var builder = new ConfigurationBuilder()
.AddJsonFile($"appsettings.json", true, true);
var config = builder.Build();
OpenAIClientOptions clientOptions = new OpenAIClientOptions()
{
Retry =
{
Delay = TimeSpan.FromSeconds(2),
MaxRetries = 10,
Mode = RetryMode.Exponential
}
};
endpoint = config["OpenAIEndpoint"];
key = config["OpenAIKey"];
embeddingDeployment = config["OpenAIEmbeddingDeployment"];
completionsDeployment = config["OpenAIcompletionsDeployment"];
maxToken = config["OpenAIMaxToken"];
openAI_Client = new(new Uri(endpoint), new AzureKeyCredential(key), clientOptions);
Delay = TimeSpan.FromSeconds(2): This sets a 2-second delay between retries. If a request fails the client will wait for 2 seconds before retrying.
MaxRetries = 10: The maximum number of retries allowed. In this case, if the request keeps failing, the client will attempt to retry up to 10 times before giving up.
Mode = RetryMode.Exponential: This specifies the retry attempts. Exponential means that the delay between retries will increase exponentially. For example, after the first retry, the delay might be 2 seconds, then 4 seconds, then 8 seconds, and so on, with each retry waiting longer before trying again.
The next step would be to identify documents where vector embeddings aren't defined. The function below cross checks whether the vector embeddings are set for each individual document and returns the list of documents where they are not.
public static async Task<List<Recipe>> GetRecipesToVectorizeAsync()
{
QueryDefinition query = new QueryDefinition("SELECT * FROM c WHERE IS_ARRAY(c.vectors)=false");
FeedIterator<Recipe> results = container.GetItemQueryIterator<Recipe>(query);
List<Recipe> output = new();
while (results.HasMoreResults)
{
FeedResponse<Recipe> response = await results.ReadNextAsync();
output.AddRange(response);
}
return output;
}
The next step is to add vector embeddings to the documents identified by the above function. The above function GetRecipesToVectorizeAsync is called within the function GenerateEmbeddings.
private static async void GenerateEmbeddings(IConfiguration config)
{
Dictionary<string, float[]> dict = new Dictionary<string, float[]>();
int recipeCount = 0;
var Recipes = GetRecipesToVectorizeAsync().GetAwaiter().GetResult();
foreach (var recipe in Recipes)
{
recipeCount++;
var embeddingVector = GetEmbeddingsAsync(JsonConvert.SerializeObject(recipe)).GetAwaiter().GetResult();
await SetEmbeddings(recipe.id, embeddingVector);
}
}
Here the function GetEmbeddingsAsync takes recipe text as a parameter and returns 1536 dimensional vectors for each recipe text.
public static async Task<float[]?> GetEmbeddingsAsync(string recipe)
{
try
{
EmbeddingsOptions embdOptions = new()
{
DeploymentName = embeddingDeployment,
Input = { recipe }
};
var response = await openAI_Client.GetEmbeddingsAsync(embdOptions);
Embeddings embeddings = response.Value;
float[] embedding = embeddings.Data[0].Embedding.ToArray();
return embedding;
}
catch (Exception ex)
{
Console.WriteLine(ex.Message);
return null;
}
}
The following function SetEmbeddings would embed the vector values in Cosmos DB returned by function GetEmbeddingsAsync for a given recipe text.
public static async Task SetEmbeddings(string key, float[] embeddingVector)
{
container.PatchItemAsync<Recipe>(key, new PartitionKey(key), patchOperations: new[] { PatchOperation.Add("/vectors", embeddingVector) });
}
Now build and run the application
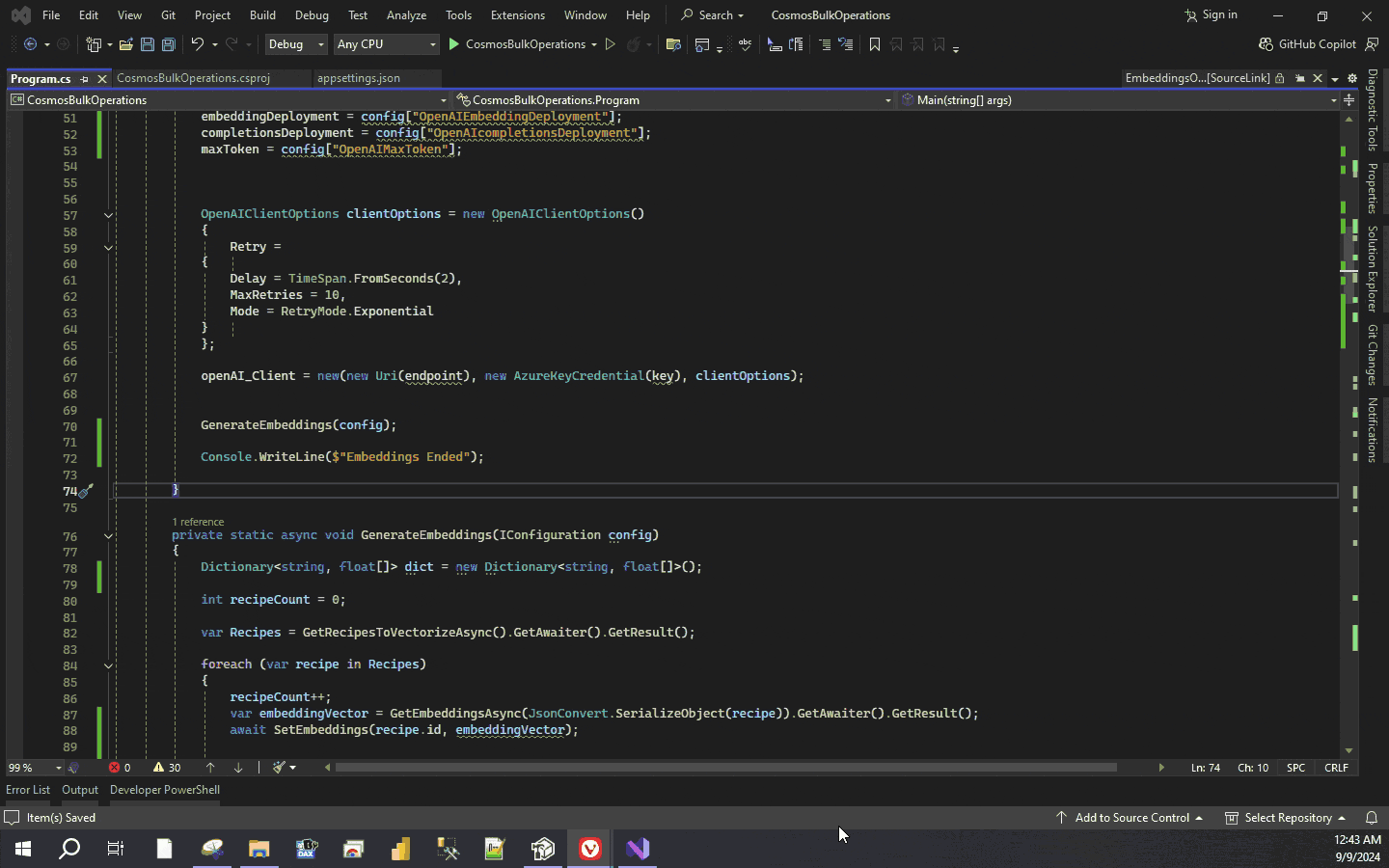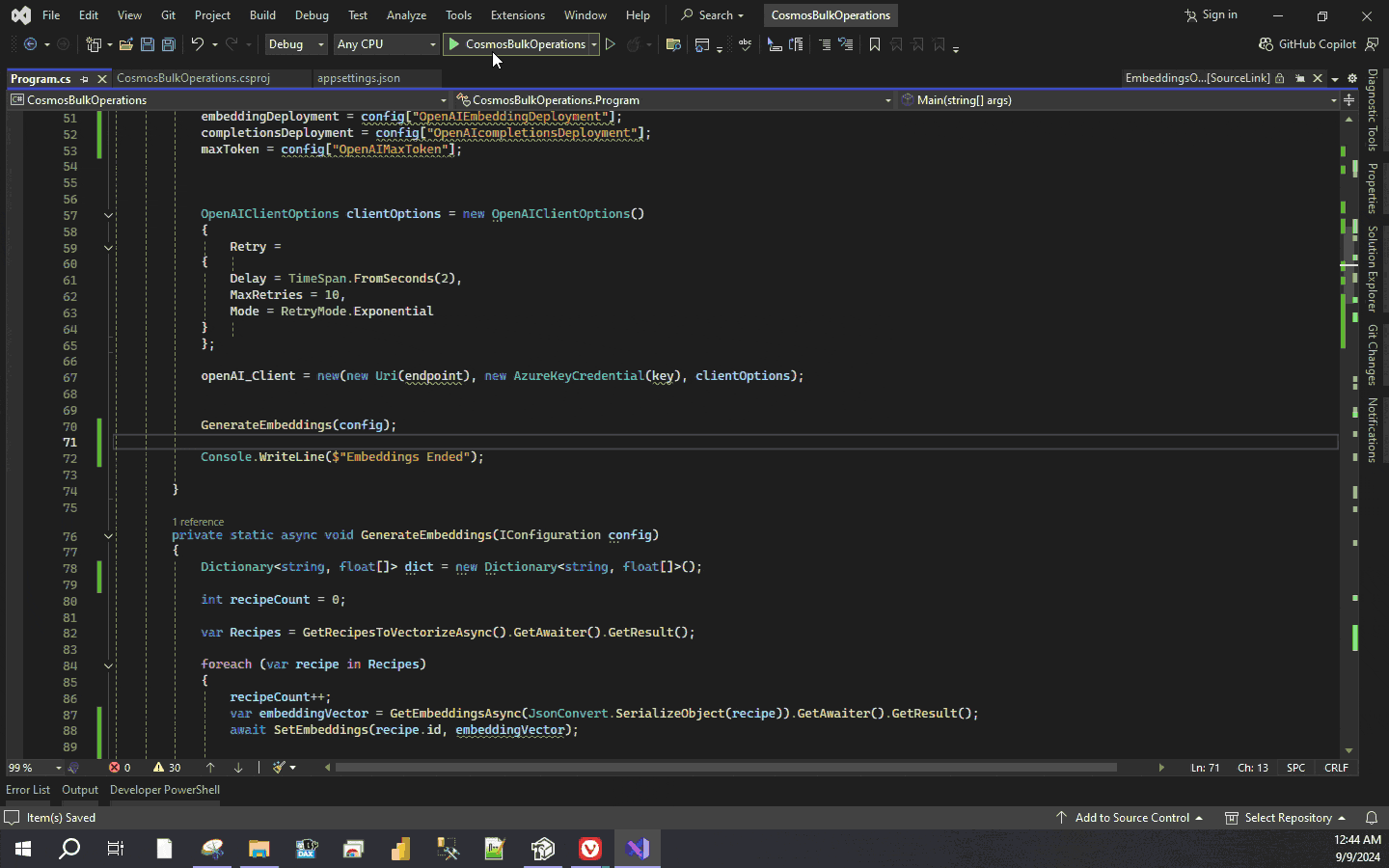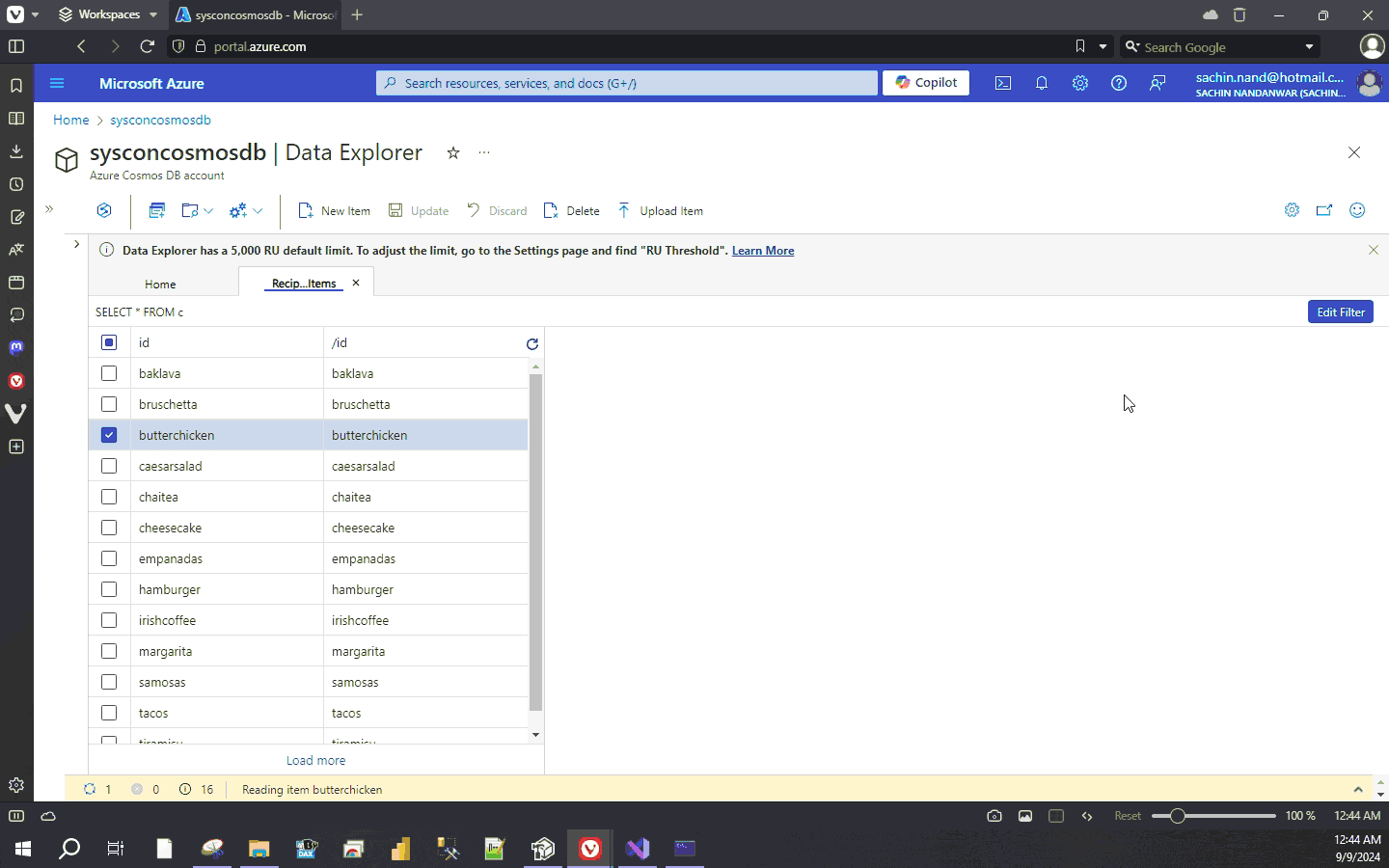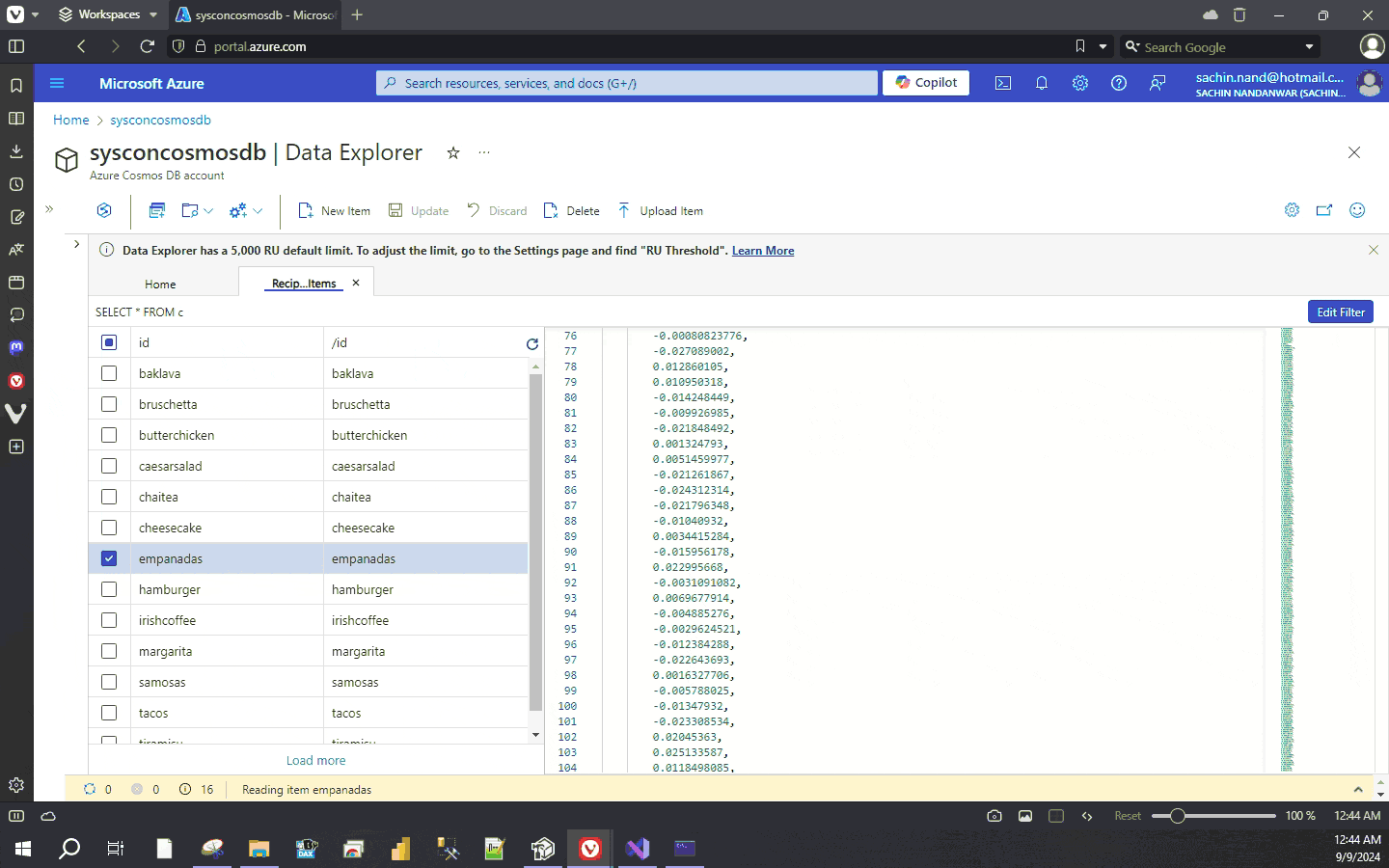
The function GetRecipesToVectorizeAsync identifies documents that require vector embeddings which are then processed by the GenerateEmbeddings function. The function SetEmbeddings patches the vector values of the document. The function creates 1536 dimension vector for each individual document.
Conclusion
My previous articles on vector embeddings were conceptually focused on explanation of the mathematical foundation of how vector similarity works. In this article I have tried to showcase the implementation of vector embeddings on a practical use case.
In the next article we would see how to leverage the vector embeddings to retrieve Augmented LLMs on the data stored in Cosmos DB.
Thank You for reading !!!
Subscribe to my newsletter
Read articles from Sachin Nandanwar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by