Comprehensive Guide to the ReLU Activation Function in Neural Networks: Definition, Role, and Type Explained
 Pronod Bharatiya
Pronod Bharatiya
ReLU stands for Rectified Linear Unit and is an activation function commonly used in artificial neural networks, especially in deep learning models. It's a simple but effective mathematical function that introduces non-linearity to the network's computations. There are a few variations of the ReLU activation function, that are introduced to cater to the limitations of ReLU.
ReLU (Rectified Linear Unit) is a widely-used activation function in deep learning that introduces non-linearity, enhances computational efficiency, and mitigates gradient vanishing. However, it can suffer from the "dying ReLU" problem. Variants like Leaky ReLU, Parametric ReLU (PReLU), Scaled Exponential Linear Unit (SELU), Exponential Linear Unit (ELU), Randomized Leaky ReLU (RReLU), Swish, and Gaussian Error Linear Unit (GELU) address this and other limitations. These variants offer diverse features, including learnable parameters, self-normalizing properties, and randomization, each catering to specific neural network training needs and enhancing overall performance and stability.
1. The Importance of ReLU in Neural Network Learning
ReLU is important in understanding neural networks for several reasons as mentioned below:
Non-linearity: It introduces non-linearity. While it seems linear (output is proportional to input for positive values), its derivative varies, enabling learning intricate, non-linear connections.
Efficient Computation: ReLU is computationally efficient. Unlike sigmoid or tanh, which require exponentiation, ReLU simply thresholds at zero. This results in quicker training.
Avoiding Gradient Vanishing: Sigmoid and tanh can cause the vanishing gradient problem, with extremely small gradients leading to sluggish convergence or even halting learning. ReLU helps alleviate this for many networks.
Sparsity and Sparse Representations: ReLU encourages sparsity in neural networks. For negative inputs, it outputs zero, potentially leading to a more efficient representation in terms of active neurons.
Reduced Overfitting Likelihood: In certain cases, ReLU can curb overfitting. Zeroing out a significant portion of activations for negative inputs serves as a form of regularization, enhancing generalization.
Empirical Success: Empirically, ReLU proves effective across a wide array of tasks and is a preferred choice for numerous deep-learning architectures.
Thus, ReLU and its variants are fundamental activation functions in neural networks. They help neural networks learn complex patterns, mitigate certain training issues, and contribute to the overall effectiveness and efficiency of deep learning models. Understanding ReLU and its properties is essential for building and training neural networks effectively.
2. Types of ReLU
There are several variants of the Rectified Linear Unit (ReLU) activation function, each with its own characteristics. Here are eight common types of ReLU functions.
1. Standard ReLU

The standard ReLU function is zero for negative inputs and linear for positive inputs. However, it suffers from the "dying ReLU" problem, where neurons can become inactive (always outputting zero) during training.
ReLU is a simple and widely used activation function. It is computationally efficient and helps with the vanishing gradient problem. However, it can suffer from the dying ReLU problem, where neurons output zero for all inputs, effectively becoming inactive.
ReLU Graph
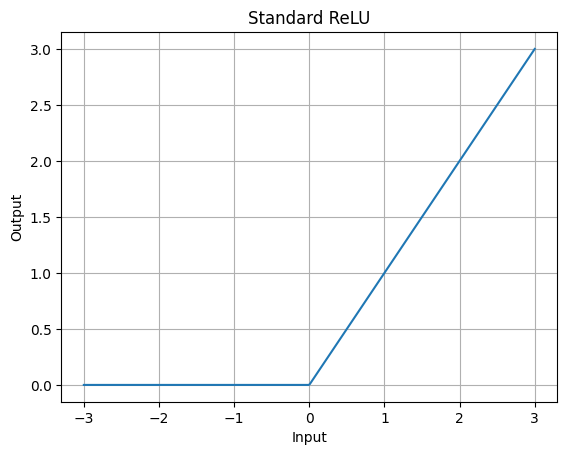
It's a piecewise function that outputs 0 for negative inputs and the input itself for positive inputs. The graph has a sharp bend at 0, leading to its simplicity and efficiency in deep networks.The ReLU graph shows a linear increase for positive x values, allowing them to pass through unchanged. For negative x values, it flattens at y = 0, suppressing negativity. This property introduces non-linearity in neural networks, enabling them to capture complex data patterns.
2. Leaky ReLU
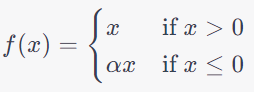
Leaky ReLU introduces a small slope (α) for negative inputs, preventing neurons from dying completely. It addresses the issue of dying ReLU.
Leaky ReLU addresses the dying ReLU problem by allowing a small, non-zero gradient for negative inputs. This ensures that neurons with negative inputs still receive some signal during backpropagation.
Leaky ReLU Graph

Similar to ReLU but allows a small, non-zero gradient $$\alpha = 0.01$$ for negative inputs, which prevents dead neurons.
Leaky_relu is a function that implements the leaky ReLU activation. The alpha parameter controls how much "leak" there is for negative inputs. This graph shows a linear portion for x > 0 and a non-zero, linear portion for x <= 0. This small non-zero gradient for negative inputs helps to mitigate the dying ReLU problem.
The Dying ReLU Problem and Leaky ReLU
The "dying ReLU" issue occurs when some neurons in a network using Rectified Linear Units (ReLU) output zero for all inputs, becoming inactive in learning. This usually results from a large gradient in a ReLU neuron during training, causing it to consistently output zero.
Leaky ReLU, a variant of traditional ReLU, mitigates this. Rather than being zero for x < 0, it allows a slight non-zero gradient (typically a tiny constant like 0.01) for x < 0. Let's now express how mathematically:
Derivative for x > 0: In this case, it's 1 (since f(x) = x, and its derivative is 1).
Derivative for x <= 0: It's 'a' (since f(x) = ax, and its derivative is 'a').
Hence, even with negative x, a small gradient ('a') still propagates in back-propagation, potentially enabling recovery.
Leaky ReLU tackles the dying ReLU problem, but it's not the sole remedy. Other versions like Parametric ReLU (PReLU) and Exponential Linear Unit (ELU) also aim to address this concern.
3. Parametric ReLU (PReLU)

Similar to Leaky ReLU, PReLU introduces a slope for negative inputs, but unlike Leaky ReLU, α is a learnable parameter, allowing the network to adapt the slope during training.
PReLU addresses the limitations of the Leaky ReLU activation function. Like Leaky ReLU, PReLU introduces a small, non-zero slope for negative inputs, preventing the complete shutdown of neurons during training.
What sets PReLU apart is that it allows this slope, denoted by
α, to be learned during the training process. In contrast, Leaky ReLU has a fixed slope, typically a small constant, which is not updated during training. This means that PReLU has the flexibility to adapt the negative slope to the specific characteristics of the data, potentially leading to improved learning and generalization.
The learnable parameter α in PReLU brings a level of adaptability that can be crucial in complex learning tasks. It enables the neural network to automatically adjust the behavior of neurons based on the data it encounters. This adaptability is particularly beneficial when dealing with different types of data distributions or complex relationships within the data. By allowing the network to fine-tune the slope, PReLU enhances the model's capacity to capture intricate patterns and relationships. This potentially leads to better performance in a wide range of tasks, from image recognition to natural language processing.
PReLU Graph
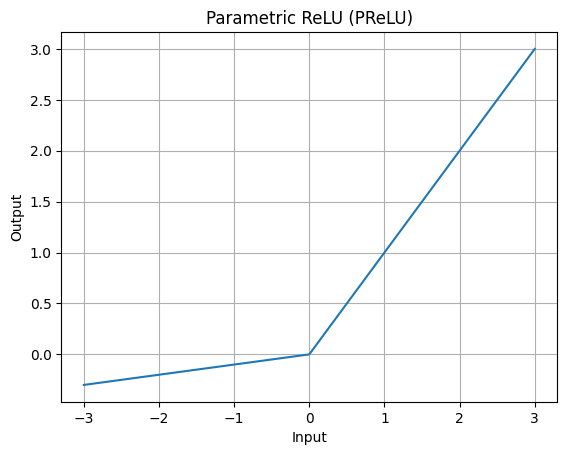
Like Leaky ReLU but with a learnable slope for negative values. It provides more flexibility as the slope of the negative side can adapt during training.
PReLU defines a function called prelu which computes the PReLU activation for a given input x and a specified parameter alpha. The function applies the ReLU activation for positive inputs and a linear function with slope alpha for negative inputs. The code then generates a range of x values using NumPy's linspace to create a smooth curve. It sets alpha to 0.1, controlling the slope for negative inputs. The corresponding y values are calculated using the prelu function. Finally, the code uses Matplotlib to plot the PReLU activation function, labeling it with the chosen value of alpha. The resulting graph visually represents how the PReLU activation function behaves for different input values.
4. Scaled Exponential Linear Unit (SELU)
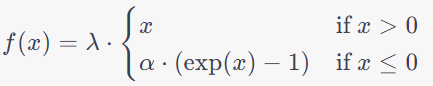
SELU is a self-normalizing activation function. It has properties that encourage the network's activations and gradients to maintain a specific mean and variance, aiding in stable training.
SELU, which stands for Scaled Exponential Linear Unit, is a self-normalizing activation function that plays a crucial role in stabilizing the training process of neural networks. Unlike traditional activation functions like ReLU or sigmoid, SELU is designed to maintain a specific mean and variance of activations throughout the layers of a network. This property helps to mitigate the vanishing and exploding gradient problems, which can hinder the learning process in deep networks.
Specifically, SELU achieves self-normalization by incorporating two key parameters: the alpha (α) and lambda (λ). The alpha parameter is the slope of the function for inputs greater than zero, which is typically set to 1.6733 to promote self-normalization. The lambda parameter is the scaling factor applied to the output for inputs less than zero, set to 1.0507 for the same purpose. By utilizing these carefully chosen parameters, SELU ensures that the mean and variance of activations remain close to one, allowing for more stable and efficient training. This self-normalizing property is particularly beneficial in deep networks with many layers, where maintaining stable gradients is crucial for successful learning.
In practice, SELU has shown remarkable performance improvements in various deep-learning tasks. It enables the training of very deep networks without the need for sophisticated initialization schemes or batch normalization layers. This makes it an attractive choice for architectures where stability and efficiency in training are paramount, ultimately leading to more accurate and reliable neural network models.
SELU Graph

SELU introduces both scaling and an exponential curve for negative inputs. It self-normalizes and stabilizes outputs for deeper networks.
The SELU function is defined with parameters for its slope (alpha) and scaling factor (lambda_). It computes the SELU activation based on input x, where positive values are returned as is, while negative values are transformed using the SELU formula. The code then generates a range of x values and applies the SELU function to obtain corresponding y values. It creates a plot to display x against y, labels the axes, sets a title, adds a grid for clarity, and includes a legend. Finally, it shows the plot on the screen, providing a visual representation of the SELU activation function.
5. Exponential Linear Unit (ELU)

ELU has a non-zero slope for negative inputs, and the slope decreases exponentially as x becomes more negative. This helps alleviate the vanishing gradient problem and can provide better learning performance than ReLU.
The Exponential Linear Unit is an activation function commonly used in deep learning models. What sets ELU apart from other popular activation functions like ReLU is its distinct behavior for negative inputs. ELU has a non-zero slope for negative values, which means that it allows gradients to flow even when the input is negative. This is crucial because in traditional activation functions like ReLU, when the input is negative, the gradient becomes zero, leading to a phenomenon known as the "dying ReLU" problem. In contrast, ELU's non-zero slope for negative inputs helps mitigate the vanishing gradient problem, allowing the network to learn effectively in deeper architectures.
Furthermore, ELU exhibits an exponential decrease in slope as the input becomes more negative. This characteristic is beneficial because it introduces a saturation effect that prevents extreme activations. As the input becomes highly negative, the slope approaches zero, which effectively limits the output and curbs the potential for exploding activations. This controlled saturation ensures that the model remains stable and avoids the issues associated with unbounded activations.
ELU's combination of a non-zero negative slope and exponential saturation properties contribute to its effectiveness in deep learning architectures, potentially leading to improved learning performance compared to other activation functions, particularly in situations where negative inputs are prevalent.
ELU Graph

ELU behaves similarly to ReLU for positive values but smooths out negative values exponentially. The graph slopes upward slowly on the negative side, helping in overcoming the dead neuron problem.
The above graph illustrates the Exponential Linear Unit (ELU) activation function which is another widely used non-linear function in neural networks. The ELU function smoothly transitions between linear and exponential behavior. The positive input values maintain linearity, mirroring the input. However, for negative inputs, it introduces a slight curvature, enabling the function to capture more complex relationships. This curvature is controlled by the alpha parameter, which determines the slope of the curve for negative inputs. The red dashed lines at y=0 and x=0 serve as reference points, highlighting the point of intersection and origin. Overall, the ELU activation function provides a versatile activation choice that can facilitate better learning in deep neural networks.
6. Randomized Leaky ReLU (RReLU):

(where ai is randomly sampled from a uniform distribution)
RReLU is similar to Leaky ReLU but introduces randomness during training by randomly sampling ai from a predefined distribution. This randomness acts as a form of regularization.
ReLU is an activation function akin to Leaky ReLU, which allows a small, non-zero gradient for negative inputs. However, RReLU goes a step further by introducing randomness during training. Instead of using a fixed slope (alpha) for negative inputs, RReLU samples a value (ai) from a predefined distribution for each neuron and multiplies it with the input during forward propagation. This introduces an element of stochasticity to the function's behavior, effectively making each neuron's response to negative inputs different during each training iteration. This randomness serves as a form of regularization, preventing neurons from becoming overly specialized and promoting a more robust and adaptable network.
The introduction of randomness in RReLU's activation function during training aids in preventing overfitting and promotes better generalization to unseen data. By allowing the function's behavior to vary in a controlled manner, RReLU encourages the network to learn more diverse and representative features. This can be particularly beneficial in scenarios where the training data is noisy or heterogeneous. Additionally, the ability to sample ai from a predefined distribution provides an additional hyperparameter that can be tuned to optimize performance on specific tasks, making RReLU a versatile activation function that can be adapted to different neural network architectures and datasets.
RReLU Graph
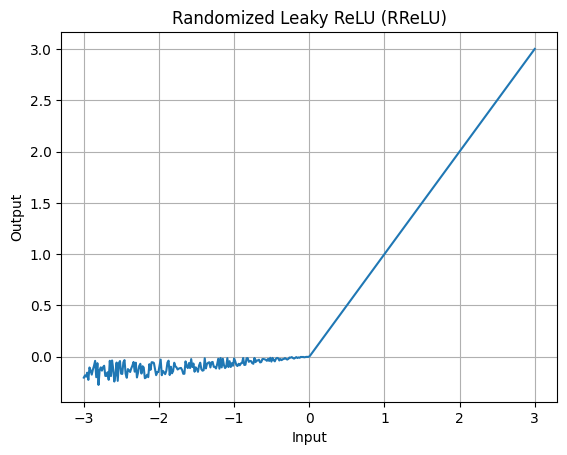
The negative slope varies randomly during training, providing a degree of regularization. Its graph can slightly change depending on the random slope for negative values.
RReLU function is an extension of the Leaky ReLU, introducing a random element to prevent neuron inactivity. For the above graph, we use the libraries matplotlib for plotting and numpy for numerical computations. It defines a function randomized_leaky_relu that applies the activation function to an input x, with an optional parameter alpha (default is 0.01). The function returns the output after comparing each element of x with a randomized element.
How does RReLU differ from Leaky ReLU?
While Leaky ReLU allows a small, non-zero gradient for negative inputs, the Randomized Leaky ReLU introduces an additional random element during computation. Specifically, it multiplies a randomly generated value between 0 and 1 with a user-defined parameter (often denoted as alpha) before applying the activation function. This randomization helps prevent neurons from becoming too specialized or inactive during training, adding a stochastic element to the function's behavior. In contrast, traditional Leaky ReLU applies a fixed multiplier to negative inputs, which may lead to a more deterministic response.
The introduction of randomness in the Randomized Leaky ReLU aims to enhance the diversity of responses from neurons, potentially making the network more robust and adaptable to different types of input data. This property is particularly useful in scenarios where a deterministic Leaky ReLU might not be sufficient, such as in complex or noisy datasets. However, it's important to note that the degree of randomization is controlled by the alpha parameter, which allows for fine-tuning based on the specific requirements of the neural network and the nature of the data being processed.
7. Swish
The "Swish" activation function, introduced by researchers at Google in 2017, is a smooth and non-monotonic activation function that has gained popularity in neural network architectures. It's defined as:
f(x)=x⋅σ(βx)**
where σ is the sigmoid function and β is a trainable parameter. This formula effectively multiplies the input x by the output of the sigmoid function applied to βx.
Let's break down how this combination works:
Linearity from the Identity Function:
- The term
xdirectly multiplies the input. This is a linear operation because the output is proportional to the input. In simple terms, if the input is twice as large, the output will also be twice as large.
- The term
Non-Linearity from the Sigmoid Function:
- The sigmoid function
σ(βx)introduces non-linearity. The sigmoid function squashes its input to a range between 0 and 1, resulting in an S-shaped curve. This introduces a non-linear element to the function. Whenβxis far from 0, the sigmoid function's output is either very close to 0 or 1, making it highly non-linear in those regions.
- The sigmoid function
By combining these two components, Swish benefits from both the linear characteristics, which allow it to adapt to simple relationships in the data, and the non-linear characteristics, which enable it to model more complex patterns. This combination is particularly effective in deep learning because it strikes a balance between being expressive enough to capture intricate relationships in data and being smooth and differentiable, which is crucial for efficient training through backpropagation.
The key characteristic of Swish is that it combines the linearity of the identity function with the non-linearity of the sigmoid function. This allows Swish to capture complex relationships within the data while maintaining the smoothness and differentiability necessary for efficient gradient-based optimization during training.
One of the peculiar behaviors of the Swish activation function is its tendency to perform consistently well across a wide range of neural network architectures and tasks. In various experiments, Swish has demonstrated better training performance and generalization capabilities compared to other popular activation functions like ReLU (Rectified Linear Unit) and sigmoid. Additionally, Swish tends to produce smoother and more continuous gradients, which can lead to faster convergence during training. However, it's worth noting that the Swish function is not always superior; its performance can be sensitive to factors like network architecture, dataset, and initialization. As a result, while Swish has shown promising results in many cases, it may not always be the optimal choice and should be evaluated in the context of specific tasks and datasets.
Swish Graph
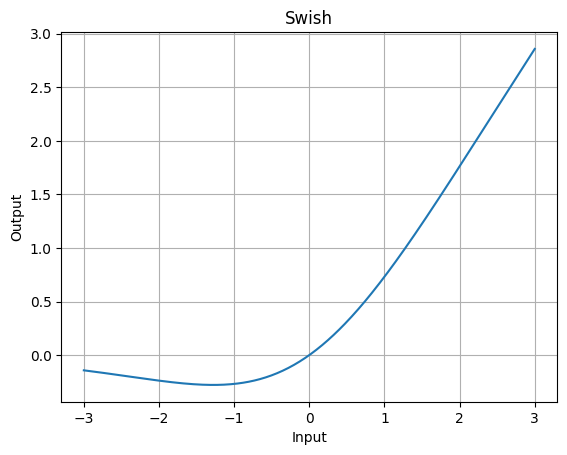
The Swish function has a smooth curve that is non-monotonic, meaning it can return negative outputs even for positive inputs. It has shown better performance in deeper networks compared to ReLU.
For the above graph, we first import the necessary libraries, NumPy for numerical operations and Matplotlib for plotting. It then defines the swish function and generates a range of input values from -10 to 10. The function is applied to these values, and a plot is generated showing the swish function's behavior.
8. GELU (Gaussian Error Linear Unit)
GELU stands for Gaussian Error Linear Unit. It was introduced by Dan Hendrycks and Kevin Gimpel in their 2016 paper titled "Gaussian Error Linear Units (GELUs)".
The GELU activation function is defined as follows:
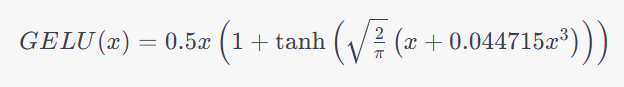
In this equation:
xis the input to the activation function.tanhis the hyperbolic tangent function, which squashes the input to a range between -1 and 1.sqrt2/π and 0.0447150.044715 are constant scaling factors chosen to approximate the cumulative distribution function of a Gaussian distribution.
The GELU activation function has several desirable properties:
Smoothness: It is a smooth and continuous function, which is important for gradient-based optimization techniques like backpropagation.
Non-linearity: It introduces non-linearity into the model, allowing it to learn complex relationships between inputs and outputs.
Zero Mean: GELU has a mean of zero, which can help with the initialization of neural network weights.
Approximation of ReLU: GELU behaves like the Rectified Linear Unit (ReLU) for large positive inputs, which is a commonly used activation function in deep learning.
Saturates at extremes: It smoothly saturates towards -1 and 1 for large negative and positive inputs, respectively.
GELU gained popularity in the deep learning community due to its good performance in a variety of tasks. It is often used as an alternative to other activation functions like ReLU, Leaky ReLU, and Sigmoid in deep neural networks.
GELU Graph

GELU is smoother than ReLU and applies a sigmoid-like shape that enables stochastic regularization. It offers a probabilistic approach to activation, unlike the hard zeroing of ReLU.
The above graph showcases how the output of the GELU function varies with different input values (x-axis). For inputs around zero, the function exhibits a roughly linear behavior, similar to the identity function. As the input moves further from zero, the curve gradually transitions into a non-linear region, displaying sigmoid-like characteristics. Notably, GELU smoothly saturates as the input approaches both positive and negative extremes. This means that it approaches -1 and 1 without exhibiting the sharp cutoffs associated with some other activation functions.
Here you can find the Python code for graph for above types of ReLU Activation Functions - ReLU Activation Graph Code
2. Training Stability, Prevention of Dead Neurons, and Gradient Properties -Comparison of Top Varient ReLU
| Activation Function | Training Stability | Prevention of Dead Neurons | Gradient Properties |
| ReLU | Prone to the Dying ReLU problem, as neurons can get stuck during training causing them to output zero. | Not effective at preventing dead neurons, as some neurons may become inactive. | Simple, either zero or one depending on input polarity. |
| Leaky ReLU | More stable compared to standard ReLU. It allows a small gradient for negative values, preventing neurons from becoming inactive. | More effective at preventing dead neurons compared to standard ReLU. | Non-zero gradient for negative values, which prevents the dying ReLU problem. |
| Parametric ReLU | A parameterized version of Leaky ReLU where the slope of the negative values is learned during training. | More stable compared to standard ReLU, similar to Leaky ReLU. | More effective at preventing dead neurons compared to standard ReLU. |
| Scaled Exponential Linear Unit (SELU) | Designed to maintain a mean of 0 and a standard deviation of 1 during training, contributing to stable training. | Highly effective at preventing dead neurons, as it enforces activations to stay in a certain range. | Maintains unit variance and mean during training, ensuring stable gradients. |
| Exponential ReLU | Similar to Leaky ReLU, it uses an exponential function for negative values. | More stable compared to standard ReLU, similar to Leaky ReLU. | Non-zero gradient for negative values, which prevents the dying ReLU problem. |
| Randomized ReLU | Similar to Leaky ReLU, the slope of the negative values is randomly chosen during training. | More stable compared to standard ReLU, similar to Leaky ReLU. | Non-zero gradient for negative values, which prevents the dying ReLU problem. |
| Swish | Designed to utilize the benefits of both ReLU and Sigmoid functions. | Offers good stability during training due to its smoothness. | Smooth gradient, which can lead to more stable training compared to ReLU. |
| GELU (Gaussian Error Linear Unit) | Designed to approximate the cumulative distribution function of a Gaussian distribution. | Generally stable during training, though it may require specific initialization schemes. | Differentiable almost everywhere, providing stable gradients during training. |
Please note that while these characteristics are generally true, the performance of activation functions may vary depending on the specific architecture, dataset, and training process. It's often recommended to experiment with different activation functions to find the most suitable one for a particular task.
3. General Comparison of Variant of ReLU Activation Functions in Neural Networks
| Activation Function | Formula | Range | Derivative | Typical Use Case | Characteristics | Description | Advantages | Disadvantages |
| ReLU (Rectified Linear Unit) | f(x) = max (0, x) | [0, ∞) | 0 for x < 0, 1 for x > 0 | General purpose deep learning tasks. | Simple and computationally efficient, but can cause a "dying ReLU" problem. | The ReLU function returns 0 for all negative inputs and is linear for all positive inputs. It is widely used in deep learning due to its simplicity and effectiveness. | - Computationally efficient. - Non-linear (allows for learning complex patterns). - Avoids the vanishing gradient problem. | - Prone to the "dying ReLU" problem (neurons can sometimes get stuck during training and stop learning altogether). |
| Leaky ReLU | f(x) = max (0.01x, x) | (-∞, ∞) | 0.01 for x < 0, 1 for x > 0 | Networks where you want to mitigate the "dying ReLU" problem. | Prevents "dying ReLU" problem by allowing a small, non-zero gradient for <0x<0. | Leaky ReLU introduces a small, non-zero slope α for negative inputs, which helps prevent the "dying ReLU" problem. It allows information flow for negative inputs. | - Addresses the "dying ReLU" problem by allowing a small gradient for negative values. | - Not zero-centered, which may lead to optimization challenges. |
| Parametric ReLU | f(x) = αx for x < 0, f(x) = x for x ≥ 0 | (-∞, ∞) | α for x < 0, 1 for x ≥ 0 | When you want the slope of the negative region to be learned. | Similar to Leaky ReLU, but α is a learnable parameter. | Parametric ReLU allows the slope parameter α to be learned alongside other parameters during training. It provides more flexibility in the function's shape. | - Introduces a learnable parameter α, allowing the network to adapt the slope for negative values. | - Requires additional computation due to the learnable parameter α. |
| SELU (Scaled Exponential Linear Unit) | f(x) = λ * (exp(x) - 1) for x < 0, f(x) = x for x ≥ 0, where λ = 1.0507, α = 1.6733 | (-∞, ∞) | λ * exp(x) for x < 0, 1 for x ≥ 0 | Networks where you want to improve training stability and performance. | Smooth transition from linear to exponential growth, good for positive inputs. | SELU combines the linearity of ReLU for negative inputs and the exponential growth for positive inputs. It is designed to maintain self-normalizing properties within a network. | - Designed to produce self-normalizing networks that converge quickly. | - Requires specific initialization and may not work well for all architectures. |
| ELU (Exponential Linear Unit) | f(x) = α * (exp(x) - 1) for x < 0, f(x) = x for x ≥ 0, where α is a hyper-parameter | (-∞, ∞) | α * exp(x) for x < 0, 1 for x ≥ 0 | Networks where you want a smooth, non-linear transition for negative inputs. | Combines exponential growth <0x<0 and linear for ≥0x≥0. | Exponential ReLU applies exponential growth for negative inputs and is linear for non-negative inputs. It aims to capture a wider range of information. | - Aims to alleviate the vanishing gradient problem and provide smoother gradients. | - Computationally more expensive than ReLU and its variants. |
| Randomized ReLU | f(x) = x with probability p, f(x) = αx with probability (1 - p), where α is a hyper-parameter | (-∞, ∞) | p for x = 0, α for x < 0 | Networks where you want to introduce randomness for regularization. | Introduces randomness to prevent neurons from always outputting zero. | Randomized ReLU randomly sets the slope α for each neuron, which introduces an element of randomness in the activations, helping to prevent "dead" neurons. | - Introduces randomness during training, which can act as a form of regularization. | - Requires tuning the probability parameter p. |
| Swish | f(x) = x * sigmoid(x) | (-∞, ∞) | sigmoid(x) (1 + x (1 - sigmoid(x))) for x ≠ 0, 0 for x = 0 | Networks where you want a self-gated activation function. | Proposed by Google's researchers, tends to perform well in deep networks. | Swish is a smooth, non-monotonic function that tends to perform well in deep neural networks. It applies a sigmoid-like transformation to the input. | - Empirically shown to perform well in deep networks. | - Computationally more expensive than ReLU. |
| GELU (Gaussian Error Linear Unit) | f(x) = 0.5x(1 + tanh(√(2/π) * (x + 0.044715x³))) | [0, ∞) | 0.5(1 + tanh(√(2/π) (x + 0.044715x³)) + 0.134145 + 0.797884x²) sech²(√(2/π) * (x + 0.044715x³)) for x ≠ 0, 1 for x = 0 | Networks where you want to explore alternatives to standard ReLU variants. | Smooth approximation of ReLU, designed to model uncertainty in neural networks. | GELU is a smooth approximation of ReLU that incorporates a Gaussian noise term. It is designed to model uncertainty in neural networks, particularly in Bayesian frameworks. | - Designed to approximate the Gaussian cumulative distribution function. | - Computationally more expensive compared to simpler activations like |
Subscribe to my newsletter
Read articles from Pronod Bharatiya directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Pronod Bharatiya
Pronod Bharatiya
As a passionate Machine Learning and Deep Learning enthusiast, I document my learning journey on Hashnode. My experience encompasses various projects, from exploring foundational algorithms to implementing advanced neural networks. I enjoy breaking down complex concepts into digestible insights, making them accessible for all. Join me as I share my thoughts, tutorials, and tips to navigate the exciting world of ML and DL. Connect with me on LinkedIn to explore collaboration opportunities!