Building an Automated Job Scraping System on AWS
 Freda Victor
Freda VictorTable of contents

In this blog, I’ll guide you through the process of building an automated job scraping system on AWS, sharing my journey, challenges, and solutions. This project involves scraping job data from various sources, processing it with AWS Lambda, storing the data in S3, and serving the data through a static website. We’ll also explain how we set up CloudWatch for scheduling and used a combination of AWS services to create a fully automated system. Throughout the process, we faced several challenges that we’ll share, along with the solutions we implemented.
Key Features 🔑
Serverless & Scalable: Scrapes jobs from multiple websites using Dockerized Lambda containers.
Real-Time Alerts: Sends job alerts via Amazon SNS when new jobs match specific keywords.
Automated Scheduling: Periodic scraping using AWS CloudWatch to keep job listings up-to-date.
Static Website: Hosted on Amazon S3, displaying job listings in a clean, accessible format.
Project Flow
Web Scraping with Python & AWS Lambda Function
Data Storage in AWS S3 Bucket
Automating & Scheduling with AWS CloudWatch Events
Job Alerts via AWS SNS
Static Website Hosting in AWS S3 (For Job Board)
| Technology | Description |
| Python | The core programming language used for the scraping scripts. |
| Selenium | For automating browser interactions and handling dynamically loaded content. |
| BeautifulSoup | For parsing HTML and extracting data from web pages. |
| XPath & CSS Selectors | For precise and flexible data extraction from HTML elements. |
| HTML, CSS, JavaScript | For building the static website interface to display job listings. |
| AWS Lambda | To run the scraping logic as a serverless function in the cloud. |
| Docker | Used to package and deploy the Lambda function with all dependencies. |
| AWS S3 | For storing job data and hosting the static website. |
| AWS CloudWatch | To schedule automated scraping tasks at regular intervals. |
| AWS SNS | To send job alerts to users via email or SMS. |
Web Scraping with Python & AWS Lambda Function
Web scraping is a powerful tool for gathering data across the web, but it comes with its own set of challenges. I embarked on a project to scrape job listings from various websites, which proved to be an excellent learning experience. This blog will walk you through the process, highlighting the hurdles I encountered, the solutions I devised, and the valuable insights I gained.
Starting Point: Setting Up the Environment on VS Code
The first step in any web scraping project is to set up the right environment. I used Python’s Selenium library for web automation and BeautifulSoup for parsing HTML.
To run Selenium, I needed a ChromeDriver that matched my Chrome version, which I placed in a specified directory:
driver_path = "/Users/....../..../chromedriver"
This setup allowed me to automate web browsing, interact with web elements, and extract the necessary data.
- Challenge 1: Identifying Job Elements
My first challenge was to identify and extract job elements from various websites correctly. Websites often have unique structures, with job listings spread across different HTML tags and classes. For instance, some sites used <div> elements with complex nested structures, while others relied on lists (<ul> and <li> tags).
Solution: I used Chrome’s Inspect tool to manually inspect each website’s HTML structure. This allowed me to identify unique class names or attributes that I could target with BeautifulSoup or Selenium.
For example: job_elements = soup.find_all('div', class_='posting')
- Challenge 2: Dynamic Content Loading
Some websites load content dynamically using JavaScript. This meant that the content wasn’t immediately available in the initial HTML source, causing the scrapers to miss job listings.
Solution: I implemented Selenium’s WebDriverWait to give the browser time to fully load the content before scraping:
WebDriverWait(driver, 15).until( EC.presence_of_element_located((By.XPATH, "//li[contains(@class, 'Role_roleWrapper')]")) )
This method ensured that all dynamically loaded elements were available before I attempted to scrape them.
- Challenge 3: Handling Complex and Dynamic HTML Structures
Another significant challenge was dealing with complex and dynamic HTML structures. Many websites use dynamically generated class names, making it difficult to target elements reliably.
Solution: To overcome this, I switched to using XPath and more robust CSS selectors that could handle dynamic class names:
job_elements = soup.select("li[class*='Role_roleWrapper']")
This approach proved more resilient, allowing me to capture the correct elements even when the class names changed slightly.
- Challenge 4: Incorrect Data Extraction
During the scraping process, I occasionally encountered situations where the extracted data was incorrect, such as missing job titles or incorrect URLs. This was often due to unexpected changes in the website’s structure or overlooked edge cases.
Solution: I added additional checks and debugging print statements to identify the exact source of the issue. For example, I verified that each job title and URL was correctly extracted before storing them:
title = title_element.get_text(strip=True) if title_element else 'N/A' link = link_element['href'] if link_element else 'N/A'
Additionally, I used the .split('|')[0] trick to clean up location data, ensuring we only captured the main location from the full string.
Aha Moments and Insights
JavaScript-Rendered Content: Understanding that some content is loaded via JavaScript and thus requires waiting or interaction was a key insight. This realization shifted how I approached certain sites, using Selenium’s capabilities to simulate user actions.
XPath vs. CSS Selectors: While CSS selectors are usually sufficient, learning when and how to use XPath for more complex queries was a crucial lesson. XPath proved invaluable when dealing with deeply nested or dynamically generated elements.
Importance of Robust Error Handling: Adding robust error handling and debugging helped catch issues early and made the scraping process more reliable. This included using try-except blocks and logging meaningful error messages.
Tips and Tricks
Always Inspect the Website First: Before you start writing code, spend time exploring the website’s structure using Chrome’s Inspect tool. Luckily some websites have their job API which I can directly call using
GetorPostrequests. This will save you a lot of headaches later.Use WebDriverWait: When dealing with dynamic content, always use WebDriverWait to ensure all elements are fully loaded before scraping.
XPath for Complex Structures: If CSS selectors aren’t working or are too complex, switch to XPath. It’s often more precise and can handle dynamic elements better.
Debugging and Validation: Regularly print and validate the data you’re scraping to ensure accuracy. This helps catch errors early and ensures your scraper is working as expected.
Creating an S3 Bucket and Optimizing Python Code for AWS Lambda
Step 1: Creating an S3 Bucket
After writing and testing the web scraping Python script, the next step was to set up an S3 bucket in AWS to store the scraped job data.
Bucket Creation:
In the AWS S3 console, we created a new bucket named
job-scraper-bucket-project. This bucket will serve as the storage location for job data scraped by the Lambda function.We ensured that the appropriate permissions were set up so that the Lambda function could write job data (in JSON format) into this bucket. This involved:
Attaching an IAM policy to the Lambda function’s execution role, permitting it to put objects into the S3 bucket.
Testing was done manually to confirm that Lambda could successfully write job data to the bucket.
Configuring Bucket Permissions:
To securely manage data access, we defined strict bucket policies. This allowed the Lambda function to have write access while restricting any unwanted public access.
Here is a simplified version of the lambda writing to our bucket in the job scraping code:
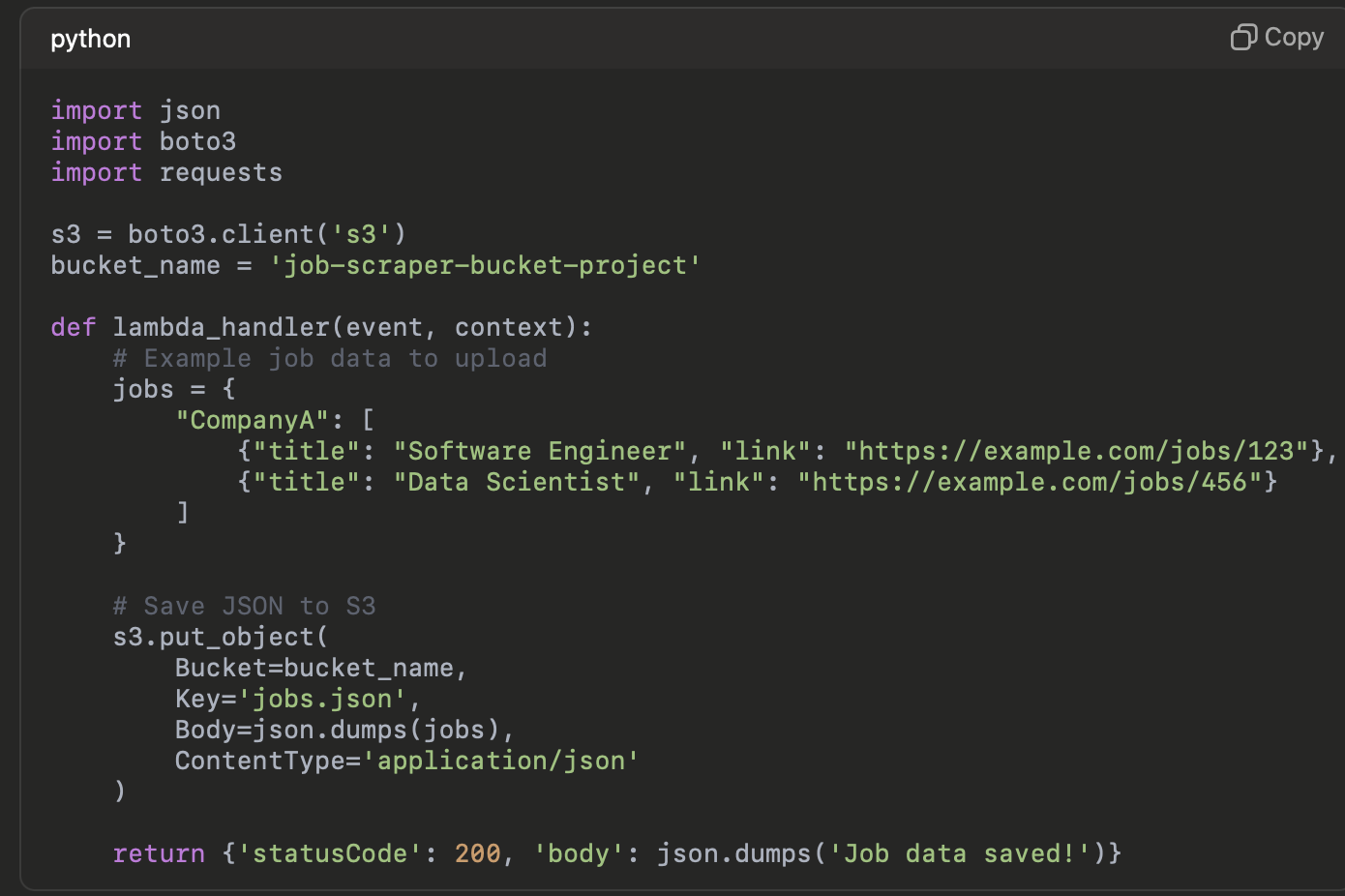
By leveraging AWS best practices, we ensured that S3 bucket versioning and encryption were enabled for data protection while keeping within the AWS Free Tier.
Step 2: Optimizing Python Code for Lambda
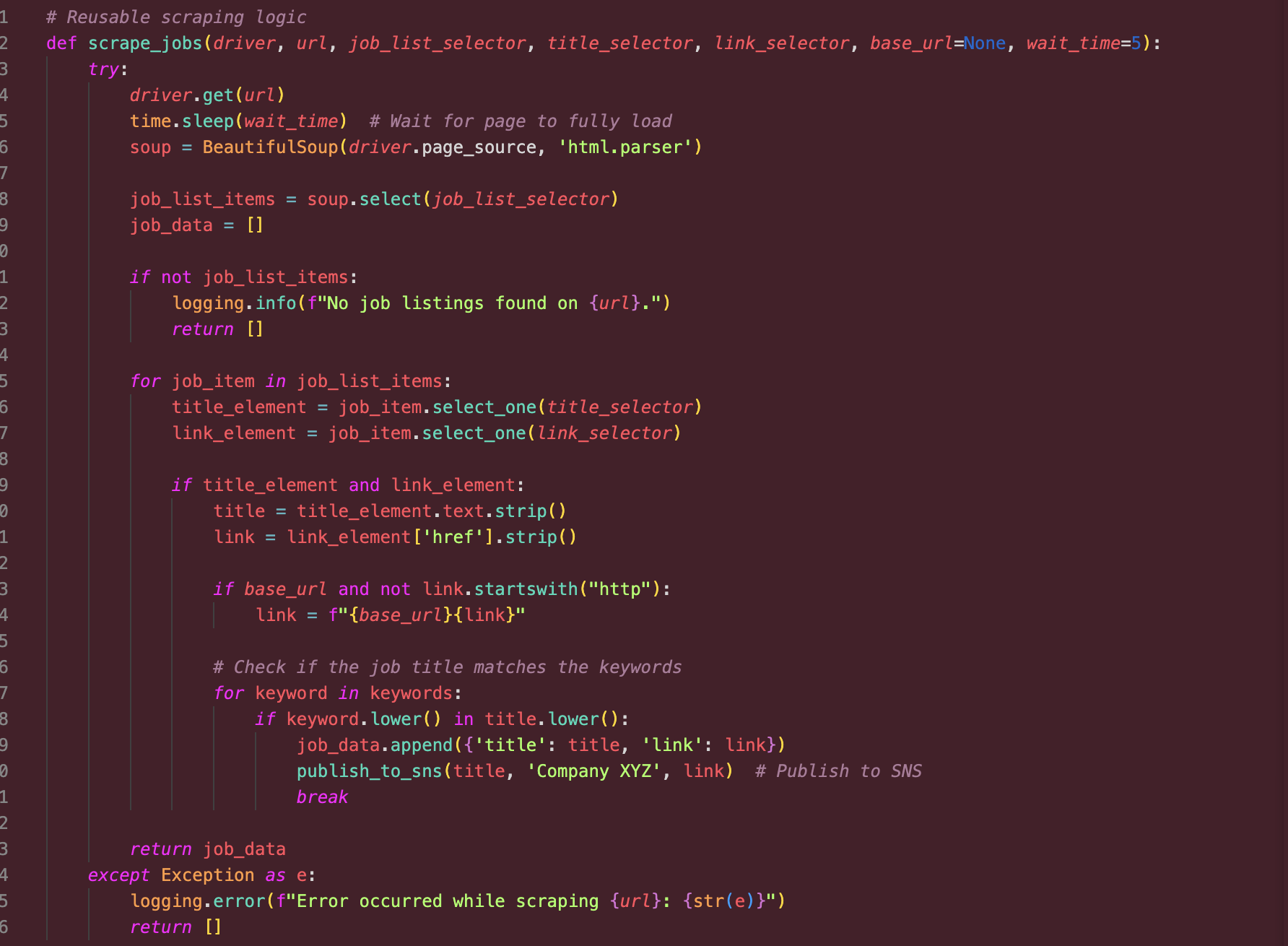
To make the scraping process efficient, scalable, and cost-effective on AWS Lambda, we optimized the Python code and consolidated dependencies.
Refactoring the Python Code:
Reusability and Modularity: The code was optimized by breaking it down into functions, separating the core scraping logic from other parts like S3 interactions. This modular structure made it easier to maintain and update.
Generalizing Scraping Logic: We identified common elements across the websites we were scraping and consolidated the logic into a function that could handle different target URLs and scraping patterns. This made the code more adaptable for scaling to additional websites in the future.
Handling Dependencies: Deploying a Docker-based AWS Lambda Function for Web Scraping Using Serverless Framework and Selenium
The Python scraping script required external Python libraries such as Selenium, BeautifulSoup, and requests. These dependencies are required by the Lambda function to run efficiently. AWS Lambda is a serverless environment, but it doesn't natively support running a headless browser like Chrome.
Our goal was to make headless Chrome work in this environment, allowing us to run Selenium for web scraping tasks. Unfortunately, running headless Chrome on AWS Lambda is not straightforward due to the absence of built-in browser binaries and required dependencies. In this post, we walk through our journey of setting up Selenium with Headless Chrome and Python libraries like BeautifulSoup and requests on Lambda, the challenges faced, and how we resolved them—using pre-built Docker.
Key Steps Involved
Set up AWS Lambda with Selenium and headless Chrome for web scraping.
Use Docker to package the environment.
Deploy the function using the Serverless Framework.
Install Serverless Framework using npm:
npm install -g serverlessAfter installation, configure it by running:
serverlessThis command will guide you through signing into the framework and setting up access to your AWS account.
Clone the Docker-Selenium-Lambda Repository
To avoid configuring Selenium and headless Chrome manually, we used the pre-built Docker image by umihico. This project already includes all the necessary dependencies for running Selenium in AWS Lambda.
git clonehttps://github.com/umihico/docker-selenium-lambda.gitcd docker-selenium-lambdaThe project already contains a Dockerfile, serverless.yml, and other configurations. The Dockerfile is crucial as it sets up the container environment, including Selenium, Chromium, and ChromeDriver, which we will use for scraping.
Configure the Docker Image and Serverless
The serverless.yml file in this project is configured to:
Build and push the Docker image to the AWS Elastic Container Registry (ECR).
Deploy the Lambda function, linking it to the ECR Docker image.
This configuration defines:
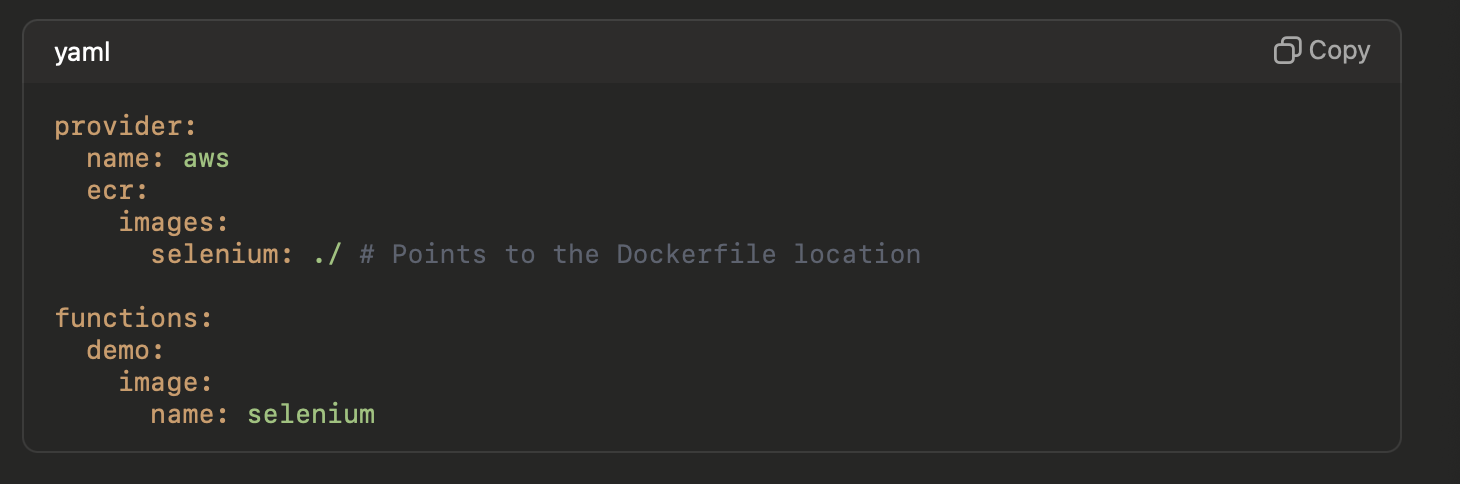
The ECR image that the function will use.
A Lambda function called "demo" points to this Docker image.
Deploy the Function
Build the Docker image and deploy the Lambda function by running:
sls deployWhat happens here:
Docker Image Build: Serverless builds the Docker image locally, which includes Selenium, ChromeDriver, and Headless Chromium.
ECR Push: The image is pushed to your AWS ECR.
Lambda Deployment: AWS Lambda is deployed with this Docker image. Check that the Lambda function has been deployed by visiting the AWS Lambda console.
Testing in Lambda:
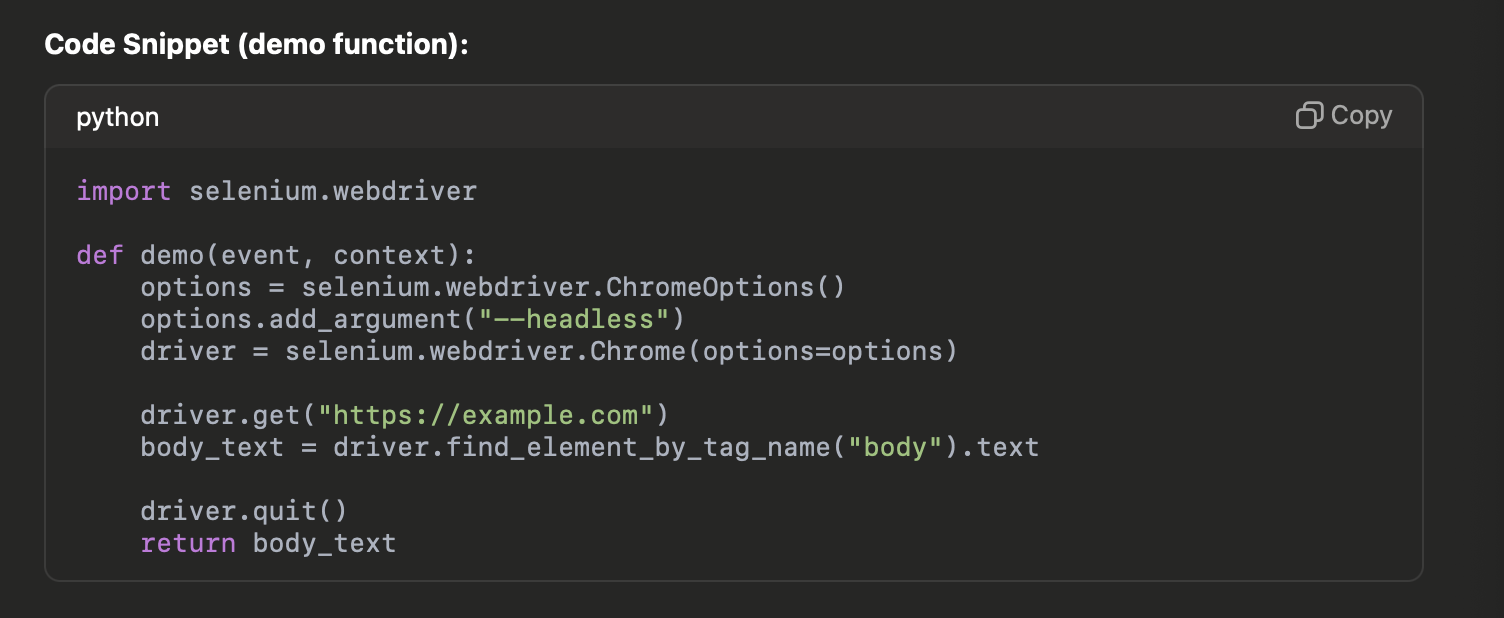
After deploying via docker, we tested the function to confirm that it executed as expected, writing the scraped job data to S3.
In my case, the demo function successfully scraped content from example.com as a basic test. You can modify the function to scrape your desired content.
Code Snippet (demo function):
Challenges Faced
Lambda Package Size Limit: One challenge was managing the size of the deployment package. We resolved this by using the pre-built Docker image to bundle large dependencies such as Selenium and headless Chrome.
Chrome Driver Compatibility: I faced countless issues running headless Chrome in the Lambda environment due to its strict runtime limitations and compatibility issues. After exploring different solutions, I used a pre-built Docker for headless Chrome from GitHub, which simplified the process.
S3 Permissions: Initially, the Lambda function was not able to write to S3 due to insufficient permissions. This was solved by fine-tuning the IAM policies attached to the Lambda role.
Once I deployed the pre-built docker image, I tested the setup by running a Selenium task to retrieve the content of a webpage (e.g., example.com). The Lambda function worked perfectly, retrieving the page title and proving that headless Chrome was successfully running in the Lambda environment.
This phase laid the groundwork for automating the scraping process and storing the results securely, setting the stage for future integration with AWS CloudWatch, SNS alerts, and other advanced features.
Automating Scraping with AWS CloudWatch
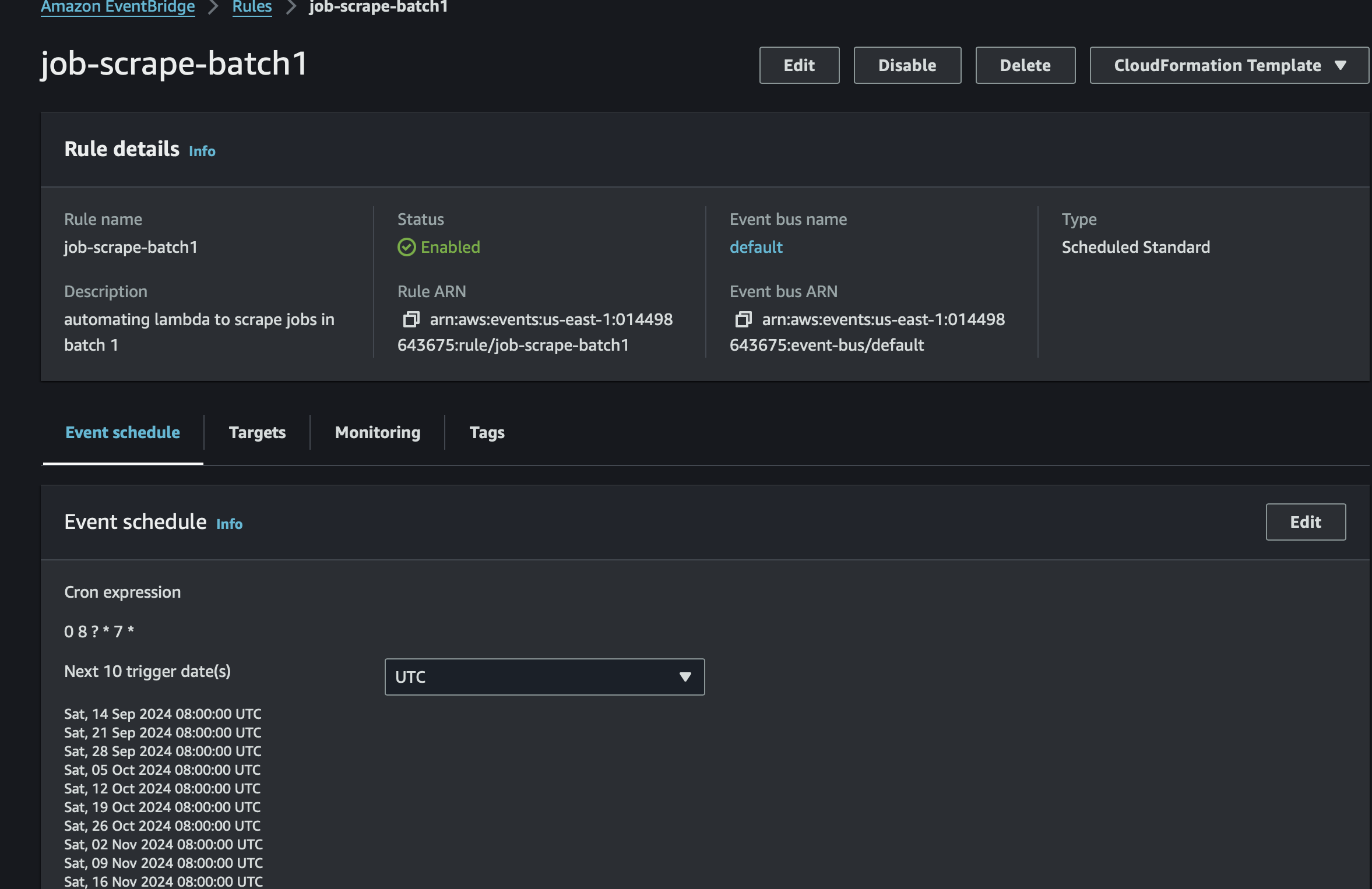
To make the scraping run at regular intervals, you can use Amazon CloudWatch to trigger your Lambda function on a schedule.
Go to CloudWatch in the AWS Console.
Navigate to Rules under the Events section.
Create a new rule:
Set the Event Source to Schedule with a cron expression that defines the desired frequency (e.g., daily at 8 AM UTC).
Set the Target to your Lambda function.
Save the rule and test the automation.
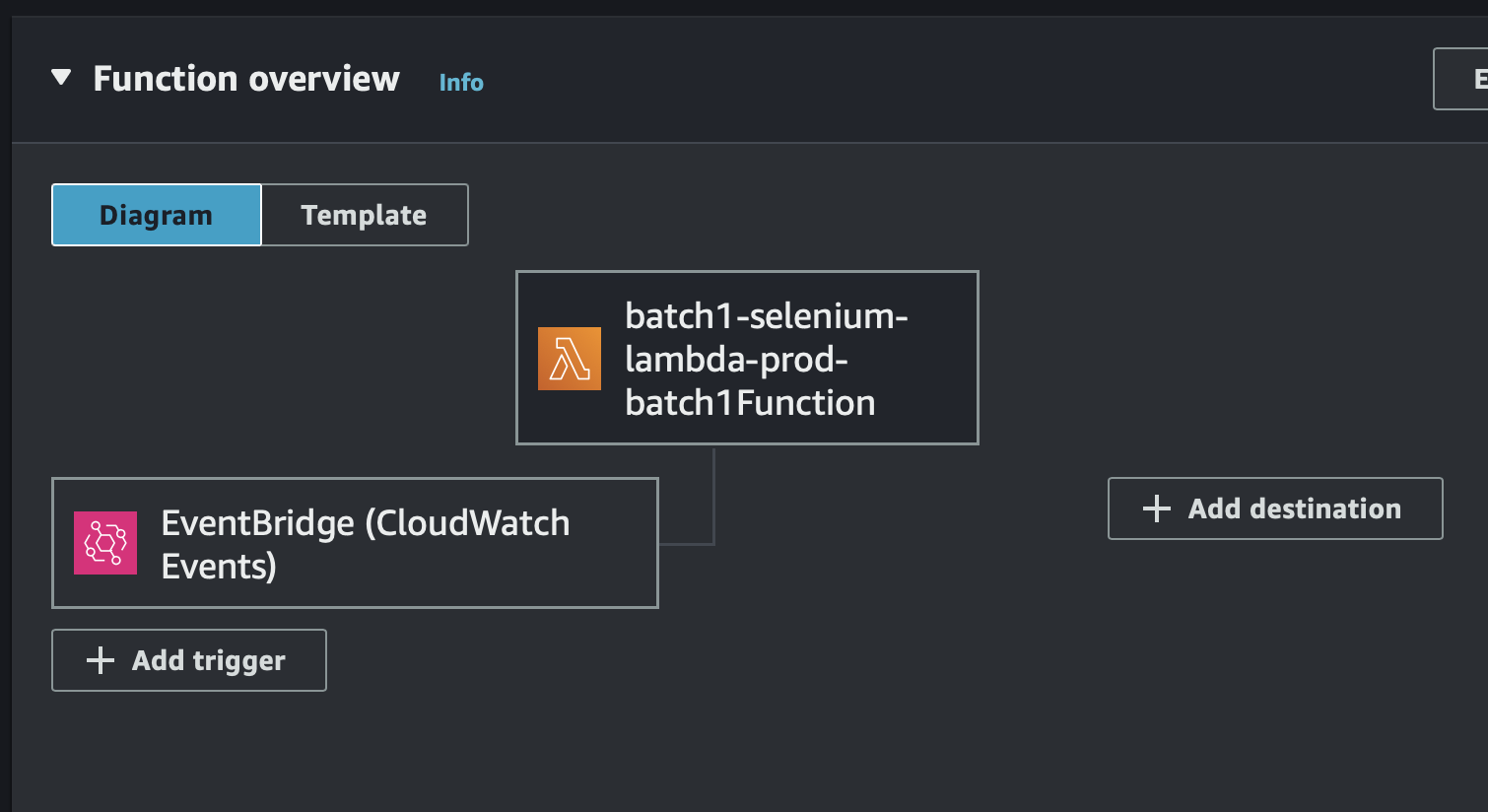
Job Alerts via SNS (Amazon Simple Notification Service)
Set up SNS (Simple Notification Service) to send job alerts for specific job titles (e.g., Data Engineer, ML Engineer):
Create an SNS Topic in the SNS console.
Subscribe your email or phone number to the topic.
In your Lambda function, use the boto3 library to publish to SNS when new jobs are found:
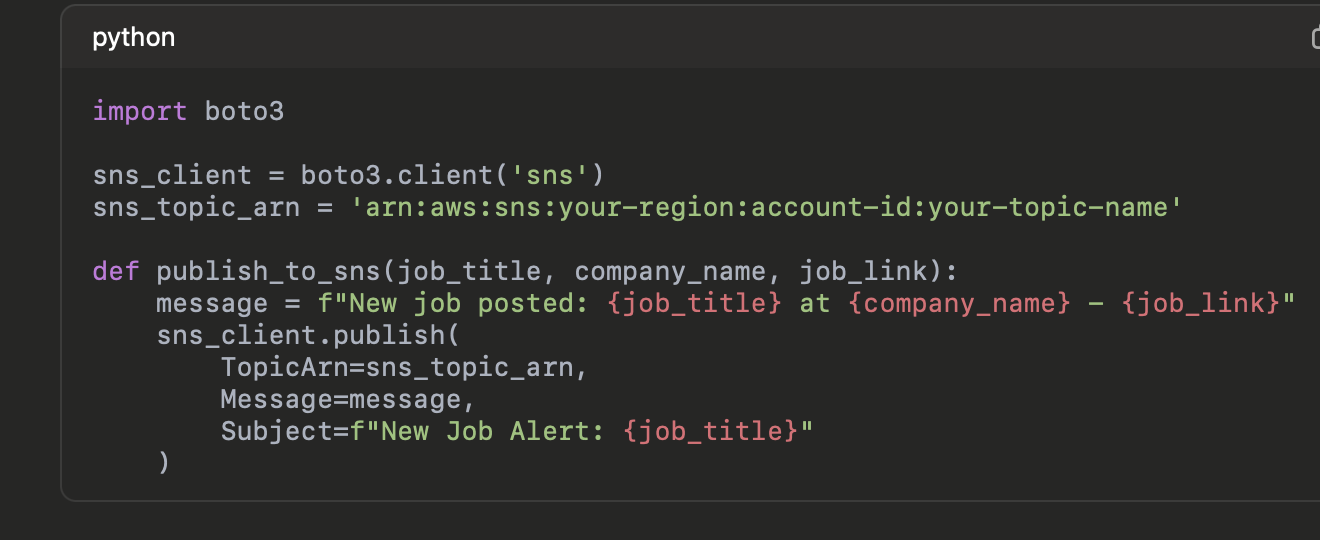
Static Website Hosting in AWS S3 (For Job Board)
I configured the Lambda function to upload scraped job data as JSON files to the S3 bucket, and then fetch this data in our static website.
For the bucket to serve as a static website, you would need to "Enable Static Website Hosting". In the bucket settings, turn on static website hosting and set index.html as the root document.
Final Website Structure:
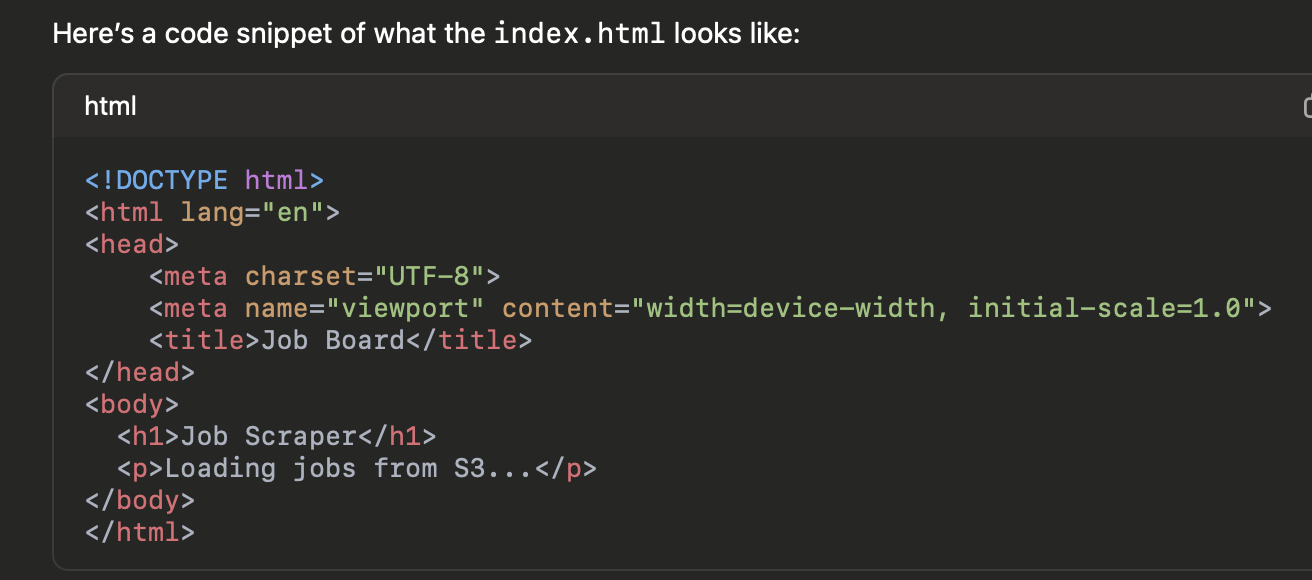
• Index.html: Contains the layout and script to fetch job data.
Here’s a code snippet of what the index.html looks like:
• S3 Bucket: Stores the job data as jobs.json, along with the index.html for the static site.
Challenges and Resolutions
Issue: Access Denied When Fetching JSON Data
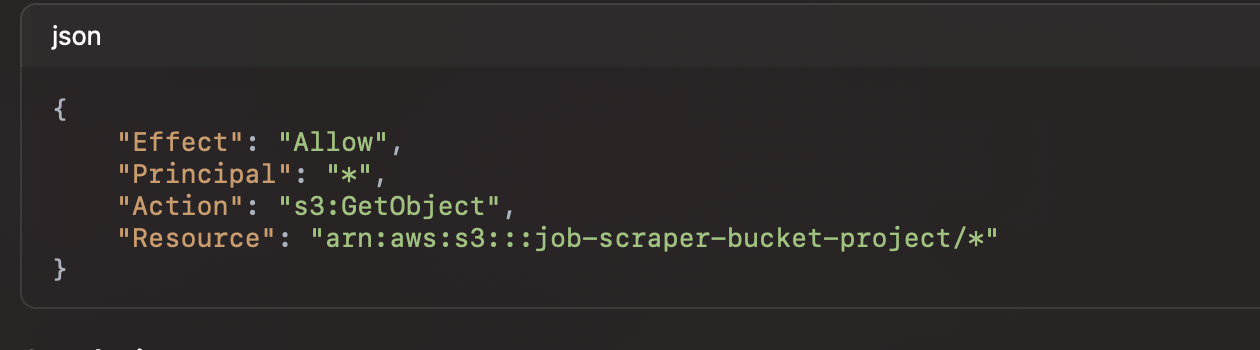
• Problem: We initially forgot to make the JSON files publicly accessible, leading to access denied errors.
• Solution: I updated the S3 bucket policy to allow public access to the objects:
Conclusion
This project demonstrated how AWS Lambda, S3, SNS and CloudWatch can work together to create an automated job scraper. We covered setting up Lambda for scraping, writing data to S3, automating the process with CloudWatch and SNS, and serving the data on a static website hosted in S3. We also addressed common issues like permission problems, access configuration, and troubleshooting using browser tools like Chrome DevTools.
By using a Docker container to deploy Selenium in AWS Lambda, you eliminate many compatibility headaches associated with running headless browsers in Lambda’s limited environment. The Serverless Framework simplifies deployment, while CloudWatch helps automate scraping jobs at regular intervals.
With the job board now live and updating regularly without manual intervention, we have successfully automated the job scraping process. This project showcases the power of AWS services in creating efficient and scalable solutions. 🎉
Live Demo 🌐
- Static Website URL: Visit the Job Board.
Subscribe to my newsletter
Read articles from Freda Victor directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Freda Victor
Freda Victor
I am an Analytics Engineer skilled in Python, SQL, AWS, Google Cloud, and GIS. With experience at MAKA, Code For Africa & Co-creation Hub, I enhance data accessibility and operational efficiency. My background in International Development and Geography fuels my passion for data-driven solutions and social impact.