Unlocking the Power of Retrieval-Augmented Generation (RAG): The Future of Intelligent Content Generation
 Yashkumar Dubey
Yashkumar DubeyIn the evolving world of AI, Retrieval-Augmented Generation (RAG) stands out as the best of two AI paradigms: retrieval-based models and generative models. It enhances the accuracy and relevance of content, taking it far beyond the limitations of traditional approaches.
What is RAG?
At its core, RAG combines the strengths of retrieval mechanisms (like search engines) and generative models (like GPT-4). While generative models are great at producing human-like text, they can sometimes generate hallucinated or irrelevant information. Retrieval models, on the other hand, excel at finding factual and pertinent information from a knowledge base.
How RAG Works
RAG follows a two-step process:
Retrieval Phase: The system retrieve the most relevant documents or pieces of information based on the input.
Generation Phase: The retrieved data is then fed into a generative model (like GPT), which crafts a coherent response based on the factual information found.
Types of Retrieval-Augmented Generation (RAG)
There are several types of RAG setups, each serving different purposes depending on the nature of the knowledge base and the task at hand:
1. RAG-Sequence
RAG-Sequence retrieves relevant documents first and then generates a response, integrating all retrieved pieces at once. This sequence is particularly powerful in answering complex questions where multiple pieces of information need to be synthesized for a coherent answer mostly used in, Complex document summarization, technical Q&A systems, or creating multi-source reports.
2. RAG-Token
RAG-Token works at the token level, where each token (a small piece of language like a word or character) is influenced by different retrieved documents. Instead of generating text after retrieving the entire document, RAG-Token refines its generation process for each token based on real-time information retrieval.
3. Hybrid RAG
Hybrid RAG combines both Sequence and Token approaches for highly complex or sensitive tasks. It leverages the benefits of broader document retrieval and token-level precision.
Use case: Legal document creation, medical AI systems, or financial report generation, where accuracy at every level is paramount.
Advantages of RAG
Improved Accuracy.
Context-Aware Generation.
Scalability.
Domain-Specific Knowledge.
How to Use RAG in Your Projects
To leverage the power of RAG in real-world applications, I have given sample codes of my own projects, follow these steps:
- Define Your Knowledge Source: Identify the knowledge base that RAG will retrieve information from. This could be a database of documents, research papers, or even a proprietary data store.
Step1 will be loading the data.
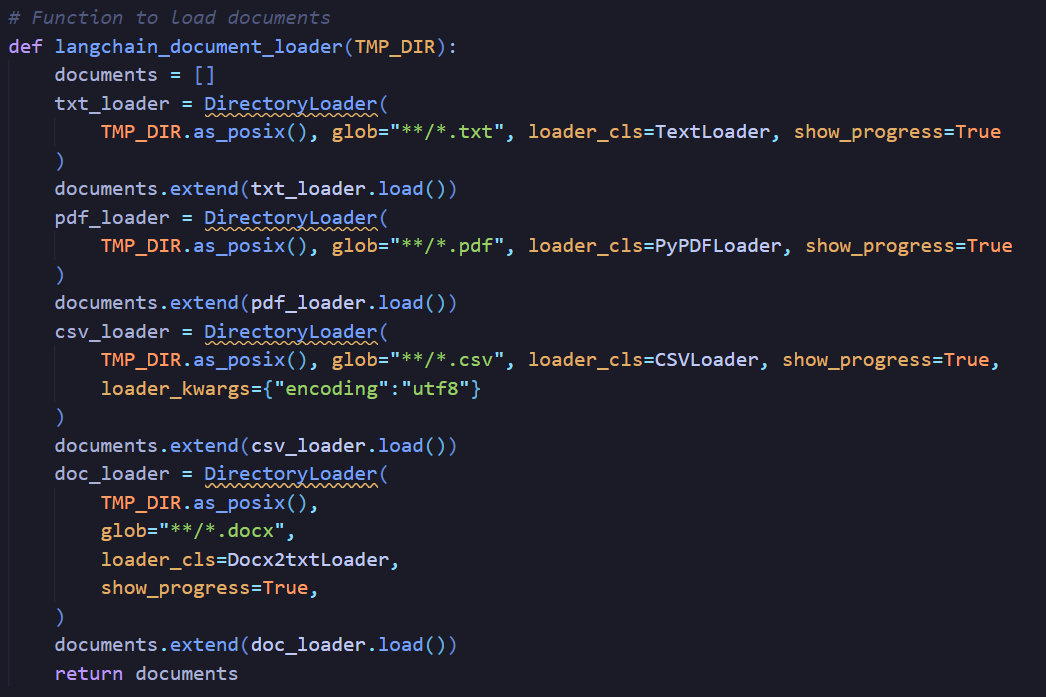
Step2 will be storing the data, Here I have used MongoDB Atlas or Astradb VectorStore to store my Embedded data.
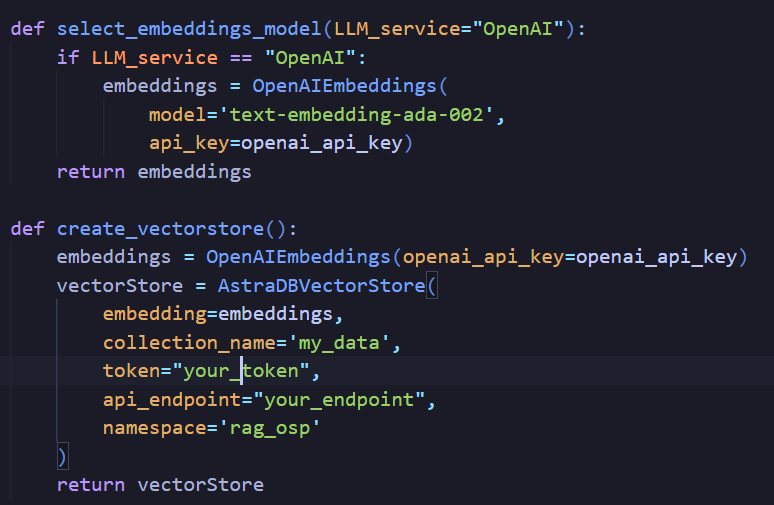
Step3 Choose the Which Rag you want to use based on the application you have then will be choosing the model like (eg GPT4, Google Gemini etc.) to fed the retrieved data, which will crafts a response based on the factual information found.
Applications in which we use RAG:
Customer Support: RAG can be used to generate accurate responses to customer queries by retrieving relevant information from a database of FAQs or manuals.
Research Assistance: Scholars can use RAG to generate summaries or answers to complex questions by pulling data from large corpora of scientific papers.
Legal Services: Lawyers and legal assistants can retrieve case law or statutes relevant to their cases and generate structured arguments or briefs.
Medical AI: RAG-powered systems can provide accurate medical advice by retrieving the latest research articles and guidelines, ensuring that the generated recommendations are based on the latest medical data.
Subscribe to my newsletter
Read articles from Yashkumar Dubey directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Yashkumar Dubey
Yashkumar Dubey
I am a AIML Enthusiast working in the field of data science. I have also worked in web development and android development. I like to code at night with listening to music.