RAG Explained: How 'This' Company Implemented Retrieval-Augmented Generation
 Zahiruddin Tavargere
Zahiruddin Tavargere
Video
The Context
TechnoHealth Solutions, a fictitious, mid-sized tech company that builds software for hospitals, has identified a critical issue facing healthcare professionals - information overload and outdated knowledge.

The Problem:
Picture this:
Doctors spend hours buried in research instead of treating patients
Nurses struggling to keep up with thousands of new medical studies published every week
Patients receiving inconsistent care because their providers can't access the latest information
The constant fear of medical errors due to outdated knowledge
It's a healthcare nightmare, and it's happening right now in hospitals around the world.
The Failed Solutions:

TechnoHealth Solutions first thought, "Let's just build a better search engine!" But they quickly realized that would only add to the problem. Doctors don't have time to sift through endless documents.
Then they considered an AI chatbot. But two major roadblocks appeared:
The risk of AI "hallucinations" – making up false medical information
The sheer volume of medical data exceeded what current AI systems could handle
The Breakthrough:
Finally, TechnoHealth Solutions developed MedAssist AI, a system that leverages Retrieval Augmented Generation (RAG) technology to address these challenges. Here's how RAG solved their problem:
But what exactly is RAG, and how does it solve this medical knowledge crisis?
What is RAG?
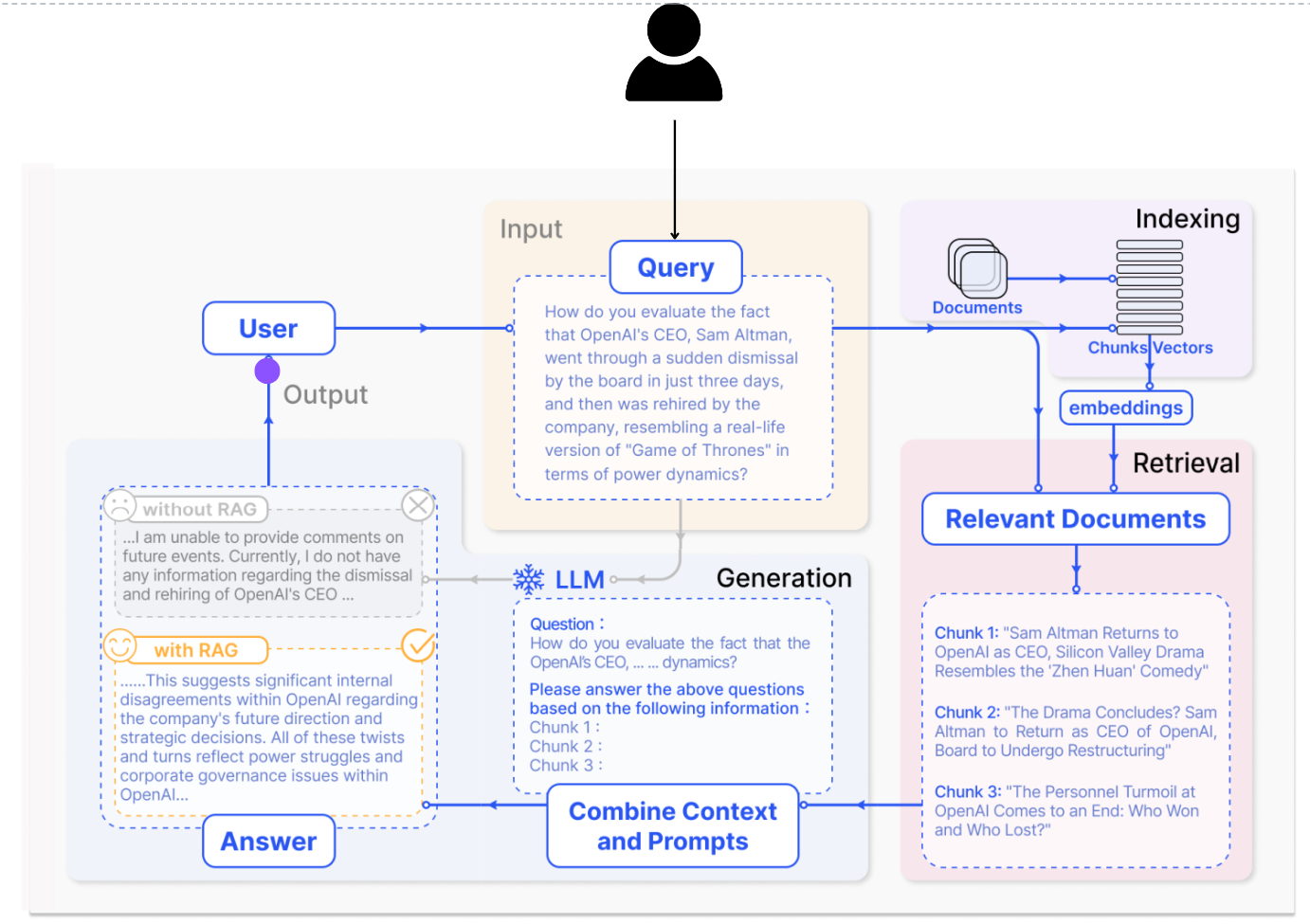
Here’s how it works.
Retrieval: When a user asks a question or provides a prompt, RAG first retrieves relevant passages from a vast knowledge base. This knowledge base could be the internet, a company’s internal documents, or any other source of text data.
Augmentation: The retrieved passages are then used to “augment” the LLM’s knowledge. This can involve various techniques, such as summarizing or encoding the key information.
Generation: Finally, the LLM leverages its understanding of language along with the augmented information to generate a response. This response can be an answer to a question, a creative text format based on a prompt, or any other form of text generation.
Why RAG?
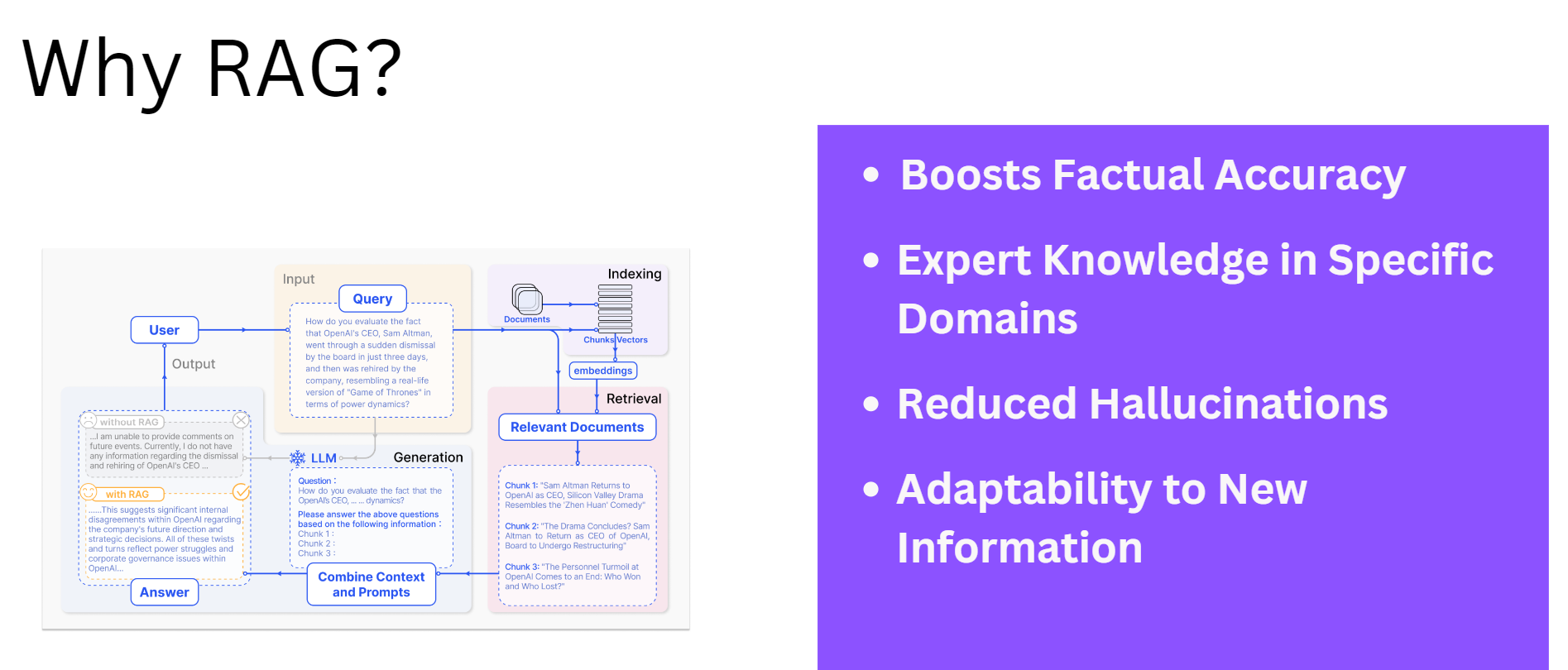
Boosted Factual Accuracy: RAG strengthens LLMs by connecting them to external sources of information, like databases or live feeds. This ensures that their responses are based on real-world facts rather than relying solely on what they were trained on.
Expert Knowledge in Specific Domains: General-purpose LLMs are like a jack of all trades—they know a bit about everything but aren’t experts in any one field. With RAG, you can integrate specific knowledge bases, allowing the AI to answer highly specialized questions.
Fewer Mistakes (Reduced Hallucination): LLMs sometimes make up information that sounds convincing but isn’t true. RAG reduces this risk by providing the AI with reliable sources to back up its claims, leading to more trustworthy responses.
Adaptability to New Information: The world is constantly evolving, and LLMs trained on older data can quickly become outdated. RAG solves this by giving AI access to up-to-date sources, so it can always provide current information.
Customizable and Scalable: RAG isn’t a one-size-fits-all solution. It can be adjusted to fit your needs, whether you're working with limited resources or require more power for complex tasks.
TechnoHealth Solutions’ RAG Implementation
Here’s how TechnoHealth Solutions built their RAG solution to make their AI smarter, faster, and more reliable.
Step 1: Building an Indexing Pipeline
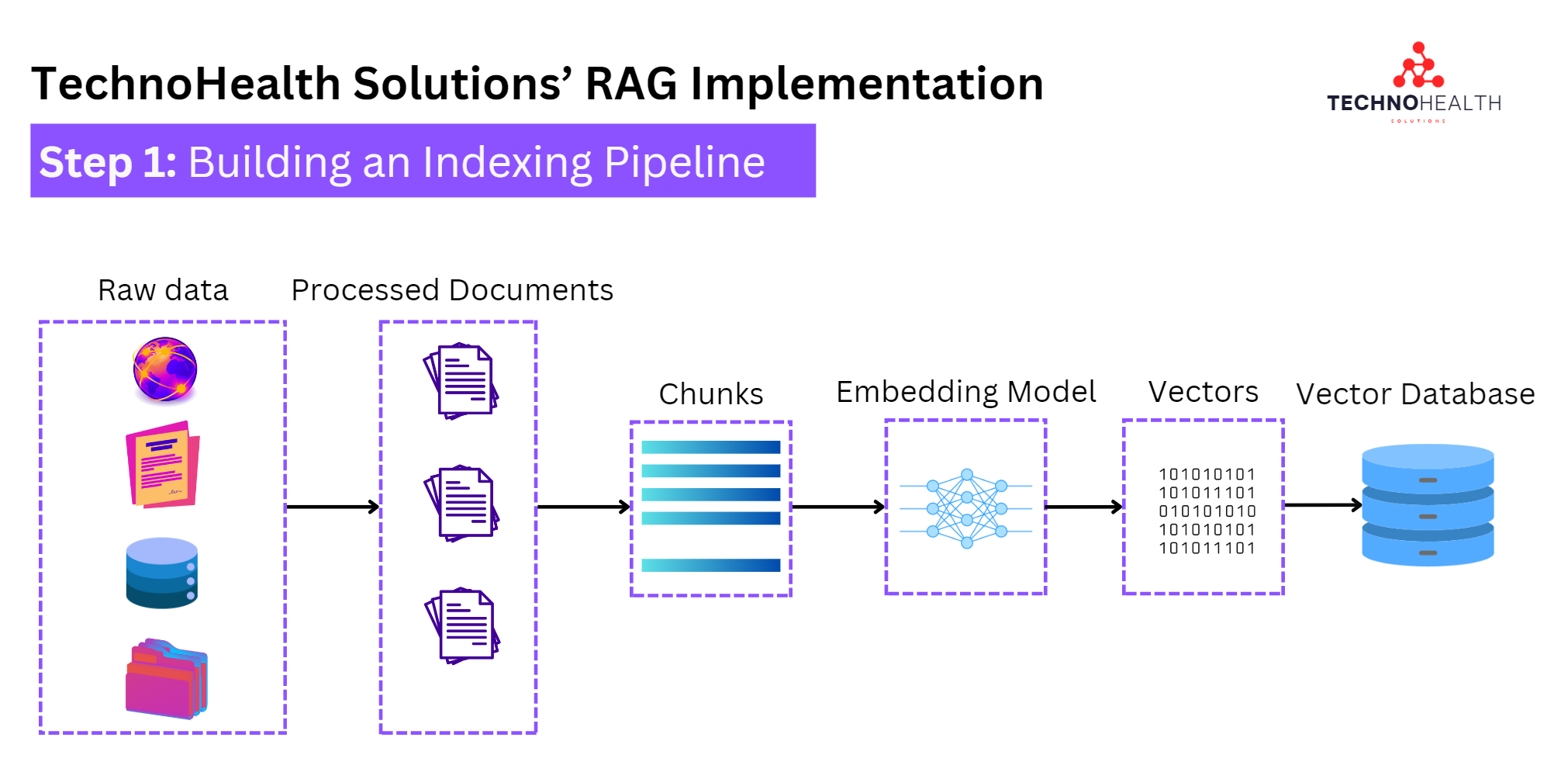
The first step was to organize and process their data. TechnoHealth consolidated all their data sources, from medical reports to research papers. They then:
Processed the documents by breaking them down into smaller, manageable chunks.
Passed these chunks through an embedding model, which turned them into vector representations, or "embeddings." These are mathematical versions of the text that make it easy for the system to compare and find similarities.
Finally, they stored all these embeddings in a vector database. Think of this as a specialized storage space for these mathematical text chunks.
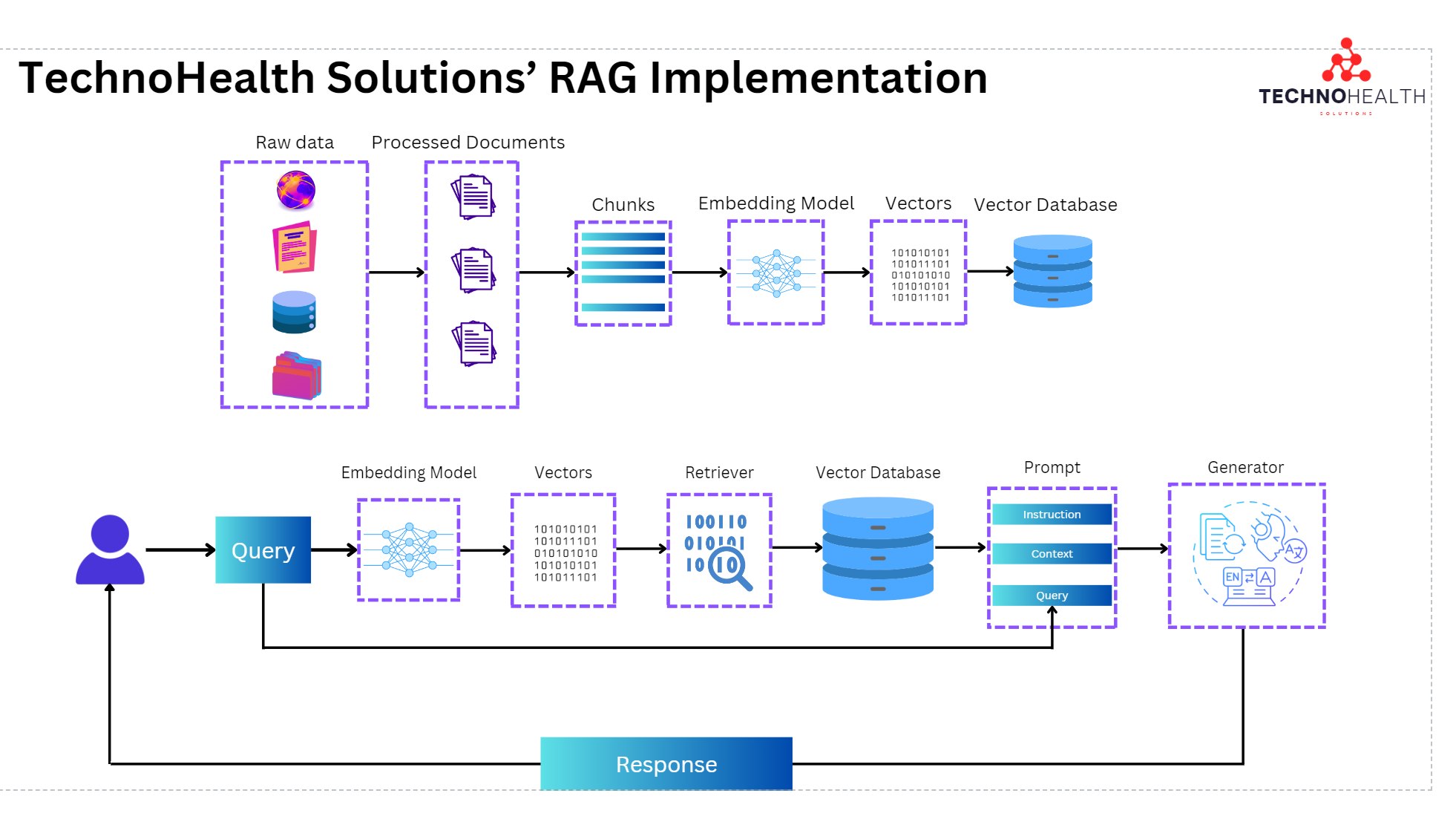
Step 2: Building the Retrieval System
When a user asks a question, TechnoHealth’s retrieval system goes to work:
It first converts the user’s question into an embedding (just like they did with the documents).
Then, it compares this question embedding to all the text chunks stored in the vector database to find the most similar chunks.
Step 3: Augmenting the LLM
Now comes the magic of augmenting the LLM’s knowledge:
The system crafts a prompt that includes:
Instructions for the LLM.
The user’s question.
The most relevant documents retrieved from the database (the context).
This carefully crafted prompt tells the LLM how to use the data to generate a better response
Step 4: Generating the Response
Finally, the crafted prompt is sent to the LLM:
The LLM uses the instructions and the context to generate a complete, informed response to the user’s query.
The response is sent back to the user, more accurate and grounded in real-world data than if the LLM had answered from its general knowledge alone.
Conclusion:
By combining indexing, retrieval, augmentation, and generation, TechnoHealth Solutions built a RAG system that ensures every answer their AI provides is based on real, up-to-date knowledge.
In the next article, we will talk about pre-retrieval optimizations.
Subscribe to my newsletter
Read articles from Zahiruddin Tavargere directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Zahiruddin Tavargere
Zahiruddin Tavargere
I am a Journalist-turned-Software Engineer. I love coding and the associated grind of learning every day. A firm believer in social learning, I owe my dev career to all the tech content creators I have learned from. This is my contribution back to the community.