ETL Process: A Beginner’s Guide 3
 Shreyash Bante
Shreyash Bante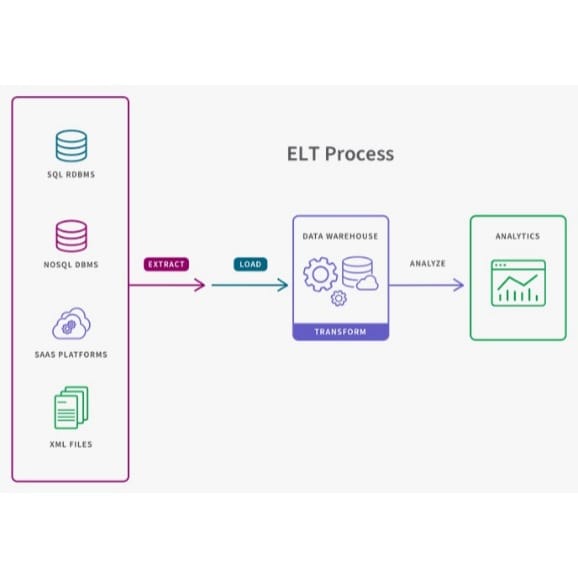
LOAD ⭐
Well, so far we extracted the data from the source and transformed it how difficult will be just to push the data to a location right? well it's different from just pushing the Final Dataframeto a location. how you load data depends on the requirement we will understand about different requirements and loading types here.
Full Load:
In a full load process, all the data from the source is transferred to the target system in one go. This approach is typically used when initializing a database or data warehouse, where the entire dataset needs to be replicated. Full load can be resource-intensive as it processes and moves large volumes of data at once. It’s usually done infrequently, often during off-peak hours, to avoid performance issues on the target system.
Incremental Load:
Incremental load focuses on transferring only the new or updated data since the last load. This approach is more efficient, especially for large datasets, as it reduces the volume of data processed and loaded. Incremental loads are commonly used in data warehousing to keep the system up-to-date without reloading all the data, allowing for frequent updates without significantly affecting system performance.
Bulk vs. Batch Loading:
Bulk loading refers to moving large datasets in a single operation, which is efficient for loading massive amounts of data quickly. It is typically used for one-time migrations or when large data updates are needed. Batch loading, on the other hand, involves transferring smaller chunks of data at regular intervals. It is used when real-time updates are not necessary but maintaining a near-real-time flow of data is important, ensuring the system isn’t overloaded at once.
Now Imagine a Full load fails or a batch load fails because of any issues either on the target database or an error in the process, or some data gets written and then the load fails how to only send the remaining data will be an issue as you are copying the data. These are very common scenarios that can occur. and data engineers need to be prepared for this.
Load Strategies
Append-Only Load:
In an append-only load strategy, new records are added to the target system without making changes to existing data. This approach is simple and ideal when historical data should be preserved without alteration. It’s commonly used in logging or transactional systems where a continuous stream of new data is added but past records remain untouched.
Truncate and Reload:
This strategy involves clearing out the entire target table (truncating) and then reloading all the data from the source. While effective for ensuring the target data remains consistent with the source, it is resource-intensive and can be disruptive, especially for large datasets, as all existing data is removed and replaced.
Upsert (Update/Insert):
The upsert strategy is a combination of updating existing records and inserting new ones. If a record exists, it is updated; if it doesn't, it is inserted as a new entry. This method is efficient for maintaining data accuracy, as it ensures the target system is kept up-to-date with both new and changed records from the source, without needing to reload all data.
Challenges in Data Loading
Handling Schema Changes During Loading:
Schema changes, such as adding new columns or altering data types, can disrupt the data loading process. Without proper handling, these changes can cause load failures or data mismatches. To manage schema changes, it's important to implement dynamic mapping or schema evolution techniques that allow the system to adapt without manual intervention.
Managing Load Failures and Retry Mechanisms:
Load failures can occur due to network issues, source system unavailability, or data inconsistencies. To minimize disruption, it’s crucial to have retry mechanisms in place that automatically attempt the load again after a failure. Additionally, logging errors and implementing alerts can help quickly identify and resolve issues.
Ensuring Data Consistency During the Loading Process (e.g., Atomicity):
Data consistency is vital to ensure the target system remains accurate and reliable. Atomicity, a property of database transactions, ensures that a data load operation is either fully completed or not at all, preventing partial or corrupt data from being loaded. Techniques such as transactional loading, using staging tables, and locking mechanisms help maintain consistency.
Apart from this, there are many other topics that can be covered here. ill be continuing to write on topics like SCD,Monitoring and Error Handling,Differennt tools and actual use cases of overall process.
To Sum It up
the load phase in ETL is crucial for ensuring that transformed data is accurately and efficiently moved to the target system. Various loading strategies, such as append-only, truncate and reload, and upsert, offer flexibility based on the nature of the data and system requirements. However, this phase presents challenges like handling schema changes, managing load failures with retry mechanisms, and ensuring data consistency through atomic operations. Addressing these challenges and choosing the right strategy ensures smooth, reliable, and effective data integration into your systems.
Subscribe to my newsletter
Read articles from Shreyash Bante directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Shreyash Bante
Shreyash Bante
I am a Azure Data Engineer with expertise in PySpark, Scala, Python.