Masterclass: Client-Server Architechture
 Ahmed Zubairu
Ahmed Zubairu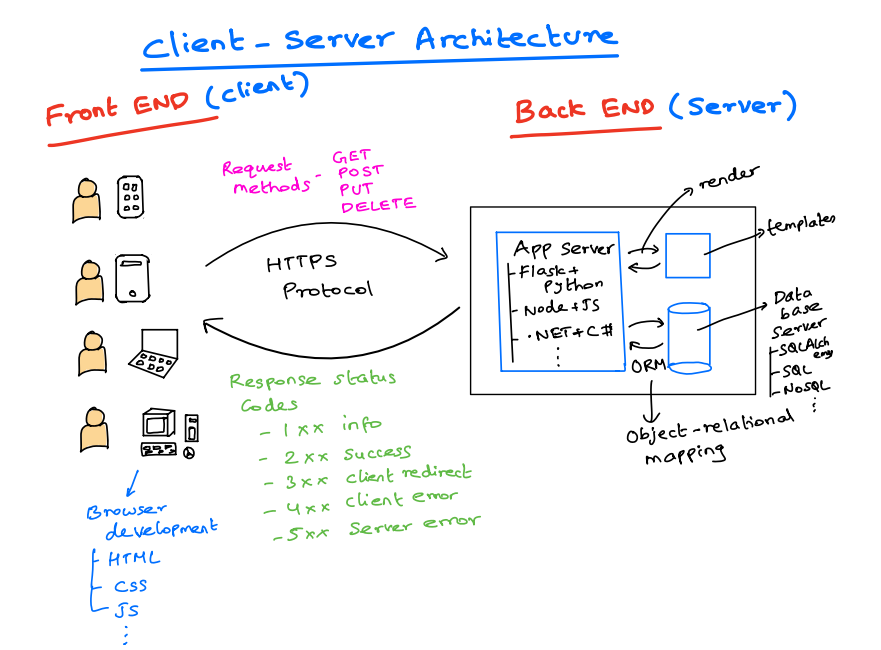
1. Introduction
Definition of Client-Server Architecture: Client-server architecture is a foundational model in computing that defines how services are requested and provided across a network. In this model, there are two main components: the client, which initiates requests for services or resources, and the server, which responds to these requests by providing the requested services or resources. This separation of roles allows for a more organized and scalable system where multiple clients can interact with centralized servers to access data or perform tasks.
Core Principles:
Clients Request Services: Clients, such as web browsers or mobile apps, initiate communication with the server to request data, services, or resources.
Servers Provide Services: Servers handle client requests, process them, and return the necessary responses or resources, such as HTML pages, images, or data from a database.
Communication Over a Network: Clients and servers communicate over a network, typically using standard protocols like TCP/IP, which ensure data is transmitted accurately and reliably.
2. Core Components of Client-Server Architecture
Client:
Definition: A client is a device or application that accesses a service made available by a server. Common examples include web browsers, desktop applications, and mobile apps.
Role: The client's role is to initiate requests to the server and process the responses it receives. For example, a web browser requests web pages from a web server and renders them for the user.
Server:
Definition: A server is a powerful computer or application that provides services, data, or resources to clients over a network. It listens for incoming requests from clients and processes them.
Role: Servers handle requests, perform necessary computations or data retrieval, and respond with the required information. Examples include web servers, database servers, and file servers.
Network:
How Clients and Servers Communicate: The network acts as the medium that connects clients and servers, allowing them to exchange data. Communication typically occurs over the internet or a local area network (LAN), using protocols that ensure reliable data transfer.
TCP/IP Protocol: The backbone of most client-server communications, the TCP/IP protocol suite ensures data packets are sent and received accurately. TCP handles data transmission control, while IP takes care of addressing and routing the packets to the correct destination.
Protocols:
HTTP/HTTPS: Hypertext Transfer Protocol (HTTP) and its secure version (HTTPS) are the primary protocols used by web browsers to request and receive web pages from servers. HTTPS adds a layer of security with encryption, protecting data in transit.
DNS: The Domain Name System (DNS) translates human-readable domain names (like www.example.com) into IP addresses that computers use to identify each other on the network.
TCP/IP Stack: This set of protocols underpins all internet communications, enabling data exchange between client and server applications across diverse network configurations.
These core components work together to form the client-server architecture, which enables efficient, scalable, and flexible communication between users and services in a networked environment.
3. Workflow: How Connecting to the Server Works
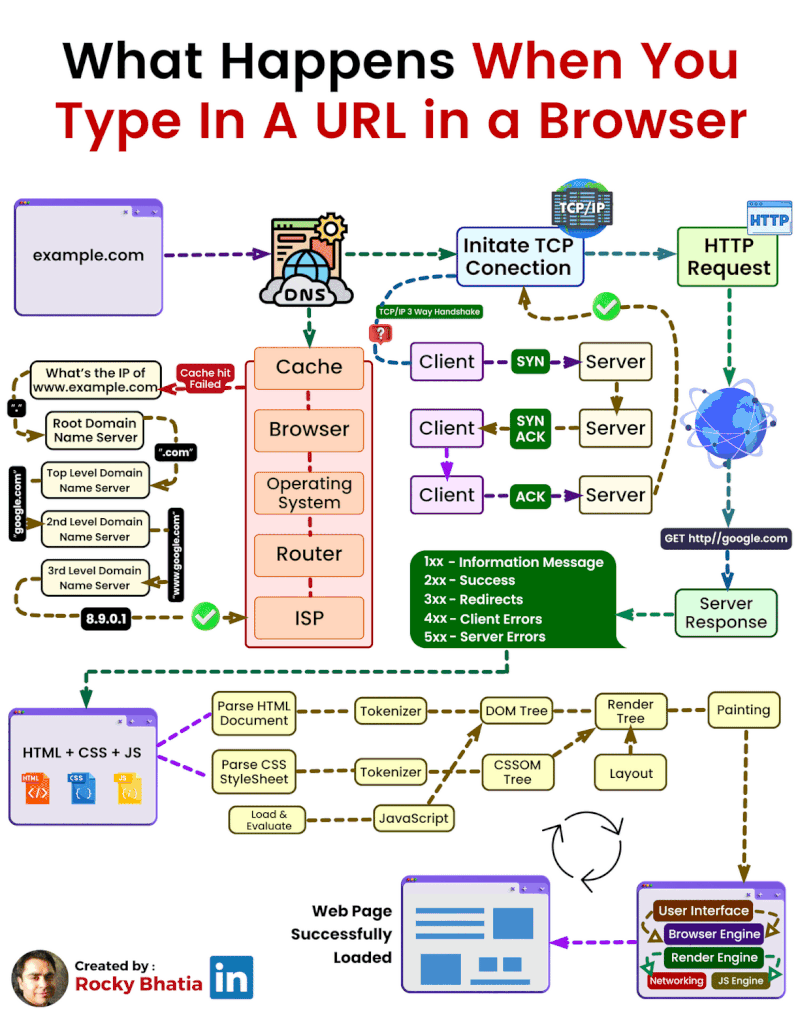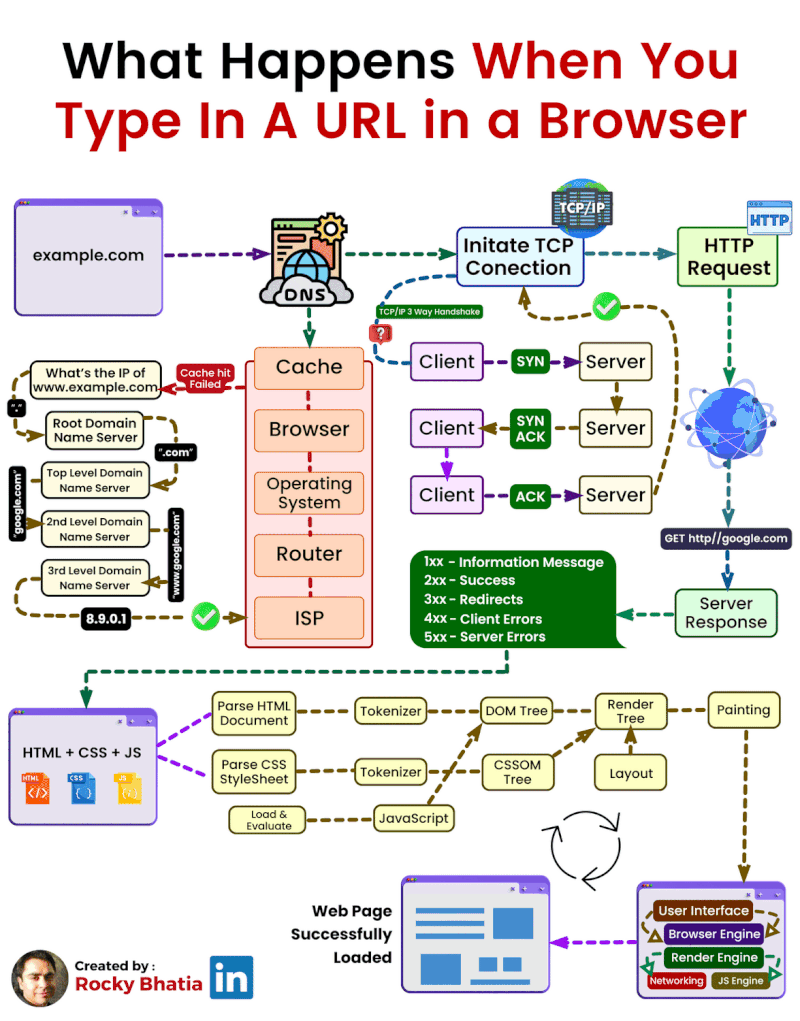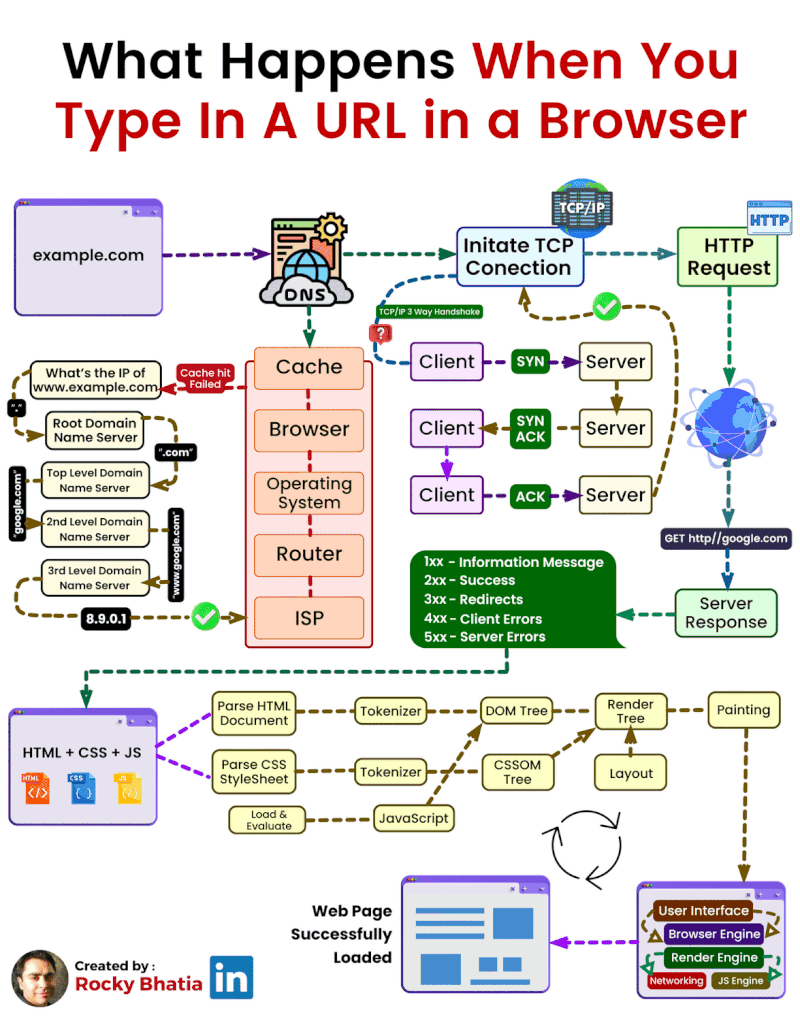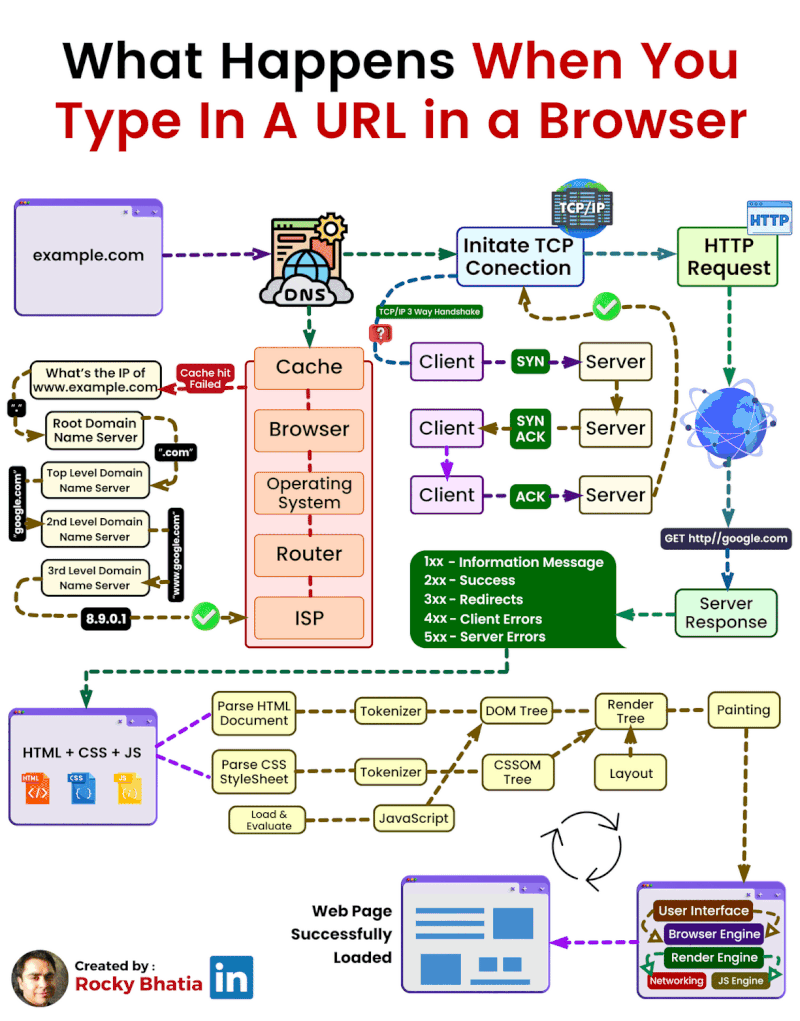
When you type a web address (like www.example.com) into your browser, a lot happens behind the scenes to display the page. Here’s a simple step-by-step breakdown of how this works:
Step-by-Step Connection Process
DNS Lookup:
Before your browser can connect to the website, it needs to know the IP address of the server hosting the website. The Domain Name System (DNS) translates the human-friendly domain name (like www.example.com) into an IP address that computers use to locate each other on the network.
This process checks several caches:
Browser Cache: The browser first checks its own cache to see if it recently visited the site.
OS Cache: If not found in the browser, it checks the operating system's cache.
Router Cache: If still not found, the query moves to the router, which might have the IP address stored.
ISP Cache: Finally, it checks with your Internet Service Provider's (ISP) DNS cache. If none of these caches have the IP address, the ISP's DNS server performs a full lookup by querying other DNS servers on the internet.
TCP Connection:
Once the IP address is found, your browser establishes a connection with the server using the TCP (Transmission Control Protocol). This involves a 3-step process known as the 3-way handshake:
SYN: The browser sends a synchronization packet to the server to initiate a connection.
SYN-ACK: The server responds with a synchronization acknowledgment packet.
ACK: The browser sends an acknowledgment back to the server, completing the connection setup.
HTTP Request/Response Cycle:
After establishing a connection, the browser sends an HTTP request to the server asking for the webpage. For example, it might request an HTML document, images, or other resources.
The server processes this request and sends back the requested data (like HTML, CSS, JavaScript files) in an HTTP response.
Browser Parsing:
Once the browser receives the server’s response, it begins to parse and render the webpage:
HTML Rendering: The browser reads the HTML document and builds the structure of the page.
CSS Styling: It applies CSS to style the page elements (like fonts, colors, and layout).
JavaScript Execution: If the page includes JavaScript, the browser executes it to add interactivity, such as form validation or animations.
JavaScript Engine (V8)
The JavaScript Engine in your browser (like V8 in Chrome) plays a crucial role in executing JavaScript code:
Just-in-Time (JIT) Compilation: This technique compiles JavaScript code into machine code on the fly, as it's needed, which helps to optimize performance and speed up execution.
Ahead-of-Time (AOT) Compilation: In some cases, JavaScript code can be pre-compiled before it’s even executed, which can further improve performance by reducing the load time.
These steps happen within milliseconds, making it possible for you to quickly access and interact with websites. The entire process is a seamless interaction between your browser, your computer’s hardware and software, and the server hosting the website, all working together to deliver the content you requested.
4. Types of Client-Server Architecture
Client-server architecture comes in various forms, depending on how complex the setup is and how many layers of servers are involved. Here are the most common types:
2-Tier Architecture:
This is the simplest form, where the client communicates directly with the server.
Example: A web browser (client) directly connects to a web server to load a website.
It’s straightforward but can get overwhelmed if too many clients try to connect at once.
3-Tier Architecture:
In this setup, there are three layers: the client, an application server, and a database server.
Example: A web browser (client) talks to an application server that runs the business logic, and the application server talks to a database server to fetch or store data.
This structure makes it easier to manage and scale because each layer can be managed separately.
N-Tier Architecture:
This extends the 3-tier setup by adding more specialized layers, such as caching servers, API servers, or microservices.
Example: An online shopping site where the browser connects to a front-end server, which communicates with separate servers for inventory, payments, and customer data.
This allows for better performance and flexibility, as each layer can be fine-tuned independently.
5. Variants of Client-Server Architecture
Beyond the basic types, there are some modern variants of client-server architecture that offer even more flexibility and efficiency:
Microservices:
Microservices break down a big application into smaller, independent services that work together.
Each service is responsible for a specific task, like user authentication, payment processing, or managing orders.
Benefits:
Easier to scale specific parts of the application as needed.
Teams can develop and deploy different services independently, speeding up development.
Fault isolation means if one service fails, it doesn’t necessarily take down the entire application.
Serverless Architecture:
In serverless architecture, developers don’t have to manage servers at all. Instead, they write functions that run in the cloud.
Example: A function that sends a confirmation email when someone signs up on a website.
Benefits:
No need to worry about server management—cloud providers handle all the infrastructure.
It automatically scales to handle the workload, which can be more cost-effective because you only pay for what you use.
It’s great for tasks that don’t need to run all the time but must handle lots of requests when they do.
These modern variants, especially microservices and serverless, represent an evolution of traditional client-server architecture, making it easier to build, maintain, and scale complex applications. They help organizations adapt quickly to changing needs, improve performance, and reduce costs by leveraging the flexibility and power of cloud computing.
6. Advantages of Client-Server Architecture
Client-server architecture offers several benefits that make it a popular choice for building applications. Here are some of the key advantages:
Scalability:
Client-server systems can easily be scaled to handle more users or increased workloads.
Horizontal Scaling: Adding more servers to distribute the load.
Vertical Scaling: Upgrading existing servers with more power (like more RAM or faster CPUs).
Compared to monolithic architecture, where everything is bundled into a single application, client-server setups make scaling easier and more flexible.
Fault Tolerance:
Client-server systems can be designed with redundancy, meaning if one server fails, others can take over.
Load Balancing: Distributes client requests across multiple servers to prevent any single server from becoming a bottleneck.
This setup improves reliability because even if part of the system fails, the rest can continue to operate.
Maintainability:
Since client-server architecture separates different parts of an application (like the front-end, back-end, and database), it’s easier to update or fix specific parts without affecting the whole system.
For example, you can upgrade the server software without needing to change the client applications, and vice versa.
Centralized Control:
Servers manage and store all the data, making it easier to enforce security policies, back up data, and maintain consistency across the application.
This central control is beneficial for managing user access, tracking data changes, and ensuring that the application runs smoothly.
Security:
With centralized servers, security measures like firewalls, encryption, and user authentication can be more easily implemented and managed.
Compared to peer-to-peer models, where each device communicates directly, client-server architecture provides better control over data protection and user access.
7. Comparison to Other Architectures
To better understand the strengths of client-server architecture, it helps to compare it with other common models:
Monolithic Architecture:
In monolithic architecture, everything (front-end, back-end, and database) is bundled into a single application.
Challenges:
Scaling is harder because the entire application must be duplicated for each instance.
Fault tolerance is lower; if one part fails, the whole application can crash.
Updates are more challenging because a change in one part can affect the entire system.
Compared to client-server, monolithic systems are simpler to develop initially but become complex to manage as they grow.
Peer-to-Peer (P2P) Architecture:
In P2P architecture, there’s no central server; instead, each device (or node) can act as both a client and a server, sharing resources directly.
Pros:
Decentralization can improve redundancy and fault tolerance since no single point of failure exists.
Ideal for sharing large amounts of data among many users (like torrenting).
Cons:
Security can be more challenging to manage, as there is no central authority.
Scalability issues arise because each node must handle its own resources and connections.
Compared to client-server, P2P is less structured and can be harder to secure and maintain.
Overall, client-server architecture offers a balanced approach with good scalability, security, and control, making it suitable for a wide range of applications. While other architectures have their own benefits, the structured nature of client-server makes it a reliable choice for many businesses and developers.
8. Disadvantages of Client-Server Architecture
While client-server architecture has many advantages, it also comes with some downsides. Here are the key challenges:
Scalability Issues:
Scaling a client-server system can be difficult when many users try to access the server simultaneously. This can lead to slowdowns or even crashes if the server gets overwhelmed.
Compared to microservices or cloud-based solutions, which are designed to handle heavy loads more flexibly, traditional client-server setups might struggle under peak demand without significant investment in infrastructure.
Single Point of Failure:
In a client-server setup, if the server goes down, all clients relying on it can’t function.
This makes it crucial to implement redundancy (like backup servers) and failover mechanisms (automatic switching to a backup if one server fails) to keep the system running smoothly.
Network Dependence:
The entire system relies on a stable and fast network connection. If the network is slow or experiences outages, the performance of the client-server system suffers.
This dependency can be a major issue in areas with unreliable internet connectivity or when trying to serve users spread across different geographic locations.
Cost:
Maintaining servers, including hardware, networking, and scaling, can be expensive.
You need to invest in powerful servers, proper networking equipment, and possibly cloud services to handle traffic efficiently.
As the demand grows, costs can escalate quickly, especially if you need to add more servers or pay for additional resources in the cloud.
9. Conclusion
Summary of Key Points: Client-server architecture is a widely used model that organizes how services and resources are provided across a network. It offers many benefits, such as scalability, centralized control, and improved security. However, it also has trade-offs, including potential scalability issues, single points of failure, reliance on a stable network, and high maintenance costs.
Future Trends: The evolution of technology is moving towards microservices and serverless architectures, which build on the client-server model by offering more flexibility, better fault tolerance, and often lower costs. These newer approaches allow applications to scale more easily and respond more efficiently to changing demands, making them a natural progression for businesses looking to modernize their systems. As the tech landscape continues to evolve, the shift towards these advanced architectures is likely to accelerate, providing even more robust and adaptable solutions for application development.
Subscribe to my newsletter
Read articles from Ahmed Zubairu directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by